InnoDB存储引擎概览
InnoDB存储引擎概览
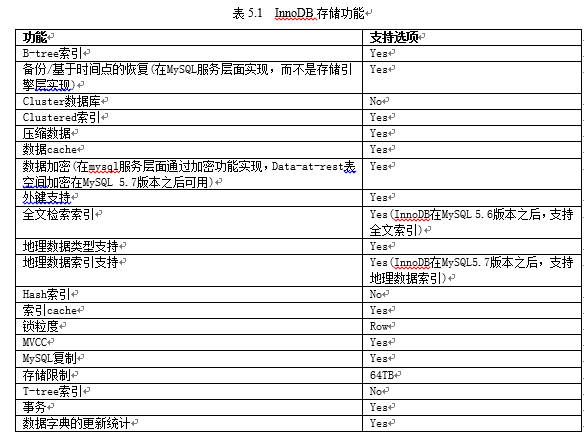
InnoDB存储引擎以其平衡了高可靠性和高性能性而闻名遐迩,在MySQL 8.0版本中,InnoDB存储引擎是默认的存储引擎。(历史追溯从MySQL 5.5.5版本开始,默认的存储引擎从MyISAM替换为Innodb)。当然,你也可以指定其他存储引擎,通过CREATE TABLE语句加上ENGINE=xxx指定特定的存储引擎,如表5.1所示。
Innodb的关键特性
- DML操作语句遵循ACID模型,具有事务的提交(commit)和回滚(rollback)的功能以及MySQL实例故障恢复。
- 支持行级锁(Row-level locking)和有着Oracle数据库风格的一致性读(consistent reads),用于提升多用户并发的性能。
- InnoDB表根据主键优化表的查询,每张InnoDB表有一个主键索引叫聚集索引(clusterd index)。索引可以通过主键查找数据,读取数据时使IO最小化,提高性能。
- 为维护数据的完整性,Innodb支持外键约束(foreign keys)。使用外键时,插入,更新和删除数据都会进行检查,确保不同表之间不会有不一致的结果产生。
为什么使用InnoDB存储引擎
使用InnoDB表的益处如下:
- 如果你的服务因为软件或者硬件问题导致宕机,不管当时数据库正在做何种操作,只需重新启动数据库,之后无需做任何特殊的操作。InnoDB crash recovery会自动commit那些最终确定修改的数据和撤销在进程中还没有来得及commit的数据。
- 当数据被访问的时候,InnoDB存储引擎有自己的一套buffer pool用来缓存数据表和索引数据。经常使用到的数据会直接从内存中读取。用于提高处理速度。作为一个独享的数据库服务器,可以设置物理内存的80%指定为buffer pool。
- 如果你分割一个关联数据到不同表中,为了保证其数据的完整性可以使用外键进行约束。当你修改和删除数据的时候,另外关联表的数据也会被自动地修改和删除。
- 如果在磁盘或者在内存的数据corrupted了,那么checksum机制会发出一个警报告知你数据bug了。
- 当你设计你的数据库的时候,对每一张表设计合适的主键,操作其相关的数据列时都会被自动地优化。当你在where,order by,group by子句中或者join操作中引用了主键,那么查询的速度是非常快的。
- change buffering的自动机制,可以在同一张表中进行多并发地读和写的操作。
- 性能增益并不仅局限于查询时间很长的SQL语句,当一遍遍地访问同一张表的同样数据的时候,自适应的hash索引会接管这种查询,使它们的查找更为迅速。
- 你可以压缩数据表和相关索引。
- 你可以在较小影响性能的前提下,创建和删除索引。
- Truncate操作,在基于file-per-table的表空间的情况下,速度非常快。
- InnoDB存储引擎对于存储BLOB和Text字段效率变得更高。
- 你可以通过INFORMATION_SCHEMA表监控存储引擎的内部工作原理。
- 你可以通过Performance Schema表监控存储引擎的性能信息。
- 你可以随意地让InnoDB存储引擎下的表和其他存储引擎的表在同一个SQL语句进行混合,例如:你可以通过join语句来联合来自InnoDB存储引擎的表和Memory存储引擎的表。
- 对于处理大数据量的时候,InnoDB能充分利用CPU的性能。
- 即使文件系统被限制只有为2GB的文件大小,InnoDB也能处理大量的数据。
InnoDB存储引擎的使用建议
使用InnoDB存储引擎的使用建议:
- 建立主键(Primary key):对于每一张数据表建立一个主键,可以选择最频繁查询的列,如果没有的话,可以使用自增ID。
- JOIN语句的性能优化建议:为了获得更好的性能,可以对需要join的列定义外键。亦或者对这些列相同的数据类型在每张表中。增加外键(foreign keys)可以对被引用的列能被索引,从而提高性能。同时外键还能保证数据完整性,当父表中没有相关的列,可以阻止子表插入数据。
- 关闭autocommit:避免增,删,改的事务自动提交,影响数据库的性能(生产环境下很少关闭此操作,让程序员通过start transaction控制事务比较少)。
- 多使用事务提交语句: 以START TRANSACTION和COMMIT的语句涵盖增,删,改的操作,避免频繁提交,提供数据库的性能。
- 不使用LOCK TABLE语句:Innodb存储引擎支持多用户并发操作,可以使用SELECT....FOR UPDATE语句获得一个排它锁,只锁你要修改的那条数据。支持行锁
- 开启 innodb_file_per_table参数:
innodb_file_per_table = 1开启后,每张表的数据和索引都会存入各自的数据文件中,文件名如:*.ibd文件,而不会都存储到一个系统表空间中。分散数据存储后,提高Innodb存储引擎的应用性能。
验证InnoDB为默认存储引擎
可通过SHOW ENGINES 语句来查看可用的MySQL存储引擎。查看默认的存储引擎。
语句如下:
(root@localhost) [(none)]> (root@localhost) [(none)]> SHOW ENGINES;
另外一个方法:
SELECT * FROM INFORMATION_SCHEMA.ENGINES;
InnoDB和ACID模型
ACID模型对于数据库设计来说,是一项基本准则。在业务数据非常重要的关键性应用具有一种可靠性方面的原则。MySQL的组件中,Innodb引擎是紧密贴合ACID模型进行开发设计的。所以它的数据不会由于软件或者硬件问题导致的异常问题而丢失。当你兼容了ACID原则,你就不需要对数据一致性校验和实例恢复这个问题进行重复造轮子。
在你拥有了额外软件的守卫保障和可靠性高的硬件保障。亦或者你的应用允许一点点的数据丢失和数据不一致的情况。那么你可以调整MySQL的参数来让它在ACID交易情况下提高更高的性能。ACID的特性,如图5.1所示。
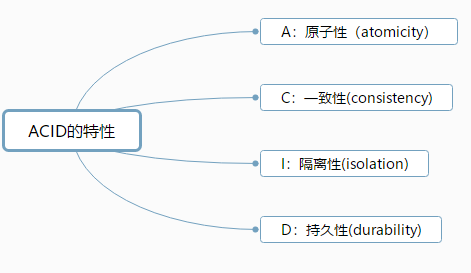
图5.1 ACID的特性
- 原子性
ACID中原子性的方面主要涉及InnoDB transactions的知识点。特性如下:- 自动提交设置(Autocommit)
- COMMIT语句
- ROLLBACK语句
- 来自于INFORMATION_SCHEMA表的数据操作
- 一致性
ACID中一致性的方面主要涉及InnoDB 的内部处理机制。可以在数据库实例崩溃的情况下恢复数据。相关特性如下:- InnoDB两次写(InnoDB doublewrite buffer)
- InnoDB实例恢复(InnoDB crash recovery)
- 隔离性
ACID中隔离性的方面主要涉及InnoDB transactions,主要体现在隔离级别上面(isolation level)。相关特性如下:- 自动提交设置(Autocommit)
- SET ISOLATION LEVEL语句
- 在InnoDB Locking中有行级锁,在性能调优方面,
可以通过INFORMATION_SCHEMA表查看细节。
- 持久性
ACID中持久性的方面主要通过MySQL软件功能的配置。因为许多特性依赖于硬件本身的性能,例如:CPU,网络,存储。这是在采购硬件的时候,硬件厂商可以提供一个指导方针,超过了本书的讨论范围。相关的MySQL特性如下:- InooDB doublewrite buffer。可以通过innodb_doublewrite在配置文件进行配置,来决定是否启动此项功能
- 配置选项innodb_flush_log_at_trx_commit
- 配置选项sync_binlog
- 配置选项innodb_file_per_table
- 在存储设备中有写缓存区的,例如SSD和RAID磁盘阵列
- 在存储设备中有Battery-backed cache
- 在操作系统中,跑了MySQL数据库服务,特别是它支持fsync()系统调用
- 不间断UPS保护所有服务器和存储设备,不掉电。保护MySQL服务的正常运行和数据存储。
- 备份策略,通过脚本和异地备份保证数据的可用性。
- 特别是在分布式应用中,在两个数据中心的网路传输,保证MySQL某些特性功能能顺利运行,例如MySQL Replication
InnoDB多版本控制(Multi-Versioning)
- InnoDB多版本控制与机理介绍
InnoDB是一个多版本控制的存储引擎。它可以对已修改的行保留一个旧版本的数据信息。用于支持事务特性。例如:并发和数据回滚。这个信息保留在数据结构中的表空间中,这个表空间称之为rollback segment回滚段。(在Oracle中也有一种类似的数据结构)。
当事务需要回滚的时候,InnoDB会使用回滚段的信息,用于执行undo操作。对于某一行,InnoDB会用早前版本的信息来保障读一致性(consistent read)。 - 内部机理
MySQL数据中InnoDB存储引擎对于每一行会添加三个字段。每一个字段明细如下:- 一个6字节的DB_TRX_ID字段,用于指向最后一个事务的事务标识符。这个事务用于删除行或者插入行。当然,删除操作在内部机理中被视为更新操作一类。其中有一个特殊的位(bit)用来标识deleted标志。
- 一个7字节的DB_ROLL_PTR字段,称之为回滚指针(roll pointer)。用于把undo日志写入回滚段中。如果一个行被更新了,那么undo日志会记录必要的信息,用于重建被更新之前的行数据信息。
- 一个6字节的DB_ROW_ID字段,包含一个ROW ID。用于一个新行插入的时候单调递增。如果InnoDB自动继承了clutered索引,那么这个索引就包含了ROW ID值。否则,DB_ROW_ID是不会出现在任何索引之中的。
Undo日志在回滚段(rollback segment)中被分为两部分,一部分叫做插入undo日志(insert undo logs),另外一部分叫做更新undo日志(update undo logs)。插入undo日志只用于事务回滚,如事务一旦提交,那么日志就可以被丢弃。更新undo日志用在读一致性,InnoDB会指定一个数据快照,这个快照的构建来自于更新undo日志中数据行的早期版本。通过数据行早期版本的快照来保证读一致性,如果不需要这种事务数据保护的时候,这个日志可以被丢弃。
定期提交事务,这些事务只包括一致性读。否则的话,InnoDB不会丢弃更新undo日志,回滚段也许会增长的非常大,填满整个表空间。
一个undo日志的物理空间大小通常要小于相应的插入行或者更新行的数据大小。所以你可以使用这个信息来统计计算回滚段需要的空间。
在InnoDB多版本控制的架构下,当你执行delete的SQl语句去删除一行数据的时候,一个行的物理删除并不是马上执行。只要当对于删除类操作的更新undo日志被遗弃掉之后,InnoDB存储引擎会做出物理的删除行操作。这个删除操作称之为purge。这个purge的操作速度是非常快的和SQL语句执行删除操作的时间不分伯仲。
知识点备注:purge
是一种垃圾收集机制(garbage collection)的类型。这种垃圾收集机制通过一或多个后台进程管理控制(控制参数为innodb_purge_threads)并且周期性地运行。
Purge会解析和处理来自于历史列表中的undo日志页。对这些日志页(被之前的DELETE SQL语句删除的行)标记为deltetion的clustered和secondary索引日志记录,而且不再为MVCC和回滚所需要。Purge处理完之后会从历史列表中释放掉这些undo日志页。
如果你以相同的速率小批量的插入或者删除行。那么purge线程会开始滞后。数据表有由于“dead”数据行导致越来越大,导致所有的事情都与磁盘绑定从而非常地慢。在这种情况下,可以调节新行操作的阀门,来分配更多的资源给予purge线程。通过优化系统变量innodb_max_purge_lag。
InnoDB存储引擎概览的更多相关文章
- MySQL内核:InnoDB存储引擎 卷1
MySQL内核:InnoDB存储引擎卷1(MySQL领域Oracle ACE专家力作,众多MySQL Oracle ACE力捧,深入MySQL数据库内核源码分析,InnoDB内核开发与优化必备宝典) ...
- MySQL数据库和InnoDB存储引擎文件
参数文件 当MySQL示例启动时,数据库会先去读一个配置参数文件,用来寻找数据库的各种文件所在位置以及指定某些初始化参数,这些参数通常定义了某种内存结构有多大等.在默认情况下,MySQL实例会按照一定 ...
- 在MySQL的InnoDB存储引擎中count(*)函数的优化
写这篇文章之前已经看过了很多数据库方面的优化内容,大部分都是加索引.使用事务.要什么select什么等等.然而,只是停留在阅读的层面上,很少有实践,因为没有遇到真实的项目,一切都是纸上谈兵.实践是检验 ...
- MySQL InnoDB存储引擎
200 ? "200px" : this.width)!important;} --> 介绍 本篇文章是对Innodb存储引擎的概念进行一个整体的概括,innodb存储引擎的 ...
- [MySQL Reference Manual]14 InnoDB存储引擎
14 InnoDB存储引擎 14 InnoDB存储引擎 14.1 InnoDB说明 14.1.1 InnoDB作为默认存储引擎 14.1.1.1 存储引擎的趋势 14.1.1.2 InnoDB变成默认 ...
- myisam、innodb存储引擎比较
MYSQL表类型(存储引擎) 1.概述 MySQL数据库其中一个特性是它的存储引擎是插件式的.用户可以根据应用需要选择存储引擎.Mysql默认支持多种存储引擎,以适用各种不同的应用需要.默认情况下,创 ...
- Galera集群server.cnf参数调整--Innodb存储引擎内存相关参数(一)
在innodb引擎中,内存的组成主要有三部分:缓冲池(buffer pool),重做日志缓存(redo log buffer),额外的内存池(additional memory pool).
- innodb 存储引擎特性
使用独立表空间后,系统表空间存储什么内容呢? 1.innodb 数据字典信息 和存储引擎相关. frm 是服务器的数据字典和存储引擎无关. 2. undo 回滚段. 可以单独存储. ...
- mysql innodb存储引擎介绍
innodb存储引擎1.存储:数据目录.有配置参数为“ innodb_data_home_dir ” .“ innodb_data_file_path ” 和 “innodb_log_group_ho ...
随机推荐
- 【ElasticSearch】 安装
Elasticsearch简介 Elasticsearch 是一个开源的分布式 RESTful 搜索和分析引擎,能够解决越来越多不同的应用场景 官网地址:https://www.elastic.co ...
- web版ssh的使用
一.web_ssh版本安装使用 web_ssh源码:https://github.com/shellinabox/shellinabox 1)安装依赖包 yum install git openssl ...
- MFC字体样式和颜色设置
在编写MFC界面程序时,可能会使用不同大小或者颜色的字体,这里稍做记录. 使用方法 CFont *m_pFont;//创建新的字体 m_pFont = new CFont; m_pFont->C ...
- 用Rider写一个有IOC容器Autofac的.net core的程序
一:Autofac是一个和Java里的Spring IOC容器一样的东西,不过它确实没有Spring里的那么方便,主要是在于它没有提供足够的Api和扫描方式等等,不过优点是它比Spring要快很多,而 ...
- cf 700e(sam好题,线段树维护right)
代码参考:http://blog.csdn.net/qq_33229466/article/details/79140428 #include<iostream> #include< ...
- Service启动过程分析
Service是一种计算型组件,用于在后台执行一系列的计算任务.由于工作在后台,因此用户是无法直接感知到它的存在.Service组件和Activity组件略有不同,Activity组件只有一种运行模式 ...
- Django orm 实现批量插入数据
Django ORM 中的批量操作 在Hibenate中,通过批量提交SQL操作,部分地实现了数据库的批量操作.但在Django的ORM中的批量操作却要完美得多,真是一个惊喜. 数据模型定义 首先,定 ...
- H5内联视频
概述 微信上很多H5页面都会有会动的像视屏的页面,这样的效果很棒.从技术上来说,这个其实就是视屏,不过没有控制播放的按钮罢了.它们还有一个专业的名字--内联视频.下面我把自己对内联视屏的学习记录下来, ...
- process(进程)
进程 指的是执行中程序的一个实例(instance). 新进程由fork() 与 execve() 等系统调用起始,然后执行,直到下达exit()系统调用为止. 操作系统内核里,称为调度器(sched ...
- ffmpeg命令: 删除视频中不需要的音频流
1.ffprobe gf.mkv 查看 2.ffmpeg -i gf.mkv -map 0:0 -map 0:2 -vcodec copy -acodec copy out.mkv 注: -m ...