一文掌握数仓中auto analyze的使用
摘要:analyze执行的是否及时,在一定程度上直接决定了SQL执行的快慢。
本文分享自华为云社区《一文读懂autoanalyze使用【这次高斯不是数学家】》,作者: leapdb。
analyze执行的是否及时,在一定程度上直接决定了SQL执行的快慢。因此,GaussDB(DWS)引入了自动统计信息收集,可以做到让用户不再担心统计信息是否过期。
1. 自动收集场景
需要进行自动统计信息收集的场景通常有五个:批量DML结束时,增量DML结束时,DDL结束时,查询开始时和后台定时任务。
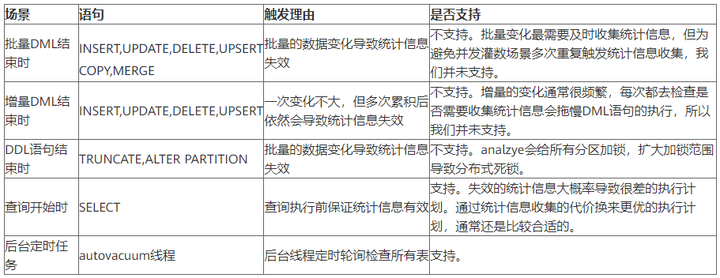
所以,为了避免对DML,DDL带来不必要的性能开销和死锁风险,我们选择了在查询开始前触发analzye。
2. 自动收集原理
GaussDB(DWS)在SQL执行过程中,会记录表增删改查相关的运行时统计信息,并在事务提交或回滚后记录到共享的内存种。
这些信息可以通过 “pg_stat_all_tables视图” 查询,也可以通过下面函数进行查询。
pg_stat_get_tuples_inserted --表累积insert条数
pg_stat_get_tuples_updated --表累积update条数
pg_stat_get_tuples_deleted --表累积delete条数
pg_stat_get_tuples_changed --表自上次analyze以来,修改的条数
pg_stat_get_last_analyze_time --查询最近一次analyze时间
因此,根据共享内存中 "表自上次analyze以来修改过的条数" 是否超过一定阈值,就可以判定是否需要做analyze了。
3. 自动收集阈值
3.1 全局阈值
autovacuum_analyze_threshold #表触发analyze的最小修改量
autovacuum_analyze_scale_factor #表触发analyze时的修改百分比
当"表自上次analyze以来修改的条数" >= autovacuum_analyze_threshold + 表估算大小 * autovacuum_analyze_scale_factor时,需要自动触发analyze。
3.2 表级阈值
--设置表级阈值
ALTER TABLE item SET (autovacuum_analyze_threshold=50);
ALTER TABLE item SET (autovacuum_analyze_scale_factor=0.1); --查询阈值
postgres=# select pg_options_to_table(reloptions) from pg_class where relname='item';
pg_options_to_table
---------------------------------------
(autovacuum_analyze_threshold,50)
(autovacuum_analyze_scale_factor,0.1)
(2 rows) --重置阈值
ALTER TABLE item RESET (autovacuum_analyze_threshold);
ALTER TABLE item RESET (autovacuum_analyze_scale_factor);
不同表的数据特征不一样,需要触发analyze的阈值可能有不同的需求。表级阈值优先级高于全局阈值。
3.3 查看表的修改量是否超过了阈值(仅当前CN)
postgres=# select pg_stat_get_local_analyze_status('t_analyze'::regclass);
pg_stat_get_local_analyze_status
----------------------------------
Analyze not needed
(1 row)
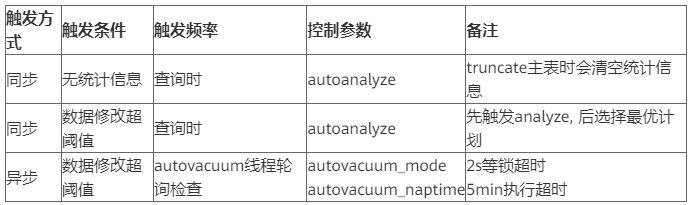
4. 自动收集方式
GaussDB(DWS)提供了三种场景下表的自动分析。
- 当查询中存在“统计信息完全缺失”或“修改量达到analyze阈值”的表,且执行计划不采取FQS (Fast Query Shipping)执行时,则通过autoanalyze控制此场景下表统计信息的自动收集。此时,查询语句会等待统计信息收集成功后,生成更优的执行计划,再执行原查询语句。
- 当autovacuum设置为on时,系统会定时启动autovacuum线程,对“修改量达到analyze阈值”的表在后台自动进行统计信息收集。
5.冻结统计信息
5.1 冻结表的distinct值
当一个表的distinct总是估算不准,例如:数据扎堆儿重复场景。如果表的distinct值固定,可以通过以下方式冻结表的distinct值。
postgres=# alter table lineitem alter l_orderkey set (n_distinct=0.9);
ALTER TABLE postgres=# select relname,attname,attoptions from pg_attribute a,pg_class c where c.oid=a.attrelid and attname='l_orderkey';
relname | attname | attoptions
----------+------------+------------------
lineitem | l_orderkey | {n_distinct=0.9}
(1 row) postgres=# alter table lineitem alter l_orderkey reset (n_distinct);
ALTER TABLE postgres=# select relname,attname,attoptions from pg_attribute a,pg_class c where c.oid=a.attrelid and attname='l_orderkey';
relname | attname | attoptions
----------+------------+------------
lineitem | l_orderkey |
(1 row)
5.2. 冻结表的全部统计信息
如果表的数据特征基本不变,还可以冻结表的统计信息,来避免重复进行analyze。
alter table table_name set frozen_stats=true;
6. 手动查看表是否需要做analyze
a. 不想在业务高峰期时触发数据库后台任务,所以不愿意打开autovacuum来触发analyze,怎么办?
b. 业务修改了一批表,想立即对这些表马上做一次analyze,又不知道都有哪些表,怎么办?
c. 业务高峰来临前想对临近阈值的表都做一次analyze,怎么办?
我们将autovacuum检查阈值判断是否需要analyze逻辑,抽取成了函数,帮助用户灵活主动的检查哪些表需要做analyze。
6.1 判断表是否需要analyze(串行版,适用于所有历史版本)
-- the function for get all pg_stat_activity information in all CN of current cluster.
CREATE OR REPLACE FUNCTION pg_catalog.pgxc_stat_table_need_analyze(in table_name text)
RETURNS BOOl
AS $$
DECLARE
row_data record;
coor_name record;
fet_active text;
fetch_coor text;
relTuples int4;
changedTuples int4:= 0;
rel_anl_threshold int4;
rel_anl_scale_factor float4;
sys_anl_threshold int4;
sys_anl_scale_factor float4;
anl_threshold int4;
anl_scale_factor float4;
need_analyze bool := false;
BEGIN
--Get all the node names
fetch_coor := 'SELECT node_name FROM pgxc_node WHERE node_type=''C''';
FOR coor_name IN EXECUTE(fetch_coor) LOOP
fet_active := 'EXECUTE DIRECT ON (' || coor_name.node_name || ') ''SELECT pg_stat_get_tuples_changed(oid) from pg_class where relname = ''''|| table_name ||'''';''';
FOR row_data IN EXECUTE(fet_active) LOOP
changedTuples = changedTuples + row_data.pg_stat_get_tuples_changed;
END LOOP;
END LOOP; EXECUTE 'select pg_stat_get_live_tuples(oid) from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into relTuples;
EXECUTE 'show autovacuum_analyze_threshold;' into sys_anl_threshold;
EXECUTE 'show autovacuum_analyze_scale_factor;' into sys_anl_scale_factor; EXECUTE 'select (select option_value from pg_options_to_table(c.reloptions) where option_name = ''autovacuum_analyze_threshold'') as value
from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into rel_anl_threshold; EXECUTE 'select (select option_value from pg_options_to_table(c.reloptions) where option_name = ''autovacuum_analyze_scale_factor'') as value
from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into rel_anl_scale_factor; --dbms_output.put_line('relTuples='||relTuples||'; sys_anl_threshold='||sys_anl_threshold||'; sys_anl_scale_factor='||sys_anl_scale_factor||'; rel_anl_threshold='||rel_anl_threshold||'; rel_anl_scale_factor='||rel_anl_scale_factor||';');
if rel_anl_threshold IS NOT NULL then
anl_threshold = rel_anl_threshold;
else
anl_threshold = sys_anl_threshold;
end if;
if rel_anl_scale_factor IS NOT NULL then
anl_scale_factor = rel_anl_scale_factor;
else
anl_scale_factor = sys_anl_scale_factor;
end if; if changedTuples > anl_threshold + anl_scale_factor * relTuples then
need_analyze := true;
end if; return need_analyze;
END; $$
LANGUAGE 'plpgsql';
6.2 判断表是否需要analyze(并行版,适用于支持并行执行框架的版本)
-- the function for get all pg_stat_activity information in all CN of current cluster.
--SELECT sum(a) FROM pg_catalog.pgxc_parallel_query('cn', 'SELECT 1::int FROM pg_class LIMIT 10') AS (a int); 利用并发执行框架
CREATE OR REPLACE FUNCTION pg_catalog.pgxc_stat_table_need_analyze(in table_name text)
RETURNS BOOl
AS $$
DECLARE
relTuples int4;
changedTuples int4:= 0;
rel_anl_threshold int4;
rel_anl_scale_factor float4;
sys_anl_threshold int4;
sys_anl_scale_factor float4;
anl_threshold int4;
anl_scale_factor float4;
need_analyze bool := false;
BEGIN
--Get all the node names
EXECUTE 'SELECT sum(a) FROM pg_catalog.pgxc_parallel_query(''cn'', ''SELECT pg_stat_get_tuples_changed(oid)::int4 from pg_class where relname = ''''|| table_name ||'''';'') AS (a int4);' into changedTuples;
EXECUTE 'select pg_stat_get_live_tuples(oid) from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into relTuples; EXECUTE 'show autovacuum_analyze_threshold;' into sys_anl_threshold;
EXECUTE 'show autovacuum_analyze_scale_factor;' into sys_anl_scale_factor; EXECUTE 'select (select option_value from pg_options_to_table(c.reloptions) where option_name = ''autovacuum_analyze_threshold'') as value
from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into rel_anl_threshold; EXECUTE 'select (select option_value from pg_options_to_table(c.reloptions) where option_name = ''autovacuum_analyze_scale_factor'') as value
from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into rel_anl_scale_factor; dbms_output.put_line('relTuples='||relTuples||'; sys_anl_threshold='||sys_anl_threshold||'; sys_anl_scale_factor='||sys_anl_scale_factor||'; rel_anl_threshold='||rel_anl_threshold||'; rel_anl_scale_factor='||rel_anl_scale_factor||';');
if rel_anl_threshold IS NOT NULL then
anl_threshold = rel_anl_threshold;
else
anl_threshold = sys_anl_threshold;
end if;
if rel_anl_scale_factor IS NOT NULL then
anl_scale_factor = rel_anl_scale_factor;
else
anl_scale_factor = sys_anl_scale_factor;
end if; if changedTuples > anl_threshold + anl_scale_factor * relTuples then
need_analyze := true;
end if; return need_analyze;
END; $$
LANGUAGE 'plpgsql';
6.3 判断表是否需要analyze(自定义阈值)
-- the function for get all pg_stat_activity information in all CN of current cluster.
CREATE OR REPLACE FUNCTION pg_catalog.pgxc_stat_table_need_analyze(in table_name text, int anl_threshold, float anl_scale_factor)
RETURNS BOOl
AS $$
DECLARE
relTuples int4;
changedTuples int4:= 0;
need_analyze bool := false;
BEGIN
--Get all the node names
EXECUTE 'SELECT sum(a) FROM pg_catalog.pgxc_parallel_query(''cn'', ''SELECT pg_stat_get_tuples_changed(oid)::int4 from pg_class where relname = ''''|| table_name ||'''';'') AS (a int4);' into changedTuples;
EXECUTE 'select pg_stat_get_live_tuples(oid) from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into relTuples; if changedTuples > anl_threshold + anl_scale_factor * relTuples then
need_analyze := true;
end if; return need_analyze;
END; $$
LANGUAGE 'plpgsql';
通“优化器触发的实时analyze”和“后台autovacuum触发的轮询analyze”,GaussDB(DWS)已经可以做到让用户不再关心表是否需要analyze。建议在最新版本中试用。
一文掌握数仓中auto analyze的使用的更多相关文章
- 在HUE中将文本格式的数据导入hive数仓中
今天有一个需求需要将一份文档形式的hft与fdd的城市关系关系的数据导入到hive数仓中,之前没有在hue中进行这项操作(上家都是通过xshell登录堡垒机直接连服务器进行操作的),特此记录一下. - ...
- Hive 数仓中常见的日期转换操作
(1)Hive 数仓中一些常用的dt与日期的转换操作 下面总结了自己工作中经常用到的一些日期转换,这类日期转换经常用于报表的时间粒度和统计周期的控制中 日期变换: (1)dt转日期 to_date(f ...
- 一文读懂数仓中的pg_stat
摘要:GaussDB(DWS)在SQL执行过程中,会记录表增删改查相关的运行时统计信息,并在事务提交或回滚后记录到共享的内存中.这些信息可以通过 "pg_stat_all_tables视图& ...
- 使用Oozie中workflow的定时任务重跑hive数仓表的历史分期调度
在数仓和BI系统的开发和使用过程中会经常出现需要重跑数仓中某些或一段时间内的分区数据,原因可能是:1.数据统计和计算逻辑/口径调整,2.发现之前的埋点数据收集出现错误或者埋点出现错误,3.业务数据库出 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
- 【企业流行新数仓】Day01:新版本对比、业务和表的介绍☆、Hive、ODS层、DWD层
一.2.0版本对比 二.业务介绍 1.术语 SKU SPU UV: user views 用户浏览总量[浏览量] PV:page views 页面浏览总量 2.电商业务表结构 表名 同步方式 字段名 ...
- 数仓建设 | ODS、DWD、DWM等理论实战(好文收藏)
本文目录: 一.数据流向 二.应用示例 三.何为数仓DW 四.为何要分层 五.数据分层 六.数据集市 七.问题总结 导读 数仓在建设过程中,对数据的组织管理上,不仅要根据业务进行纵向的主题域划分,还需 ...
- 数仓建设中最常用模型--Kimball维度建模详解
数仓建模首推书籍<数据仓库工具箱:维度建模权威指南>,本篇文章参考此书而作.文章首发公众号:五分钟学大数据,公众号中发送"维度建模"即可获取此书籍第三版电子书 先来介绍 ...
- 【大数据-课程】高途-天翼云侯圣文-Day2:离线数仓搭建分解
一.内容介绍 昨日福利:大数据反杀熟 今日:数据看板 离线分析及DW数据仓库 明日:实时计算框架及全流程 一.数仓定义及演进史 1.概念 生活中解答 2.数据仓库的理解 对比商品仓库 3.数仓分层内容 ...
- 文盘Rust -- rust 连接云上数仓 starwift
作者:京东云 贾世闻 最近想看看 rust 如何集成 clickhouse,又犯了好吃懒做的心理(不想自己建环境),刚好京东云发布了兼容ck 的云原生数仓 Starwfit,于是搞了个实例折腾一番. ...
随机推荐
- Chromium Command Buffer原理解析
Command Buffer 是支撑 Chromium 多进程硬件加速渲染的核心技术之一.它基于 OpenGLES2.0 定义了一套序列化协议,这套协议规定了所有 OpenGLES2.0 命令的序列化 ...
- 后缀自动机 (SAM) 的构造及应用
cnblogs 怎么又炸了. 为什么又可爱又强的 xxn 去年 9 月就会的科技樱雪喵现在还不会呢 /kel. 感觉 SAM 的教程已经被前人写烂了啊.那就写点个人学习过程中对 SAM 的理解. 参考 ...
- QString类常用属性
目录 1. isNull() 2. isEmpty() 3. length() 4. truncate() 5. indexOf()/lastIndexOf() 6. arg() 7. at() 8. ...
- HTML-8
(一)引用数据类型 object function array object JavaScript对象用花括号来书写 对象属性是name:value由逗号分隔 var x={firstname:&qu ...
- PostgreSQL 提升子连接与 ORACLE 子查询非嵌套
查询优化器对子查询一般采用嵌套执行的方式,即父查询中的每一行,都要执行一次子查询,这样子查询会执行很多次,效率非常低. 例如 exists.not exists 逐行取出经行匹配处理,项目中使用子查询 ...
- JavaScript高级程序设计笔记05 基本引用类型
基本引用类型 引用值(对象)是某个特定引用类型的实例.引用类型是把数据和功能组织到一起的结构. 引用类型有时也被称为对象定义,因为它们描述了自己的对象应有的属性和方法. Date 参考了Java早期版 ...
- go基础-函数
概述 在任何语言中函数都是极其重要的内容,业务功能都是由一个或多个函数组合完成.go语言是函数式编程语言,函数是一等公民,可以被传递.有函数类型,go语言有三种类型的函数,普通函数.匿名函数(Lamb ...
- json数组根据某属性去重
数据: let arry = [ {name: "张三", age: 23, work: '计算机'}, {name: "王五", age: 29, work: ...
- String.trim()含义
就是去除两端空格,目前只用到了这个.
- 黑客玩具入门——4、漏洞扫描与Metasploit
1.Legion漏洞扫描分析工具 Legion是Sparta的一个分支,它是一个开源的.易于使用的.超级可扩展的.半自动的网络渗透测试框架.它是一款Kali Linux系统默认集成的Python GU ...