什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集RDD,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。
RDD包含很多分区,由一系列分区构成,一个分区构成一个逻辑分片。

1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。宽依赖和窄依赖。
4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
1.1. 创建RDD
1)由一个已经存在的Scala集合创建。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
2)由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
val rdd2 = sc.textFile("hdfs://node1.beicai.cn:9000/words.txt")
2.3. RDD编程API
2.3.1. Transformation
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
常用的Transformation:
|
转换 |
含义 |
|
map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
|
filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
|
flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
|
mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
|
mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
|
sample(withReplacement, fraction, seed) |
根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
|
union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
|
intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
|
distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
|
groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
|
reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
|
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) |
|
|
sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
|
sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 |
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
|
cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
|
cartesian(otherDataset) |
笛卡尔积 |
|
pipe(command, [envVars]) |
|
|
coalesce(numPartitions) |
|
|
repartition(numPartitions) |
|
|
repartitionAndSortWithinPartitions(partitioner) |
2.3.2. Action
|
动作 |
含义 |
|
reduce(func) |
通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 |
|
collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
|
count() |
返回RDD的元素个数 |
|
first() |
返回RDD的第一个元素(类似于take(1)) |
|
take(n) |
返回一个由数据集的前n个元素组成的数组 |
|
takeSample(withReplacement,num, [seed]) |
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
|
takeOrdered(n, [ordering]) |
|
|
saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
|
saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
|
saveAsObjectFile(path) |
|
|
countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
|
foreach(func) |
在数据集的每一个元素上,运行函数func进行更新。 |
2.3.4练习
启动spark-shell
/usr/local/spark-1.5.2-bin-hadoop2.6/bin/spark-shell --master spark://node1.beicai.cn:7077
常用transformation举例:
Map:返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
Filter:返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
flatMap:与map类似,区别是原RDD中的元素经map处理后只能生成一个元素,而原RDD中的元素经flatmap处理后可生成多个元素来构建新RDD。 举例:对原RDD中的每个元素x产生y个元素(从1到y,y为元素x的值)
Partitions :显示分区,一般与length一起使用
union:求并集,注意类型要一致
#intersection求交集
Join 操作,根据key 聚合 ,有join,leftjoin,rightjoin
GroupByKey: 根据可以进行分组
Cogroup:和join很像,但是会先在每个集合中聚合
Cartesian :求笛卡尔积
#spark action
val rdd1 = sc.parallelize(List(1,2,3,4,5), 2)
#collect 是把rdd转换为 数组
rdd1.collect
#reduce 前面这个_ 是一个累计值,后面是每一个数
val rdd2 = rdd1.reduce(_+_)
#count 就是有个数
rdd1.count
#top
rdd1.top(2)
#take
rdd1.take(2)
#first(similer to take(1))
rdd1.first
#takeOrdered 用法很相似,但是的反着的
rdd1.takeOrdered(3)
//想要了解更多,访问下面的地址
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
2.4 RDD的依赖关系
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
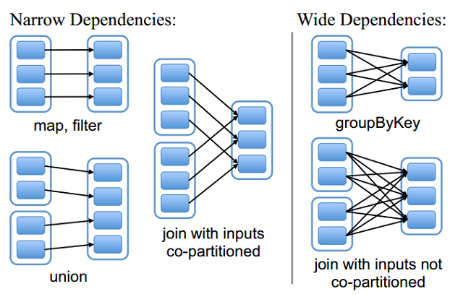
2.4.1 窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女-----也叫非shuffle算子
2.4.2 宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
总结:窄依赖我们形象的比喻为超生--也叫shuffle算子
2.4.3 Lineage
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
2.4.4 RDD的缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存多个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
2.4.5 RDD的缓存方式
什么是RDD的更多相关文章
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- Spark笔记:复杂RDD的API的理解(下)
本篇接着谈谈那些稍微复杂的API. 1) flatMapValues:针对Pair RDD中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录 这个方法我最开始接 ...
- Spark笔记:复杂RDD的API的理解(上)
本篇接着讲解RDD的API,讲解那些不是很容易理解的API,同时本篇文章还将展示如何将外部的函数引入到RDD的API里使用,最后通过对RDD的API深入学习,我们还讲讲一些和RDD开发相关的scala ...
- Spark笔记:RDD基本操作(下)
上一篇里我提到可以把RDD当作一个数组,这样我们在学习spark的API时候很多问题就能很好理解了.上篇文章里的API也都是基于RDD是数组的数据模型而进行操作的. Spark是一个计算框架,是对ma ...
- Spark笔记:RDD基本操作(上)
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark核心——RDD
Spark中最核心的概念为RDD(Resilient Distributed DataSets)中文为:弹性分布式数据集,RDD为对分布式内存对象的 抽象它表示一个被分区不可变且能并行操作的数据集:R ...
- 【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Spark Rdd coalesce()方法和repartition()方法
在Spark的Rdd中,Rdd是分区的. 有时候需要重新设置Rdd的分区数量,比如Rdd的分区中,Rdd分区比较多,但是每个Rdd的数据量比较小,需要设置一个比较合理的分区.或者需要把Rdd的分区数量 ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
- 深入理解Spark(一):Spark核心概念RDD
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
随机推荐
- 【GUI界面软件】抖音评论采集:自动采集10000多条,含二级评论、展开评论!
目录 一.背景说明 1.1 效果演示 1.2 演示视频 1.3 软件说明 二.代码讲解 2.1 爬虫采集模块 2.2 软件界面模块 2.3 日志模块 三.获取源码及软件 一.背景说明 1.1 效果演示 ...
- 09. rails 创建user用户列表
gem添加分页的依赖 #列表分页 gem 'will_paginate', '~> 3.0.pre2' bundle 安装依赖 用户列表控制器 before_filter :auth_user, ...
- node.js环境在Window和Mac中配置,以及安装cnpm和配置Less环境
Node.js 和cnpm安装 最近准备学习vue.js,但首先需要配置电脑的环境.配置node.js. 1.在node(https://nodejs.org/en/)官网上下载安装node.js,两 ...
- 关于DDD和COLA的一些总结和思考
写在前面: 其实之前一直想汇总一篇关于自己对于面向对象的思考以及实践的文章,但是苦于自己的"墨迹",一延再延,最近机缘巧合下仔细了解了一下COLA的内容,这个想法再次被勾起,所以这 ...
- 包含Symbol类型的对象遍历取key使用Reflect.ownKeys
Reflect.ownKeys(target)等同于 Object.getOwnPropertyNames 与Object.getOwnPropertySymbols 之和
- 在uGUI正交相机中实现旋转透视效果
正常uGUI使用正交相机的话,旋转是没有透视效果的,但如果能实现较简单的透视, 对一些效果表现来说还是不错的:见下图(左为透视效果): 正常思路感觉各种麻烦. 因为uGUI使用unity的x和y方向表 ...
- C数据结构:循环队列的顺序存储结构
顺序队列目录 队列的定义 定义 假溢出 空间浪费的缺点 如何解决 循环队列的缺点 *==主要的算法思想(重要)==* 如何理解循环队列(必看) 结构体代码 两种实现方法 **①循环队列,队头和队尾指针 ...
- Python:conda install 和pip install的区别
pip是个安装包的软件,conda是个环境管理的工具.conda能够安装多个python解释器,pip不行.因此conda在实际开发中是主要用来隔离不同的python版本和Tensorflow& ...
- CSS操作——列表属性
CSS中提供了一些列表属性可以用来: (1).设置不同的列表项标记为有序列表 (2).设置不同的列表项标记为无序列表 (3).设置列表项标记为图像 list-style-type(系统提供 ...
- vue 的directives一个坑
大江东去,浪淘尽,千古风流人物.故垒西边,人道是,三国周郎赤壁.乱石穿空,惊涛拍岸,卷起千堆雪.江山如画,一时多少豪杰.遥想公瑾当年,小乔初嫁了,雄姿英发.羽扇纶巾,谈笑间,樯橹灰飞烟灭.故国神游,多 ...