Mybatis的小计
1连接池
一 我的错误想法
poolMaximumIdleConnections 最大活跃连接数
poolMaximumActiveConnections 最大空闲连接数
我一直以为
空闲是一直存在的。没请求的时候,活跃回收,空闲连接保持。请求多的时候空闲直接变为活跃,然后生成新的连接直到最大活跃连接数,最大空闲连接数,活跃不断的处理请求,处理完自动销毁。其实是错的。
二 正确想法和源码分析
正确的情况是
没请求的时候,空闲连接每隔一段时间判断其有没有在使用,随时保证空闲的连接健壮性。至于活跃连接会回收,并在回收的时候判断,空闲有没有满,没有就新建个连接给空闲连接,然后设置成不可用,满则直接设置成不可用。
有请求的时候,空闲连接取出到活跃连接,取完空闲就新建连接到活跃连接。而且此时活跃连接完成就会变成空闲连接,再从空闲连接取出到活跃连接执行操作。
我们要知道连接取出来使用popConnection,连接使用完的处理pushConnection。
pushConnection分析
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) {
//从活跃连接取出
state.activeConnections.remove(conn);
//连接可用
if (conn.isValid()) {
//空闲连接未满,还是期待的连接类型
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
//复制成新连接
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
//放入空闲连接
state.idleConnections.add(newConn);
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
conn.invalidate();
if (log.isDebugEnabled()) {
log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
}
state.notifyAll();
} else {
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
//销毁连接
conn.getRealConnection().close();
if (log.isDebugEnabled()) {
log.debug("Closed connection " + conn.getRealHashCode() + ".");
}
conn.invalidate();
}
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
}
//放入坏的连接
state.badConnectionCount++;
}
}
}
popConnection分析
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
synchronized (state) {
//空闲连接集合不是空
if (!state.idleConnections.isEmpty()) {
// Pool has available connection
//从空闲连接取出
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// Pool does not have available connection
//活跃连接集合还没满
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// Can create new connection
//新建连接
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
//此处活跃连接,空闲连接都满了
// Cannot create new connection
//取第一个活跃连接的状态
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
//检查时间大于最大检查时间
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// Can claim overdue connection
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
//从活跃连接去掉第一个的连接
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
log.debug("Bad connection. Could not roll back");
}
}
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// Must wait
try {
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
if (conn.isValid()) {
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + 3)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
2.Mybatis,hibernate和hibernate Jpa的对比
MyBatis主要设计目 执行SQL语句时对输入输出的数据管理更加方便,直观体现就是可以手写SQL语句
hibernate主要设计目 加快sql开发,直观体现就是有多个默认的方法,但是复杂的sql支持的不太好
hibernate Jpa结合了两者的优点,既有简单的默认方法·,又可手写sql语句。
3.MyBatis的主要成员
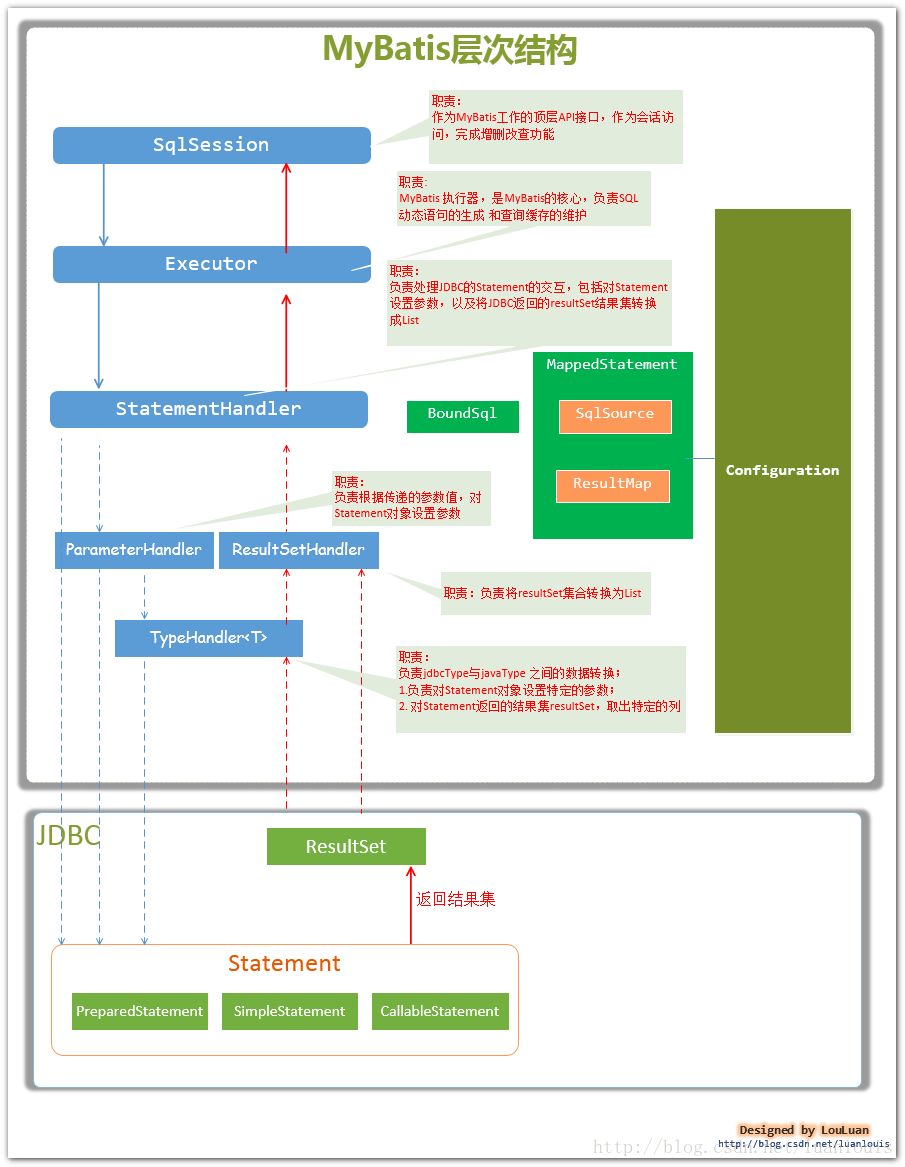
Configuration MyBatis所有的配置信息都保存在Configuration对象之中,配置文件中的大部分配置都会存储到该类中
SqlSession 作为MyBatis工作的主要顶层API,表示和数据库交互时的会话,完成必要数据库增删改查功能
Executor MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护
StatementHandler 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数等
ParameterHandler 负责对用户传递的参数转换成JDBC Statement 所对应的数据类型
ResultSetHandler 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合
TypeHandler 负责java数据类型和jdbc数据类型(也可以说是数据表列类型)之间的映射和转换
MappedStatement MappedStatement维护一条<select|update|delete|insert>节点的封装
SqlSource 负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回ResultMap
ResultMap 负责返回给用户的parameterObject
BoundSql 表示动态生成的SQL语句以及相应的参数信息
简单说就是,先通过Configuration生成配置,初始化了MappedStatement,SqlSource,ResultMap,BoundSql,然后程序调用持久化操作的时候从sqlsession走一遍流程。
图
4.mybatis的缓存
一级缓存是SqlSession级别的缓存,每个SqlSession对象都有一个哈希表用于缓存数据,不同SqlSession对象之间缓存不共享。同一个SqlSession对象对象执行2遍相同的SQL查询,在第一次查询执行完毕后将结果缓存起来,这样第二遍查询就不用向数据库查询了,直接返回缓存结果即可。MyBatis默认是开启一级缓存的。
二级缓存是mapper级别的缓存,二级缓存是跨SqlSession的,多个SqlSession对象可以共享同一个二级缓存。不同的SqlSession对象执行两次相同的SQL语句,第一次会将查询结果进行缓存,第二次查询直接返回二级缓存中的结果即可。MyBatis默认是不开启二级缓存的,要在配置文件中使用配置开启二级缓存
ps.当SQL语句进行更新操作(删除/添加/更新)时,会清空对应的缓存,保证缓存中存储的都是最新的数据。
但是MyBatis的二级缓存对细粒度的数据级别的缓存实现不友好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分(mapper文件),当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题需要在业务层根据需求对数据有针对性缓存(划分不同的mapper文件),具体业务具体实现。
同理和hibernate一样,分布式情况下,这缓存也失效了。
Mybatis的小计的更多相关文章
- SQLSERVER 使用 ROLLUP 汇总数据,实现分组统计,合计,小计
表结构: CREATE TABLE [dbo].[Students]( ,) NOT NULL, ) NULL, [Sex] [int] NOT NULL, ) NULL, ) NULL, , ) N ...
- PB gird类型数据窗口 设置分组、分组小计、合计
今天遇到一个需求,gird表格数据如下: 部门 类型 数据 A 类型1 1 A 类型2 2 B 类型1 3 B 类型2 4 合计 10 实际需要显示的结果为: 部门 ...
- 简单的angular购物车商品小计
<!DOCTYPE html> <html lang="en" ng-app="shopApp"> <head> <m ...
- C#给DataTable添加序号、C#给DataTable添加合计、小计
/// <summary> /// 给DataTable添加序号 /// </summary> /// <param name= ...
- SAP ALV中同一列的不同行显示不同的小数位,并能够总计,小计
物料数量字段,根据物料类型的不同,来显示不同的小数位:要求有点苛刻: 首先,要能够总计和小计的话,这一列的字段类型必须是数值类型. 这样的话,就不能通过截取的方式改变不同行的小数位. 以下是两种思路: ...
- 每日学习心得:SQL查询表的行列转换/小计/统计(with rollup,with cube,pivot解析)
2013-8-20 1. SQL查询表的行列转换/小计/统计(with rollup,with cube,pivot解析) 在实际的项目开发中有很多项目都会有报表模块,今天就通过一个小的SQL ...
- VMProtect使用小计【一】
文章列表 VMProtect使用小计[一] – 初次使用VMProtect使用小计[二] – 加壳查看VMProtect使用小计[三] – 权限管理 说明 VMProtect的功能我就不说了,详情大家 ...
- 用SQL实现统计报表中的"小计"与"合计"的方法详解
本篇文章是对使用SQL实现统计报表中的"小计"与"合计"的方法进行了详细的分析介绍,需要的朋友参考下 客户提出需求,针对某一列分组加上小计,合计汇总.网上找 ...
- 【IOS实例小计】今日开贴,记录我的ios学习生涯,留下点滴,留下快乐,成荫后人。
今天开贴来记录自己的ios学习过程,本人目前小白一个,由于对ios感兴趣,所以开始学习,原职java程序,呵呵,勿喷. 本次的[ios实例小计]主要参考一文http://blog.sina.com.c ...
随机推荐
- ES6学习之Class
一.定义类(ES6的类,完全可以看做是构造函数的另一种写法) class Greet { constructor(x, y) { this.x = x; this.y = y; } sayHello( ...
- Project Server调用PSI关闭任务以进行更新锁定任务
/// <summary> /// 锁定和解锁项目任务 /// </summary> /// <param name="projectuid"> ...
- 关于Windows文件读写_暗涌_新浪博客
关于Windows文件读写_暗涌_新浪博客 这几天在研究怎么才能加快windows文件读写速度,搜了很多文章,MSDN也看了不少.稍微给大家分享一下. 限制windows文件读写速度的 ...
- MS SQL 取分组后的几条数据
SELECT uploaddate ,ptnumber ,instcount FROM ( SELECT ROW_NUMBER() OVER( PARTITION BY uploaddate ORDE ...
- GIT 图形化操作指南
Git操作指南(2) -- Git Gui for Windows的建库.克隆(clone).上传(push).下载(pull).合并 关于linux上建库等操作请看文章: http://hi.bai ...
- 6.6 Ubuntu 安装 截图工具 Shutter
可参考: http://blog.csdn.net/hanshileiai/article/details/46843713
- Spring入门第三课
属性注入 属性注入就是通过setter方法注入Bean的属性值或依赖的对象. 属性植入使用<property>元素,使用name属性指定Bean的属性名称,value属性或者<val ...
- UVaLive 11525 Permutation (线段树)
题意:有一个由1到k组成的序列,最小是1 2 … k,最大是 k k-1 … 1,给出n的计算方式,n = s0 * (k - 1)! + s1 * (k - 2)! +… + sk-1 * 0!, ...
- IOS 获取系统通讯录
进入正题 获取系统通讯录,不想多讲,留下链接http://my.oschina.net/joanfen/blog/140146 通常做法: 首先创建一个ABAddressBookRef类的对象add ...
- HDU 3400 Line belt (三分嵌套)
题目链接 Line belt Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...