chapter02 PCA主成分分析在手写数字识别分类的应用
#coding=utf8
# 导入numpy工具包。
import numpy as np
# 导入pandas用于数据分析。
import pandas as pd
from sklearn.metrics import classification_report
# 从sklearn.decomposition导入PCA。
from sklearn.decomposition import PCA
# 从互联网读入手写体图片识别任务的训练数据,存储在变量digits_train中。
digits_train = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tra', header=None)
# 从互联网读入手写体图片识别任务的测试数据,存储在变量digits_test中。
digits_test = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tes', header=None)
# 对训练数据、测试数据进行特征向量(图片像素)与分类目标的分隔。
X_train = digits_train[np.arange(64)]
y_train = digits_train[64]
X_test = digits_test[np.arange(64)]
y_test = digits_test[64]
# 导入基于线性核的支持向量机分类器。
from sklearn.svm import LinearSVC
# 使用默认配置初始化LinearSVC,对原始64维像素特征的训练数据进行建模,并在测试数据上做出预测,存储在y_predict中。
svc = LinearSVC()
svc.fit(X_train, y_train)
y_predict = svc.predict(X_test)
# 使用PCA将原64维的图像数据压缩到20个维度。
estimator = PCA(n_components=20)
# 利用训练特征决定(fit)20个正交维度的方向,并转化(transform)原训练特征。
pca_X_train = estimator.fit_transform(X_train)
# 测试特征也按照上述的20个正交维度方向进行转化(transform)。
pca_X_test = estimator.transform(X_test)
# 使用默认配置初始化LinearSVC,对压缩过后的20维特征的训练数据进行建模,并在测试数据上做出预测,存储在pca_y_predict中。
pca_svc = LinearSVC()
pca_svc.fit(pca_X_train, y_train)
pca_y_predict = pca_svc.predict(pca_X_test)
# 对使用原始图像高维像素特征训练的支持向量机分类器的性能作出评估。
print svc.score(X_test, y_test)
print classification_report(y_test, y_predict, target_names=np.arange(10).astype(str))
# 对使用PCA压缩重建的低维图像特征训练的支持向量机分类器的性能作出评估。
print pca_svc.score(pca_X_test, y_test)
print classification_report(y_test, pca_y_predict, target_names=np.arange(10).astype(str))
结果:
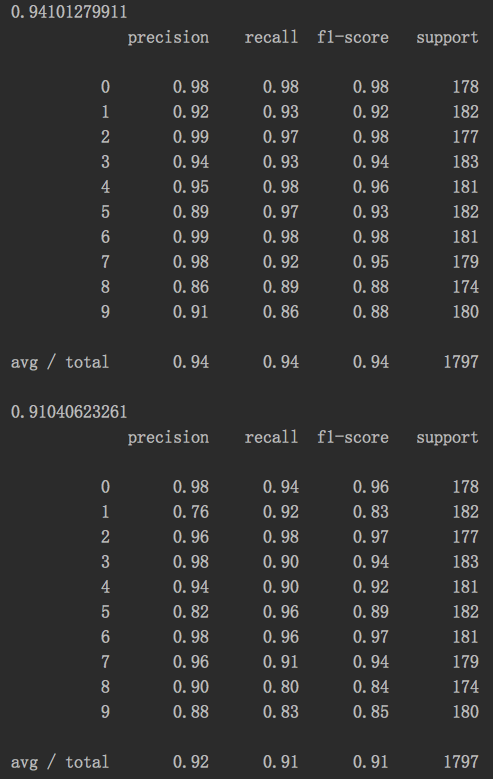
分析:虽然损失了%3的预测准确性,但是相比于原来的64维特征,使用PCA压缩并降低了68.75%的维度,能改节省大量的训练时间,在保持数据多样性的基础上,规避掉了大量特征冗余和噪声。
chapter02 PCA主成分分析在手写数字识别分类的应用的更多相关文章
- kaggle 实战 (1): PCA + KNN 手写数字识别
文章目录 加载package read data PCA 降维探索 选择50维度, 拆分数据为训练集,测试机 KNN PCA降维和K值筛选 分析k & 维度 vs 精度 预测 生成提交文件 本 ...
- 【Keras篇】---利用keras改写VGG16经典模型在手写数字识别体中的应用
一.前述 VGG16是由16层神经网络构成的经典模型,包括多层卷积,多层全连接层,一般我们改写的时候卷积层基本不动,全连接层从后面几层依次向前改写,因为先改参数较小的. 二.具体 1.因为本文中代码需 ...
- 基于卷积神经网络的手写数字识别分类(Tensorflow)
import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_dat ...
- MindSpore手写数字识别初体验,深度学习也没那么神秘嘛
摘要:想了解深度学习却又无从下手,不如从手写数字识别模型训练开始吧! 深度学习作为机器学习分支之一,应用日益广泛.语音识别.自动机器翻译.即时视觉翻译.刷脸支付.人脸考勤--不知不觉,深度学习已经渗入 ...
- 机器学习框架ML.NET学习笔记【4】多元分类之手写数字识别
一.问题与解决方案 通过多元分类算法进行手写数字识别,手写数字的图片分辨率为8*8的灰度图片.已经预先进行过处理,读取了各像素点的灰度值,并进行了标记. 其中第0列是序号(不参与运算).1-64列是像 ...
- 机器学习框架ML.NET学习笔记【5】多元分类之手写数字识别(续)
一.概述 上一篇文章我们利用ML.NET的多元分类算法实现了一个手写数字识别的例子,这个例子存在一个问题,就是输入的数据是预处理过的,很不直观,这次我们要直接通过图片来进行学习和判断.思路很简单,就是 ...
- Tensorflow之MNIST手写数字识别:分类问题(1)
一.MNIST数据集读取 one hot 独热编码独热编码是一种稀疏向量,其中:一个向量设为1,其他元素均设为0.独热编码常用于表示拥有有限个可能值的字符串或标识符优点: 1.将离散特征的取值扩展 ...
- Kaggle竞赛丨入门手写数字识别之KNN、CNN、降维
引言 这段时间来,看了西瓜书.蓝皮书,各种机器学习算法都有所了解,但在实践方面却缺乏相应的锻炼.于是我决定通过Kaggle这个平台来提升一下自己的应用能力,培养自己的数据分析能力. 我个人的计划是先从 ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
随机推荐
- C/C++UNION中包含STRUCT
测试环境:Win7x64,cn_visual_studio_2010_ultimate_x86_dvd_532347.iso,qt-opensource-windows-x86-msvc2010_op ...
- 5-11敏捷开发rails的章节: Rspec(使用方法) ,Slim(使用操作简介)
Rspec: test Slim :可以取代ERB的模版语言.(简单了解了以下,方便写代码,但我觉得不方便读.还是用原生的html) Webpack管理css: 不再使用app/assets/styl ...
- php数组转化为字符串
1.函数explode(); 这个是字符串转化为数组 , implode() ;这个是数组转化为字符串. $array=explode(separator,$string); $string=imp ...
- POJ 2352 treap
当年经常遇到这种题,愣是没做出来,好像那时不会线段树,也不会平衡树. 凭借一身蛮力来搞,倒是和那群朋友搞得开开心心. 题意: y从小到大,若y相同,x从小到大,这样给出一些坐标,求每个点覆盖的点个数. ...
- map和unordered_map
1.boost::unordered_map, 它与 stl::map的区别就是,stl::map是按照operator<比较判断元素是否相同,以及比较元素的大小,然后选择合适的位置插入到树中. ...
- 快照库MV不能成功刷新问题的解决
前几天,一个用户找到我,说他们的物化视图不能刷新了,这得从几天前主库的一次意外down机说起(另文说明),前几天,用户现场的一个中心库因某原因意外down掉了,当时短期内对中心库进行了重启修复,没有造 ...
- 小程序animation动画效果(小程序组件案例)
WXML <view class="container"> <view class="page-body"> <view clas ...
- linux-网络使用
linux网络的基本使用 "ifconfig" 查看已经被激活的网卡详细信息 "ifconfig eth0" 查看特定的网卡信息 [root@ssgao ~]# ...
- sql 的理解
sql的作用有: 1.筛选数据,连接表 2.数据的补充,连接表 3.数据的加减乘除的运算,+ - * / 4.数据的逻辑运输,比如case..when...,decode,nvl,ifnull.... ...
- SpingBoot三——基础架构
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:https://www.cnblogs.com/by-dream/p/10492073.html 继续上一节,为了更好的开发,现将 ...