在Pycharm上编写WordCount程序
本篇博客将给大家介绍怎么在PyCharm上编写运行WordCount程序。
第一步 下载安装PyCharm
下载Pycharm
PyCharm的下载地址(Linux版本)。
下载完成后你将得到一个名叫:pycharm-professional-2018.2.4.tar.gz文件。我们选择的是正版软件,学生可申请免费使用。详细信息请百度。
安装PyCharm
执行以下命令解压文件:
- cd ~/下载
- tar -xvf pycharm-professional-2018.2.4.tar.gz
这时候我们可以在下载目录看到一个pycharm-2018.2.4文件夹。接下来我们把它放到/usr/local下,并且重命名
- sudo mv ./pycharm-2018.2.4 /usr/local/pycharm
然后我们要执行pycharm.sh文件,完成首次安装:
- cd /usr/local/pycharm/bin
- ./pycharm.sh
等待之后我们可以看到如下图界面: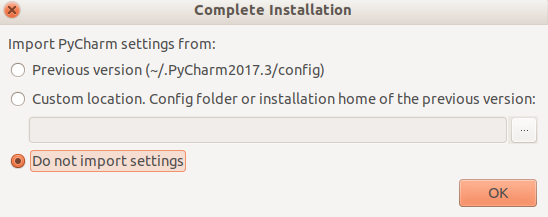
选择不导入设置,点击OK。然后我们会看到以下界面: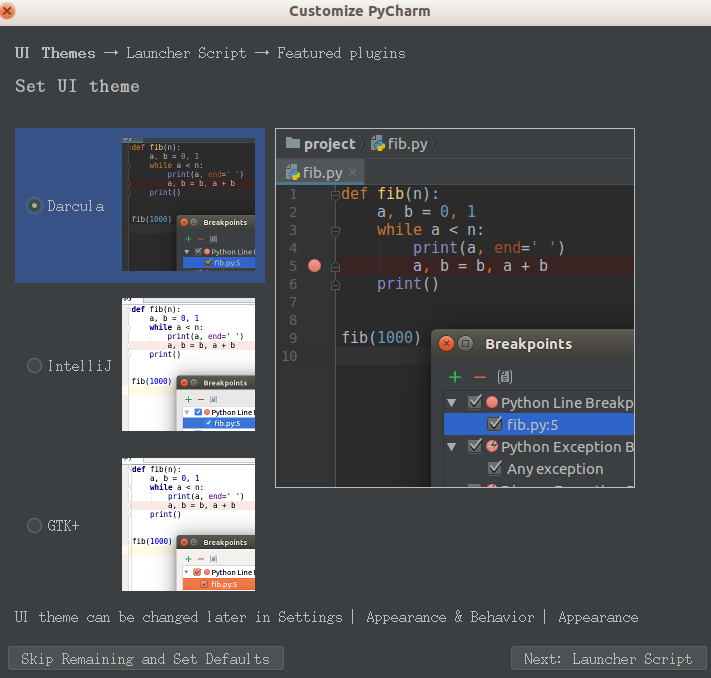
选择左下角“Skip Remaining and Set Defaults”,默认设置即可,本人更偏爱白色,所以后面的截图会跟大家不一样,但是没有影响。
配置环境变量
配置环境变量的意义在于我们以后不需要每次都到pycharm文件夹下去启动程序。
- sudo vim ~/.bashrc
将下面内容复制到文件的开头部分。
- #pycharm
- export PyCharm_HOME=/usr/local/pycharm
- export PATH=${PyCharm_HOME}/bin:$PATH
完成以上操作后你就可以在终端直接使用:pycharm.sh命令打开程序了。
第二步 创建并运行WordCount程序
创建工程文件
在开始界面选择“Create New Project”
接下来按照下图操作,修改图中两处红框内容,project起名为WordCount,python选择3.6版本,没有的请安装。
最后点击Create,完成项目创建。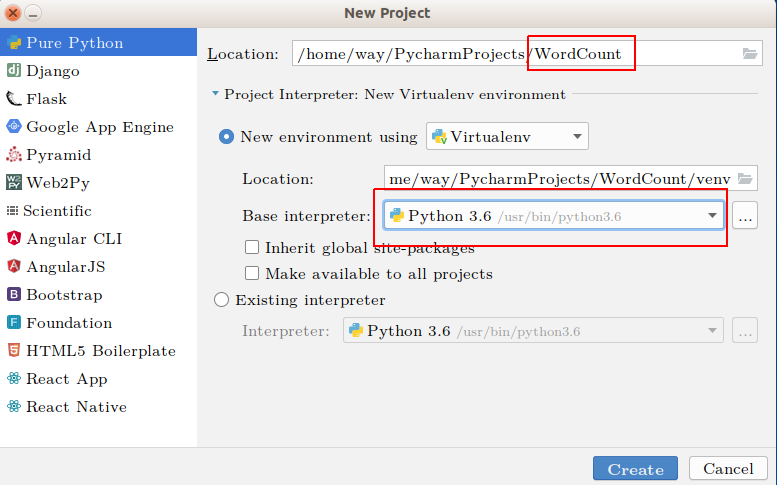
创建python文件
右键点击WordCount文件夹,选择New -> Python File,可以看到以下界面,我们取文件名为WordCount。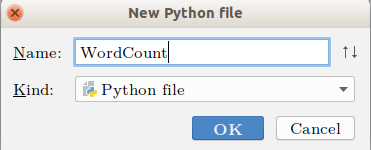
然后我们在WordCount.py中复制以下代码:
- #-*- coding:utf8-*-
- from pyspark import SparkConf, SparkContext
- conf = SparkConf().setAppName("WordCount").setMaster("local")
- sc = SparkContext(conf=conf)
- inputFile = "hdfs://localhost:9000/user/way/word.txt"
- textFile = sc.textFile(inputFile)
- wordCount = textFile.flatMap(lambda line : line.split(" ")).map(lambda word : (word, 1)).reduceByKey(lambda a, b : a + b)
- wordCount.foreach(print)
这时候你会看到PyCharm自动报错,代码中带红色波浪线部分为PyCharm提示的错误。缺少pyspark等。接下来我们要利用pycharm自动帮我们安装pyspark。把鼠标放到带红色波浪线的地方,并且将光标点进错误的地方,如下图,会出现一个小红灯泡。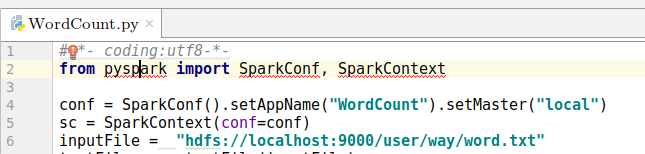
点击小红灯泡,选择“Install package pyspark”,等待程序自动安装完成,在程序底部可看到正在安装的提示。
补充说明一下代码。
我的inputFile = “hdfs://localhost:9000/user/way/word.txt”
这个文件是放在hdfs伪分布式文件系统上的,这时候你必须开启hdfs文件系统,相关操作查看实验室相关博客。
你也可以选择本地文件inputFile = “file:///home/way/桌面/word.txt”。 当然在这些位置你必须有这个word.txt文件。
Pycharm运行WordCount
然后你可以右键点击代码页面,选择Run “WordCount”。可以看到以下结果: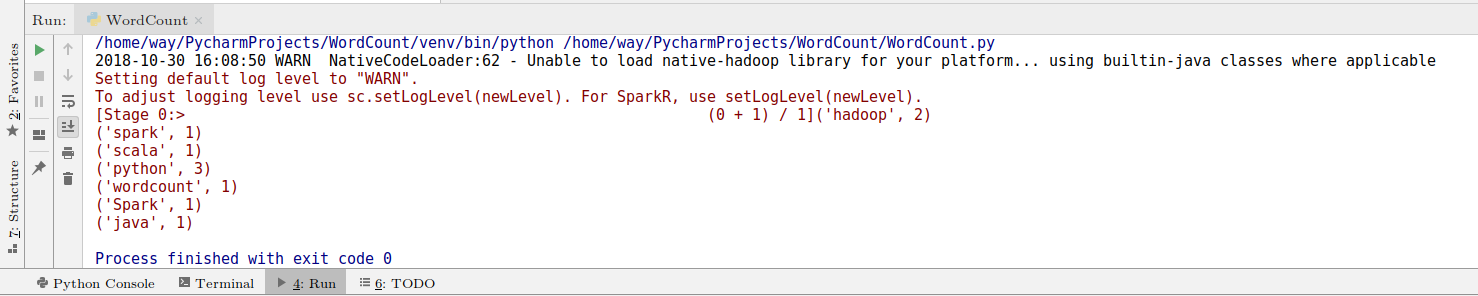
提交到spark运行
我们也可以把代码提交到Spark运行,具体方法是:
打开终端,打开Spark安装目录,并执行提交任务命令:
- cd /usr/local/spark/
- ./bin/spark-submit /home/way/PycharmProjects/WordCount/WordCount.py
翻一下我们的输出信息可以找到以下结果: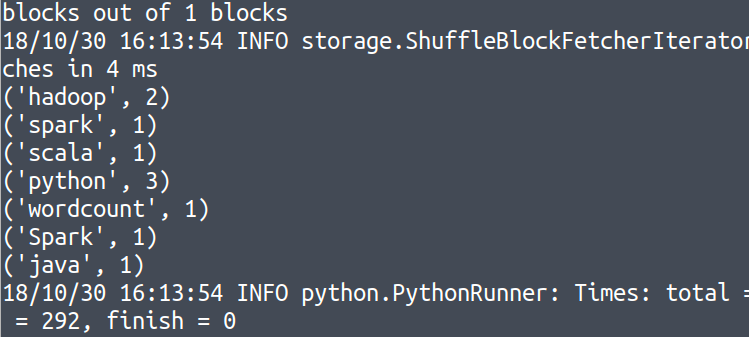
至此我们完成了在pycharm用python编写wordcount程序的实验。

在Pycharm上编写WordCount程序的更多相关文章
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- indows Eclipse Scala编写WordCount程序
Windows Eclipse Scala编写WordCount程序: 1)无需启动hadoop,因为我们用的是本地文件.先像原来一样,做一个普通的scala项目和Scala Object. 但这里一 ...
- Spark在Yarn上运行Wordcount程序
前提条件 1.CDH安装spark服务 2.下载IntelliJ IDEA编写WorkCount程序 3.上传到spark集群执行 一.下载IntellJ IDEA编写Java程序 1.下载IDEA ...
- 在Spark上运行WordCount程序
1.编写程序代码如下: Wordcount.scala package Wordcount import org.apache.spark.SparkConf import org.apache.sp ...
- 在Linux上编写C#程序
自从C#开源之后,在Linux编写C#程序就成了可能.Mono-project就是开源版本的C#维护项目.在Linux平台上使用的C#开发工具为monodevelop.安装方式如下: 首先需要安装一些 ...
- 编写wordcount程序
一.程序概述 1.此次编写的程序为邹欣老师<构建之法>科书2.4.2 wordcount程序. 2.我写的wordcount程序要实现的功能整体可以总结为: ① 统计word文档中的字符数 ...
- 第一天:学会如何在pycharm上编写第一条robotframework用例
---恢复内容开始--- 1.python环境的安装和依赖包的下载
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 020_自己编写的wordcount程序在hadoop上面运行,不使用插件hadoop-eclipse-plugin-1.2.1.jar
1.Eclipse中无插件运行MP程序 1)在Eclipse中编写MapReduce程序 2)打包成jar包 3)使用FTP工具,上传jar到hadoop 集群环境 4)运行 2.具体步骤 说明:该程 ...
随机推荐
- cd命令无效
原因是没有切换盘符步骤一:C:\Documents and Settings\Administrator>d:步骤二:cd D:\Program Files\Python35-32\Script ...
- .NET回归 HTML----表单元素(1)和一些常用的标记
表单就是-----用于搜集不同类型的用户输入. 表单元素指的是不同类型的 input 元素.复选框.单选按钮.提交按钮等等. 首先将表单元素分为三个类型.文本类,按钮类,选择类. 表单可以嵌套在表中, ...
- 报错:空指针java.lang.NullPointerException 原因 Action层 private UserService userservice 上未加@Autowire注解
java.lang.NullPointerException at com.itheima.test.Test2.fun1(Test2.java:18) at sun.reflect.NativeMe ...
- JButton变换样式
JButton变换样式 摘自:绘制JButton圆角效果 http://caleb-520.iteye.com/blog/1039493 RButton btnNewButton_1 = new RB ...
- dreamweaver cs5 快捷键
撤销上一步:ctrl + Z: 回复上一步:ctrl + Y: 代码缩进:左下角(应用原格式)
- springMVC:modelandview,model,controller,参数传递
转载:http://blog.csdn.net/wm5920/article/details/8173480 1.web.xml 配置: copy <> ></> & ...
- 访问其他电脑的c盘
访问其他电脑的c盘 \\192.168.0.1\C$
- Dubbo接口测试方法及步骤
1)打开soapUI,点击File--New project: 2)右键New REST service from URL,注:因为dubbo接口不像http接口一样有URL,所以这里的URL可以随便 ...
- vncviewer 命令行使用
一.命令行输入密码登录 /usr/bin/vncviewer 192.168.210.80:3此时弹出输入密码框,输入密码即可登录 二.命令行免输入密码登录 (a) /usr/bin/vncviewe ...
- 「BZOJ 3529」「SDOI 2014」数表「莫比乌斯反演」
题意 有一张 \(n\times m\) 的数表,其第\(i\)行第\(j\)列的数值为能同时整除\(i\)和\(j\)的所有自然数之和. \(T\)组数据,询问对于给定的 \(n,m,a\) , 计 ...