06_Flume_interceptor_时间戳+Host
1、目标场景
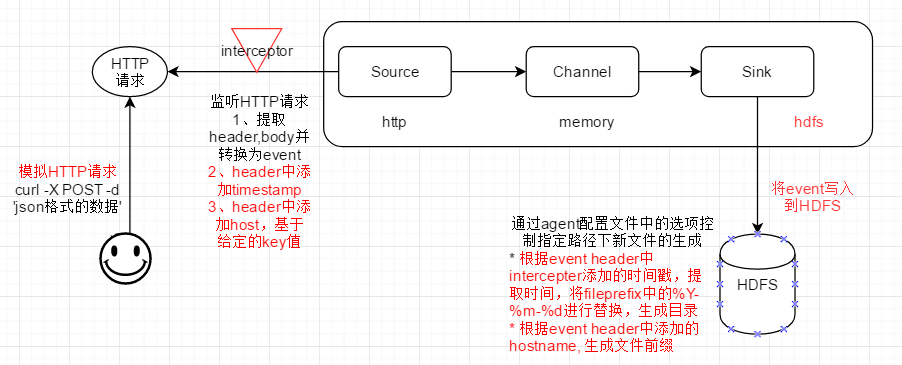
2、flume agent配置文件
# define agent name, source/sink/channel name
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # source,http,jsonhandler
a1.sources.r1.type = http
a1.sources.r1.bind = master
a1.sources.r1.port =
a1.sources.r1.handler = org.apache.flume.source.http.JSONHandler # 03 timestamp and host interceptors work before source
a1.sources.r1.interceptors = i1 i2 # 两个interceptor串联,依次作用于event
a1.sources.r1.interceptors.i1.type = timestamp
a1.sources.r1.interceptors.i1.preserveExisting = false a1.sources.r1.interceptors.i2.type = host
# flume event的头部将添加 “hostname”:实际主机名
a1.sources.r1.interceptors.i2.hostHeader = hostname # 指定key,value将填充为flume agent所在节点的主机名
a1.sources.r1.interceptors.i2.useIP = false # IP和主机名,二选一即可 # hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/%Y-%m-%d/ # hdfs sink将根据event header中的时间戳进行替换
# 和hostHeader的值保持一致,hdfs sink将提取event中key为hostnmae的值,基于该值创建文件名前缀
a1.sinks.k1.hdfs.filePrefix = %{hostname} # hdfs sink将根据event header中的hostnmae对应的value进行替换
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval =
a1.sinks.k1.hdfs.rollCount =
a1.sinks.k1.hdfs.rollSize = # channel,memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # bind source,sink to channel
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1
3、验证timestamp+host interceptor
验证思路:
1)先将interceptor作用后的event,通过logger sink打印到console,验证header是否正常添加
2)修改sink为hdfs, 观察目录和文件的名称是否能够按照预期创建(时间戳-目录,hostname-文件前缀)
验证过程:
1)发送header为空的http请求,logger sink打印event到终端,观察event header中是否被添加了timestamp以及hostname

2)ogger打印到console的event,header发生了变化

3)修改sink为hdfs, 观察HDFS的目录名(时间戳)和文件前缀(hostnme)
*目录名被正常替换(基于event header中的时间戳)

*文件前缀被正常替换(基于event header中的hostname:实际主机名)

* 文件内容被写入为event的body

06_Flume_interceptor_时间戳+Host的更多相关文章
- kafka笔记-Kafka在zookeeper中的存储结构【转】
参考链接:apache kafka系列之在zookeeper中存储结构 http://blog.csdn.net/lizhitao/article/details/23744675 1.topic注 ...
- kafka在zookeeper中的存储结构
参考site:http://kafka.apache.org/documentation.html#impl_zookeeper 1.zookeeper客户端相关命令 在确保zookeeper服务启动 ...
- 快速搭建日志系统——ELK STACK
什么是ELK STACK ELK Stack是Elasticserach.Logstash.Kibana三种工具组合而成的一个日志解决方案.ELK可以将我们的系统日志.访问日志.运行日志.错误日志等进 ...
- flume组件汇总 source、sink、channel
Flume Source Source类型 说明 Avro Source 支持Avro协议(实际上是Avro RPC),内置支持 Thrift Source 支持Thrift协议,内置支持 Exec ...
- apache kafka系列之在zookeeper中存储结构
1.topic注册信息 /brokers/topics/[topic] : 存储某个topic的partitions所有分配信息 Schema: { "version": ...
- Kafka学习之路 (五)Kafka在zookeeper中的存储
一.Kafka在zookeeper中存储结构图 二.分析 2.1 topic注册信息 /brokers/topics/[topic] : 存储某个topic的partitions所有分配信息 [zk: ...
- kafka在zookeeper中存储结构
1.topic注册信息 /brokers/topics/[topic] : 存储某个topic的partitions所有分配信息 Schema: { "version": ...
- Kafka(四)Kafka在zookeeper中的存储
一 Kafka在zookeeper中存储结构图 二 分析 2.1 topic注册信息 /brokers/topics/[topic] : 存储某个topic的partitions所有分配信息 [zk: ...
- tcpdump学习笔记
简介 简单的说,tcpdump就是一个抓包工具,类似Wireshark. tcpdump可以根据使用者的定义过滤/截取网络上的数据包,并进行分析.tcpdump可以将数据包的头部完全接 ...
随机推荐
- Kylin安装问题--/home/hadoop-2.5.1/contrib/capacity-scheduler/.jar (No such file or directory)
WARNING: Failed to process JAR [jar:file:/home/hadoop-2.5.1/contrib/capacity-scheduler/.jar!/] for T ...
- [sql]mysql管理手头手册,多对多sql逻辑
各类dbms排名 cs模型 mysql字符集设置 查看存储引擎,字符集 show variables like '%storage_engine%'; show VARIABLES like '%ma ...
- Python随机数生成方法
假设你对在Python生成随机数与random模块中最经常使用的几个函数的关系与不懂之处.以下的文章就是对Python生成随机数与random模块中最经常使用的几个函数的关系,希望你会有所收获,以下就 ...
- Python安装常见问题(1):zipimport.ZipImportError: can't decompress data
在CentOS以及其他的Linux系统中遇到安装包安装错误的原因,大多数都是因为缺少依赖包导致的,所以对于错误:zipimport.ZipImportError: can’t decompress d ...
- [LeetCode] 836. Rectangle Overlap_Easy
A rectangle is represented as a list [x1, y1, x2, y2], where (x1, y1) are the coordinates of its bot ...
- [LeetCode] 680. Valid Palindrome II_Easy tag: Two Pointers
Given a non-empty string s, you may delete at most one character. Judge whether you can make it a pa ...
- 把 ElasticSearch 当成是 NoSQL 数据库
Elasticsearch 可以被当成一个 “NoSQL”-数据库来使用么? NoSQL 意味着在不同的环境下存在不同的东西, 而erestingly 它并不是真的跟 SQL 有啥关系. 我们开始只会 ...
- VUE滚动条插件——vue-happy-scroll
最近自己在自学vue2.0,然后就自己摸索做一个简单的后台管理系统,在做的过程中,总感觉不同浏览器自带的滚动条样式不统一,也很难看,所以就在网上找一些使用vue的滚动条插件.最开始用的是Easy-sc ...
- sql server中批量插入与更新两种解决方案分享(存储过程)
转自http://www.shangxueba.com/jingyan/1940447.html 1.游标方式 SET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONG ...
- Amaze UI JS 气泡弹出
http://amazeui.org/javascript/popover?_ver=2.x