用手机写代码:基于 Serverless 的在线编程能力探索
简介:Serverless 架构的按量付费模式,可以在保证在线编程功能性能的前提下,进一步降低成本。本文将会以阿里云函数计算为例,通过 Serverless 架构实现一个 Python 语言的在线编程功能,并对该功能进一步的优化,使其更加贴近本地本地代码执行体验。
随着计算机科学与技术的发展,越来越多的人开始接触编程,也有越来越多的在线编程平台诞生。以 Python 语言的在线编程平台为例,大致可以分为两类:
- 一类是 OJ 类型的,即在线评测的编程平台,这类的平台特点是阻塞类型的执行,即用户需要一次性将代码和标准输入内容提交,当程序执行完成会一次性将结果返回;
- 另一类则是学习、工具类的在线编程平台,例如 Anycodes 在线编程等网站,这一类平台的特点是非阻塞类型的执行,即用户可以实时看到代码执行的结果,以及可以实时内容进行内容的输入。
但是,无论是那种类型的在线编程平台,其背后的核心模块( “代码执行器”或“判题机”)都是极具有研究价值,一方面,这类网站通常情况下都需要比要严格的“安全机制”,例如程序会不会有恶意代码,出现死循环、破坏计算机系统等,程序是否需要隔离运行,运行时是否会获取到其他人提交的代码等;
另一方面,这类平台通常情况下都会对资源消耗比较大,尤其是比赛来临时,更是需要突然间对相关机器进行扩容,必要时需要大规模集群来进行应对。同时这类网站通常情况下也都有一个比较大的特点,那就是触发式,即每个代码执行前后实际上并没有非常紧密的前后文关系等。
随着 Serverless 架构的不断发展,很多人发现 Serverless 架构的请求级隔离和极致弹性等特性可以解决传统在线编程平台所遇到的安全问题和资源消耗问题,Serverless 架构的按量付费模式,可以在保证在线编程功能性能的前提下,进一步降低成本。所以,通过 Serverless 架构实现在线编程功能的开发就逐渐的被更多人所关注和研究。本文将会以阿里云函数计算为例,通过 Serverless 架构实现一个 Python 语言的在线编程功能,并对该功能进一步的优化,使其更加贴近本地本地代码执行体验。
在线编程功能开发
一个比较简单的、典型的在线编程功能,在线执行模块通常情况下是需要以下几个能力:
- 在线执行代码
- 用户可以输入内容
- 可以返回结果(标准输出、标准错误等)
除了在线编程所需要实现的功能之外,在线编程在 Serverless 架构下,所需要实现的业务逻辑,也仅仅被收敛到关注代码执行模块即可:获取客户端发送的程序信息(包括代码、标准输入等),将代码缓存到本地,执行代码,获取结果,但会给客户端,整个架构的流程简图为:

关于执行代码部分,可以通过 Python 语言的 subprocess 依赖中的 Popen() 方法实现,在使用 Popen() 方法时,有几个比较重要的概念,需要明确:
- subprocess.PIPE:一个可以被用于 Popen 的stdin 、stdout 和 stderr 3 个参数的特殊值,表示需要创建一个新的管道;
- subprocess.STDOUT:一个可以被用于 Popen 的 stderr 参数的输出值,表示子程序的标准错误汇合到标准输出;
所以,当我们想要实现可以:
进行标准输入(stdin),获取标准输出(stdout)以及标准错误(stderr)的功能
可以简化代码实现为:
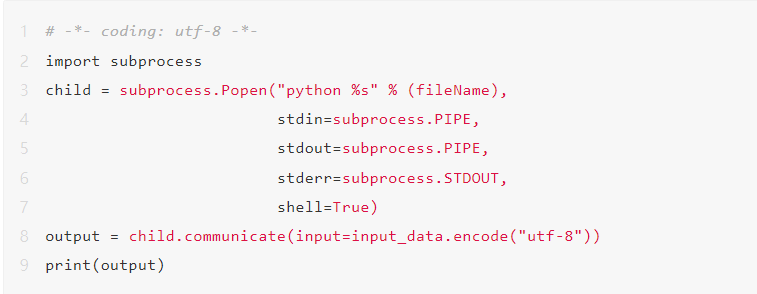
除代码执行部分之外,在 Serverless 架构下,获取到用户代码并将其存储过程中,需要额外注意函数实例中目录的读写权限。通常情况下,在函数计算中,如果不进行硬盘挂载,只有/tmp/目录是有可写入权限的。所以在该项目中,我们将用户传递到服务端的代码进行临时存储时,需要将其写入临时目录/tmp/,在临时存储代码的时候,还需要额外考虑实例复用的情况,所以此时,可以为临时代码提供临时的文件名,例如:
# -*- coding: utf-8 -*-
import randomrandom
Str = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))
path = "/tmp/%s"% randomStr(5)
完整的代码实现为:
# -*- coding: utf-8 -*-
import json
import uuid
import random
import subprocess
# 随机字符串
randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))
# Response
class Response:
def __init__(self, start_response, response, errorCode=None):
self.start = start_response
responseBody = {
'Error': {"Code": errorCode, "Message": response},
} if errorCode else {
'Response': response
}
# 默认增加uuid,便于后期定位
responseBody['ResponseId'] = str(uuid.uuid1())
self.response = json.dumps(responseBody)
def __iter__(self):
status = '200'
response_headers = [('Content-type', 'application/json; charset=UTF-8')]
self.start(status, response_headers)
yield self.response.encode("utf-8")
def WriteCode(code, fileName):
try:
with open(fileName, "w") as f:
f.write(code)
return True
except Exception as e:
print(e)
return False
def RunCode(fileName, input_data=""):
child = subprocess.Popen("python %s" % (fileName),
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
shell=True)
output = child.communicate(input=input_data.encode("utf-8"))
return output[0].decode("utf-8")
def handler(environ, start_response):
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8"))
code = requestBody.get("code", None)
inputData = requestBody.get("input", "")
fileName = "/tmp/" + randomStr(5)
responseData = RunCode(fileName, inputData) if code and WriteCode(code, fileName) else "Error"
return Response(start_response, {"result": responseData})
完成核心的业务逻辑编写之后,我们可以将代码部署到阿里云函数计算中。部署完成之后,我们可以获得到接口的临时测试地址。通过 PostMan 对该接口进行测试,以 Python 语言的输出语句为例:
print('HELLO WORLD')
可以看到,当我们通过 POST 方法,携带代码等作为参数,发起请求后,获得到的响应为:


我们通过响应结果,可以看到,系统是可以正常输出我们的预期结果:“HELLO WORLD” 至此我们完成了标准输出功能的测试,接下来我们对标准错误等功能进行测试,此时我们将刚刚的输出代码进行破坏:
print('HELLO WORLD)
使用同样的方法,再次进行代码执行,可以看到结果:

结果中,我们可以看到 Python 的报错信息,是符合我们的预期的,至此完成了在线编程功能的标准错误功能的测试,接下来,我们进行标准输入功能的测试,由于我们使用的 subprocess.Popen() 方法,是一种阻塞方法,所以此时我们需要将代码和标准输入内容一同放到服务端。测试的代码为:
tempInput = input('please input: ')
print('Output: ', tempInput)
测试的标准输入内容为:“serverless devs”。
当我们使用同样的方法,发起请求之后,我们可以看到:

系统是正常输出预期的结果。至此我们完成了一个非常简单的在线编程服务的接口。该接口目前只是初级版本,仅用于学习使用,其具有极大的优化空间:
- 超时时间的处理
- 代码执行完成,可以进行清理
当然,通过这个接口也可以看到这样一个问题:那就是代码执行过程中是阻塞的,我们没办法进行持续性的输入,也没有办法实时输出,即使需要输入内容也是需要将代码和输入内容一并发送到服务端。这种模式和目前市面上常见的 OJ 模式很类似,但是就单纯的在线编程而言,还需要进一步对项目优化,使其可以通过非阻塞方法,实现代码的执行,并且可以持续性的进行输入操作,持续性的进行内容输出。
更贴近“本地”的代码执行器
我们以一段代码为例:
import time
print("hello world")
time.sleep(10)
tempInput = input("please: ")
print("Input data: ", tempInput)
当我们在本地的执行这段 Python 代码时,整体的用户侧的实际表现是:
- 系统输出 hello world
- 系统等待 10 秒
- 系统提醒我们 please,我们此时可以输入一个字符串
- 系统输出 Input data 以及我们刚刚输入的字符串
但是,这段代码如果应用于传统 OJ 或者刚刚我们所实现的在线编程系统中,表现则大不相同:
- 代码与我们要输入内容一同传给系统
- 系统等待 10 秒
- 输出 hello world、please,以及最后输 Input data 和我们输入的内容
可以看到,OJ 模式上的在线编程功能和本地是有非常大的差距的,至少在体验层面,这个差距是比较大的。为了减少这种体验不统一的问题,我们可以将上上述的架构进一步升级,通过函数的异步触发,以及 Python 语言的 pexpect.spawn() 方法实现一款更贴近本地体验的在线编程功能:

在整个项目中,包括了两个函数,两个存储桶:
- 业务逻辑函数:该函数的主要操作是业务逻辑,包括创建代码执行的任务(通过对象存储触发器进行异步函数执行),以及获取函数输出结果以及对任务函数的标准输入进行相关操作等;
- 执行器函数:该函数的主要作用是执行用户的函数代码,这部分是通过对象存储触发,通过下载代码、执行代码、获取输入、输出结果等;代码获取从代码存储桶,输出结果和获取输入从业务存储桶;
- 代码存储桶:该存储桶的作用是存储代码,当用户发起运行代码的请求, 业务逻辑函数收到用户代码后,会将代码存储到该存储桶,再由该存储桶处罚异步任务;
- 业务存储桶:该存储桶的作用是中间量的输出,主要包括输出内容的缓存、输入内容的缓存;该部分数据可以通过对象存储的本身特性进行生命周期的制定;
为了让代码在线执行起来,更加贴近本地体验,该方案的代码分为两个函数,分别进行业务逻辑处理和在线编程核心功能。
其中业务逻辑处理函数,主要是:
- 获取用户的代码信息,生成代码执行 ID,并将代码存到对象存储,异步触发在线编程函数的执行,返回生成代码执行 ID;
- 获取用户的输入信息和代码执行 ID,并将内容存储到对应的对象存储中;
- 获取代码的输出结果,根据用户指定的代码执行 ID,将执行结果从对象存储中读取出来,并返回给用户;
整体的业务逻辑为:

实现的代码为:
# -*- coding: utf-8 -*-
import os
import oss2
import json
import uuid
import random
# 基本配置信息
AccessKey = {
"id": os.environ.get('AccessKeyId'),
"secret": os.environ.get('AccessKeySecret')
}
OSSCodeConf = {
'endPoint': os.environ.get('OSSConfEndPoint'),
'bucketName': os.environ.get('OSSConfBucketCodeName'),
'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))
}
OSSTargetConf = {
'endPoint': os.environ.get('OSSConfEndPoint'),
'bucketName': os.environ.get('OSSConfBucketTargetName'),
'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))
}
# 获取获取/上传文件到OSS的临时地址
auth = oss2.Auth(AccessKey['id'], AccessKey['secret'])
codeBucket = oss2.Bucket(auth, OSSCodeConf['endPoint'], OSSCodeConf['bucketName'])
targetBucket = oss2.Bucket(auth, OSSTargetConf['endPoint'], OSSTargetConf['bucketName'])
# 随机字符串
randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))
# Response
class Response:
def __init__(self, start_response, response, errorCode=None):
self.start = start_response
responseBody = {
'Error': {"Code": errorCode, "Message": response},
} if errorCode else {
'Response': response
}
# 默认增加uuid,便于后期定位
responseBody['ResponseId'] = str(uuid.uuid1())
self.response = json.dumps(responseBody)
def __iter__(self):
status = '200'
response_headers = [('Content-type', 'application/json; charset=UTF-8')]
self.start(status, response_headers)
yield self.response.encode("utf-8")
def handler(environ, start_response):
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8"))
reqType = requestBody.get("type", None)
if reqType == "run":
# 运行代码
code = requestBody.get("code", None)
runId = randomStr(10)
codeBucket.put_object(runId, code.encode("utf-8"))
responseData = runId
elif reqType == "input":
# 输入内容
inputData = requestBody.get("input", None)
runId = requestBody.get("id", None)
targetBucket.put_object(runId + "-input", inputData.encode("utf-8"))
responseData = 'ok'
elif reqType == "output":
# 获取结果
runId = requestBody.get("id", None)
targetBucket.get_object_to_file(runId + "-output", '/tmp/' + runId)
with open('/tmp/' + runId) as f:
responseData = f.read()
else:
responseData = "Error"
return Response(start_response, {"result": responseData})
执行器函数,主要是通过代码存储桶触发,从而进行代码执行的模块,这一部分主要包括:
- 从存储桶获取代码,并通过 pexpect.spawn() 进行代码执行;
- 通过 pexpect.spawn().read_nonblocking() 非阻塞的获取间断性的执行结果,并写入到对象存储;
- 通过 pexpect.spawn().sendline() 进行内容输入;
整体流程为:

代码实现为:
# -*- coding: utf-8 -*-
import os
import re
import oss2
import json
import time
import pexpect
# 基本配置信息
AccessKey = {
"id": os.environ.get('AccessKeyId'),
"secret": os.environ.get('AccessKeySecret')
}
OSSCodeConf = {
'endPoint': os.environ.get('OSSConfEndPoint'),
'bucketName': os.environ.get('OSSConfBucketCodeName'),
'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))
}
OSSTargetConf = {
'endPoint': os.environ.get('OSSConfEndPoint'),
'bucketName': os.environ.get('OSSConfBucketTargetName'),
'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))
}
# 获取获取/上传文件到OSS的临时地址
auth = oss2.Auth(AccessKey['id'], AccessKey['secret'])
codeBucket = oss2.Bucket(auth, OSSCodeConf['endPoint'], OSSCodeConf['bucketName'])
targetBucket = oss2.Bucket(auth, OSSTargetConf['endPoint'], OSSTargetConf['bucketName'])
def handler(event, context):
event = json.loads(event.decode("utf-8"))
for eveEvent in event["events"]:
# 获取object
code = eveEvent["oss"]["object"]["key"]
localFileName = "/tmp/" + event["events"][0]["oss"]["object"]["eTag"]
# 下载代码
codeBucket.get_object_to_file(code, localFileName)
# 执行代码
foo = pexpect.spawn('python %s' % localFileName)
outputData = ""
startTime = time.time()
# timeout可以通过文件名来进行识别
try:
timeout = int(re.findall("timeout(.*?)s", code)[0])
except:
timeout = 60
while (time.time() - startTime) / 1000 <= timeout:
try:
tempOutput = foo.read_nonblocking(size=999999, timeout=0.01)
tempOutput = tempOutput.decode("utf-8", "ignore")
if len(str(tempOutput)) > 0:
outputData = outputData + tempOutput
# 输出数据存入oss
targetBucket.put_object(code + "-output", outputData.encode("utf-8"))
except Exception as e:
print("Error: ", e)
# 有输入请求被阻塞
if str(e) == "Timeout exceeded.":
try:
# 从oss读取数据
targetBucket.get_object_to_file(code + "-input", localFileName + "-input")
targetBucket.delete_object(code + "-input")
with open(localFileName + "-input") as f:
inputData = f.read()
if inputData:
foo.sendline(inputData)
except:
pass
# 程序执行完成输出
elif "End Of File (EOF)" in str(e):
targetBucket.put_object(code + "-output", outputData.encode("utf-8"))
return True
# 程序抛出异常
else:
outputData = outputData + "\n\nException: %s" % str(e)
targetBucket.put_object(code + "-output", outputData.encode("utf-8"))
return False
当我们完成核心的业务逻辑编写之后,我们可以将项目部署到线上。
项目部署完成之后,和上文的测试方法一样,在这里也通过 PostMan 对接口进行测试。此时,我们需要设定一个覆盖能较全的测试代码,包括输出打印、输入、一些 sleep() 等方法:

当我们通过 PostMan 发起请求执行这段代码之后,我们可以看到系统为我们返回了预期的代码执行 ID:

我们可以看到系统会返回给我们一个代码执行 ID,该执行 ID 将会作为我们整个请求任务的 ID,此时,我们可以通过获取输出结果的接口,来获取结果:

由于代码中有:
time.sleep(10)
所以,迅速获得结果的时候是看不到后半部分的输出结果,我们可以设置一个轮训任务,不断通过该 ID 对接口进行刷新:

可以看到,10 秒钟后,代码执行到了输入部分:
tempInput = input('please: ')
此时,我们再通过输入接口,进行输入操作:

完成之后,我们可以看到输入成功(result: ok)的结果,此时我们继续刷新之前获取结果部分的请求:

可以看到,我们已经获得到了所有结果的输出。
相对于上文的在线编程功能,这种“更贴近本地的代码执行器“变得复杂了很多,但是在实际使用的过程中,却可以更好的模拟出本地执行代码时的一些现象,例如代码的休眠、阻塞、内容的输出等。
总结
无论是简单的在线代码执行器部分,还是更贴近“本地”的代码执行器部分,这篇文章在所应用的内容是相对广泛的。通过这篇文章你可以看到:
- HTTP 触发器的基本使用方法;对象存储触发器的基本使用方;
- 函数计算组件、对象存储组件的基本使用方法,组件间依赖的实现方法;
同时,通过这篇文章,也可以从一个侧面看到这样一个常见问题的简单解答:我有一个项目,我是每个接口一个函数,还是多个接口复用一个函数?
针对这个问题,其实最主要的是看业务本身的诉求,如果多个接口表达的含义是一致的,或者是同类的,类似的,并且多个接口的资源消耗是类似的,那么放在一个函数中来通过不同的路径进行区分是完全可以的;如果出现资源消耗差距较大,或者函数类型、规模、类别区别过大的时候,将多个接口放在多个函数下也是没有问题的。
本文实际上是抛砖引玉,无论是 OJ 系统的“判题机”部分,还是在线编程工具的“执行器部分”,都可以很好的和 Serverless 架构有着比较有趣的结合点。这种结合点不仅仅可以解决传统在线编程所头疼的事情(安全问题,资源消耗问题,并发问题,流量不稳定问题),更可以将 Serverless 的价值在一个新的领域发挥出来。
原文链接
本文为阿里云原创内容,未经允许不得转载。
用手机写代码:基于 Serverless 的在线编程能力探索的更多相关文章
- 20个最强的基于浏览器的在线代码编辑器 - OPEN资讯
20个最强的基于浏览器的在线代码编辑器 - OPEN资讯 20个最强的基于浏览器的在线代码编辑器
- Appium初始化设置:手写代码连接手机、appium-desktop连接手机
一.包名获取的三种方式 1)找开发要2)mac使用命令:adb logcat | grep START win使用命令:adb logcat | findstr START 或者可以尝试使用第3条命令 ...
- 文档驱动 —— 表单组件(五):基于Ant Design Vue 的表单控件的demo,再也不需要写代码了。
源码 https://github.com/naturefwvue/nf-vue3-ant 特点 只需要更改meta,既可以切换表单 可以统一修改样式,统一升级,以最小的代价,应对UI的升级.切换,应 ...
- 文档驱动 —— 表单组件(六):基于AntDV的Form表单的封装,目标还是不写代码
开源代码 https://github.com/naturefwvue/nf-vue3-ant 也不知道大家是怎么写代码的,这里全当抛砖引玉 为何封装? AntDV非常强大,效果也非常漂亮,功能强大, ...
- 【玩转 WordPress】基于 Serverless 搭建个人博客图文教程,学生党首选!
以下内容来自「玩转腾讯云」用户原创文章,已获得授权. 01. 什么是 Serverless? 1. Serverless 官方定义 Serverless 中的 Server是服务器的意思,less 是 ...
- 云开发中的战斗机 Laf,让你像写博客一样写代码
各位云原生搬砖师 and PPT 架构师,你们有没有想过像写文章一样方便地写代码呢? 怎样才能像写文章一样写代码? 理想的需求应该是可以在线编写.调试函数,不用重启服务,随时随地在 Web 上查看函数 ...
- 用css以写代码形式画一个皮卡丘
我的个人网站是通过写代码的形式来形成一个网站的,前一阵子在某个大神的github上看到他用写代码的形式来完成一个皮卡丘,于是心血来潮花了半个小时,也完成了一个作品. 这其中涉及到的知识点也不是很复杂, ...
- UI到底应该用xib/storyboard完成,还是用手写代码来完成?
UI到底应该用xib/storyboard完成,还是用手写代码来完成? 文章来源:http://blog.csdn.net/libaineu2004/article/details/45488665 ...
- EEPlat的基于浏览器的在线开发技术
EEPlat的开发内容主要包含配置开发和基于API的扩展开发两块内容. EEPlat的配置开发基于后台的配置环境.直接通过界面操作配置就可以. EEPlat的配置平台是用EEPlat自解释构建的.本身 ...
- Java 10的10个新特性,将彻底改变你写代码的方式!
Java 9才发布几个月,很多玩意都没整明白,现在Java 10又快要来了.. 这时候我真尼玛想说:线上用的JDK 7 甚至JDK 6,JDK 8 还没用熟,JDK 9 才发布不久不知道啥玩意,JDK ...
随机推荐
- CSS(相对定位relative、绝对定位absolute、固定定位fixed、定位应用、元素的显示和隐藏)
一. 定位(position) 介绍 1.1 为什么使用定位 我们先来看一个效果,同时思考一下用标准流或浮动能否实现类似的效果? 场景1: 某个元素可以自由的在一个盒子内移动位置,并且压住其他盒子. ...
- apache添加php模块
实验介绍: apache本身只能发布静态网站,而添加了php模块就可以发布动态网站 一:下载php 进入php官方网址https://www.php.net/ 点击进入windows版本 下载thre ...
- RageFrame学习笔记:环境配置+项目拉取并实例化到本地
最近在研究一个基于YII2的框架,原本我以为很简单,但没想到在第一步环境配置和实例化上就卡了我4个小时,这里分享出我走过的弯路和解决问题的整个流程. 关注我文章的朋友应该了解过,我之前学习easyad ...
- C# OpenCvSharp+ 微信二维码引擎实现二维码识别
微信开源了其二维码的解码功能,并贡献给 OpenCV 社区.其开源的 wechat_qrcode 项目被收录到 OpenCV contrib 项目中.从 OpenCV 4.5.2 版本开始,就可以直接 ...
- modelsim的工程文件结构
modelsim的工程文件结构 1.工程结构 modelsim中的工程包括一个库(这个库可以是空的,也可以包含器件延时信息的真实库),一个工程(以mpf为后缀的文件是工程的快捷打开方式)和若干源文件. ...
- KingbaseES 对象重命名需要注意的事项
前言: Oracle 对视图或同义词依赖的底层对象表,如果被重命名,则视图或同义词失效.Oracle DBA 经常利用这个特点,对表进行重建,在重建过程中,无法通过视图或同义词访问,这就保证了数据的安 ...
- KingbaseES V8R6运维案例之---普通表toast表故障修复
案例说明: 数据库在日常的维护过程中,在执行表查询(select),如下图所示,出现"could not read block 0 in file "base/16385/1640 ...
- https安全性 带给im 消息加密的启发
大家好,我是蓝胖子,在之前# MYSQL 是如何保证binlog 和redo log同时提交的?这篇文章里,我们可以从mysql的设计中学会如何让两个服务的调用逻辑达到最终一致性,这也是分布式事务实现 ...
- 1 CSS的引入方式
1 CSS的引入方式 CSS样式有三种不同的使用方式,分别是行内样式,嵌入样式以及链接式.我们需要根据不同的场合不同的需求来使用不同的样式. 行内样式 行内样式,就是写在元素的style属性中的样式, ...
- 使用Python的turtle模块绘制美丽的樱花树
引言 Python的turtle模块是一个直观的图形化编程工具,让用户通过控制海龟在屏幕上的移动来绘制各种形状和图案.turtle模块的独特之处在于其简洁易懂的操作方式以及与用户的互动性.用户可以轻松 ...