解读知识蒸馏模型TinyBert
摘要:本篇文章的重点在于改进信息瓶颈的优化机制,并且围绕着高纬空间中互信息难以估计,以及信息瓶颈优化机制中的权衡难题这两个点进行讲解。
本文分享自华为云社区《【云驻共创】美文赏析:大佬对变分蒸馏的跨模态行人重识别的工作》,作者:启明。
论文讲解:《Farewell to Mutual Information: Variational Distillation for CrossModal Person Re-identification》
论文概述
本篇文章的重点在于改进信息瓶颈的优化机制,并且围绕着高纬空间中互信息难以估计,以及信息瓶颈优化机制中的权衡难题这两个点进行讲解。
信息瓶颈研究背景
此报告一共分为3个部分,为了便于理解,我们先介绍一下信息瓶颈的研究背景。
就“信息瓶颈”这个概念而言,在2000年左右的时候才正式被学者提出,其理想状态下的目标,是获得一个最小充分标准。意思就是,把所有那些对任务有帮助的判别性信息全提取出来,同时又过滤掉冗余性的信息。从实践的角度来说,信息瓶颈的部署就是直接优化下图红色框出部分即可:
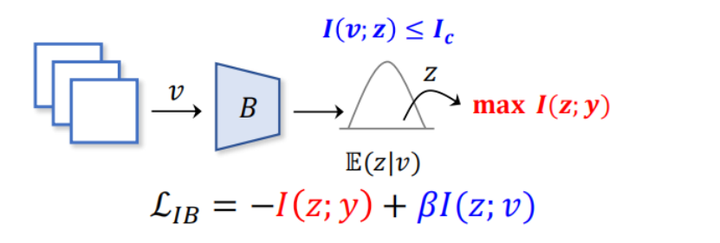
迄今为止,信息瓶颈作为一种信息论指导下的表征学习方法,已经被广泛应用于多个领域,包括计算机视觉、自然语言处理、神经科学等等,当然还有一些学者已经把信息瓶颈用于揭开神经网络黑箱的问题上。
但是,互信息有3个不足之处:
1. 其有效性严重依赖互信息估算精度
虽然信息瓶颈有着先进的构思和理念,但是它的有效性严重依赖于互信息的估算精度。根据现在大量的理论分析,以及目前很多的工作在实践中的尝试,我们可以知道在高维空间中,算互信息其实是非常有力的。
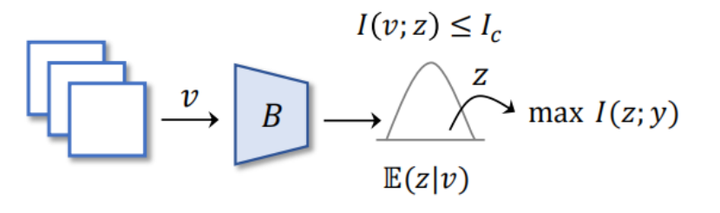
从上图表达式上来看,
v代表着观察量,大家可以把它直接理解成一个高维度的特征图;
z代表是代表它的一个表征,可以把它理解成是一个经过信息瓶颈压缩得到的一个低纬度的表征。
现在我们需要算它们两个之间的互信息。

理论上来说我们需要知道这三个分布才可以实现互信息的计算(如上图)。但是很可惜的是,对于观察量其本身的潜在分布,我们只能有限个数据点,而并不能通过这些有限个数据点去观测到其具体的潜在分布,更不用说空间变量z的相关信息了。
那么,如果我们用一个代参的估计器在解空间去猜呢?也不是很可行。因为其可信度不是很高,而且去年ICLR(国际表征学习大会)上有很多篇工作已经证明了,互信息估计器很大可能只是一个噱头。
2. 预测性能与简洁性之间难以权衡

另外一个比较严重的问题是,信息平台优化本质上是一种权衡。这意味着,这种机制会把表征的判别性和简洁性放到天平的两侧(如上图)。
想消除冗余信息,那么也会附带的造成部分判定性信息的损失;但如果你想保留更多的判别性信息,那么也会有相当部分的冗余信息跟着被保存下来。这样一来,就会使得信息瓶颈最开始定的目标成为不可能实现的目标。
或是咱们从优化目标上来看。假设我们给一个非常大的β,这意味着模型此时更倾向于做删减。显而易见,压缩力度是提上来了,但是此时模型就没怎么保存判定性。
同样的,假如说现在给一个非常小的β(假设是10^(-5)),那么相对来说模型就更倾向于完成第一项互信息给的目标。但此时模型就不管“去冗余”的事了。
所以我们在选取β的过程中,其实就是权衡两个目标在不同任务下的重要性,也就印证了文章开头讲的问题,信息瓶颈的优化的本质是一种权衡。
3. 对多视图问题乏力
除上述2个问题之外,我们还可以发现,信息瓶颈虽然可以通过任务给定的标签,对任务所包含的信息进行二元化定义,也就是说我们可以根据是否对任务有帮助来定义判别性信息(红色部分)和冗余信息(蓝色部分)。

但是任务涉及到多视图的数据的时候,信息瓶颈没有确切的依据从多视图的角度把信息再次写出来,后果就是使得它对视图变化比较敏感,或者说,就是缺乏应对多视图问题的能力。
变分信息瓶颈工作介绍
说完传统的信息瓶颈,我们再引入一篇里程碑式的工作:《变分信息瓶颈》。此工作发表在2017年的ICLR上面,其一个突出贡献,是引入了“变分推断”(如下图):把互信息转化成了熵的形式。虽然这篇工作没有很好的解决我们前面提到的问题,但这个思路几乎启发了后续的所有相关工作。
把互信息转化到熵,是一个非常大的进步。但是还是有几点不足之处:
1. 表征判别性能与简洁性之间的trade-off没得到解决
遗憾的是变分信息瓶颈,也没能解决优化机制中判别性与简洁性之间的权衡难题。被优化的天平依然随着λ摆动。
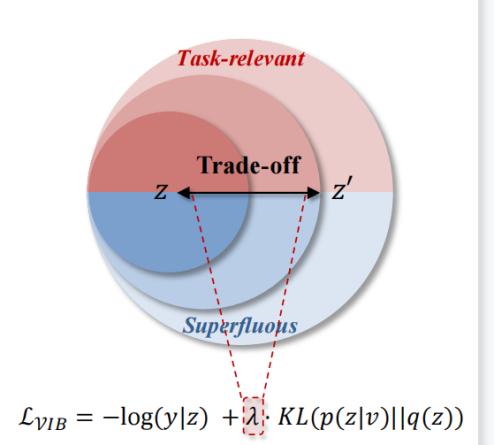
2. 无法保证变分上界的有效性
第二个问题就是变分信息瓶颈优化的时候,其实是优化其找的一个上界,但上界的有效性是值得商榷的。因为它需要空间变量z的一个鲜艳分布Q(z)去逼近一个潜在分布P(z)。然而,这在实际中这其实是很难保证的。

3. 涉及重参数、重采样等复杂操作
第三点就是优化这一项变分推断的结果,会涉及到很多复杂的操作(重参数、重采样等这些不确定性很高的操作),会给训练过程增加一定的波动,使得训练可能不是很稳定,而且复杂度较高。
研究方法
上面说的几个问题,是变分信息瓶颈针对方法的通病,一定程度上阻碍了信息瓶颈的时间应用。那么,接下来讲解一下相应的解决思路,从本质上解决前面提到的所有问题。
充分性
首先需要引入“充分性”概念:z包含所有关于y的判别性信息。
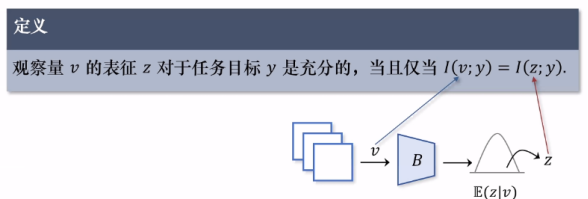
它要求信息瓶颈的编码过程不允许有判别性信息的损失,也就是说v经过信息瓶颈到达z之后,只允许消除冗余信息,当然这是一个比较理想化的要求(如上图)。
有了“充分性”概念之后,我们把观察量和其表征之间的互信息进行拆分,可以得到蓝色的冗余信息和红色的判别性信息,再根据信息处理不等式可以得到下面这行的结果。此结果意义比较大,它说明我们想要获得最小充分标准,也就是最优标准,需要经历三个子过程。
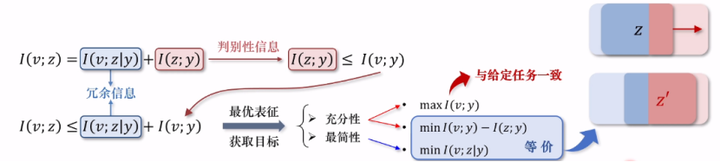
第一个子过程,其实是在提高表征z所包含的判别性信息总量的上限。为什么这样说?因为z所包含的所有内容都来源于它的观察量。所以提高观察量,它自己的判别性信息总量的上限,也就是拉高了z的它自己的上限。
而第二个子过程就是让表征z去逼近自己的判别性上限。这两项其实对应了充分性的要求。
第三个子过程的条件互信息,如前面所说,它代表目标所包含的冗余信息,因此最小化这一项就对应了最简性的目标。此处,简单说明一下“条件互信息”,它代表的是z中所包含的仅和v相关且与y无关的信息,简单来说,就是和任务没有关系的冗余信息。其实从前面的变分信息瓶颈可以看到第一个子过程,其实优化一个条件熵,也就是用观察量v初始的特征图和标签算一个交叉熵,然后进行优化。所以这一项它本质上和给定的任务是一致的,因此暂且不需要特殊处理。
至于另外两项的优化目标,他们本质上是等价的。而且值得注意的一点是这种等价关系,意味着提升表征的判别性的过程中,也在消除冗余。把原来曾经对立的两个目标拉到了天平同一侧,直接就摆脱了信息瓶颈原有的一个权衡难题,使得信息瓶颈随着最小充分标准理论上是可行的。
定理一和引理一
定理一:最小化I(v;y) − I(z;y) 等价于最小化 v,z 关于任务目标y条件熵的差值,即:
minI(v;y)−I(z;y) ⇔ min H(y|z) − H(y|v),
其中条件熵定义为H(y|z):=−∫p(z)dz∫p(y|z)log p(y|z)dy .
引理一:当表征z对任务目标y做出的预测与其观察量 v的相同时,表征 z对于任务目标 y具备充分性,即:
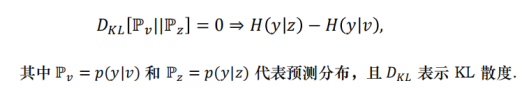
为了达到前面制定的目标,还需要避免高维空间中互信息的估算,因此文章中提出了非常详细的重点的定理和引理这两项内容。
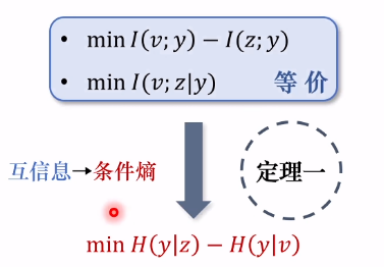
为了方便理解,可以看上面的逻辑图。定理一通过对蓝色的互信息的优化,直接转化成条件熵之间的差。也就是说,如果想实现上面两个(蓝色的)目标,可以转变为最小化条件熵的差即可。
而引理一,在此基础上把上面的结果转化成了一项KL散度,而 KL散度里面其实就是两个logits。

也就是实践当中只需要优化这么一项简单的KL散度,就能同时达到表征的充分性和最简性。照比传统的信息瓶颈来说,还是简单很多的。
网络结构本身很简单:一个编码器一个信息瓶颈,再加一个KL散度。考虑到它的形式,将这方法也命名为变分自蒸馏(Variational Self-Distillation),简称VSD。
和互信息瓶颈原有的优化机制做一个对比,可以发现VSD有三个比较突出的优点:
- 无需进行互信息估算且更精确地拟合
- 解决优化时的权衡难题
- 不涉及重参数、采样等繁琐操作
Consistency
仅保存判别性且满足视图间一致性的信息,以增强表征对于视图变化的鲁棒性。
定义:表征 z1, z2 满足视图间一致性,当且仅当 I(z1;y) = I(v1v2;y) = I(z2;y)。
在有了定理一和引理一之后,接下来的任务是要把变分自蒸馏扩展到多视图的学习背景下。
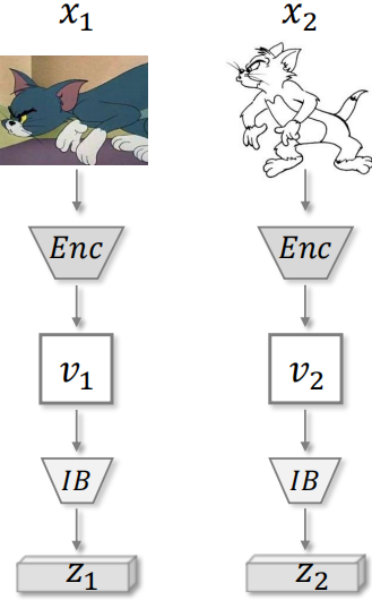
如上图,这是一个最基本的框架。两张图像x1,x2,输入到一个编码器中,得到两个原始的高维特征图v1和v2,然后把v1和v2送到信息瓶颈,得到两个压缩过的低维度表征z1和z2。

如上图所示,此项互信息是同一视图下的观察量和其表征之间的互信息。但拆分的时候要注意和VSD中的处理的区别,因为这里对信息的划分依据是它是否反映了视图间的共性,而不再是判别性和冗余性的要求,所以它拆分出来的结果有I(Z1;V2) = i(v2;v1|y) + I(z1;y)。

之后再根据视图是否满足判别性要求,对层次的视图间共性的信息进行二次划分,得到两项冗余信息和判别信息(如上图)。
如果要想提升表征对于视图变化的鲁棒性,以及进而提升任务的精度,只需要保持I(z1;y)(红色部分)就可以了,I(v1;z1|v2)(蓝色部分)和I(v2;v1|y)(绿色部分)都要丢掉。优化的目标如下:
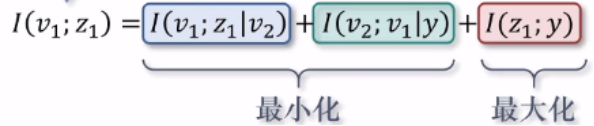
定理二:给定两个满足充分性的观察量 v1, v2, 其对应的表征 z1和 z2 满足视图间一致性,当且仅当满足此条件:I(v1;z1|v2) + I(v2;z2|v1)≤0 and I(v2;v1|y) + I(v1;v2|y) ≤ 0
定理二可用来阐述视图间一致性的本质。视图间一致性在本质上就是要求消除视图特异性信息,也消除和任务没有关系的冗余信息来最大化的提升表征。
两种方法
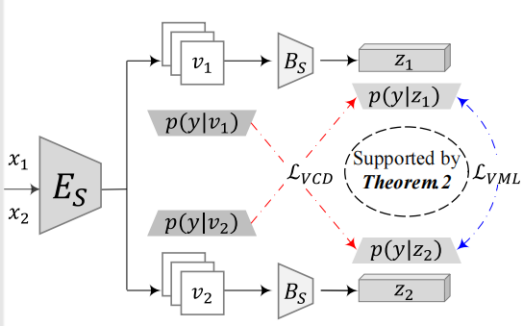
消除视图特异性信息
变分互学习(Variational Mutual Learning, VML,对应上图蓝色部分):最小化 z1, z2 预测分布之间的JS散度以消除其所包含的视图特异性信息,具体目标如下:
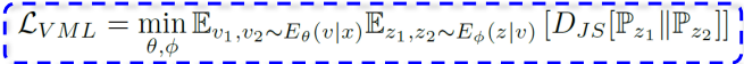
消除冗余信息
变分交叉蒸馏(Variational Cross-Distillation, VCD,对应上图红色部分):在留存的视图一致性信息中,通过交叉地优化观察量与不同视图表征之间的KL散度提纯判别性信息,同时剔除冗余信息,具体目标如下( v1 与 z1 同理):
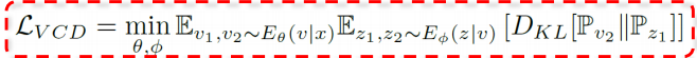
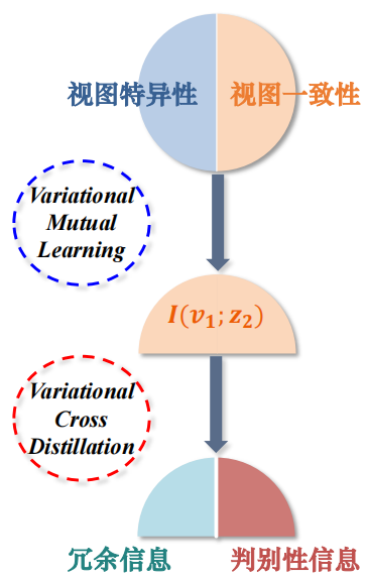
上图是这两种方法的处理的结构图。原本是有特异性和一致性,根据VML来把信息进行二元划分,再用变分互学习把特性的信息全部消除掉了,然后剩下的橙色的一致性信息还有两块:冗余信息和判决信息。这个时候就需要变分交叉蒸馏,把冗余信息(绿色部分)分别消掉,只保留判别性信息(红色的部分)。
实验结果
接下来我们来分析一下文章中的实验部分。为了验证方法的有效性,我们把前文中提到的三种方法:变分自蒸馏、交叉蒸馏,还有互学习,应用到跨模态行人群识别的问题。
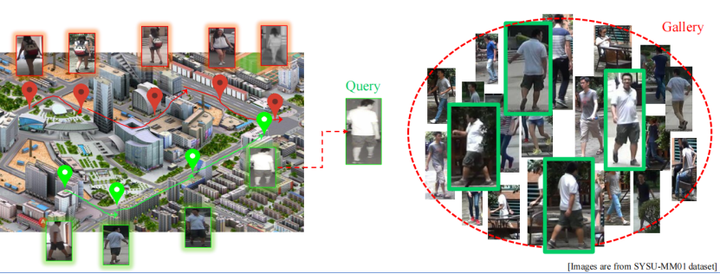
跨模态行人群识别问题,是计算机学的子问题,核心目标是为给定的人像匹配另一个模态下的照片。举例来说,以下图绿色框标记出来的红外图像来说,我们希望在一个图像库中找到对应同一个人的可见光图像,要么是用红外光去找可见光,或者用可见光去找红外光。
框架总览
模型结构总览:
模型总体一共包括三条独立的分支,且每条分支仅包含一个编码器和一个信息瓶颈。具体结构见下图。
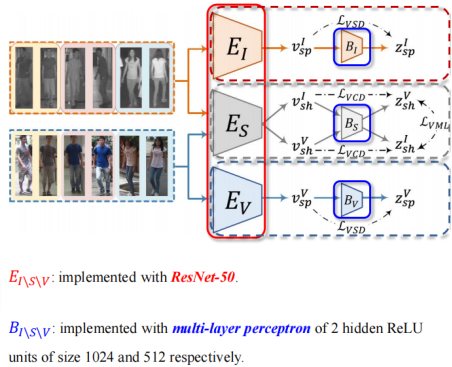
这里值得注意的一点是,由于上下两个分支,橙色的部分只接受和处理红外光东西,蓝色的只接受和处理可见光的东西,所以他们不涉及多视图,因而用VSD和它们绑定即可。
中间这条分支训练的时候,会同时接受并处理两个模态的数据。因此训练的时候,用VCD,就是变分交叉蒸馏和变分互学习协同训练分析。
损失函数总览:
损失函数由两部分构成,即论文中提出的变分蒸馏,以及 Re-ID 最常用的训练约束。注意 VSD 只约束单模态分支,而 VCD 协同 VML 一起约束跨模态分支。
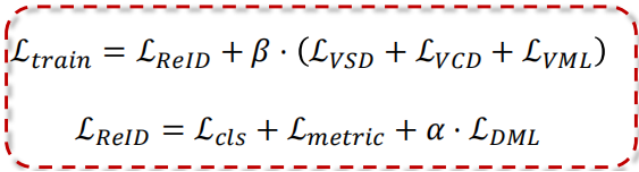
实验标准:SYSU-MM01 & RegDB
SYSU-MM01:
数据集共包括 491 个目标的 287,628 张可见光图像以及 15,792 张红外光图像。每个目标的图像都来源于 6 个不重叠摄像头分别在室内和户外进行拍摄的拍摄结果。
评测标准包含全场景查询( all-search )和室内查询( indoorsearch )。论文中所有实验结果都采用标准评测准则。

RegDB:
数据集共包括 412 个目标,且每个目标对应十张在同一时刻拍摄的可见光图像以及红外光图像。
评测标准包括可见光搜红外(visible-to-infrared)以及红外搜可见光(infrared-to-visible)。最终评测结果为十次实验的平均精度,且每次实验都开展于随机划分的评估集。

结果分析

我们把跨模态行人群识别的相关工作大体分为了4类:Network Design(网络框架设计)、Metric Design(度量设计)、Generative(生成类)、Representation(表征学习类)。
此方法作为第一份探索表征学习的工作,在不涉及生存过程以及复杂的网络结构的条件下,性能还能这么大幅度的领先竞争对手。而且也正是个原因,此文章提出的变分蒸馏损失可以非常轻松的融入到不同类别的方法,挖掘更大的潜力。
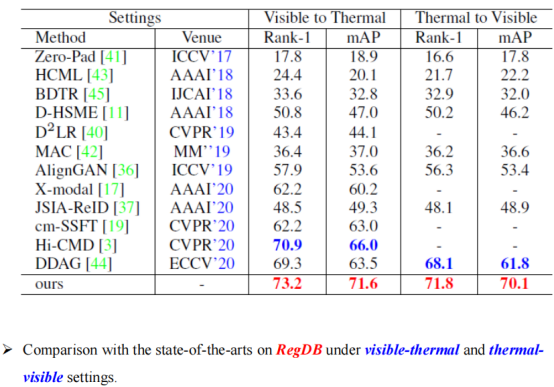
在另外一个数据集上,我们可以看到一个类似的结果。
接下来我们将选一些代表性的消融实验,分析一下方法在实践中的有效性。
开始之前我们需要明确,接下来所有的实验:观察量v的维度统一设置成Re-ID社区常用的2048;表征的维度就默认成256;信息瓶颈统一采用GS互信息估计器。
消融实验:单一模态分支条件下,变分蒸馏 vs 信息瓶颈
在不考虑多视图条件下,仅关注表征的充分性。
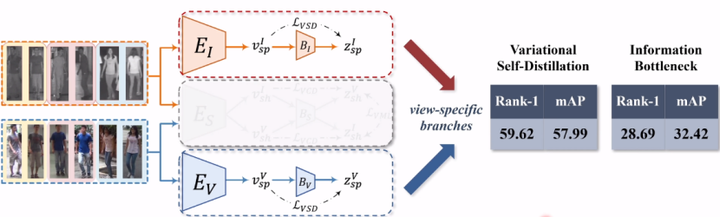
如上图,我们可以观察到变分自蒸馏可以带来巨额的性能提升。28.69至59.62,非常直观的数,说明了变分自蒸馏可以有效的提升表征的判别性,大量去除冗余信息的同时,提炼出更多有价值的信息。
消融实验:多模态分支条件下,变分蒸馏 vs 信息瓶颈
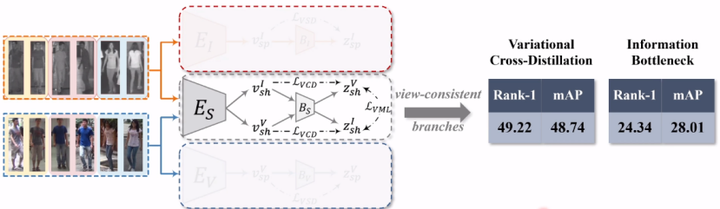
我们再来看多视图下面的结果。当我们只用跨模态分支做测试的时候,发现两个现象:
一是,变分蒸馏的方法的性能是有所下降的。刚刚是59,而现在只有49。这里我们推测是被抛弃的一些模态特异性信息。中间分值保留同时满足两个特点信息,所以会先抛去那些模态特异性信息。但对被抛弃的模态特异性信息里面,也具备相当的判别性,因此就满足模态一致性的代价,即,判别性损失带来的精度下降。
二是传统信息瓶颈的性能,在多模态的条件下,变化其实并不是很大。刚刚是28,现在是24。我们认为是传统的信息瓶颈并不能很好的去辨别一致性和特异性信息,因为其根本就不关注多视图问题,也根本就没有能力去处理这个问题。所以说多视图的条件并不会给其带来显著性的波动。
消融实验:三分支条件下,变分蒸馏 vs 信息瓶颈
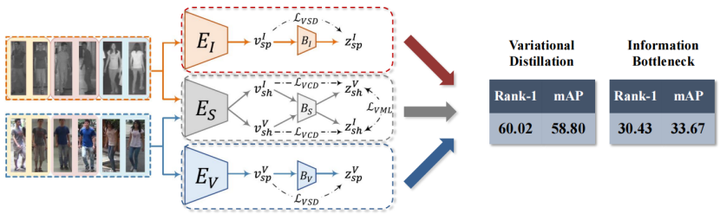
在双分支的基础上,再添加了中间这条分支之后,模型的总体性能基本没有变化。我们可以得出以下结论:
上下两条分分支,只要满足了判别性信息,信息就可以得以保存下来。
而中间这条分支保存的信息要满足两个要求。其中一个是满足判别性要求,也就是说中间这条分支所保存的信息,其实是上下两个信息的一个子集。
反观信息瓶颈,三个分支能给它带来的提升还是比较明显的。因为它哪条分支都不能完整的保存判别性信息,更不要说再去顾及“多视图”这个事情。
消融实验:不同压缩率的情况下,“充分性”对比
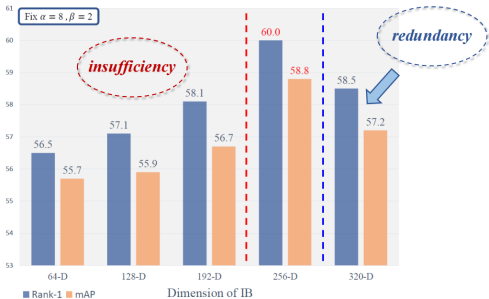
我们再看表征的压缩率对性能的影响。按照Re-ID设计的统一标准,原始的特征图维度设计成2048。
我们通过调整表征v对模型总体的性能产生的变化。当维度小于256的时候,性能会随着维度的上升不断的升高,我们推测是因为当压缩率压缩太厉害的时候,模型再怎么强,都没有那么多通道用来保存足够的判别性信息,就容易导致非充分的现象。
而当维度超过256的时候,发现性能反而开始下降。关于这一点我们认为是多出来的那部分通道,反而使得一部分冗余信息也可以保留下来,这样就造成了整体判别性和泛化性的事情降低。此时这种现象被称之为“冗余”(Redundancy)。
为了更好的展示不同方法的差别,我们用TFNE把不同的特征空间合并到了一个平面上(如下图)。
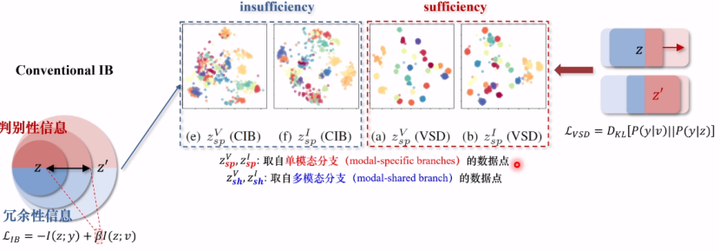
我们先针对充分性展开分析,就是VSD和传统信息瓶颈的对比。上标“V”“I”代表的是可见光和红外光下的数据,而下标的 Sp代表的是View specific,也就是说他们取自于单模态的分析。
我们可以看到传统信息瓶颈的特征空间可以说是混乱不堪,说明模型根本就没有办法清晰的分辨不同目标所属的类别。换句话来说,就是判别性信息损失严重;而VSD情况完全相反是,虽然说不同模态之间的特征空间还是有不小的差别,因为所保存的判决性信息就相当一部分属于模态特异性信息,但是能看到几乎每一个错误都是清晰分明,说明模型在VSD的帮助下可以更好的满足充分性。
我们再来看下面这张图,下标的sh代表他们来自于shared branch,他们来自于多模态的分支,上标“V”“I”依然代表了可见光以及红外光的数据点。
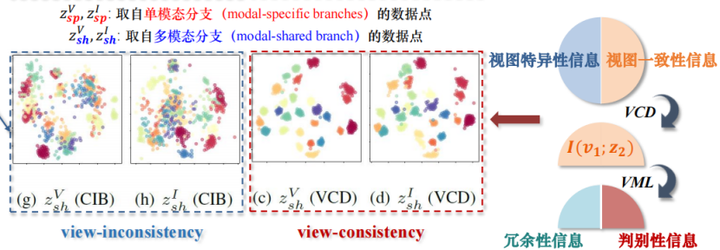
同样的信息瓶颈的特征空间,在多视图的条件下依然是混乱不堪。而且如果不作说明的话,其实基本无法分辨上下这两张图到底哪个是单模态,哪个是多模态。这也就验证了前面的观点:传统的信息瓶颈根本没有能力去应对多视图的问题。

经过变分交叉蒸馏处理的特征空间,虽然照比VSD有一些松散(因为视图的要求难免造成一些判别性信息的损失),但是单看两个模态的特征空间的重合度是很高的,侧面说明方法对一致性信息提出了有效性。
接下来,我们把不同模态的数据投射到同一个特征空间,用橙色和蓝色分别代表红外光图像数据点和可见光图像数据点。
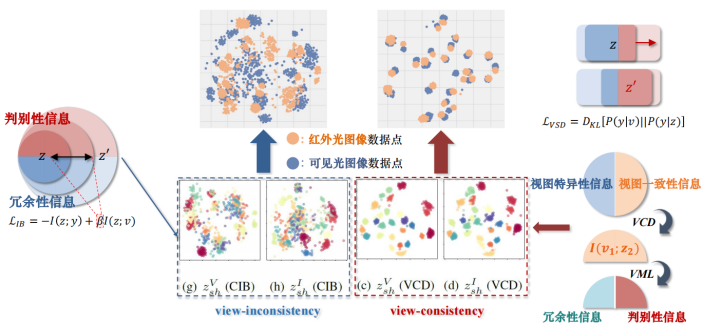
我们可以看到在变分交叉蒸馏作用的帮助下,不同模态的特征空间几乎完全吻合。对比信息瓶颈的结果,可以非常直观的说明变分交叉蒸馏的有效性。
代码复现
性能对比:Pytorch vs Mindspore
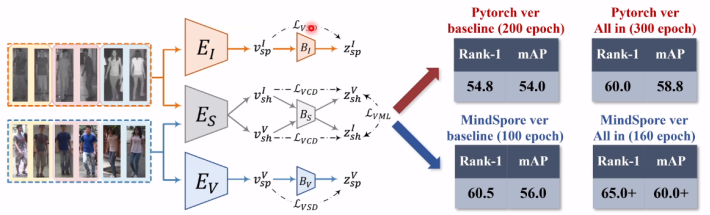
无论是用PyTorch还是用MindSpore,它们都是用来训练模型,而性能测试则是需要用得到的模型把特征提取出来,送到对应数据及官方支持的测试文件,因此这个结果的对比肯定是公平的。
我们能看到无论是baseline,还是从整个框架来看(由于右下角的实验现在只跑了一半,我只能先放一个中间),无论从精度上来说,还是从训练的时长来说,MindSpore得出来的模型还是比PyTorch是要好不少。
如果对MindSpore感兴趣可以前往学习一下:https://www.huaweicloud.com/product/modelarts.html
本文整理自【内容共创系列】IT人加薪新思路,认证华为云签约作者,赢取500元稿酬和流量扶持!→查看活动详情
解读知识蒸馏模型TinyBert的更多相关文章
- R语言解读多元线性回归模型
转载:http://blog.fens.me/r-multi-linear-regression/ 前言 本文接上一篇R语言解读一元线性回归模型.在许多生活和工作的实际问题中,影响因变量的因素可能不止 ...
- 知识蒸馏(Distillation)
蒸馏神经网络取名为蒸馏(Distill),其实是一个非常形象的过程. 我们把数据结构信息和数据本身当作一个混合物,分布信息通过概率分布被分离出来.首先,T值很大,相当于用很高的温度将关键的分布信息从原 ...
- 【DKNN】Distilling the Knowledge in a Neural Network 第一次提出神经网络的知识蒸馏概念
原文链接 小样本学习与智能前沿 . 在这个公众号后台回复"DKNN",即可获得课件电子资源. 文章已经表明,对于将知识从整体模型或高度正则化的大型模型转换为较小的蒸馏模型,蒸馏非常 ...
- Deeplearning知识蒸馏
Deeplearning知识蒸馏 merge paddleslim.dist.merge(teacher_program, student_program, data_name_map, place, ...
- 【论文考古】知识蒸馏 Distilling the Knowledge in a Neural Network
论文内容 G. Hinton, O. Vinyals, and J. Dean, "Distilling the Knowledge in a Neural Network." 2 ...
- R语言解读一元线性回归模型
转载自:http://blog.fens.me/r-linear-regression/ 前言 在我们的日常生活中,存在大量的具有相关性的事件,比如大气压和海拔高度,海拔越高大气压强越小:人的身高和体 ...
- DDD学习笔录——提炼问题域之有效提炼知识的模型(三)
方式六:延迟对模型中概念的命名 对领域建模时命名很重要. 因为在不断的知识提炼过程中经常会发现已经被命名的概念与你最初理解的有出入,这时你当初的命名就会变成一个问题.其问题在于 最初选作名称的这个词 ...
- 从JVM设计角度解读Java内存模型
第十六章:Java内存模型 本文我们将重点放在Java内存模型(JMM)的一些高层设计问题,以及JMM的底层需求和所提供的保证,还有一些高层设计原则背后的原理. 例如安全发布,同步策略的规范以及一致性 ...
- Apache OFBiz源码解读之MVC模型
节点解析 request-map 你可以将其理解为controller的配置,如果你了解或使用过struts的配置或springmvc的annotation,就会发现这个定义跟它们是很相似的: [ht ...
- django基础知识之模型查询:
查询集表示从数据库中获取的对象集合 查询集可以含有零个.一个或多个过滤器 过滤器基于所给的参数限制查询的结果 从Sql的角度,查询集和select语句等价,过滤器像where和limit子句 接下来主 ...
随机推荐
- IOI2020 国家集训队作业 Part 1
日期不对,但要保证顺序正确方便查找少了啥题. 计算几何和实在不会的题没写. 9.20 CF504E Misha and LCP on Tree *3000 二分,hash,树剖 CF505E Mr. ...
- 前后端分离,前端发送过来的请求是服务器的ip还是用户的ip
前后端分离部署时,服务器A用于部署前端项目,称为前端服务器,服务器B用于部署后端项目,称为后端服务器.后端服务器通过开放API的方式,向前端服务器中的前端项目提供数据或数据操作接口,以此实现前端与后端 ...
- JZYZ作业好题
文章目录 敲砖块 Circle 敲砖块 首先把砖块向左对齐, 这样选择第 ( i , j ) (i,j) (i,j)块的前提是第 ( i − 1 , j ) , ( i − 1 , j + 1 ) ( ...
- 【pwn】[SWPUCTF 2022 新生赛]InfoPrinter--格式化字符串漏洞,got表劫持,data段修改
下载附件,checksec检查程序保护情况: No RELRO,说明got表可修改 接下来看主程序: 函数逻辑还是比较简单,14行出现格式化字符串漏洞,配合pwntools的fmtstr_payloa ...
- 二分图--AcWing刷题
S 城现有两座监狱,一共关押着 N 名罪犯,编号分别为 1∼N. 他们之间的关系自然也极不和谐. 很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突. 我们用"怨气值"( ...
- 按键1按下数码管显示1,按键2按下数码管显示2,按键3按下8个LED灯实现流水灯效果;
#include "reg52.h" //此文件中定义了单片机的一些特殊功能寄存器 #include<intrins.h> //因为要用到左右移函数,所以加入这个头文件 ...
- JAVA学习9/29
1.继承extends//关键字 1.1.测试:子类继承父类后,能使用子类对象调用父类方法吗? 可以,因为子类继承父类后,这个该方法就属于子类了. 当然可以使用子类对象来调用 1.2.在实际开发中,满 ...
- C++20语言核心特性的变化
using for Enumeration Values 对比一下C++20前后的区别: enum class State { open, progress, done = 9 }; // Bef ...
- Codeforces Round 894 (Div. 3)
Codeforces Round 894 (Div. 3) A. Gift Carpet 题意:判断一列一个字母有没有"vika" 思路:挨个枚举每一列 #include<b ...
- 使用 Guava Retry 优雅的实现重试机制
王有志,一个分享硬核Java技术的互金摸鱼侠 加入Java人的提桶跑路群:共同富裕的Java人 大家好,我是王有志.今天我会通过一个真实的项目改造案例和大家聊一聊如何优雅的实现 Java 中常用的的重 ...