ELK日志收集记录
logstash在需要收集日志的服务器里运行,将日志数据发送给es
在kibana页面查看es的数据
es和kibana安装:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch cat << EOF >/etc/yum.repos.d/elasticsearch.repo
[elasticsearch]
name=Elasticsearch repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
EOF yum install -y --enablerepo=elasticsearch elasticsearch
# 安装完成后,在终端里可以找到es的密码
# 修改密码:'/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic'
# config file: /etc/elasticsearch/elasticsearch.yml
# network.host: 0.0.0.0 允许其他服务器访问
# http.port 修改成可以外部访问的端口
# 启动es
systemctl start elasticsearch.service
# 测试是否可以访问:curl --cacert /etc/elasticsearch/certs/http_ca.crt -u elastic https://localhost:es_host
# 如果要在其他服务器里访问的话,需要先把证书移过去:/etc/elasticsearch/certs/http_ca.crt,直接复制证书的内容,在客户端保存成一个证书文件即可
# 在客户端里测试是否可以访问:curl --cacert path_to_ca.crt -u elastic https://localhost:es_host
# install kibana
cat << EOF >/etc/yum.repos.d/kibana.repo
[kibana-8.x]
name=Kibana repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
# kibana和es可以安装到同一台服务器
yum install -y kibana
# /etc/kibana/kibana.yml 修改server.port为外部可以访问的端口,server.host修改为0.0.0.0允许其他服务器访问,elasticsearch部分的可以先不用设置,
# root用户使用:/usr/share/kibana/bin/kibana --allow-root
systemctl start kibana.service
# 首次打开kibana页面需要添加elastic的token,使用如下命令生成token
# /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
# 登录的时候也需要es的用户名和密码
# 登录成功之后,/etc/kibana/kibana.yml的底部会自动添加elasticsearch的连接信息
需要收集日志的服务器里安装logstash:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch cat <<EOF > /etc/yum.repos.d/logstash.repo
[logstash-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF yum install -y logstash
ln -s /usr/share/logstash/bin/logstash /usr/bin/logstash # install filebeat
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
cat <<EOF > /etc/yum.repos.d/filebeat.repo
[elastic-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
yum install -y filebeat
ln -s /usr/share/filebeat/bin/filebeat /usr/bin/logstash #filebeat->logstash->ES
#filebeat从具体目录里拿文件的内容发送给logstash,logstash将数据发送给es
midr -m 777 -p /data/logstash
cat <<EOF >/data/logstash/filebeat.conf
filebeat.inputs:
- type: log
paths:
- /your_log_path/*.log
output.logstash:
hosts: ["127.0.0.1:5044"]
EOF cat <<EOF >/data/logstash/logstash.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline. input {
beats {
port => 5044
client_inactivity_timeout => 600
}
} filter{
mutate{
remove_field => ["agent"]
remove_field => ["ecs"]
remove_field => ["event"]
remove_field => ["tags"]
remove_field => ["@version"]
remove_field => ["input"]
remove_field => ["log"]
}
} output {
elasticsearch {
hosts => ["https://es_ip_address:es_port"]
index => "log-from-logstash"
user => "es_user_name"
password => "es_password"
ssl_certificate_authorities => "path_to_es_http_ca.crt"
}
}
EOF
#es_http_ca.crt的内容和es服务器里的/etc/elasticsearch/certs/http_ca.crt内容相同
#filter里移除一些不必要的字段 #启动
logstash -f /data/logstash/logstash.conf >/dev/null 2>&1 &
filebeat -e -c /data/logstash/filebeat.conf >/dev/null 2>&1 &
启动之后,filebeat.conf里配置的日志路径里可以copy一些文件做测试,或者已经有一些日志文件的话,都可以在kabana里看到配置的index被自动创建:
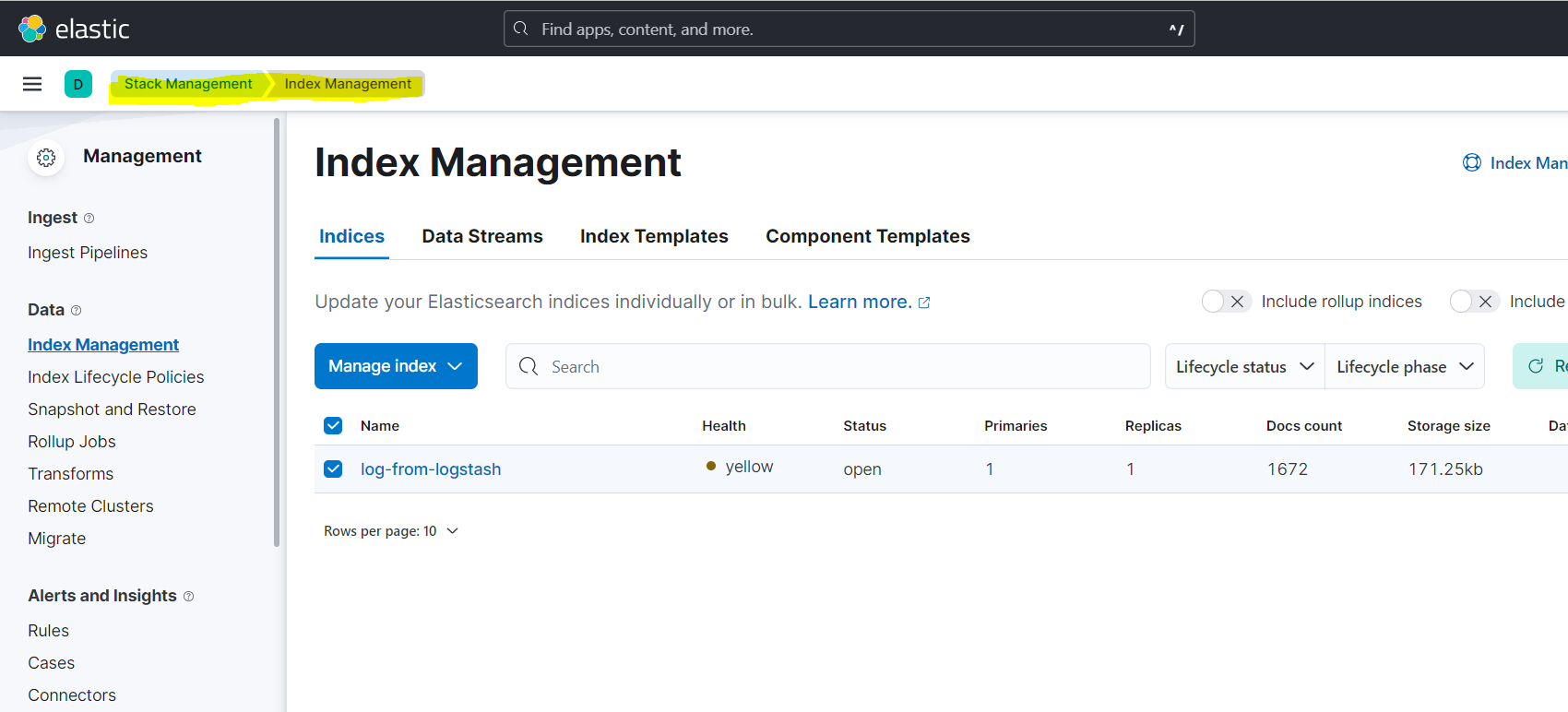
创建一个DataView就可以查看index里的文档内容:
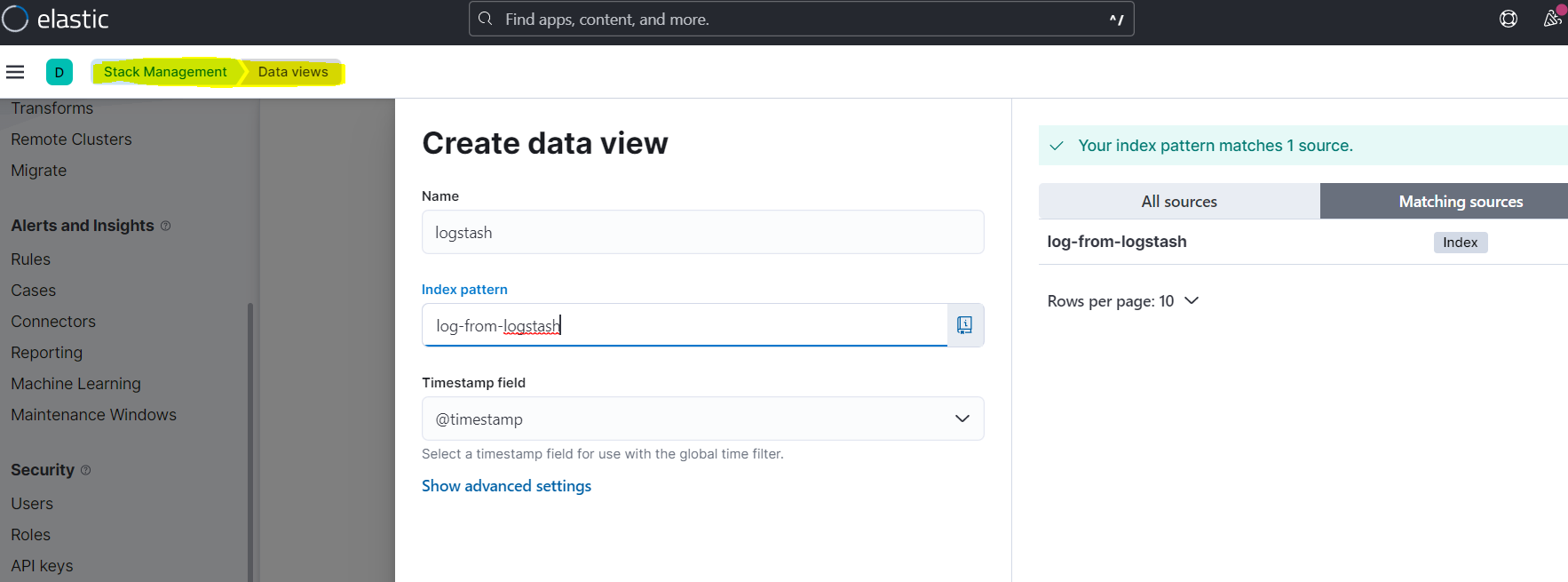
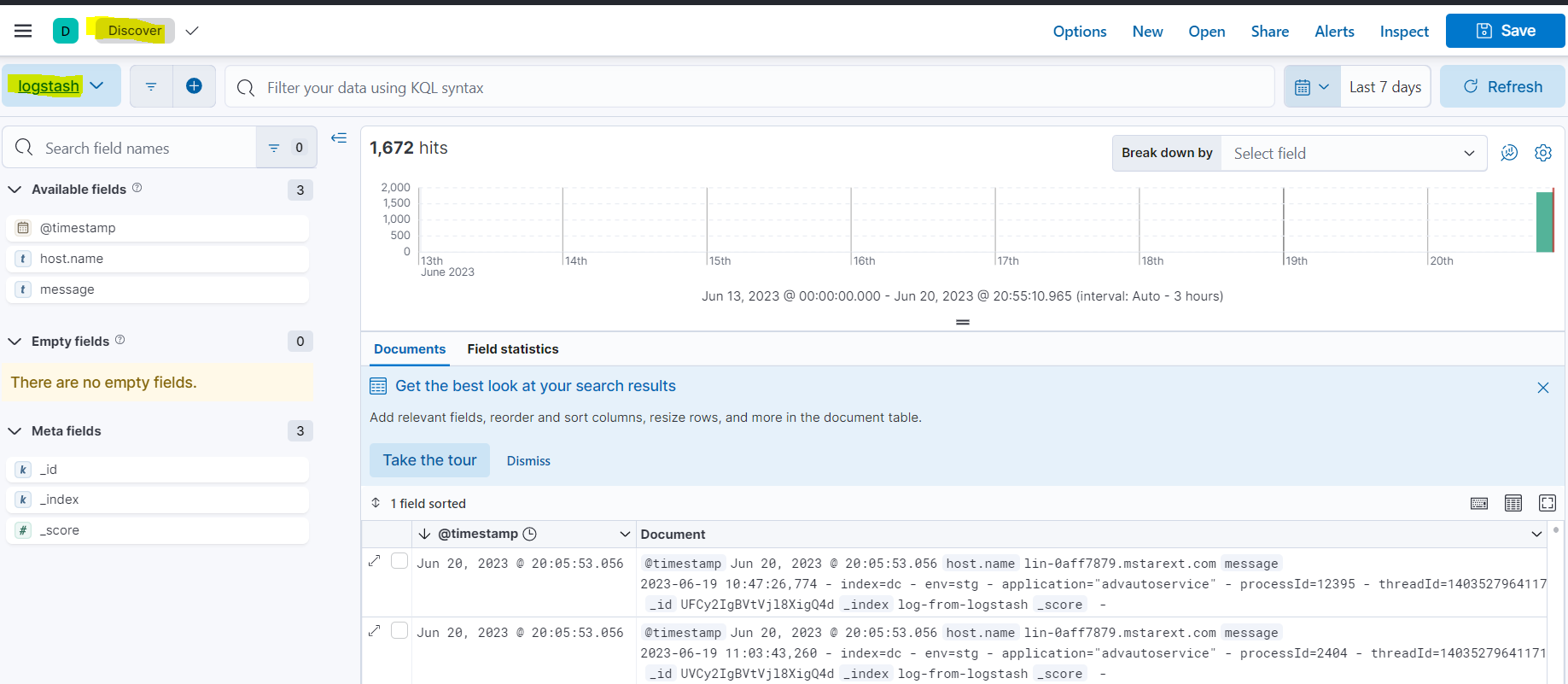
在Discover里选择配置的dataview查看数据:
ELK日志收集记录的更多相关文章
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- SpringBoot使用ELK日志收集
本文介绍SpringBoot应用配合ELK进行日志收集. 1.有关ELK 1.1 简介 在之前写过一篇文章介绍ELK日志收集方案,感兴趣的可以去看一看,点击这里-----> <ELK日志分 ...
- springboot 集成 elk 日志收集功能
Lilishop 技术栈 官方公众号 & 开源不易,如有帮助请点Star 介绍 官网:https://pickmall.cn Lilishop 是一款Java开发,基于SpringBoot研发 ...
- ELK日志收集分析系统配置
ELK是日志收益与分析的利器. 1.elasticsearch集群搭建 略 2.logstash日志收集 我这里的实现分如下2步,中间用redis队列做缓冲,可以有效的避免es压力过大: 1.n个ag ...
- ELK 日志收集系统
传统系统日志收集的问题 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下. 通常,日志被分 ...
- ELK日志收集平台部署
需求背景 由于公司的后台服务有三台,每当后台服务运行异常,需要看日志排查错误的时候,都必须开启3个ssh窗口进行查看,研发们觉得很不方便,于是便有了统一日志收集与查看的需求. 这里,我用ELK集群,通 ...
- Linux下单机部署ELK日志收集、分析环境
一.ELK简介 ELK是elastic 公司旗下三款产品ElasticSearch .Logstash .Kibana的首字母组合,主要用于日志收集.分析与报表展示. ELK Stack包含:Elas ...
- elk 日志收集 filebeat 集群搭建 php业务服务日志 nginx日志 json 7.12版本 ELK 解决方案
难的不是技术,难的是业务.熟悉业务流程才是最难的. 其实搜索进来的每一个人的需求不一样,希望你能从我的这篇文章里面收获到. 建议还是看官方文档,更全面一些. 一.背景 1,收集nginx acces ...
- ELK日志收集分析平台 (Elasticsearch+Logstash+Kibana)使用说明
使用ELK对返回502的报警进行日志的收集汇总 eg:Server用户访问网站返回502 首先在zabbix上找到Server的IP 然后登录到elk上使用如下搜索条件: pool_select:X. ...
- ELK日志收集
目前日志的痛点 运维要经常登陆到服务器上拿日志给开发.测试 每次都是出问题后才去看日志,不能提前通过日志预判问题 如果是集群服务,日志将要从多台机器取 开发人员搞出来的日志不规范,没有标准.日志目录不 ...
随机推荐
- 保持唯一性,请停止使用【python3 内置hash() 函数】
问题: 如图,用hash() 筛重时竟然出现了重复. 如下图: hash字符串时,同一窗口的是一致的,不同窗口结果竟然不同. 原因: python的字符串hash算法并不是直接遍历字符串每个字符去计算 ...
- [BUUCTF]Web刷题记录
为提升观感体验,本篇博文长期更新,新题目以二次编辑形式附在最后 [ACTF2020 新生赛]Exec 打开后发现网页是关于执行一个ping指令,经过测试是直接执行的,所以就直接命令执行了 127.0. ...
- w11默认调用ie浏览器方法
作为公司的一个it人员,最近发现w11不能不能调用ie,导致公司的系统不能正常使用,因为后台插件室默认调用ie,如果重新写插件太麻烦,所以百度了下,亲测可用,目前,公司电脑已经可以正常使用,具体方法如 ...
- [Web服务容器/Apache Tomcat]WINDOWS系统下:一台机器部署多个[解压版]Tomcat
以windows为例. 1 思路 1.1 前置条件 已成功配置JDK (JAVA_HOME / Path) 控制面板>所有控制面板项>系统>高级系统设置>系统变量(S): JA ...
- 如何优雅的申请一个属于自己的ChatGPT账号
前言 GPT-4是一种语言模型,是基于GPT-3推出的下一代自然语言处理模型.与之前的GPT模型一样,GPT-4是一种基于深度学习技术的神经网络模型,可以自动地生成人类水平的文本.回答问题.完成翻译任 ...
- 【SSM项目】尚筹网(五)项目改写:使用前后端分离的SpringSecurityJWT认证
在项目中加入SpringSecurity 1 加入依赖 <!-- SpringSecurity --> <dependency> <groupId>org.spri ...
- 【迭代器设计模式详解】C/Java/JS/Go/Python/TS不同语言实现
简介 迭代器模式(Iterator Pattern),是一种结构型设计模式.给数据对象构建一套按顺序访问集合对象元素的方式,而不需要知道数据对象的底层表示. 迭代器模式是与集合共存的,我们只要实现一个 ...
- Docker 配置阿里云或腾讯云镜像加速
1.新建 /etc/docker/daemon.json 文件,并写入以下内容: 阿里云按下面配置 sudo tee /etc/docker/daemon.json <<-'EOF' { ...
- SpringCloud Gateway 3.x 响应头添加 Skywalking TraceId
在微服务架构中,一次请求可能会被多个服务处理,而每个服务又会产生相应的日志,且每个服务也会有多个实例.在这种情况下,如果系统发生异常,没有 Trace ID,那么在进行日志分析和追踪时就会非常困难,因 ...
- awk判断整除(包含小数和负数)
awk判断整除常用的方法是用内置的int或者求余数的算符% 被整数整除 输出0-100之间能被9整除的整数 使用 num/9==int(num/9) 的判断方法可以很好实现. awk 'BEGIN{ ...