掌握pandas cut函数,一键实现数据分类
pandas中的cut函数可将一维数据按照给定的区间进行分组,并为每个值分配对应的标签。
其主要功能是将连续的数值数据转化为离散的分组数据,方便进行分析和统计。
1. 数据准备
下面的示例中使用的数据采集自王者荣耀比赛的统计数据。
数据下载地址:https://databook.top/。
导入数据:
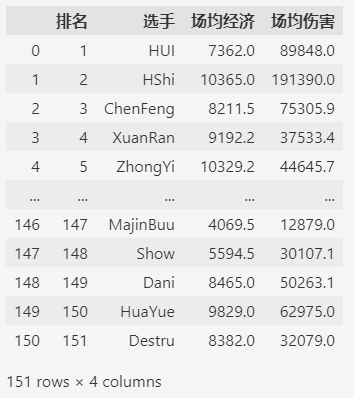
# 2023年世冠比赛选手的数据
fp = r"D:\data\player-2023世冠.csv"
df = pd.read_csv(fp)
# 这里只保留了下面示例中需要的列
df = df.loc[:, ["排名", "选手", "场均经济", "场均伤害"]]
df
2. 使用示例
每个选手的“场均经济”和“场均伤害”是连续分布的数据,为了整体了解所有选手的情况,
可以使用下面的方法将“场均经济”和“场均伤害”分类。
2.1. 查看数据分布
首先,可以使用直方图的方式看看数据连续分布的情况:
import matplotlib.pyplot as plt
df.loc[:, ["场均经济", "场均伤害"]].hist()
plt.show()
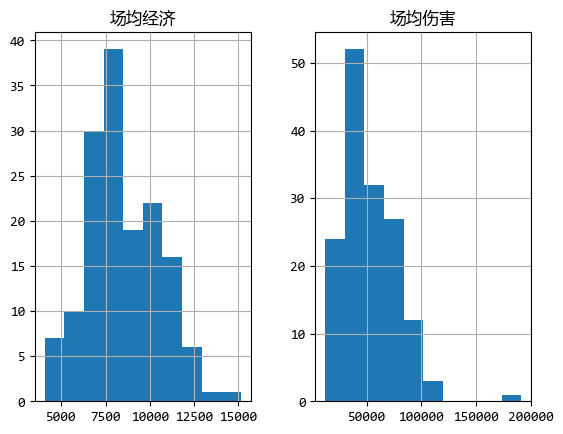
图中的横轴是“经济”和“伤害”的数值,纵轴是选手的数量。
2.2. 定制分布参数
从默认的直方图中可以看出大部分选手的“场均经济”和“场均伤害”大致在什么范围,
不过,为了更精细的分析,我们可以进一步定义自己的分类范围,看看各个分类范围内的选手数量情况。
比如,我们将“场均经济”分为3块,分别为低(0~5000),中(5000~10000),高(10000~20000)。
同样,对于“场均伤害”,也分为3块,分别为低(0~50000),中(50000~100000),高(100000~200000)。
bins1 = [0, 5000, 10000, 20000]
bins2 = [0, 50000, 100000, 200000]
labels = ["低", "中", "高"]
s1 = "场均经济"
s2 = "场均伤害"
df[f"{s1}-分类"] = pd.cut(df[s1], bins=bins1, labels=labels)
df[f"{s2}-分类"] = pd.cut(df[s2], bins=bins2, labels=labels)
df
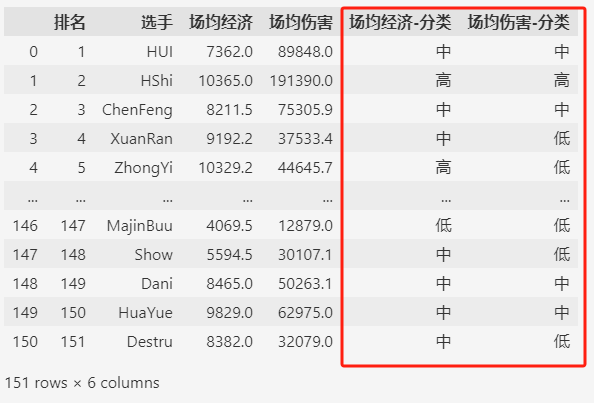
分类之后,选手被分到3个类别之中,然后再绘制直方图。
df.loc[:, f"{s1}-分类"].hist()
plt.title(f"{s1}-分类")
plt.show()
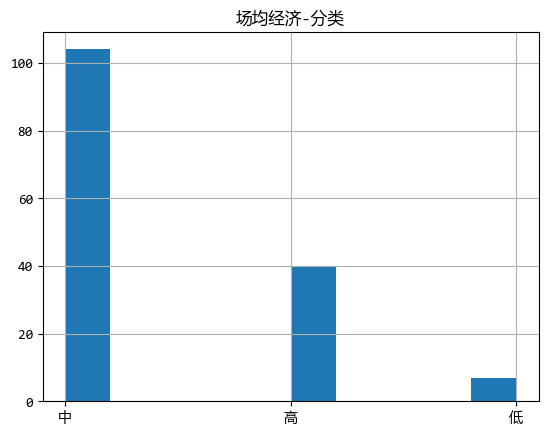
从这个图看出,大部分选手都是“中”,“高”的经济,说明职业选手很重视英雄发育。
df.loc[:, f"{s2}-分类"].hist()
plt.title(f"{s2}-分类")
plt.show()
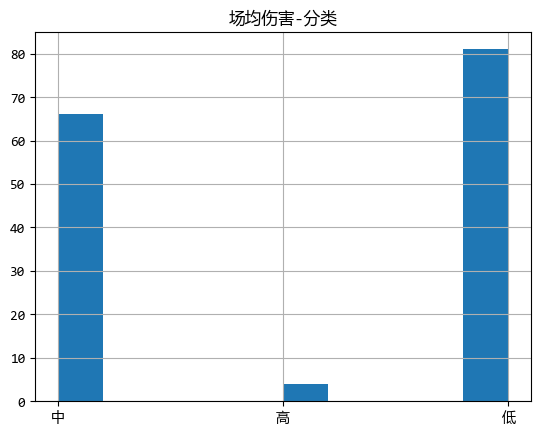
从图中可以看出,打出高伤害的选手比例并不高,可能职业比赛中,更多的是团队作战。
3. 总结
总的来说,cut函数的主要作用是将输入的数值数据(可以是一维数组、Series或DataFrame的列)按照指定的间隔或自定义的区间边界进行划分,并为每个划分后的区间分配一个标签。
这样,原始的连续数据就被转化为了离散的分组数据,每个数据点都被分配到了一个特定的组中,从而方便后续进行分析和统计。
掌握pandas cut函数,一键实现数据分类的更多相关文章
- pandas 常用函数整理
pandas常用函数整理,作为个人笔记. 仅标记函数大概用途做索引用,具体使用方式请参照pandas官方技术文档. 约定 from pandas import Series, DataFrame im ...
- 【转载】pandas常用函数
原文链接:https://www.cnblogs.com/rexyan/p/7975707.html 一.import语句 import pandas as pd import numpy as np ...
- Pandas的函数应用、层级索引、统计计算
1.Pandas的函数应用 1.apply 和 applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random ...
- pandas常用函数之shift
shift函数是对数据进行移动的操作,假如现在有一个DataFrame数据df,如下所示: index value1 A 0 B 1 C 2 D 3 那么如果执行以下代码: df.shift() 就会 ...
- pandas常用函数之diff
diff函数是用来将数据进行某种移动之后与原数据进行比较得出的差异数据,举个例子,现在有一个DataFrame类型的数据df,如下: index value1 A 0 B 1 C 2 D 3 如果执行 ...
- pandas.cut使用总结
用途 pandas.cut用来把一组数据分割成离散的区间.比如有一组年龄数据,可以使用pandas.cut将年龄数据分割成不同的年龄段并打上标签. 原型 pandas.cut(x, bins, rig ...
- R quantile函数 | cut函数 | sample函数 | all函数 | scale函数 | do.call函数
取出一个数字序列中的百分位数 1. 求某一个百分比 x<-rnorm(200) quantile(x,0.9) 2. 求一系列的百分比 quantile(x,c(0.1,0.9)) quanti ...
- python pandas字符串函数详解(转)
pandas字符串函数详解(转)——原文连接见文章末尾 在使用pandas框架的DataFrame的过程中,如果需要处理一些字符串的特性,例如判断某列是否包含一些关键字,某列的字符长度是否小于3等等 ...
- Pandas常用函数入门
一.Pandas Python Data Analysis Library或Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的.Pandas纳入了大量库和一些标准的数据模型, ...
- pandas常用函数
1. df.head(n): 显示数据前n行,不指定n,df.head则会显示所有的行 2. df.columns.values获取所有列索引的名称 3. df.column_name: 直接获取列c ...
随机推荐
- [西湖论剑 2022]web部分题解(更新中ing
[西湖论剑 2022]Node Magical Login 环境!启动!(ノへ ̄.) 这么一看好像弱口令啊,(不过西湖论剑题目怎么会这么简单,当时真的傻),那就bp抓包试一下(这里就不展示了,因为是展 ...
- Vue基础系列文章05----babel安装与使用
1.安装babel-node包,运行: 1) npm install --save-dev @babel/core @babel/cli @babel/preset-env @babel/node 2 ...
- javaScript随机图片
<script type="text/javascript"> //<!CDATA[ var pic = []; pic[0] = "链接"; ...
- MySQL【二】---数据库查询详细教程{查询、排序、聚合函数、分组}
1.数据准备.基本的查询(回顾一下) 创建数据库 create database python_test charset=utf8; 查看数据库: show databases; 使用数据库: use ...
- 7.4 C/C++ 实现链表栈
相对于顺序栈,链表栈的内存使用更加灵活,因为链表栈的内存空间是通过动态分配获得的,它不需要在创建时确定其大小,而是根据需要逐个分配节点.当需要压入一个新的元素时,只需要分配一个新的节点,并将其插入到链 ...
- 分布式压测之locust和Jmeter的使用
受限于单台机器的配置问题,我们在单台机器上达不到一个很高的压测并发数,那这个时候就需要引入分布式压测 分布式压测原理: 一般通过局域网把不同测试计算机链接到一起,达到测试共享.分散操作.集中管理的目的 ...
- 论文精读:用于少样本图像识别的语义提示(Semantic Prompt for Few-Shot Image Recognition)
原论文于2023.11.6撤稿,原因:缺乏合法的授权,详见此处 Abstract 在小样本学习中(Few-shot Learning, FSL)中,有通过利用额外的语义信息,如类名的文本Embeddi ...
- C++中,new与malloc的区别何在?(代码实验向)
在C++中,new与malloc()都可用于在堆中分配一块内存.其中,new是C++的语法,而malloc则来自古老的C语言,二者在使用时有何区别? new会调用构造函数,而malloc()不会 假设 ...
- Java并发(七)----线程sleep、yield、线程优先级
1.sleep 与 yield sleep 调用 sleep 会让当前线程从 Running 进入 Timed Waiting 状态(阻塞) 其它线程可以使用 interrupt 方法打断正在睡眠的线 ...
- Java集合框架学习(九) TreeMap详解
TreeMap介绍 TreeMap 类实现了Map接口,和HashMap类类似. TreeMap是一个基于Red-Black tree的可导航map的实现. 它基于key的自然顺序排序. TreeMa ...