基于 redis 的分布式锁实现 Distributed locks with Redis debug 排查错误
小结:
1、
锁的实现方式,按照应用的实现架构,可能会有以下几种类型:
如果处理程序是单进程多线程的,在 python下,就可以使用 threading 模块的 Lock 对象来限制对共享变量的同步访问,实现线程安全。
单机多进程的情况,在 python 下,可以使用 multiprocessing 的 Lock 对象来处理。
多机多进程部署的情况,就得依赖一个第三方组件(存储锁对象)来实现一个分布式的同步锁了。
https://mp.weixin.qq.com/s/DL-d9V69paxN77V6V1PwXw
基于 redis 的分布式锁实现
云龙
资深运维开发工程师,负责游戏系统配置管理平台的设计和开发,目前专注于新 CMDB 系统的开发,平时也关注运维自动化,devops,python 开发等技术。
背景
CMDB 系统里面的机器数据会分为很多种类,比如系统服务数据,硬件数据,资产相关的数据,离线计算数据等,这些数据都可以认为是流数据,数据库里面呈现出来的某台机器的完整信息,就是该台机器对应的流数据合并后的结果。
在对数据流做合并处理时,我们采用了多进程多线程的机制来提高处理效率,但同时也会遇到多个线程同时对一台机器的信息进行读写,导致数据出现不一致的问题。
以某台机器为例,d 表示该机器的某种数据流,假设有 n 个数据源,理想的情况下,一台机器最终呈现的数据应该是 d1 + d2 + …+ dn,如下图:
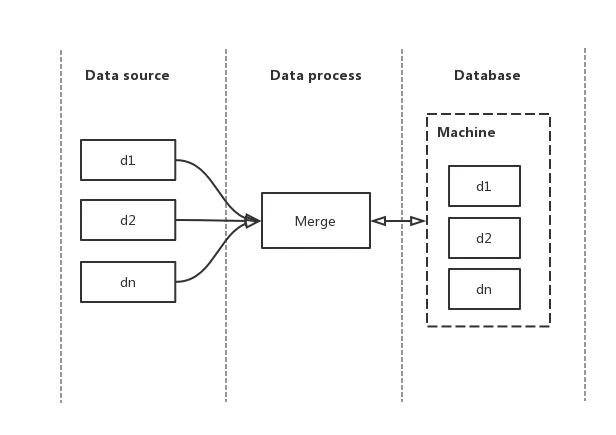
图 1-单线程合并数据
如果上图的 Merge 是单线程操作,数据库里面的结果是正确的,但是如果变成了多线程,即有多个线程同时对上图的 Machine 数据进行读写操作,是必然会出现数据不一致问题的,如下图所示:

图 2-多线程合并数据
假设某台机器(图中的 machine )在数据库的原始数据是 d0,上图的处理流程如下:
t1 时刻,有两个数据源的数据 d1,d2 分别到达数据处理层,主进程分配线程 Merge1 处理 d1,Merge2 处理 d2,两者又同时(假设还是 t1 )从数据库获取原始数据 d0
t2 时刻,Merge1 合并完 d0 和 d1 的数据,并将合并后的数据存到数据库,数据库的数据变成 d0 + d1
t3 时刻,Merge2 合并完 d0 和 d2 的数据,并将合并后的数据存到数据库,数据库的数据变成 d0 + d2
t1 到 t3,数据库最终的数据变成了 d0 + d2,数据源 d1 的数据消失,出现数据不一致问题。
方案探索
上面所列的问题,是由于多线程同时对某一个共享数据进行读写导致,我们只要找到一种方案,使得对共享数据的访问是同步的,即可解决该问题。当有某个线程或者进程已经访问了该数据,其他进程或者线程就必须等待其访问结束,才可拥有该共享数据的访问权(进入临界区)。最简单的方式,就是加个同步锁。
锁的实现方式,按照应用的实现架构,可能会有以下几种类型:
如果处理程序是单进程多线程的,在 python下,就可以使用 threading 模块的 Lock 对象来限制对共享变量的同步访问,实现线程安全。
单机多进程的情况,在 python 下,可以使用 multiprocessing 的 Lock 对象来处理。
多机多进程部署的情况,就得依赖一个第三方组件(存储锁对象)来实现一个分布式的同步锁了。
CMDB 系统目前是多机多进程多线程的处理机制,所以符合第三种方式。
分布式锁实现方式
目前主流的分布式锁实现方式有以下几种:
基于数据库来实现,如 mysql
基于缓存来实现,如 redis
基于 zookeeper 来实现
每种实现方式各有千秋,综合考量,我们最终决定使用 redis,主要原因是:
redis 是基于内存来操作,存取速度比数据库快,在高并发下,加锁之后的性能不会下降太多
redis 可以设置键值的生存时间(TTL)
redis 的使用方式简单,总体实现开销小
同时使用 redis 实现的分布锁还需要具备以下几个条件:
同一个时刻只能有一个线程占有锁,其他线程必须等待直到锁被释放
锁的操作必须满足原子性
不会发生死锁,例如已获得锁的线程在释放锁之前突然异常退出,导致其他线程会一直在循环等待锁被释放
锁的添加和释放必须由同一个线程来设置
分布式锁保持数据一致的原理
我们在图 2 的基础上,在 Data process 和 Database 之间加了一层锁,我们在 redis 中使用添加了一个 lock_key 来作为锁的标识,流程图如下:
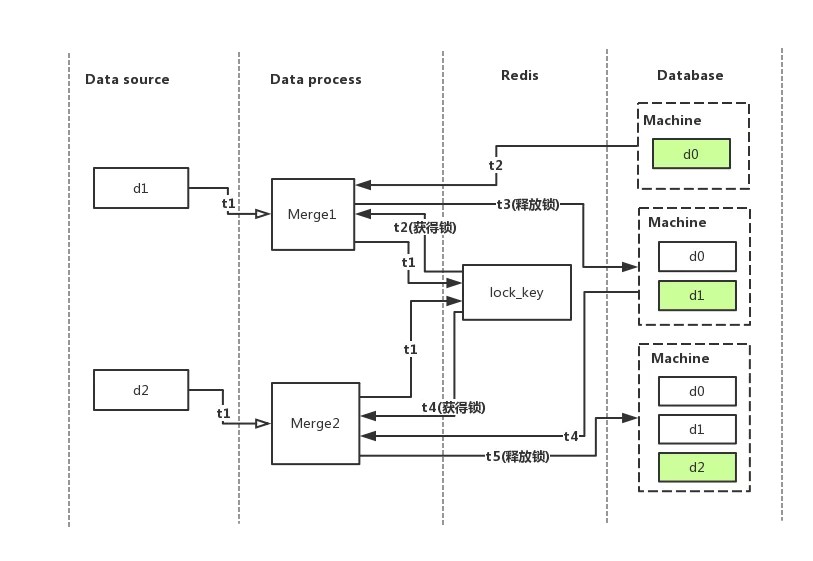
图 3-使用分布式锁合并数据
还是假设某台机器(图中的machine)在数据库的原始数据是 d0,上图的处理流程变成了:
t1 时刻,有两个数据源的数据 d1,d2 同时到达数据处理层,主进程分配了线程 Merge1 处理 d1,线程 Merge2 处理 d2,两者又同时尝试从 redis 获得锁
t2 时刻,Merge1 成功获得了锁,同时从数据库中加载 machine 的原始数据 d0,Merge2 循环等待 Merge1 释放锁
t3 时刻,Merge1 合并完数据,并将合并好的数据 d0 + d1 存放到数据库,最后释放锁
t4 时刻,Merge2 获得了锁,同时从数据库中加载machine的数据 d0 + d1
t5 时刻,Merge2 合并完数据,并将合并好的数据 d0 + d1 + d2 存放到数据库,最后释放锁
从以上可以看到保持数据一致的原理其实也不难,无非就是使用一个键值来使得多个线程对同一台机器的数据的读写是同步的,但是在实现的过程中,往往会忽视了分布式锁所要具备的某个条件,极端情况下,还是会出现数据不一致的问题。
实现过程
结合以上的三种锁条件,下面我们将给出几种实现方式,来观察如果任意一个条件不满足,test_key的结果是否符合我们的预期。在实现的过程中将使用同一份测试用例。如下:
# test.py
def increase(redis, lock, key):
# 获得锁
lock_value = lock.get_lock(key)
value = redis.get(key)
# 模拟实际情况下进行的某些耗时操作
time.sleep(0.1)
value += 1
redis.set(key, value)
thread_name = threading.current_thread().name
# 打印线程名和最新的值
print thread_name, new_value
# 释放锁
lock.del_lock(key, lock_value)
# 连接服务端
redis = RedisCli(REDIS_CACHE_HOST_LIST, REDIS_CACHE_MASTER_NAME)
lock = RedisLock(redis)
key = 'test_key'
thread_count = 10
redis.delete(key)
for i in xrange(thread_count):
thread = threading.Thread(target=increase, args=(redis, lock, key))
thread.start()
我们启用了多线程去对 redis 中的 test_key 的值进行自增操作,理想情况,test_key 的值应该等于线程的数量,比如开了 10 个线程,test_key的值最终应该是 10。
方式一:加锁操作非原子性
在这个版本中,当线程 A get(key) 的值为空时,set key 的值为 1,并返回,这表示线程 A 获得了锁,可以继续执行后面的操作,否则需要一直循环去获取锁,直到 key 的值再次为空,重新获得锁,执行任务完毕后释放锁。
代码如下:
class RedisLock(object):
def __init__(self, rediscli):
self.rediscli = rediscli
def get_lock_key(self, key):
lock_key = "lock_%s" % key
return lock_key
def get_lock(self, key):
lock_key = self.get_lock_key(key)
while True:
value = self.rediscli.get(lock_key)
if not value:
self.rediscli.set(lock_key, '1')
return True
time.sleep(0.01)
def del_lock(self, key, new_expire_time):
lock_key = self.get_lock_key(key)
return self.rediscli.delete(lock_key)
执行测试脚本,得到的结果如下:
# python test.py
Thread-1 1
Thread-5 2
Thread-2 2
Thread-6 3
Thread-7 3
Thread-4 3
Thread-9 4
Thread-8 5
Thread-10 5
Thread-3 5观察结果就发现,同时有多个线程输出的结果是一样的。乍一看上面加锁的代码逻辑似乎没啥问题,但是结果却事与愿违,原因是上面的代码 get(key) 和 set(key, value) 并不是原子性的,A 线程在 get(key) 的时候发现是空值,于是重新 set(key, value),但在 set 完成的前一刻,B 线程恰好 get(key) 的时候得到的还是空值,然后也顺利获得锁,导致数据被两个或多个线程同时修改,最后出现不一致,可以参考图2的过程。
方式二:使用 setnx 来实现
鉴于上面版本是由于命令不是原子性操作造成两个或多个线程同时获得锁的问题,这个版本改成使用 redis 的 setnx 命令来进行锁的查询和设置操作,setnx 即 set if not exists,顾名思义就是当key不存在的时候才设置 value,并返回 1,如果 key 已经存在,则不进行任何操作,返回 0。
代码改进如下:
def get_lock(self, key):
lock_key = self.get_lock_key(key)
while True:
value = self.rediscli.setnx(lock_key, 1)
if value:
return True
time.sleep(0.01)
测试结果:
Thread-1 1
Thread-4 2
Thread-2 3
Thread-3 4
Thread-7 5
Thread-6 6
Thread-5 7
Thread-8 8
Thread-9 9
Thread-10 10
结果是正确的,但是如果满足于此,还是会出问题的,比如假设 A 线程获得了锁后,由于某种异常原因导致线程 crash了,一直不释放锁呢?我们稍微改一下测试用例的 increase 函数,模拟某个线程在释放锁之前因为异常退出。
代码如下:
def increase(redis, lock, key):
thread_name = threading.current_thread().name
lock_value = lock.get_lock(key)
value = redis.get(key)
if not value:
value = 0
# 模拟实际情况下进行的某些耗时操作
time.sleep(0.1)
value = int(value) + 1
redis.set(key, value)
print thread_name, value
# 模拟线程2异常退出
if thread_name == 'Thread-2':
print 'Thread-2 crash..'
import sys
sys.exit(1)
lock.del_lock(key, lock_value)
测试结果:
Thread-2 3
Thread-2 crash..
Thread-7 waiting..
Thread-3 waiting..
Thread-5 waiting..
Thread-4 waiting..
Thread-9 waiting..
Thread-6 waiting..
Thread-10 waiting..
这时候就有问题了,线程 2 crash 之后,后续的线程一直获取不了锁,便一直处于等待锁的状态,于是乎产生了死锁。如果数据是多线程处理的,比如每来一个数据就开一个线程去处理,那么堆积的线程会逐渐增多,最终可能会导致系统崩溃。
产生锁的线程由于异常退出,没法释放锁,我们可能就得曲线救国,找其他方式来释放锁了。既然我们使用了 redis 来实现分布式锁,何不利用 redis 的 ttl 机制呢,给锁加上过期时间,不就可以解决了上面的问题了吗?
但如果是这样的方式处理,使用 redis expire 来设置锁的过期时间:
value = self.rediscli.setnx(lock_key, '1')
if value:
self.rediscli.expire(lock_key, 5)
貌似又回到了第一版的操作命令不是原子性的问题,查看redis手册,好在从 redis 2.6.12 版本开始,set 命令就已经支持了 nx 和 expire 功能。
改进如下:
def get_lock(self, key, timeout=3):
lock_key = self.get_lock_key(key)
while True:
value = self.rediscli.set(lock_key, '1', nx=True, ex=timeout)
if value:
return True
time.sleep(0.01)
测试结果如下:
Thread-1 1
Thread-9 2
Thread-6 3
Thread-2 4
Thread-4 5
Thread-5 6
Thread-8 7
Thread-3 8
Thread-7 9
Thread-10 10
模拟线程 crash:
Thread-1 1
Thread-2 2
Thread-2 crash..
Thread-10 3
Thread-7 4
Thread-4 5
Thread-8 6
Thread-3 7
Thread-9 8
Thread-6 9
Thread-5 10
结果正确,线程 2 在 crash 后,其他线程在等待,直到锁过期。(这里不好演示,感兴趣的同学可以自己试试)
进行到这里,似乎已经可以解决数据不一致的问题了,但在欢喜之余,不妨多想想会不会出现其他问题。比如假设 A 进程的逻辑还没处理完,但是锁由于过期时间到了,导致锁自动释放掉,这时 B 线程获得了锁,开始处理 B 的逻辑,然后 A 进程的逻辑处理完了,就把 B 进程的锁给删除了呢?这也是下面要讲的问题。
方式三:锁的生成和删除必须是同一个线程
我们先把测试用例改成下面这样:
def increase(redis, lock, key):
thread_name = threading.current_thread().name
# 设置锁的过期时间为2s
lock_value = lock.get_lock(key, thread_name, timeout=2)
value = redis.get(key)
if not value:
value = 0
# 模拟实际情况下进行的某些耗时操作, 且执行时间大于锁过期的时间
time.sleep(2.5)
value = int(value) + 1
print thread_name, value
redis.set(key, value)
lock.del_lock(key, lock_value)
在以上的例子,我们让线程的执行时间大于锁的过期时间,导致锁到期自动释放。
测试结果:
Thread-1 1
Thread-3 1
Thread-2 2
Thread-9 2
Thread-5 3
Thread-7 3
Thread-6 4
Thread-4 4
Thread-8 5
Thread-10 5
从以上结果可以看出,由于每个线程的执行时间大于锁的过期时间,当线程的任务还没执行完时,锁已经自动释放,使得下一个线程获得了锁,而后下一个线程的锁被上一个执行完了的线程删掉或者也是自动释放(具体要看线程的执行时间和锁的释放时间),于是又产生了同一个数据被两个或多个线程同时修改的问题,导致数据出现不一致。
我们用四个线程,按照时间顺序画的流程图如下:
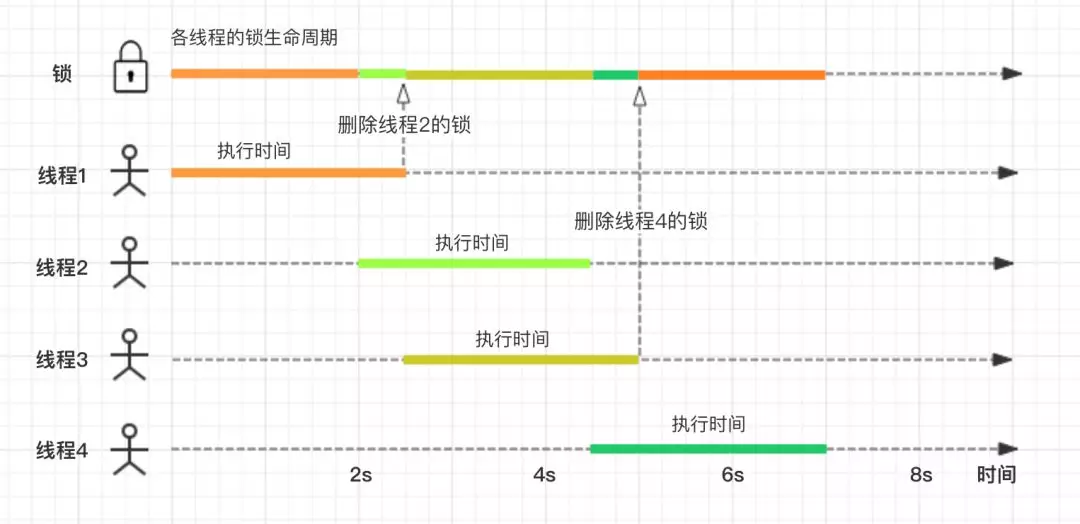
可以看到,在 2.5s 和 5s 的时刻,都产生了误删锁的情况。
既然这个现象是由于锁过期导致误删别人家的锁引发的,那我们就顺着这个思路,强制线程只能删除自己设置的锁。如果是这样,就得被每个线程的锁添加一个唯一标识了。看看上面的锁机制,我们每次添加锁的时候,都是给 lock_key 设为 1,无论是 key 还是 value,都不具备唯一性,如果把 key 设为每个线程唯一的,那在分布式系统中,得产生 N (等于总线程数)个 key 了 ,从直观性和维护性上来说,这都是不可取的,于是乎只能从 value 入手了。我们看到每个线程都可以取到一个唯一标识,即线程 ID,如果加上进程的 PID,以及机器的 IP,就可以构成一个线程锁的唯一标识了,如果还担心不够唯一,再打上一个时间戳了,于是乎,我们的分布式锁最终版就变成了以下这样:
class RedisLock(object):
def __init__(self, rediscli):
self.rediscli = rediscli.master
# ip 在实例化的时候就获取,避免过多访问DNS
self.ip = socket.gethostbyname(socket.gethostname())
self.pid = os.getpid()
def gen_lock_key(self, key):
lock_key = "lock_%s" % key
return lock_key
def gen_unique_value(self):
thread_name = threading.current_thread().name
time_now = time.time()
unique_value = "{0}-{1}-{2}-{3}".format(self.ip, self.pid, thread_name, time_now)
return unique_value
def get(self, key, timeout=3):
lock_key = self.gen_lock_key(key)
unique_value = self.gen_unique_value()
logger.info("unique value %s" % unique_value)
while True:
value = self.rediscli.set(lock_key, unique_value, nx=True, ex=timeout)
if value:
return unique_value
# 进入阻塞状态,避免一直消耗CPU
time.sleep(0.1)
def delete(self, key, value):
lock_key = self.gen_lock_key(key)
old_value = self.rediscli.get(lock_key)
if old_value == value:
return self.rediscli.delete(lock_key)
测试结果:
测试结果:
Thread-1 1
Thread-2 2
Thread-4 3
Thread-5 4
Thread-10 5
Thread-3 6
Thread-9 7
Thread-6 8
Thread-8 9
Thread-7 10
在测试一下锁过期,测试用例:
def increase(redis, lock, key):
thread_name = threading.current_thread().name
lock_value = lock.get_lock(key, timeout=1)
value = redis.get(key)
if not value:
value = 0
# 模拟实际情况下进行的某些耗时操作, 且执行时间大于锁过期的时间
time.sleep(3)
value = int(value) + 1
print thread_name, value
redis.set(key, value)
lock.del_lock(key, lock_value)
测试结果:
Thread-1 1
Thread-2 1
Thread-5 1
Thread-6 2
Thread-8 2
Thread-10 2
Thread-9 3
Thread-3 3
Thread-4 3
Thread-7 4
以上可以看出,问题没有得到解决。因为什么原因呢?以上我们设置值的唯一性只能确保线程不会误删其他线程产生的锁,进而出现连串的误删锁的情况,比如 A 删了 B 的锁,B 执行完删了 C 的锁 。使用 redis 的过期机制,只要业务的处理时间大于锁的过期时间,就没有一个很好的方式来避免由于锁过期导致其他线程同时占有锁的问题,所以需要熟悉业务的执行时间,来合理地设置锁的过期时间。
还需注意的一点是,以上的实现方式中,删除锁(del_lock)的操作不是原子性的,先是拿到锁,再判断锁的值是否相等,相等的话最后再删除锁,既然不是原子性的,就有可能存在这样一种极端情况:在判断的那一时刻,锁正好过期了,被其他线程占有了锁,那最后一步的删除,就可能会造成误删锁了。可以使用官方推荐的 Lua 脚本来确保原子性:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
但是只要锁的过期时间设置的足够合理,这个问题其实是可以忽略的,也可以说出现这种极端情况的概率是及其小的。毕竟,在我们优雅的 python 代码中,突然插入一段脚本,显得不是那么 pythonic 了。
总结
以上我们使用 redis 来实现一个分布式的同步锁,来保证数据的一致性,其特点是:
满足互斥性,同一个时刻只能有一个线程可以获取锁
利用 redis 的 ttl 来确保不会出现死锁,但同时也会带来由于锁过期引发的多线程同时占有锁的问题,需要我们合理设置锁的过期时间来避免
利用锁的唯一性来确保不会出现误删锁的情况
以上的方案中,我们是假设 redis 服务端是单集群且高可用的,忽视了以下的问题:如果某一时刻 redis master 节点发生了故障,集群中的某个 slave 节点变成 master 节点,这时候就可能出现原 master 节点上的锁没有及时同步到 slave 节点,导致其他线程同时获得锁。对于这个问题,可以参考 redis 官方推出的 redlock 算法,但是比较遗憾的是,该算法也没有很好地解决锁过期的问题。
https://redis.io/topics/distlock
基于 redis 的分布式锁实现 Distributed locks with Redis debug 排查错误的更多相关文章
- Redis++:Redis做分布式锁真的靠谱吗
Redis做分布式锁真的靠谱吗 Redis的分布式锁可以通过Lua进行实现,通过setnx和expire命令连用的方式 || 也可以使用高版本的方法同时设置失效时间,但是假如在以下情况下,就会造成无锁 ...
- 基于Redis的分布式锁真的安全吗?
说明: 我前段时间写了一篇用consul实现分布式锁,感觉理解的也不是很好,直到我看到了这2篇写分布式锁的讨论,真的是很佩服作者严谨的态度, 把这种分布式锁研究的这么透彻,作者这种技术态度真的值得我好 ...
- 基于Redis的分布式锁到底安全吗(下)?
2017-02-24 自从我写完这个话题的上半部分之后,就感觉头脑中出现了许多细小的声音,久久挥之不去.它们就像是在为了一些鸡毛蒜皮的小事而相互争吵个不停.的确,有关分布式的话题就是这样,琐碎异常,而 ...
- 基于redis 实现分布式锁(二)
https://blog.csdn.net/xiaolyuh123/article/details/78551345 分布式锁的解决方式 基于数据库表做乐观锁,用于分布式锁.(适用于小并发) 使用me ...
- 基于 Redis 做分布式锁
基于 REDIS 的 SETNX().EXPIRE() 方法做分布式锁 setnx() setnx 的含义就是 SET if Not Exists,其主要有两个参数 setnx(key, value) ...
- 基于Redis的分布式锁到底安全吗(上)?
基于Redis的分布式锁到底安全吗(上)? 2017-02-11 网上有关Redis分布式锁的文章可谓多如牛毛了,不信的话你可以拿关键词“Redis 分布式锁”随便到哪个搜索引擎上去搜索一下就知道了 ...
- 基于Redis的分布式锁安全性分析-转
基于Redis的分布式锁到底安全吗(上)? 2017-02-11 网上有关Redis分布式锁的文章可谓多如牛毛了,不信的话你可以拿关键词“Redis 分布式锁”随便到哪个搜索引擎上去搜索一下就知道了 ...
- 基于Redis的分布式锁和Redlock算法
1 前言 前面写了4篇Redis底层实现和工程架构相关文章,感兴趣的读者可以回顾一下: Redis面试热点之底层实现篇-1 Redis面试热点之底层实现篇-2 Redis面试热点之工程架构篇-1 Re ...
- 基于Redis的分布式锁设计
前言 基于Redis的分布式锁实现,原理很简单嘛:检测一下Key是否存在,不存在则Set Key,加锁成功,存在则加锁失败.对吗?这么简单吗? 如果你真这么想,那么你真的需要好好听我讲一下了.接下来, ...
随机推荐
- 【转】最近很火的 Safe Area 到底是什么
iOS 7 之后苹果给 UIViewController 引入了 topLayoutGuide 和 bottomLayoutGuide 两个属性来描述不希望被透明的状态栏或者导航栏遮挡的最高位置(st ...
- linux随机数生成
随机数多应用在密码的随机生成 #随机数生成 $RANDOM (1-32767) 11.内部系统变量($RANDOM) 1-32767 22. awk 'BEGIN{srand();print rand ...
- 【Android】解析Paint类中Xfermode的使用
Paint类提供了setXfermode(Xfermode xfermode)方法,Xfermode指明了原图像和目标图像的结合方式.谈到Xfermode就不得不谈它的派生类PorterDuffXfe ...
- Effective Java 第三版——88. 防御性地编写READOBJECT方法
Tips 书中的源代码地址:https://github.com/jbloch/effective-java-3e-source-code 注意,书中的有些代码里方法是基于Java 9 API中的,所 ...
- CentOS 7.5 安装KVM虚拟机(Linux)
1.认识理解KVM虚拟机 Kernel-based Virtual Machine的简称,是一个开源的系统虚拟化模块,自Linux 2.6.20之后集成在Linux的各个主要发行版本中.它使用Linu ...
- 为啥百度、网易、小米都用Python?Python的用途是什么?
Python是一门脚本语言.由于能将其他各种编程语言写的模块粘接在一起,也被称作胶水语言.强大的包容性.强悍的功能和应用的广泛性使其受到越来越多的关注,想起一句老话:你若盛开.蝴蝶自来. 假设你感 ...
- Unity3D中录制和输出wav文件
近期在做视频录制方面的事情,看了下音频的录制和输出.主要参考官方的FrameCapturer: https://github.com/unity3d-jp/FrameCapturer wav文件结构较 ...
- [转载] Conv Nets: A Modular Perspective
原文地址:http://colah.github.io/posts/2014-07-Conv-Nets-Modular/ Conv Nets: A Modular Perspective Posted ...
- android9.0适配HTTPS:not permitted by network security policy'
app功能接口正常,其他手机运行OK,但是在Android9.0的手机上报错 CLEARTEXT communication to 192.168.1.xx not permitted by netw ...
- java执行post请求,并获取json结果组成想要的内容存放本地txt中
大概就是这样一个post 然后用户的需求是: 1.分析这个接口,实现1.1 获取到sentence, score字段值1.2 这个score值如果是<0.5,打印分值 情感倾向:0 ...