利用neon技术对矩阵旋转进行加速
一般的矩阵旋转操作都是对矩阵中的元素逐个操作,假设矩阵大小为m*n,那么时间复杂度就是o(mn)。如果使用了arm公司提供的neon加速技术,则可以并行的读取多个元素,对多个元素进行操作,虽然时间复杂度还是o(mn),但是常数因子会变小,并且在寄存器里的操作比在普通内存中还要快一些,所以会带来一定的性能提升。
在实际应用中,我需要对一个矩阵进行顺时针旋转90度,网上这方面的资料很少,于是自己研究了一下,利用neon给出的一些加速指令,设计了一个简单的neon矩阵旋转算法。
1.目标:将输入矩阵顺时针旋转90度,如下图所示:
输入矩阵 输出矩阵


2.一般做法:
一般的做法是,将输入矩阵中的每个元素,根据旋转的角度,计算出其在旋转后矩阵中的位置,并填充该值。
3.利用NEON的做法:
考虑将一个矩阵划分成若干子矩阵,例如:一个128×256大小的矩阵可以划分为16×32个8×8大小的矩阵。分别对每个8x8的子矩阵进行旋转,再将其复制到输出矩阵中正确的坐标上即可。可以总结为2步:
循环执行以下步骤,直到所有子矩阵均被处理过
1.旋转当前子矩阵
2.将旋转后的子矩阵复制到输出矩阵中
其中最关键的就是第一步,详细讲一下利用neon技术如何做到:
以byte数组为例(因为android中获取的yuv数据就是byte型,将一个矩形按行连成了一个大一维数组),假设图像的长宽都可以被8整除。首先利用2个uint8x8x4_t型数组,将8×8大小的子矩阵读入
mat1.val[]=vld1_u8(srcImg+i*width+j);
mat1.val[]=vld1_u8(srcImg+(i+)*width+j);
mat1.val[]=vld1_u8(srcImg+(i+)*width+j);
mat1.val[]=vld1_u8(srcImg+(i+)*width+j);
mat2.val[]=vld1_u8(srcImg+(i+)*width+j);
mat2.val[]=vld1_u8(srcImg+(i+)*width+j);
mat2.val[]=vld1_u8(srcImg+(i+)*width+j);
mat2.val[]=vld1_u8(srcImg+(i+)*width+j);
接着,对两两相邻的寄存器做基于uint8_t类型的专置操作,即:mat1和mat2中的0和1,2和3寄存器分别做转置,得到4个uint8x8x2_t类型数组
vtrn操作示意图如下:
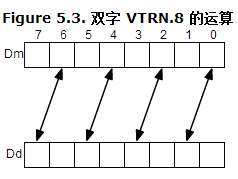
temp1=vtrn_u8(mat1.val[],mat1.val[]);
temp2=vtrn_u8(mat1.val[],mat1.val[]);
temp3=vtrn_u8(mat2.val[],mat2.val[]);
temp4=vtrn_u8(mat2.val[],mat2.val[]);
注意,vtrn_8里面两个寄存器的顺序不能颠倒
然后,对这四个数组的类型进行转换,将uint8x8_t转换成uint16x4_t
temp5.val[]= vreinterpret_u16_u8(temp1.val[]);
temp5.val[]= vreinterpret_u16_u8(temp1.val[]);
temp6.val[]= vreinterpret_u16_u8(temp2.val[]);
temp6.val[]= vreinterpret_u16_u8(temp2.val[]);
temp7.val[]= vreinterpret_u16_u8(temp3.val[]);
temp7.val[]= vreinterpret_u16_u8(temp3.val[]);
temp8.val[]= vreinterpret_u16_u8(temp4.val[]);
temp8.val[]= vreinterpret_u16_u8(temp4.val[]);
接下来的做法和上面的这一套很像,继续对这些uint16x4_t数据进行转置,这次的顺序和上次有所不同,相邻的奇偶序号寄存器之间进行专置即:0和2,1和3,4和6,5和7
temp9=vtrn_u16(temp6.val[],temp5.val[]);
temp10=vtrn_u16(temp6.val[],temp5.val[]);
temp11=vtrn_u16(temp8.val[],temp7.val[]);
temp12=vtrn_u16(temp8.val[],temp7.val[]);
然后,继续对这四个数组的类型进行转换,将uint16x4_t转换成uint32x2_t
temp13.val[]= vreinterpret_u32_u16(temp9.val[]);
temp13.val[]= vreinterpret_u32_u16(temp9.val[]);
temp14.val[]= vreinterpret_u32_u16(temp10.val[]);
temp14.val[]= vreinterpret_u32_u16(temp10.val[]);
temp15.val[]= vreinterpret_u32_u16(temp11.val[]);
temp15.val[]= vreinterpret_u32_u16(temp11.val[]);
temp16.val[]= vreinterpret_u32_u16(temp12.val[]);
temp16.val[]= vreinterpret_u32_u16(temp12.val[]);
最后,再做一次基于uint32x2_t的转置
temp17=vtrn_u32(temp15.val[],temp13.val[]);
temp18=vtrn_u32(temp15.val[],temp13.val[]);
temp19=vtrn_u32(temp16.val[],temp14.val[]);
temp20=vtrn_u32(temp16.val[],temp14.val[]);
最后的最后,还需要对各个寄存器中存储的值重新排列一遍,并转换回最初的uint8x8_t
temp1.val[]= vreinterpret_u8_u32(temp17.val[]);
temp1.val[]= vreinterpret_u8_u32(temp19.val[]);
temp2.val[]= vreinterpret_u8_u32(temp18.val[]);
temp2.val[]= vreinterpret_u8_u32(temp20.val[]);
temp3.val[]= vreinterpret_u8_u32(temp17.val[]);
temp3.val[]= vreinterpret_u8_u32(temp19.val[]);
temp4.val[]= vreinterpret_u8_u32(temp18.val[]);
temp4.val[]= vreinterpret_u8_u32(temp20.val[]);
大功告成!此时的子矩阵已经被顺时针旋转了90度,接下来,只要将其复制到输出矩阵的正确位置即可。
几点说明
1.为什么这么做可以旋转矩阵:
NEON提供的专置函数相当于对2×2的小矩阵进行专置,因此利用这个特性,可以对更大的矩阵进行旋转。其实自己按照我说的步骤,画个矩阵,自己做一下,就明白了。也不一定用8×8的,4×4的就能说明问题,当然4×4比8×8的要简单。
2.怎样得到正确位置:
这个还是自己思考一下吧,不难,假设某元素在输入矩阵的位置是(i,j),那么在输出的旋转90度的矩阵中的位置和i,j是相关的。
利用neon技术对矩阵旋转进行加速的更多相关文章
- 利用neon技术对矩阵旋转进行加速(2)
上次介绍的是顺时针旋转90度,最近用到了180度和270度,在这里记录一下. 1.利用neon技术将矩阵顺时针旋转180度: 顺时针旋转180度比顺时针旋转90度容易很多,如下图 A1 A2 A3 A ...
- 利用Cayley-Hamilton theorem 优化矩阵线性递推
平时有关线性递推的题,很多都可以利用矩阵乘法来解决. 时间复杂度一般是O(K3logn)因此对矩阵的规模限制比较大. 下面介绍一种利用利用Cayley-Hamilton theorem加速矩阵乘法的方 ...
- 利用Hadoop实现超大矩阵相乘之我见(一)
前记 最近,公司一位挺优秀的总务离职,欢送宴上,她对我说“你是一位挺优秀的程序员”,刚说完,立马道歉说“对不起,我说你是程序员是不是侮辱你了?”我挺诧异,程序员现在是很低端,很被人瞧不起的工作吗?或许 ...
- [.net 面向对象程序设计进阶] (20) 反射(Reflection)(上)利用反射技术实现动态编程
[.net 面向对象程序设计进阶] (20) 反射(Reflection)(上)利用反射技术实现动态编程 本节导读:本节主要介绍什么是.NET反射特性,.NET反射能为我们做些什么,最后介绍几种常用的 ...
- 利用Hadoop实现超大矩阵相乘之我见(二)
前文 在<利用Hadoop实现超大矩阵相乘之我见(一)>中我们所介绍的方法有着“计算过程中文件占用存储空间大”这个缺陷,本文中我们着重解决这个问题. 矩阵相乘计算思想 传统的矩阵相乘方法为 ...
- VC中利用多线程技术实现线程之间的通信
当前流行的Windows操作系统能同时运行几个程序(独立运行的程序又称之为进程),对于同一个程序,它又可以分成若干个独立的执行流,我们称之为线程,线程提供了多任务处理的能力.用进程和线程的观点来研究软 ...
- [LeetCode]Rotate Image(矩阵旋转)
48. Rotate Image Total Accepted: 69437 Total Submissions: 198781 Difficulty: Medium You are give ...
- 计蒜客模拟赛D1T1 蒜头君打地鼠:矩阵旋转+二维前缀和
题目链接:https://nanti.jisuanke.com/t/16445 题意: 给你一个n*n大小的01矩阵,和一个k*k大小的锤子,锤子只能斜着砸,问只砸一次最多能砸到多少个1. 题解: 将 ...
- HDU 5950 - Recursive sequence - [矩阵快速幂加速递推][2016ACM/ICPC亚洲区沈阳站 Problem C]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5950 Farmer John likes to play mathematics games with ...
随机推荐
- 再论FreeRTOS中的configTOTAL_HEAP_SIZE
关于任务栈和系统栈的基础知识,可以参考之前的随笔.(点击这里) 这里再次说明:#define configTOTAL_HEAP_SIZE ( ( size_t ) ( 17 * 1024 ) ) 这个 ...
- Sublime Text2/3怎样在Mac OSX中配置CTags插件
参考地址: http://jingyan.baidu.com/article/48206aeafba820216ad6b3f5.html
- 浅谈C#中的深拷贝(DeepCopy)与浅拷贝(MemberwiseClone)
场景:MVVM模式中数据双向绑定,想实现编辑.保存.撤销操作时也双向绑定了,不能实现撤销操作. 后来通过搜索找到了继承IEditableObject接口实现撤销操作,但是对其中使用了Memberwis ...
- WPF重写Button样式
首先指定OverridesDefaultStyle属性为True: 然后添加样式: 重写ControlTemplate: <Window.Resources> <Style x:Ke ...
- am335x Lan8710a 双网口配置
一. 经过调试, LAN8710A在 am335x 上面需要使用 GMII的模式,设备树 pin mux配置如下: // 下面是工作模式的配置,在睡眠模式下是配成GPIO模式 162 cpsw_def ...
- [serial]基于select/poll/epoll的串口操作
转自:http://www.cnblogs.com/darryo/p/selectpollepoll-on-serial-port.html In this article, I will use t ...
- shell常用命令大全
目录: 一.文件目录类命令 二.文件压缩和归档类命令 三.系统状态类命令 四.网络类命令 五.其他 一.文件目录类命令 1.查看联机帮助信息. man命令.#man ls info命令. #info ...
- python-opencv 图像二值化,自适应阈值处理
定义:图像的二值化,就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的只有黑和白的视觉效果. 一幅图像包括目标物体.背景还有噪声,要想从多值的数字图像中直接提取出目标物体,常用 ...
- JVM垃圾回收算法(最全)
JVM垃圾回收算法(最全) 下面是JVM虚拟机运行时的内存模型: 1.方法区 Perm(永久代.非堆) 2.虚拟机栈 3.本地方法栈 (Native方法) 4.堆 5.程序计数器 1 首先的问题是:j ...
- android 编译错误 Error:(1, 0) Plugin with id 'com.android.application' not found.
在导入一个项目时,由于它本身的gradle版本比较高,你试用比较旧版本的gradle时就报出Plugin with id 'com.android.application' not found.的错误 ...