吴恩达机器学习CS229课程笔记学习
监督学习(supervised learning)
假设我们有一个数据集(dataset),给出居住面积和房价的关系如下:
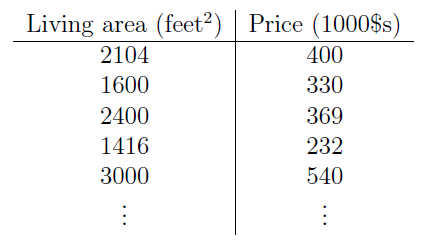
我们以居住面积为横坐标,房价为纵坐标,组成数据点,如(2104, 400),并把这些数据点描到坐标系中,如下:
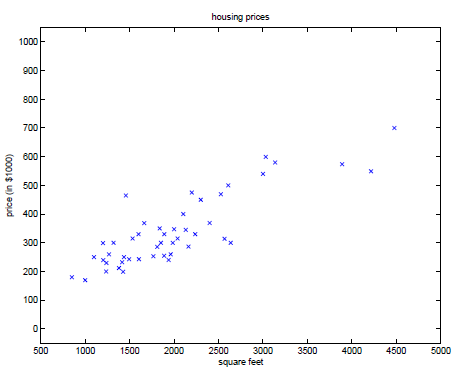
由这些数据,我们怎么才能预测(predict)其他房价呢?其中房价作为居住面积的函数。
为了方便描述,我们用x(i)表示输入变量(即居住面积),也叫做输入特征(features);同时,用y(i)表示输出(即房价),也叫做目标(target)变量。有序对 (x(i), y(i))叫做一个训练样本点(training example);我们用来学习(learn)的数据集,包含m个样本点,也叫做训练集(training set),表示为{(x(i), y(i)); i=1,...,m}。其中上标(i)表示样本点在训练集中的索引,跟指数没关系。另外,我们用X表示输入变量的取值空间,Y表示输出的取值空间,在本文中,X=Y=R。
我们的目的就是学习出一个函数h: X->Y,使得h(x)能够很好的预测y,即|h(x)-y|越小越好。由于历史原因,函数h也叫做假设(hypothesis)。整个流程形象化描述下:
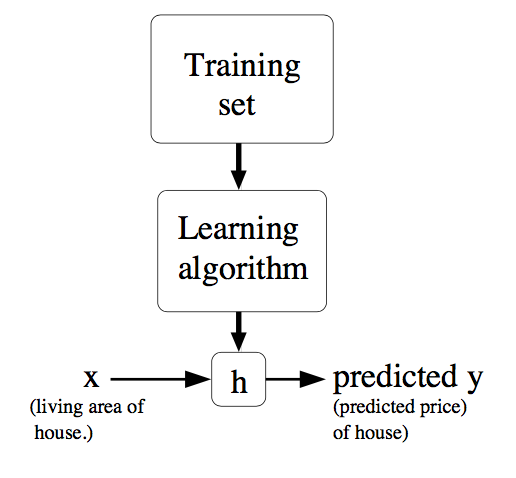
当我们想要预测的目标变量是连续的(continuous),这种学习问题被称之为回归(regression);而离散(discrete)时,则叫做分类(classification)。
线性回归(linear regression)
为了让上面的问题更加一般化,假设我们除了居住面积和房价,还知道房间个数,如下:
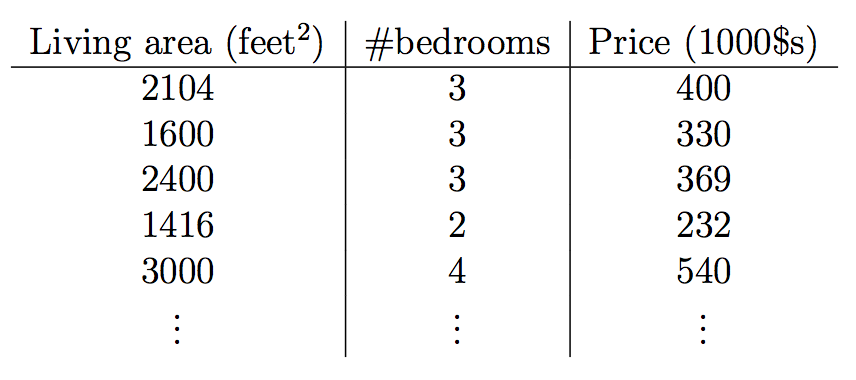
这样,x就是2维空间R2中的向量。x1(i)表示训练集中第i个房子的居住面积,而x2(i)就是它的房间个数。
学习之前,我们需要先决定函数h的表达式。最原始的想法就是,用x的线性函数来拟合(approximate)y。如下:
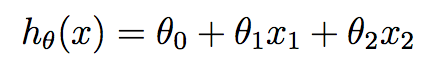
其中,θi 是参数,也叫权值(weight)。在不会引起误解的情况下,我们通常把hθ(x)中的下标θ去掉,简单表示为h(x)。进一步地,我们令x0=1(即截距),使得:
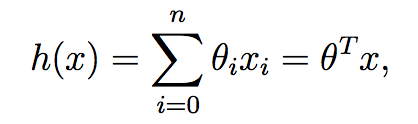
上式中,我们把θ和x都看做向量,这里其实是行向量,θT是θ的转置(即对应的列向量)。这里之所以要转成列向量,是因为要把两个向量的数量积看做是两个矩阵相乘。
有了函数表达式,接下来就是要利用训练集把参数θ学习出来。为此,我们定义代价函数(cost function)如下:
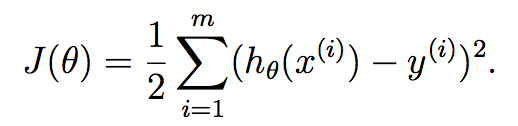
为什么这样定义代价函数呢?如果以前看过最小二乘法(least-squres),就会很熟悉上式。
LMS(Least Mean Square,最小均方)算法
我们需要找出使得代价J(θ)最小的θ。为此,我们估算一个θ的初始值,并不断改变它使得J(θ)更小,直到J(θ)不能再小。具体做法是利用梯度下降(gradient descent)算法,给θ赋一个初始值,然后按照如下表达式不断更新:
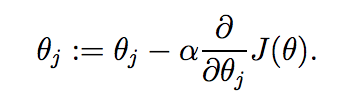
上式更新对θ向量的每个分量θj(j=0,...,n)是同时进行的,其中α叫做学习率(learning rate)。 接下来,我们需要解出右边的偏导(partial derivative),不失一般性地,先假设训练集中只有一个样本(x, y),这样,我们就可以忽略J(θ)中的累加运算,得到如下计算过程,这里需要熟悉导数运算法则,另外,求导的关键在于,对谁求导,谁就是变量,其他都是常量:
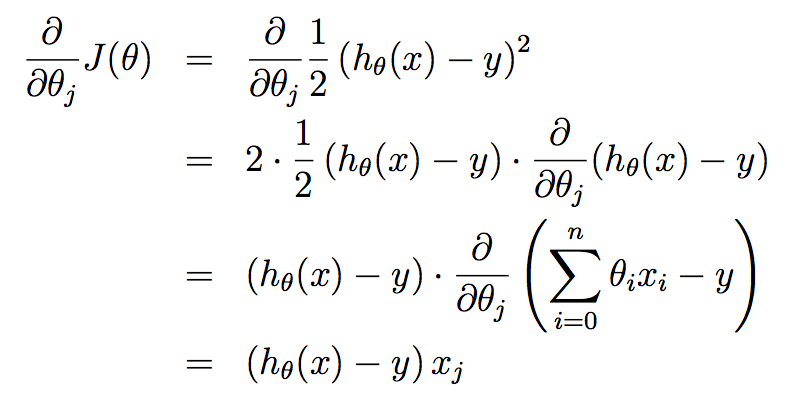
把计算后的偏导代回原式,就可以得到如下更新规则(即LMS更新规则),也叫Widrow-Hoff学习规则:
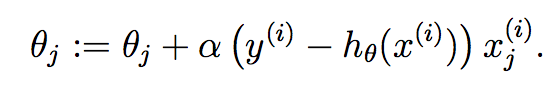
从上式更新规则可以看出,θj的更新增量α(y(i)-hθ(x(i)))xj(i)跟y(i)-hθ(x(i))成正比。通俗来讲就是,当预测值hθ(x(i))接近真实值y(i),即误差(error)越小时,参数θj需要做出的更新越小,反之同理。上述更新规则是通过一个样本计算出来的,推广到m个样本呢?有两种方法,第一种就是把之前的累加运算补回来(因为和的导数等于导数的和),如下:
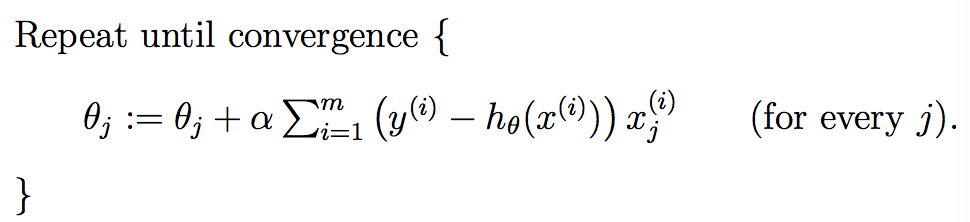
批量梯度下降(batch gradient descent)。
标准方程(normal equations)
矩阵微分(matrix derivatives)
分类和逻辑回归
接下来,我们看看二元分类(binary classification)问题,即预测值y=0或1。0也叫负类(negative class),1则叫正类(positive class)。二元分类中用到的原理同样适用于多元分类。另外,样本(x(i), y(i))中的y(i)也叫做类标(label)。
sigmoid函数
广义线性模型(generalized linear models)
softmax回归
参数拟合(parameter fitting),对数似然(log-likelihood)
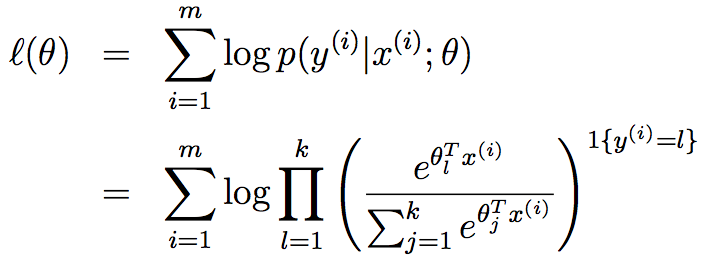
原文链接:
http://cs229.stanford.edu/notes/cs229-notes1.pdf
吴恩达机器学习CS229课程笔记学习的更多相关文章
- ML:吴恩达 机器学习 课程笔记(Week1~2)
吴恩达(Andrew Ng)机器学习课程:课程主页 由于博客编辑器有些不顺手,所有的课程笔记将全部以手写照片形式上传.有机会将在之后上传课程中各个ML算法实现的Octave版本. Linear Reg ...
- [吴恩达机器学习笔记]12支持向量机5SVM参数细节
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.5 SVM参数细节 标记点选取 标记点(landma ...
- [吴恩达机器学习笔记]12支持向量机3SVM大间距分类的数学解释
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.3 大间距分类背后的数学原理- Mathematic ...
- [吴恩达机器学习笔记]12支持向量机2 SVM的正则化参数和决策间距
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.2 大间距的直观理解- Large Margin I ...
- [吴恩达机器学习笔记]12支持向量机1从逻辑回归到SVM/SVM的损失函数
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.1 SVM损失函数 从逻辑回归到支持向量机 为了描述 ...
- [吴恩达机器学习笔记]11机器学习系统设计3-4/查全率/查准率/F1分数
11. 机器学习系统的设计 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 11.3 偏斜类的误差度量 Error Metr ...
- 吴恩达机器学习笔记22-正则化逻辑回归模型(Regularized Logistic Regression)
针对逻辑回归问题,我们在之前的课程已经学习过两种优化算法:我们首先学习了使用梯度下降法来优化代价函数
- Coursera 吴恩达 机器学习 学习笔记
Week 1 机器学习笔记(一)基本概念与单变量线性回归 Week 2 机器学习笔记(二)多元线性回归 机器学习作业(一)线性回归——Matlab实现 机器学习作业(一)线性回归——Python( ...
- ML:吴恩达 机器学习 课程笔记(Week7~8)
Support Vector Machines Unsupervised Learning Dimensionality Reduction
随机推荐
- 最优-scroll事件的监听实现
1. 背景和目标 前端在监听scroll这类高频率触发事件时,常常需要一个监听函数来实现监听和回调处理.传统写法上利用setInterval或setTimeout来实现. 为了减小 CPU 开支,往往 ...
- Linux常用基本命令:grep-从文件或者管道中筛选匹配的行
grep命令 作用:从文本文件或管道数据流中筛选匹配的行及数据,配合正则表达式一起使用,功能更加强大. 格式: grep [options] [pattern] [file] 1,匹配包含" ...
- 4个错误使用JavaScript数组方法的案例
译者按: 做一个有追求的工程师,代码不是随便写的! 原文: Here's how you can make better use of JavaScript arrays 译者: Fundebug 为 ...
- Flask 中的 CBV 与上传文件
from flask import Flask, views, render_template, request app = Flask(__name__) app.config['DEBUG'] = ...
- JavaScript中的window对象的属性和方法;JavaScript中如何选取文档元素
一.window对象的属性和方法 ①setTimeout()方法用来实现一个函数在指定毫秒之后运行,该方法返回一个值,这个值可以传递给clearTimeout()用于取消这个函数的执行. ②setIn ...
- js-MediumGrade-base.js
// 1.JavaScript 中的类型包括 Number(数字) String(字符串) Boolean(布尔) Symbol(符号)(第六版新增) Object(对象) Function(函数) ...
- 项目启动时发生NOT found
一直想记录一下这个小问题 情景: 我昨晚美滋滋的做完功能,测了测没bug提交到git上之后就屁颠屁颠的回家了,结果今天早上来就失了智,git pull拉了一下代码后,一运行,我去,我的页面呢,页面上直 ...
- Android SDK Manager无法更新的解决方案
Android SDK Manager -> Tools -> Options HTTP Proxy Server:mirrors.neusoft.edu.cn HTTP Proxy Po ...
- (网页)20个JS 小技巧超级实用
转自CSDN: 1. 将彻底屏蔽鼠标右键 oncontextmenu=”window.event.returnValue=false”< table border oncontextmenu=r ...
- 上下文管理器——with语句的实现
前言 with语句的使用给我们带来了很多的便利,最常用的可能就是关闭一个文件,释放一把锁. 既然with语句这么好用,那我也想让我自己写的代码也能够使用with语句,该怎么实现? 下面具体介绍怎样实现 ...