昇腾CANN 7.0 黑科技:大模型推理部署技术解密
本文分享自华为云社区《昇腾CANN 7.0 黑科技:大模型推理部署技术解密》,作者:昇腾CANN。
近期,随着生成式AI、大模型进入公众视野,越来越多的人意识到抓住AI的爆发就是抓住未来智能化变革的契机。AI基础设施如何快速部署使用,以及如何提升推理性能,逐渐成为众多企业关注的焦点。
CANN作为最接近昇腾AI系列硬件产品的一层,通过软硬件联合设计,打造出适合昇腾AI处理器的软件架构,充分使能和释放昇腾硬件的澎湃算力。针对大模型推理场景,CANN最新发布的CANN 7.0版本有机整合各内部组件,支持大模型的量化压缩、分布式切分编译、分布式加载部署,并在基础加速库、图编译优化、模型执行调度等方面针对大模型进行极致性能优化。
自动并行切分实现大模型分布式部署:
针对LLM模型巨大的计算和内存开销,CANN提供自动并行切分能力,实现大模型在昇腾集群的分布式部署。自动并行切分过程可以分为5个步骤:
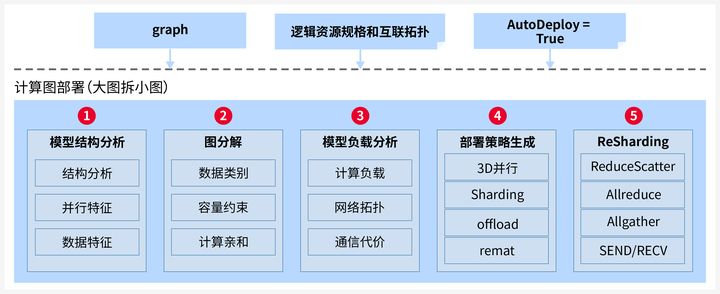
自动切分的策略以物理集群信息和模型结构为输入,进行负载切分优化的空间建模,通过策略生成-策略应用-性能模拟的多轮迭代,进而搜索得到优化的切分部署策略。
KV Cache机制减少重复推理计算:
LLM模型推理计算的过程可以分为prompt处理和后续输出token的自回归计
算。前者有大量数据的矩阵乘,是典型的计算密集型处理,而后者随着LLM的执行,会积累越来越多的对话内容,基于历史输出计算得到新的token输出。以“盘古是一个语言模型”为例,输入内容后,每一个token都会生成对应的Q、K和V向量,在attention部分进行矩阵乘和softmax等计算。在这个过程中,用户prompt加上已经输出的token都要作为下一次迭代的输入,都要重新计算相应的QKV,这造成了大量的重复计算。
为此,业界提出了KV Cache方法,将已经出现的token所计算得出的K和V向量保存在内存,仅计算最新一个token的QKV,再进行矩阵乘和softmax计算,本质上是以空间换时间。
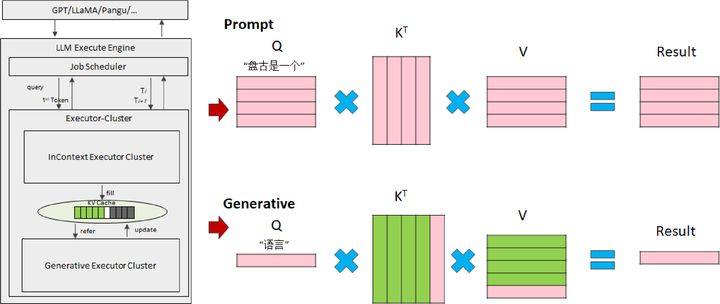
目前,CANN已经全面支持KV Cache,并实现了KV Cache的分布式存储、更新和复位,有效加速自回归阶段计算。
量化技术有效降低内存占用:
量化是AI领域的常见技术,在大模型时代,量化还有不同的特点和要求。LLM的权重分布相对均匀,而FM数据存在很多离群点。传统量化算法中,直接抛弃离群点或将所有离群点纳入量化范围,均会导致精度损失,为此CANN支持仅Weight量化,INT8量化场景相比FP16可降低50%权重内存空间占用。
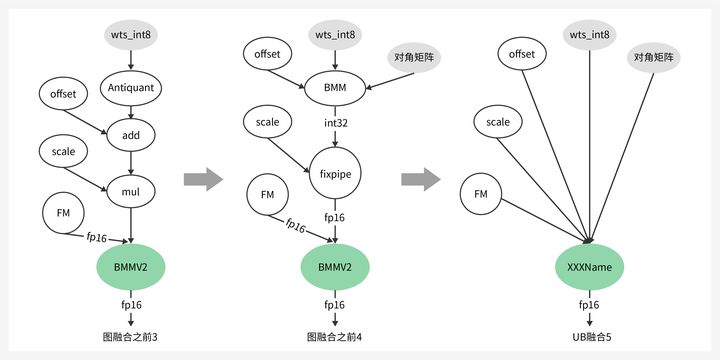
同时支持KV Cache量化,KV Cache本质上是空间换时间,随模型层数、sequence length的线性增长,KV Cache量化可降低一半存储。
FlashAttention融合算子降低访存开销:
LLM模型中大量使用了Multi-Head Atten-tion结构,这不仅带来了巨大的计算量,保存数据所需的内存容量也是计算系统的关键瓶颈。对此,业界提出了FlashAttention融合算子,其原理是对attention处理过程进行切分和计算等价,使得attention的多个步骤可以在一个算子中完成,并且通过多重循环、每次处理一小部分数据,以近似流式的方式访问HBM,减少了HBM访问的总数据量,并能够将计算和数据搬运更好的重叠隐藏。
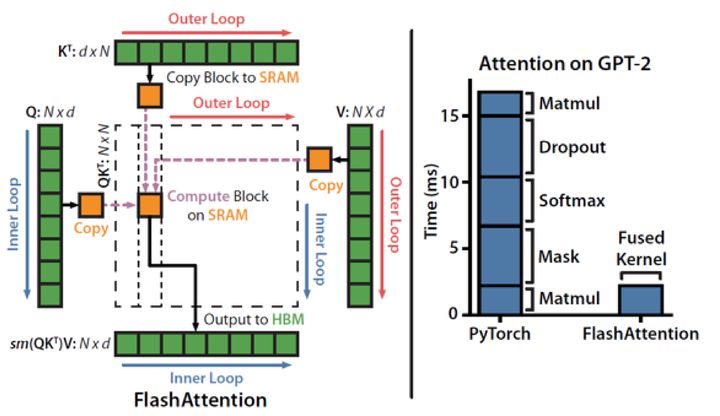
来源:https://arxiv.org/pdf/2205.14135.pdf
CANN针对昇腾AI处理器的HBM和缓存大小,以及数据搬运通路,优化实现FlashAttention融合算子,充分利用片上缓存,提升Attention处理性能可达50%。
Auto Batching调度提升算力利用率:
面对input阶段compute-bound、output阶段memory-bound的计算特征,以及LLM业务的时延需求,CANN支持多个input和output计算集群的异构部署,并支持LLM计算任务的auto batching调度,提升AI算力利用率。它的原理是将不同的服务请求尽可能地聚合处理:在input阶段通过单batch和预置的多种sequence length模型推理,尽量降低每个请求的启动开销;在output阶段以iteration粒度调度多个服务,尽可能拼成batch处理,以提升计算密度,平衡计算和访存。
支持Torch.Compile计算图提高编程效率:
为了使开发者能够更简单的将LLM在昇腾平台运行推理,CANN实现了PyTorch的计算图支持。开发者只需要使用PyTorch原生的torch.-compile接口,CANN使能的NPU后端就会对PyTorch生成的FX Graph进行接管,基于trace逻辑将AtenIR转换为AIR,再进行端到端的图编译深度优化,从而降低推理阶段的内存需求、提升计算性能,同时最大程度的减少开发者的修改工作。
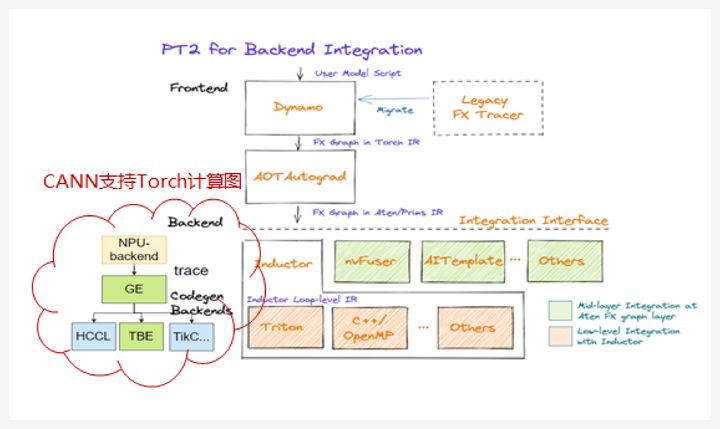
来源:https://pytorch.org/get-started/pytorch-2.0/
这里有一个CANN大模型推理上手的示例。在编译阶段使用ATC工具对pb或onnx模型进行编译,命令参数与CV等经典AI模型类似,只是增加了集群信息和切分信息的输入。打开集群开关以及并行切分开关,同时传入集群配置文件和切分方式的配置文件,ATC就会在编译过程中自动实现模型的切分和通信算子插入。
atc --model=./matmul2.pb --soc_version=Ascend910 --output=test910_parallel --distributed_cluster_build=1 --cluster_config=./numa_config_910_2p.json --enable_graph_parallel="1" --graph_parallel_option_path=./parallel_option.json

在执行阶段,通过LoadGraph接口载入om离线模型,CANN会将各个模型切片载入到相应的昇腾AI处理器device上,然后再使用既有的RunGraph接口即可执行推理。
经过计算/通信并行、图优化、算子调优等优化,LLAMA 65B推理性能可较优化前提升一倍以上,端到端耗时可以达到8s左右,仍有提升空间。
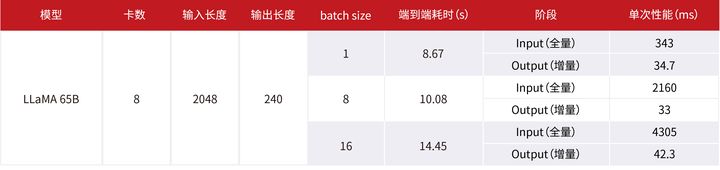
总而言之,在大模型技术日新月异不断迭代的时代背景下,昇腾CANN将会持续深耕大模型优化&加速技术,比如继续探索面向在线服务的调度优化,缩短服务时延;基于计算图的weight预取与Cache驻留优化,提升访存性能;亲和FlashAttention业界最新融合算子,提升计算性能;支持更丰富的量化计算组合、模型稀疏,降低内存占用...随着大模型规模化商业落地,以昇腾CANN为核心的昇腾AI基础软硬件平台,将持续提升大模型推理部署场景的核心竞争力,为客户提供最优选择!
昇腾CANN 7.0 黑科技:大模型推理部署技术解密的更多相关文章
- CANN5.0黑科技解密 | 别眨眼!缩小隧道,让你的AI模型“身轻如燕”!
摘要:CANN作为释放昇腾硬件算力的关键平台,通过深耕先进的模型压缩技术,聚力打造AMCT模型压缩工具,在保证模型精度前提下,不遗余力地降低模型的存储空间和计算量. 随着深度学习的发展,推理模型巨大的 ...
- 三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署 TensorFlow 模型导出 使用 SavedModel 完整导出模型 不仅包含参数的权值,还包含计算的流程(即计算 ...
- 2.69分钟完成BERT训练!新发CANN 5.0加持
摘要:快,着实有点快. 现在,经典模型BERT只需2.69分钟.ResNet只需16秒. 啪的一下,就能完成训练! 本文分享自华为云社区<这就是华为速度:2.69分钟完成BERT训练!新发CAN ...
- 三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署
本文学习笔记参照来源:https://tf.wiki/zh/basic/basic.html 前文:三分钟快速上手TensorFlow 2.0 (上)——前置基础.模型建立与可视化 tf.train. ...
- 黑科技如何制造人类V2.0?
黑科技泛指人类尚未成熟但具有巨大潜力的科学技术,智能手机.大数据.扫码支付.电子地图等等都曾属于黑科技范畴,随着时间的推移,它们慢慢成熟,且展现出巨大的能力,影响人类进程,最终黑科技转变成人类伟大的创 ...
- ACM: FZU 2105 Digits Count - 位运算的线段树【黑科技福利】
FZU 2105 Digits Count Time Limit:10000MS Memory Limit:262144KB 64bit IO Format:%I64d & ...
- [自己动手玩黑科技] 1、小黑科技——如何将普通的家电改造成可以与手机App联动的“智能硬件”
NOW, 步 将此黑科技传授予你~ 一.普通家电控制电路板分析 普通家电,其人机接口一般由按键和指示灯组成(高端的会稍微复杂,这里不考虑) 这样交互过程,其实就是:由当前指示灯信息,按照操作流程按相应 ...
- iOS 关于UITableView的黑科技
UITableView是我们最常用的控件了,今天我就来介绍一些关于UITableView的黑科技和一些注意的地方. 1.修改左滑删除按钮的高度 左滑删除这是iOS最先发明的,之后安卓开始模仿. ...
- Cnblogs关于嵌入js和css的一些黑科技
#pong .spoiler{cursor:none;display:inline-block;line-height:1.5;}sup{cursor:help;color:#3BA03B;} Pon ...
- Python3实现ICMP远控后门(中)之“嗅探”黑科技
ICMP后门 前言 第一篇:Python3实现ICMP远控后门(上) 第二篇:Python3实现ICMP远控后门(上)_补充篇 在上两篇文章中,详细讲解了ICMP协议,同时实现了一个具备完整功能的pi ...
随机推荐
- [最优化DP]决策单调性
决策单调性的概念&证明工具: 决策单调性,是在最优化dp中的可能出现的一种性质,利用它我们可以降低转移的复杂度. 首先dp中会有转移,每个状态都由若干个状态转移而来,最优化dp比较特殊,只能由 ...
- 虹科干货 | 什么是Redis数据集成(RDI)?
大量的应用程序.日益增长的用户规模.不断扩展的技术需求,以及对即时响应的持续追求.想想这些是否正是你在经历的.也许你尝试过自己构建工具来应对这些需求,但是大量的编码和集成工作使你焦头烂额.那你是否知道 ...
- 云端golang开发,无需本地配置,能上网就能开发和运行
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 需求 学习golang的时候,需要一个IDE,还需要一 ...
- 机器学习从入门到放弃:硬train一发手写数字识别
一.前言 前面我们了解了关于机器学习使用到的数学基础和内部原理,这一次就来动手使用 pytorch 来实现一个简单的神经网络工程,用来识别手写数字的项目.自己动手后会发现,框架里已经帮你实现了大部分的 ...
- (int argc, char *argv[])在MCU中的调试使用
这里主要讲了基于RTT的 finsh->MSH_CMD_EXPORT 方法,在串口终端中调用自定义函数,并传入参数的方法. 在传统的MCU开发中 当我们需要测试一个函数在传入不同参数时的运算结果 ...
- STM8 STM32 GPIO 细节配置问题
在MCU的GPIO配置中我们经常需要预置某一 IO 上电后为某一固定电平, 如果恰好我们需要上电后的某IO为高电平, 那么在配置GPIO的流程上面需要特别注意. 配置如下: (以下问题仅在STM8 / ...
- 【Javaweb】瑞吉外卖你冲不冲?冲冲!冲!冲冲!(数据库环境搭建)(maven项目搭建)一
图形界面创建数据库(Navicat) 命令行方式创建 瑞吉项目一共涉及到十一张表 导入表结构,既可以使用上面的图形界面,也可以使用MySQL命令: 通过命令导入表结构时,注意sql文件不要放在中文目录 ...
- 一行代码解决IE停用后无法继续使用IE弹窗功能的问题
微软在2023年2月14日通过Edge浏览器更新,彻底封死IE.Windows Update中没有记录.开始菜单中的IE以及桌面IE图标双击自动打开Edge,默认程序设置了IE也没有任何效果,仅能通过 ...
- 【Codeforces Global Round 12】 C2 - Errich-Tac-Toe题解(思维)
题面 题目要求不能有有三个连续相同的'X'或'O',注意到这样的连续串它们的横纵坐标之和是连续变化的,考虑将它们按照横纵坐标之和对 \(3\)的模值分组,因为这样分组后相邻的三个相同字符就被分到了三个 ...
- JSR223取样器详解
相比于BeanShell 取样器,JSR223取样器具有可大大提高性能的功能(编译)如果需要,一定要使用JSR223取样器编写脚本是更好的选择!!! 属性描述名称:显示的此取样器的描述性名称,可自定义 ...