基于Doris构建亿级数据实时数据分析系统
转载至我的博客 https://www.infrastack.cn ,公众号:架构成长指南
背景
随着公司业务快速发展,对业务数据进行增长分析的需求越来越迫切,与此同时我们的业务数据量也在快速激增、每天的数据新增量大概在30w 左右,一年就会产生1 个亿的数据,显然基于传统MySQL数据库已经无法支撑满足以上需求
基于上述需求和痛点,决定提供一个灵活的多维实时查询和分析平台,帮助业务线做精细化运营。
业务分析
现有业务数据有以下特点,查询多、更新少,基本不会更新1 个月以前的数据,但是查询范围较大,有时需要查询几年前的数据,而且数据会以年、月等不同维度统计来进行增长分析
因此以上场景使用 OLTP 引擎不是特别适合,OLAP则更为适合
这里可能有些人员不懂什么是 OLAP,下面是一个OLAP与OLTP对比图
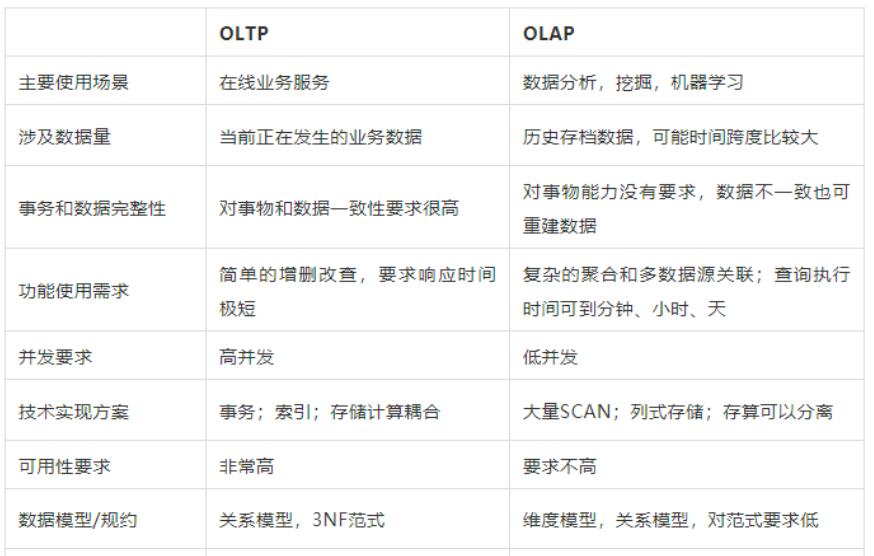
技术选型
实时数仓
以上场景确定后,我们就开始了框架选型,最终确定了 Doris,理由如下
- 性能满足要求
- 兼容MySQL 协议
- 运维成本较低
- 架构足够简单
- 社区活跃,支持力度高
下面是一个选型对比,没有好坏,只是Doris适合我们
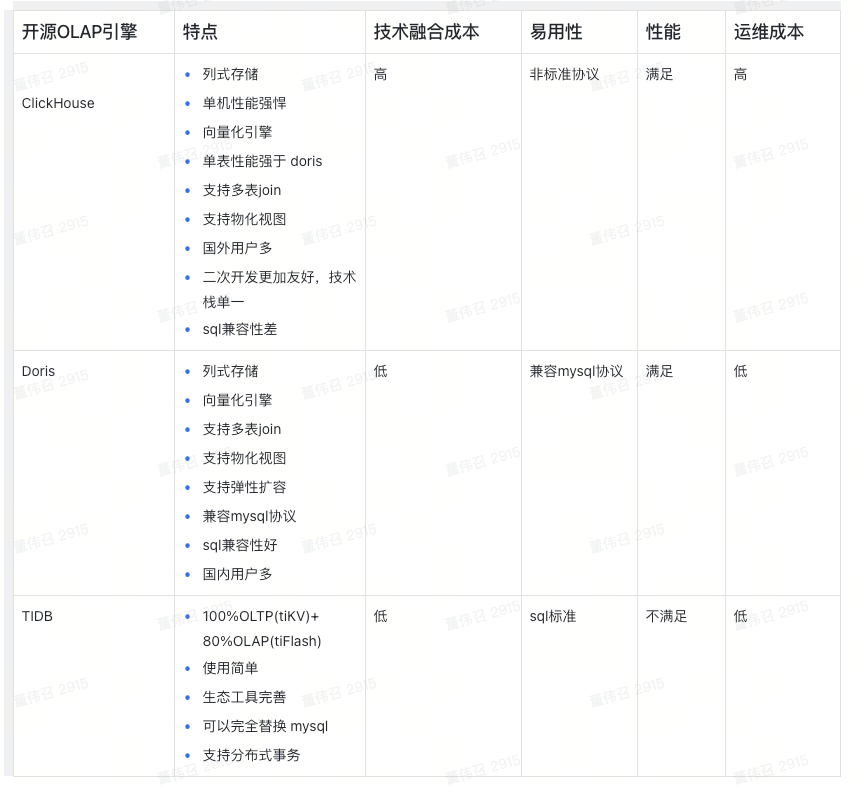
实时数据捕获
实时数据,采用Fink CDC进行捕获,Fink CDC Connectors 是Apache Flink的一组源连接器,使用变更数据捕获 (CDC) 从不同数据库中获取变更,而获取变更是通过Debezium监听Binlog 日志,获取到更新数据以后,可以对数据进行转换,然后在根据doris 提供的Flink 插件Doris flink connecto导入到 Doris 里面
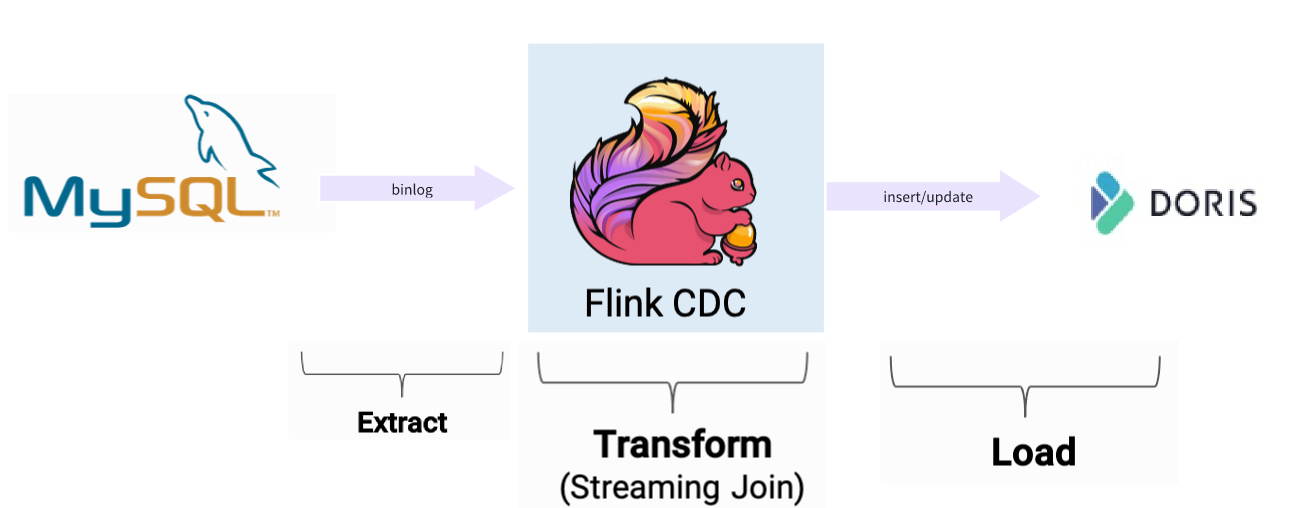
具体示例,可以参考:https://mp.weixin.qq.com/s/ssXocqCyoSVuRFBi2hzCKQ
为什么需要实时数据捕获?
Doris 只是一个数据仓库,他提供的功能是实时数据统计、查询和存储,他不支持主动实时抓取数据,需要借助第三方工具来进行实现,比如我们在 MySQL修改了一条数据,怎么让 Doris 进行更新?目前想到的答案是主动发送更新数据至Kafka,然后Doris订阅 KafKa 的 Topic 然后进行实时同步,虽然以上能实现我们想要的功能,但是有点复杂,业务每次操作都要发送 Kafka,同时要想对数据进行加工,工作量相对较,正因为有以上问题,所以我们采用Flink CDC
数据调度平台
数据调度平台,采用海豚调度器(DolphinScheduler),它也是国人开源的一款分布式可扩展的大数据调度平台,使用Java 语言开发,目前已经成为Apache 项目,它提供了强大的DAG可视化界面,所有流程定义都是可视化,通过拖拽任务完成定制DAG,同时支持 30+类型的任务,比如执行 SQL、shell 、DataX 等类型,官网地址:https://dolphinscheduler.apache.org
为什么需要数据调度平台?
数据转换:通过Flink 抽取的数据,如果还想对这些数据进行加工处理,比如实时同步的业务数据,需要再次转换为分钟级、小时级、天、月等维度的报表
非实时数据同步:通过调度DataX,以分钟、小时、天为单位进行源数据同步
定时归档:比如每晚同步业务数据库一个月前数据,同步完成之后,在执行删除任务,删除业务库一个月前的数据
数仓数据分层
数据仓库的分层是一种常见的设计模式,它将数据仓库划分为不同的层级,每个层级有不同的功能和用途。

数仓层内部的划分不是为了分层而分层,它是数据仓库经过了建模和 ETL 之后真正开始对外提供服务的地方,因此数仓层内的划分更应该符合使用者的思维习惯。 DW 内的分层没有最正确的,只有最适合你的。
ODS层
Operation Data Store 数据准备区,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,这称为ODS层,是后续数据仓库加工数据的来源。
DWD层
data warehouse details 细节数据层,是业务层与数据仓库的隔离层。主要对ODS数据层做一些数据清洗和规范化的操作,数据清洗:去除空值、脏数据、超过极限范围的
DWS层
data warehouse service 数据服务层,基于DWD上的基础数据,整合汇总成分析某一个主题域的服务数据层,一般是宽表。用于提供后续的业务查询,OLAP分析,数据分发等。
- 用户行为,轻度聚合
- 主要对ODS/DWD层数据做一些轻度的汇总。
注意:数仓层内部的划分不是为了分层而分层,它是数据仓库经过了建模和 ETL 之后真正开始对外提供服务的地方,因此数仓层内的划分更应该符合使用者的思维习惯。 DW 内的分层没有最正确的,只有最适合你的。
命名规范

系统架构
经过前面的技术选型,以及分层定义,我们最终架构如下
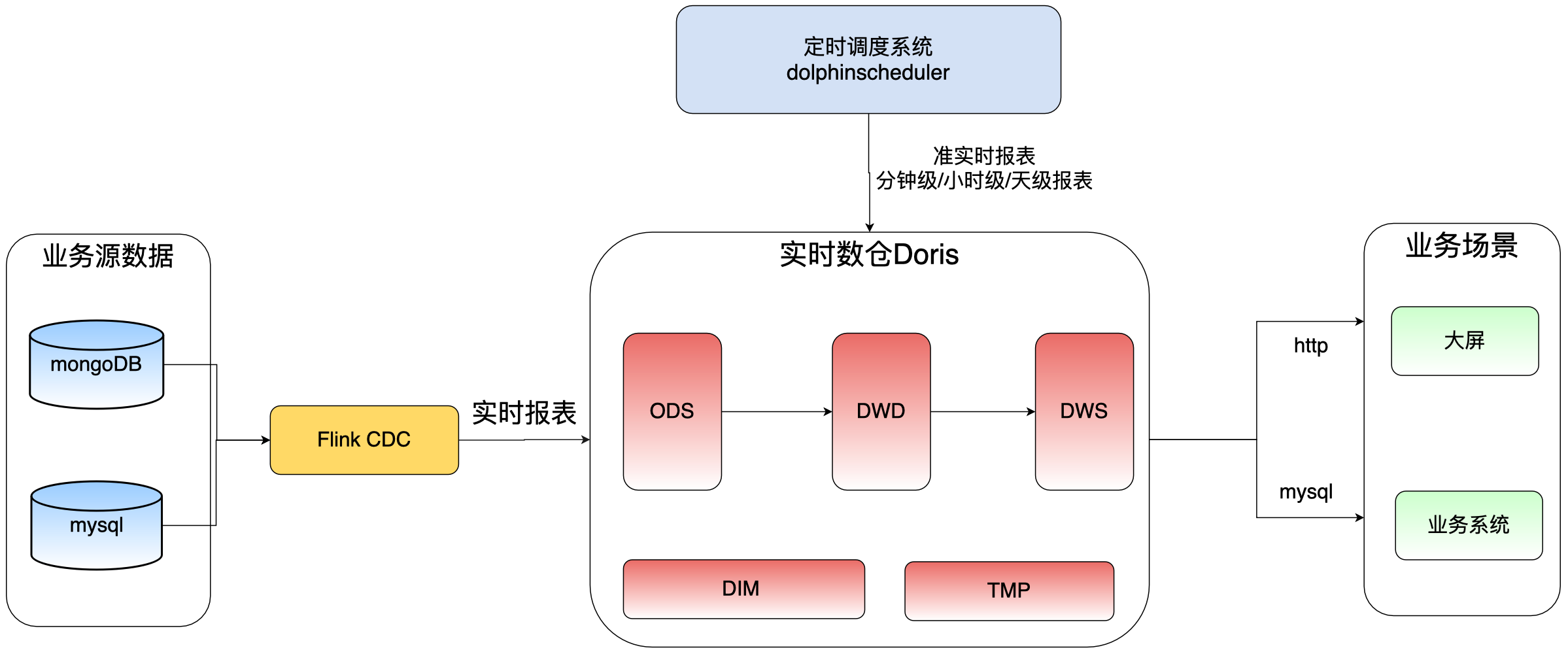
数据查询
假设语句已经同步到doris,那么怎么进行展现,这里有很多种方式,比如通过BI工具,例如:power bi、dataEase、Davinci等,同时Doris 支持mysql 协议,我们为了让之前的业务改动,对后端接口实现进行了替换,通过 mybatis 动态解析 sql,并调用 doris进行查询,架构如下
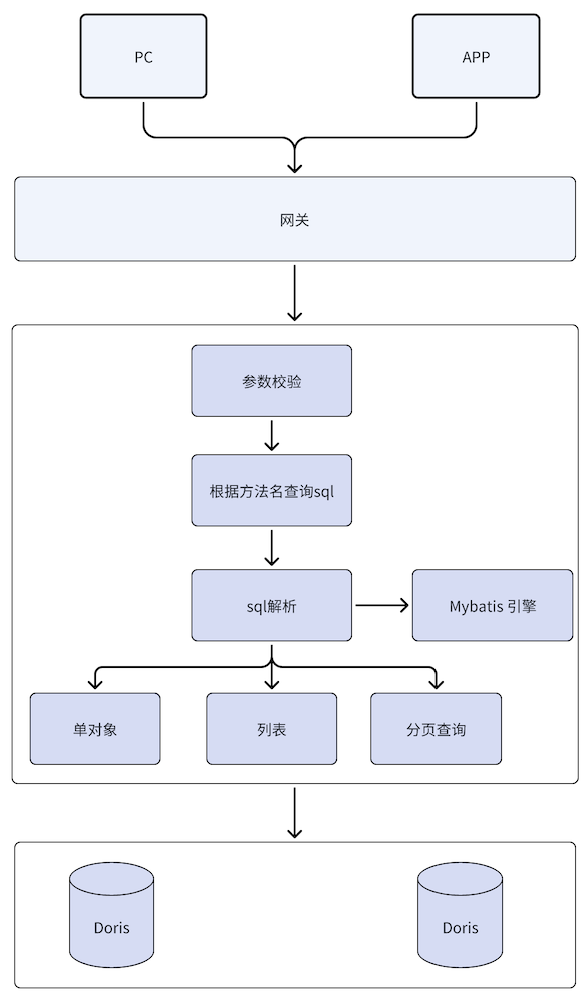
示例介绍
Flink实时同步
具体查看锋哥的文章,https://mp.weixin.qq.com/s/ssXocqCyoSVuRFBi2hzCKQ
DolphinScheduler准实时同步
同步业务数据库mysql中register表至doris的ods_test_mysql_register_s表中,并对业务数据进行删除
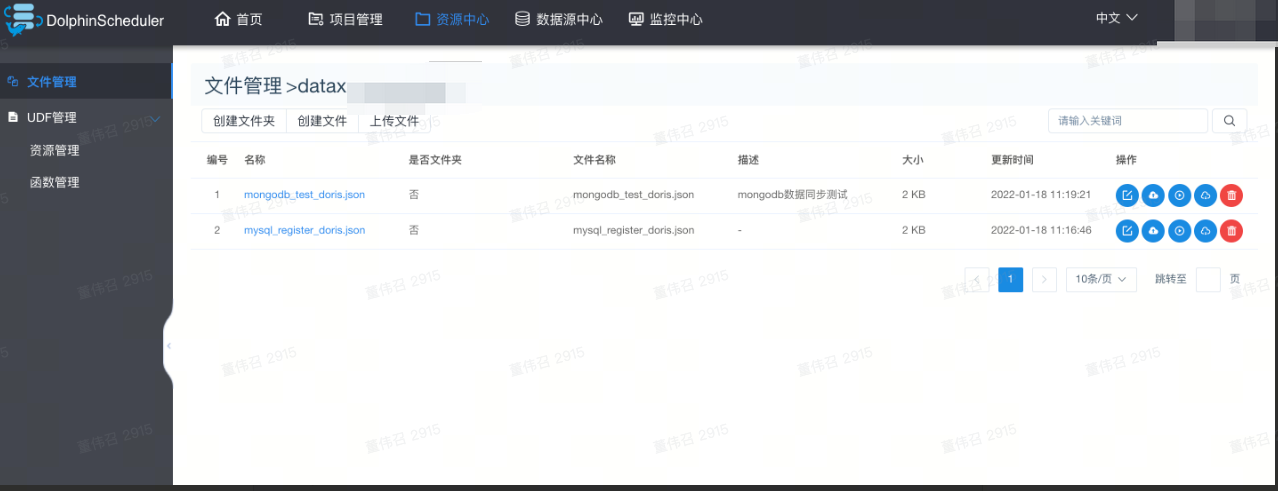
1. 创建datax文件
在资源中心创建各个团队文件夹,并在文件夹中创建对应datax文件
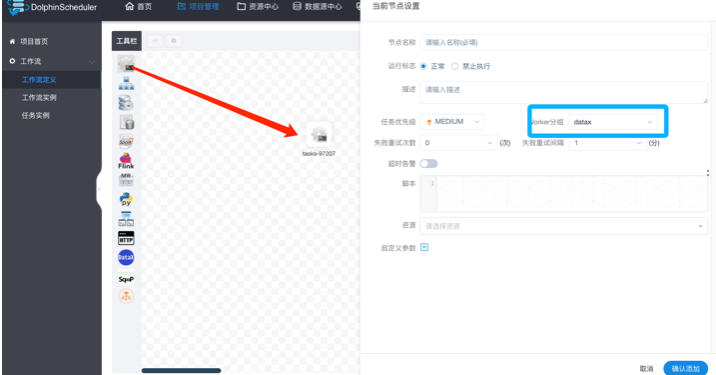
2. 创建任务
进入项目管理/工作流定义目录,点击创建工作流

选择shell任务,worker分区选择datax,
datax组为自行创建,实际配置时,以本地执行环境为准
选择资源,并编写datax启动命令
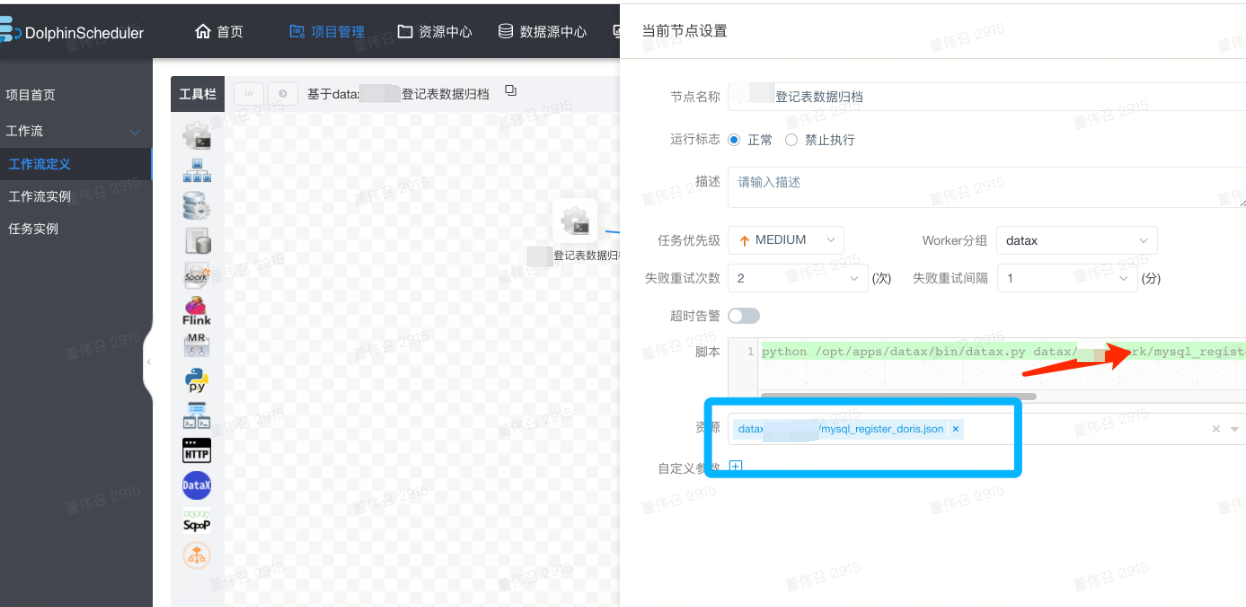
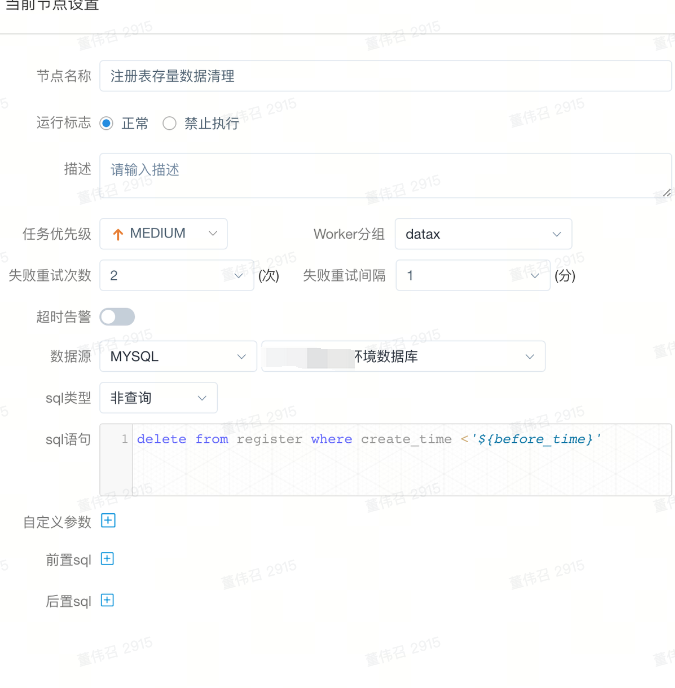
如果迁移完,需要进行原数据删除,则新建sql任务,编写sql语句,进行清理
3. 依赖关系创建
第一步进行datax数据同步第二步进行原数据清理,如下图连线就是依赖关系

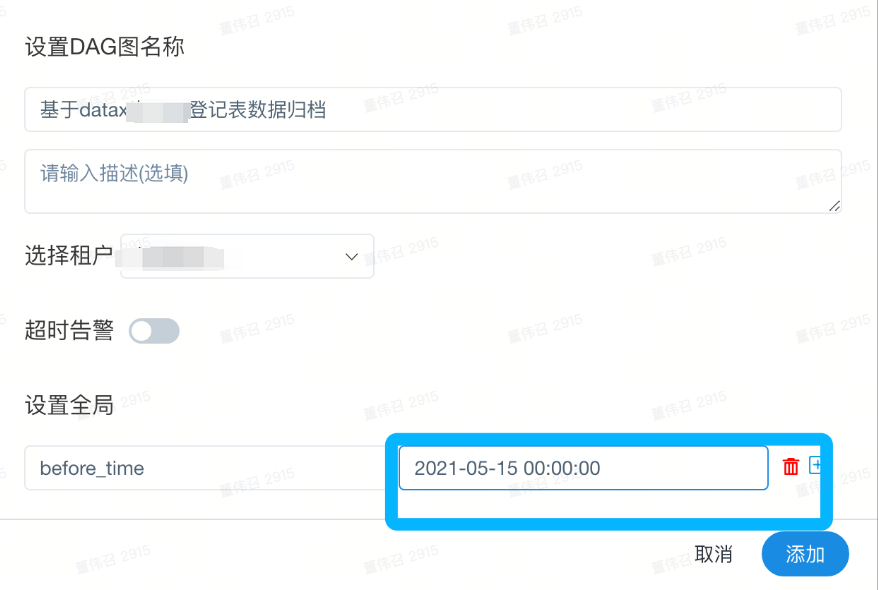
4. 全局参数设置
参数可以设置为动态参数,这里为了测试方便所以为固定值
例如:$[yyyy-MM-dd 00:00:00-15] 表示前15天,具体参考dolphinscheduler内置参数说明
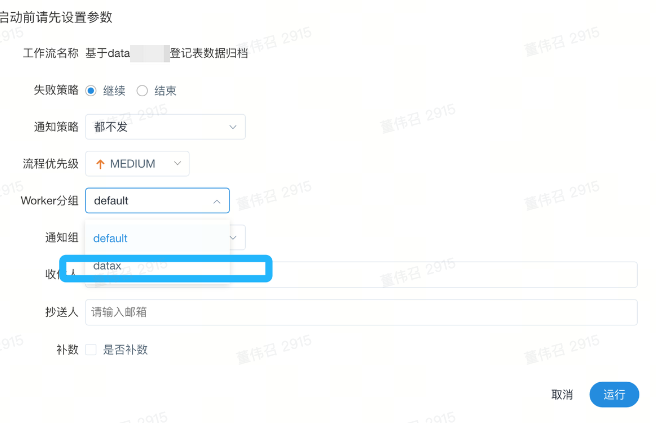
5. 启动任务
首选点击对应任务进行上线,在配置定时任务,如果测试连通性,则点击启动按钮可以立即测试
参考链接
Flink CDC结合Doris flink connector实现Mysql数据实时入Apache Doris
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的技术讨论群里面共同学习。

基于Doris构建亿级数据实时数据分析系统的更多相关文章
- 基于Mysql数据库亿级数据下的分库分表方案
移动互联网时代,海量的用户数据每天都在产生,基于用户使用数据的用户行为分析等这样的分析,都需要依靠数据都统计和分析,当数据量小时,问题没有暴露出来,数据库方面的优化显得不太重要,一旦数据量越来越大时, ...
- 基于 WebSocket 构建跨浏览器的实时应用
Socket.IO – 基于 WebSocket 构建跨浏览器的实时应用 Socket.IO 是一个功能非常强大的框架,能够帮助你构建基于 WebSocket 的跨浏览器的实时应用.支持主流浏览器,多 ...
- Socket.IO – 基于 WebSocket 构建跨浏览器的实时应用
Socket.IO 是一个功能非常强大的框架,能够帮助你构建基于 WebSocket 的跨浏览器的实时应用.支持主流浏览器,多种平台,多种传输模式,还可以集合 Exppress 框架构建各种功能复杂 ...
- Lyft 基于 Flink 的大规模准实时数据分析平台(附FFA大会视频)
摘要:如何基于 Flink 搭建大规模准实时数据分析平台?在 Flink Forward Asia 2019 上,来自 Lyft 公司实时数据平台的徐赢博士和计算数据平台的高立博士分享了 Lyft 基 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统(转)
原文链接:http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice2/index.html?ca=drs-&ut ...
- 转: 透过CAT,来看分布式实时监控系统的设计与实现
评注: 开源的分布式监控系统 转:http://www.infoq.com/cn/articles/distributed-real-time-monitoring-and-control-syste ...
- 透过CAT,来看分布式实时监控系统的设计与实现
2011年底,我加入大众点评网,出于很偶然的机会,决定开发CAT,为各个业务线打造分布式实时监控系统,CAT的核心概念源自eBay闭源系统CAL----eBay的几大法宝之一. 在当今互联网时代,业务 ...
- 挑战海量数据:基于Apache DolphinScheduler对千亿级数据应用实践
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler 精彩回顾 近期,初灵科技的大数据开发工程师钟霈合在社区活动的线 ...
- NEO4J亿级数据全文索引构建优化
NEO4J亿级数据全文索引构建优化 一.数据量规模(亿级) 二.构建索引的方式 三.构建索引发生的异常 四.全文索引代码优化 1.Java.lang.OutOfMemoryError 2.访问数据库时 ...
随机推荐
- C语言基础之基础的输入输出
前言 学一门编程语言,不能编写让用户输入数据然后输出处理后的数据的程序那么就等于没学,而在C语言中可以用printf() 和 scanf() 函数进行输入和输出操作.这两个函数是内置的库函数,定义在 ...
- Android Gradle 导入 Kotlin gRPC
project build.gradle plugins { id "com.google.protobuf" version "0.9.1" apply fa ...
- 每天学五分钟 Liunx 0011 | 服务篇:进程
1. 进程 程序放在硬盘中,在运行它的时候加载到内存,在内存里程序以进程的方式运行,进程有唯一的 ID ,叫 PID. 写个简单的 Hellow world 程序,让它产生 PID: [root@ ...
- Elasticsearch 索引与文档的常用操作总结二:复杂条件查询
本文为博主原创,未经允许不得转载: 1. 查询所有:match_all GET /es_db/_doc/_search { "query":{ "match_all&q ...
- Verilog仿真实践
Verilog必须掌握 逻辑仿真工具(VCS)和逻辑综合工具(DC) AndOR module AndOr( output X,Y, input A,B,C ); // A B进行按位与运算 assi ...
- ORACLE Enterprise Manager Database Express(OEM-express)(遇到localhost拒绝访问情况)配置端口和启动方法
1.问题 之前一直进不去ORACLE Enterprise Manager Database Express,显示的是localhost拒绝了访问,经过查阅知道是没有配置相应端口. 2.解决方法 转载 ...
- Shell-流程控制-if-then-elif
- [转帖]oracle导出千万级数据为csv格式
当数据量小时(20万行内),plsqldev.sqlplus的spool都能比较方便进行csv导出,但是当数据量到百万千万级,这两个方法非常慢而且可能中途客户端就崩溃,需要使用其他方法. 一. sql ...
- JVM内存用量的再学习
JVM内存用量的再学习 背景 最近解决一个SQLServer的问题耗时很久. 最终找到了一个看似合理的问题解释. 但是感觉不能只是总结于数据库方面 因为为了解决这个问题增加了很多监控措施. 所以想就这 ...
- [转帖]signal 11 (SIGSEGV)错误排查
https://www.jianshu.com/p/a4250c72d391 jni调试最蛋疼的就是signal 11 (SIGSEGV), code 1 (SEGV_MAPERR), fault a ...