k近邻算法(k-nearest neighbor,k-NN)
kNN是一种基本分类与回归方法。k-NN的输入为实例的特征向量,对应于特征空间中的点;输出为实例的类别,可以取多类。k近邻实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。k值的选择、距离度量及分类决策规则是k近邻的三个基本要素。
算法
输入:训练数据集T={(x1,y1),(x2,y2),……..,(xN,yN)}
输出:实例x所属的类y
(1)根据给定的距离度量,在训练集T中找到与x最邻近的k个点,涵盖这k个点的x的邻域记作Nk(x)
(2)在Nk(x)中根据分类决策规则(如多数表决)决定x的类别y:
y=arg maxΣI(yi=cj) i=1,2,3,……,N; j=1,2,3,….K 其中I为指示函数,即当yi=cj时I为1,否则I为0
k近邻法的特殊情况是k=1的情形,称为最近邻算法。对于输入的实例点(特征向量)x,最近邻法将训练数据集中与x最近邻点的类作为x的类。k近邻法没有显式的学习过程。
k近邻模型
k近邻法中,当训练数据集、距离度量(如欧氏空间)、k值及分类决策规则(如多数表决)确定后,对于任何一个新的输入实例,它属于的类唯一地确定。这相当于根据上述要素将特征空间划分为一些子空间,确定子空间里的每个点所属的类。
特征空间中,对每个训练实例点xi,距离该点比其他点更近的所有点组成一个域,叫做单元cell。每个训练实例点拥有一个单元,所有训练实例点的单元构成对特征空间的一个划分。
距离度量
常用的距离是欧式距离,Minkowski距离,更一般的是Lp距离。
设k近邻法中实例特征向量为一个n维实数向量,记为
则一般距离Lp定义为:

当p=2时就是我们常用的欧式距离。
k值的选择
k值的选择会对k近邻法的结果产生重大影响。
如果选择较小的k值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用。但缺点是“学习”的估计误差会增大,预测结果会对近邻的实例点非常敏感。如果近邻的实例点恰巧是噪声,预测就会出错。换句话说,k值的减小就意味着整体模型变得复杂,容易发生过拟合
如果选择较大的k值,就相当于用较大邻域中的训练实例进行预测,其优点是可以减少学习的估计误差。但缺点是学习的近似误差会增大。这时与输入实例较远(不相似的)训练实例也会对预测起作用,使预测发生错误。k值的增大就意味着整体模型变得简单。
在应用中,k值一般取一个比较小的数值,通常采用交叉验证法来选取最优的k值。
分类决策规则——多数表决规则
多数表决规则:
即输入实例的k个近邻的训练实例中的多数类决定输入实例的类别。多数表决规则的解释:如果分类的损失函数为0-1损失函数,
分类函数为:
f:x ——>{c1,c2,...,ch}
其中x为实例的特征向量,c1,c2,...,ch为h个类别。
对给定的实例x,其最近邻的k个训练实例构成的集合Nk(x),如果覆盖Nk(x)的区域的类别是cj,则误分类率是:

要使误分类率最小即经验风险最小,就要使
KNN算法之KD树实现原理
KD树算法没有一开始就尝试对测试样本分类,而是先对训练集建模,建立的模型就是KD树,建好了模型再对测试集做预测。所谓的KD树就是K个特征维度的树,注意这里的K和KNN中的K的意思不同。KNN中的K代表特征输出类别,KD树中的K代表样本特征的维数。为了防止混淆,后面我们称特征维数为n。
KD树算法包括三步,第一步是建树,第二部是搜索最近邻,最后一步是预测。
KD树的建立
我们首先来看建树的方法。KD树建树采用的是从m个样本的n维特征中,分别计算n个特征的取值的方差,用方差最大的第k维特征nk来作为根节点。对于这个特征,我们选择特征nk的取值的中位数nkv对应的样本作为划分点,对于所有第k维特征的取值小于nkv的样本,我们划入左子树,对于第k维特征的取值大于等于nkv的样本,我们划入右子树,对于左子树和右子树,我们采用和刚才同样的办法来找方差最大的特征来做更节点,递归的生成KD树。
具体流程如下图:
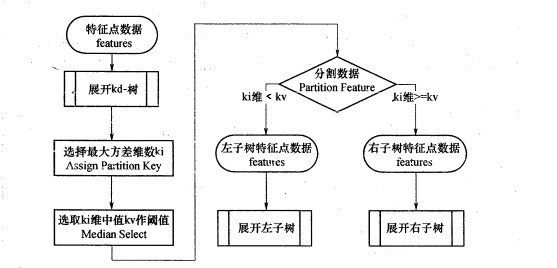
比如我们有二维样本6个,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构建kd树的具体步骤为:
1)找到划分的特征。6个数据点在x,y维度上的数据方差分别为6.97,5.37,所以在x轴上方差更大,用第1维特征建树。
2)确定划分点(7,2)。根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以划分点的数据是(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:划分点维度的直线x=7;
3)确定左子空间和右子空间。 分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)}。
4)用同样的办法划分左子树的节点{(2,3),(5,4),(4,7)}和右子树的节点{(9,6),(8,1)}。最终得到KD树。
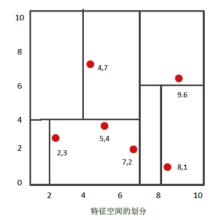
最后得到的KD树如下:
KD树搜索最近邻
当我们生成KD树以后,就可以去预测测试集里面的样本目标点了。对于一个目标点,我们首先在KD树里面找到包含目标点的叶子节点。以目标点为圆心,以目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部。然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话就更新最近邻。如果不相交那就简单了,我们直接返回父节点的父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束,此时保存的最近邻节点就是最终的最近邻。
从上面的描述可以看出,KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交,根本不需要计算距离。大大节省了计算时间。
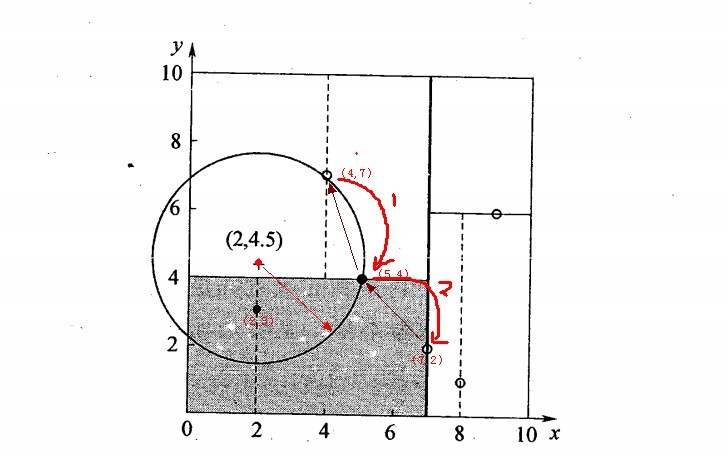
我们用前一节建立的KD树,来看对点(2,4.5)找最近邻的过程。
先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但 (4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点; 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
对应的图如下:
KD树预测
有了KD树搜索最近邻的办法,KD树的预测就很简单了,在KD树搜索最近邻的基础上,我们选择到了第一个最近邻样本,就把它置为已选。在第二轮中,我们忽略置为已选的样本,重新选择最近邻,这样跑k次,就得到了目标的K个最近邻,然后根据多数表决法,如果是KNN分类,预测为K个最近邻里面有最多类别数的类别。如果是KNN回归,用K个最近邻样本输出的平均值作为回归预测值。
KNN算法之球树实现原理
KD树算法虽然提高了KNN搜索的效率,但是在某些时候效率并不高,比如当处理不均匀分布的数据集时,不管是近似方形,还是矩形,甚至正方形,都不是最好的使用形状,因为他们都有角。一个例子如下图:
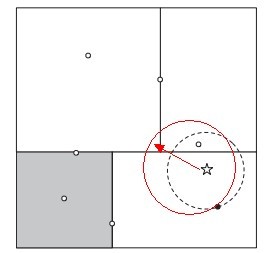
如果黑色的实例点离目标点星点再远一点,那么虚线圆会如红线所示那样扩大,导致与左上方矩形的右下角相交,既然相 交了,那么就要检查这个左上方矩形,而实际上,最近的点离星点的距离很近,检查左上方矩形区域已是多余。于此我们看见,KD树把二维平面划分成一个一个矩形,但矩形区域的角却是个难以处理的问题。
为了优化超矩形体导致的搜索效率的问题,牛人们引入了球树,这种结构可以优化上面的这种问题。
我们现在来看看球树建树和搜索最近邻的算法。
球树的建立
球树,顾名思义,就是每个分割块都是超球体,而不是KD树里面的超矩形体。
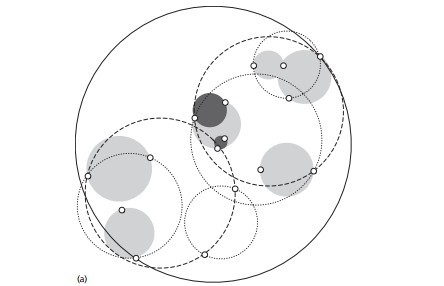
我们看看具体的建树流程:
1) 先构建一个超球体,这个超球体是可以包含所有样本的最小球体。
2) 从球中选择一个离球的中心最远的点,然后选择第二个点离第一个点最远,将球中所有的点分配到离这两个聚类中心最近的一个上,然后计算每个聚类的中心,以及聚类能够包含它所有数据点所需的最小半径。这样我们得到了两个子超球体,和KD树里面的左右子树对应。
3)对于这两个子超球体,递归执行步骤2). 最终得到了一个球树。
可以看出KD树和球树类似,主要区别在于球树得到的是节点样本组成的最小超球体,而KD得到的是节点样本组成的超矩形体,这个超球体要与对应的KD树的超矩形体小,这样在做最近邻搜索的时候,可以避免一些无谓的搜索。
球树搜索最近邻
使用球树找出给定目标点的最近邻方法是首先自上而下贯穿整棵树找出包含目标点所在的叶子,并在这个球里找出与目标点最邻近的点,这将确定出目标点距离它的最近邻点的一个上限值,然后跟KD树查找一样,检查兄弟结点,如果目标点到兄弟结点中心的距离超过兄弟结点的半径与当前的上限值之和,那么兄弟结点里不可能存在一个更近的点;否则的话,必须进一步检查位于兄弟结点以下的子树。
检查完兄弟节点后,我们向父节点回溯,继续搜索最小邻近值。当回溯到根节点时,此时的最小邻近值就是最终的搜索结果。
从上面的描述可以看出,KD树在搜索路径优化时使用的是两点之间的距离来判断,而球树使用的是两边之和大于第三边来判断,相对来说球树的判断更加复杂,但是却避免了更多的搜索,这是一个权衡。
KNN算法的扩展
这里我们再讨论下KNN算法的扩展,限定半径最近邻算法。
有时候我们会遇到这样的问题,即样本中某系类别的样本非常的少,甚至少于K,这导致稀有类别样本在找K个最近邻的时候,会把距离其实较远的其他样本考虑进来,而导致预测不准确。为了解决这个问题,我们限定最近邻的一个最大距离,也就是说,我们只在一个距离范围内搜索所有的最近邻,这避免了上述问题。这个距离我们一般称为限定半径。
接着我们再讨论下另一种扩展,最近质心算法。这个算法比KNN还简单。它首先把样本按输出类别归类。对于第 L类的Cl个样本。它会对这Cl个样本的n维特征中每一维特征求平均值,最终该类别所有维度的n个平均值形成所谓的质心点。对于样本中的所有出现的类别,每个类别会最终得到一个质心点。当我们做预测时,仅仅需要比较预测样本和这些质心的距离,最小的距离对于的质心类别即为预测的类别。这个算法通常用在文本分类处理上。
KNN算法小结
KNN算法是很基本的机器学习算法了,它非常容易学习,在维度很高的时候也有很好的分类效率,因此运用也很广泛,这里总结下KNN的优缺点。
KNN的主要优点有:
1) 理论成熟,思想简单,既可以用来做分类也可以用来做回归
2) 可用于非线性分类
3) 训练时间复杂度比支持向量机之类的算法低,仅为O(n)
4) 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
5) 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
6)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分
KNN的主要缺点有:
1)计算量大,尤其是特征数非常多的时候
2)样本不平衡的时候,对稀有类别的预测准确率低
3)KD树,球树之类的模型建立需要大量的内存
4)使用懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
5)相比决策树模型,KNN模型可解释性不强
以上就是KNN算法原理的一个总结,希望可以帮到朋友们,尤其是在用scikit-learn学习KNN的朋友们。
参考文献:统计学习方法(李航)
http://www.cnblogs.com/pinard/p/6061661.html
k近邻算法(k-nearest neighbor,k-NN)的更多相关文章
- SK-learn实现k近邻算法【准确率随k值的变化】-------莺尾花种类预测
代码详解: from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split fr ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
随机推荐
- 【Javascript 基础】使用数组
Javascript 数组的工作方式与大多数编程语言的数组类似. <!DOCTYPE html> <html lang="en"> <head> ...
- document.querySelector()与document.querySelectorAll()
document.querySelector()与document.querySelectorAll() CreationTime--2018年7月1日10点49分 Author:Marydon ...
- MvcPager源代码—PagerOptions.cs
public class PagerOptions { public PagerOptions() { AutoHide = true; ...
- 设置VisualSVN在提交修改时必须输入一定数量的备注信息
我发现在使用SVN中,提交时,很多人不习惯填写备注信息,虽然在培训中.平时使用时多次提醒备注信息的好处,但是效果不大,每次提交时还是不写,或者随便写两字. 所以很有必要通过系统设置强制填写足够数量的备 ...
- java学习笔记——java中对象的创建,初始化,引用的解析
如果有一个A类. 1.例如以下表达式: A a1 = new A(); 那么A是类,a1是引用.new A()是对象.仅仅是a1这个引用指向了new A()这个对象. 2.又如: A a2; A代 ...
- spring boot 使用拦截器 实现 用户登录拦截
登录拦截和和权限拦截实现类似 首先自定义一个[DefineAdapter]类,这个类我是用来放自定义的配置(比如 自定义请求参数,自定义拦截器等),集成WebMvcConfigurerAdapte ...
- APPLE ID随意转区到US或者HK.不需要信用卡
看到论坛有封釉想去US 或者HK 的商店下载大陆商店没有的APP.(比如 Tumblr) 但是现在在手机上或者是网页管理apple id 更改地区,需要输入付款信息. 现在教大家利用旧版的icloud ...
- 系统服务-----NotificationManager
熟悉api事例笔记: package com.test; import com.example.test.R; import android.app.Activity; import android. ...
- bzoj4069【APIO2015】巴厘岛的雕塑
4069: [Apio2015]巴厘岛的雕塑 Time Limit: 10 Sec Memory Limit: 64 MB Submit: 192 Solved: 89 [Submit][Stat ...
- 转载了个js代码
document.selection.createRange方法 document.selection.createRange() 根据当前文字选择返回 TextRange 对象,或根据控件选择返回 ...