构建健康游戏环境:DFA算法在敏感词过滤的应用
现在的游戏有敏感词检测这一点,相信大家也不陌生了,不管是聊天,起名,签名还是简介,只要是能让玩家手动输入的地方,一定少不了敏感词识别,至于识别之后是拒绝修改还是星号替换,这个就各有各的做法了,但是绕不开的一定是需要高效的敏感词检测机制。

相信大家对于游戏里聊天框的以下内容已经不陌生了
- "我***"
- “你真牛*”
- “你是不是傻*”
一个垃圾的游戏环境是非常影响玩游戏的心情的,看到这些,就知道游戏已经帮我们屏蔽掉了那些屏蔽字了,对于玩游戏而言,心里会好受很多。敏感词识别对于游戏的重要性不言而喻。当然,除了游戏,也有很多业务场景可能需要敏感词检测,如果你接到这样一个需求的时候,你会怎么做?*
一、原生API
作为Java程序员,我的第一反应,一定是使用jdk原生的String类提供的contain或replace方法来进行包含判断或字符替换,这是最简单直接的方式。那我们就来看看String的实现方式:
contains
String在java中以char数组形式存储,而String.contains的实现,实际上是对数组的遍历查找匹配
// 最终调用方法
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
// ...
}
replace
String.replace有4个接口,实现为正则匹配替换或直接遍历替换
public String replace(char oldChar, char newChar) {
// 直接进行字符串遍历,替换第一个匹配的字符串
}
public String replace(CharSequence target, CharSequence replacement) {
// 创建Pattern,使用LITERAL模式进行正则匹配替换replaceAll
// 当设置LITERAL标志时,输入字符串中的所有字符都被视为普通字符。
// 这意味着正则表达式的特殊字符,如点号(.)、星号(*)、加号(+)等,都将失去它们在正则表达式中的特殊意义,被直接视为普通字符。
}
public String replaceAll(String regex, String replacement) {
// 创建Pattern,使用正则表达式模式匹配替换replaceAll
}
public String replaceFirst(String regex, String replacement) {
// 创建Pattern,使用正则表达式模式匹配替换replaceFirst,仅替换第一个匹配的字符串
}
通过jdk提供的String源码我们可以得到以下结果:
- 使用contains方法进行包含判断,它的底层实现原理其实就是通过遍历目标字符串的字符数组进行挨个匹配;少量敏感词检测的时候是可行的,但如果目标字符串很大,并且要匹配的敏感词足够多的时候,它的遍历匹配效率是很低的。
- replace则分两种实现,其中一种是类似contains方法,也是进行对目标字符串进行字符数组的遍历替换。
- replace的另一种实现,是通过java的正则表达式去做匹配,正则匹配相比于遍历匹配,效率上不会有明显提升,但对于复杂模式的解析匹配会有比较明显的优势
其他语言的字符串操作API大同小异,具体看源码的实现方式

二、正则表达式
另外一种我们能想到的方式就是进行正则表达式的匹配了。前面提到,在java中如果使用String的api,它有部分接口就是使用正则表达式来实现的。
使用正则表达式有一定优势,也有一定缺陷。这就不得不提正则表达式的实现原理:FA(Finite Automaton:有限自动机)
DFA与NFA
FA又分为DFA和NFA,我们以正则ab|ac举例
NFA(Nondeterministic finite automaton:非确定性有限状态自动机)
在NFA中表达式会构建为以下结构
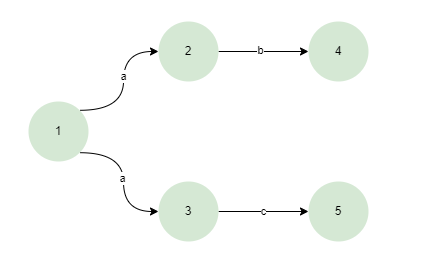
- 非确定性:对于给定的输入符号,NFA可以从一个状态转移到多个状态。这意味着存在多种可能的状态转换路径,NFA在任何时间点都可以处于多个状态。
- 回溯:由于NFA在处理输入时可以选择多条路径,因此可能需要回溯。当某条路径未能达到接受状态时,NFA会返回并尝试其他可能的路径。
- 构造:NFA相对容易构造,特别是对于复杂的或包含多种可能的语言(例如正则表达式)。
- 运行效率:由于其非确定性特性,NFA在运行时可能需要更多的计算资源,特别是在处理长输入字符串时。
DFA(Deterministic finite automaton:确定性有限自动机)
在DFA中表达式会构建为以下结构
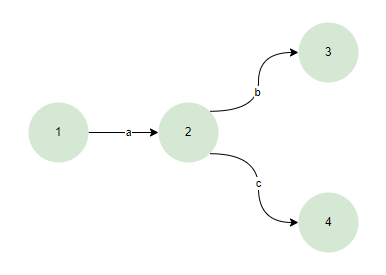
- 确定性:对于给定的输入符号,DFA从一个状态转移到另一个唯一确定的状态。这意味着DFA在任何时间点只能处于一个状态。
- 无回溯:由于每个输入符号只对应一个状态转换,DFA在处理输入时不需要回溯。
- 构造:相对于NFA,DFA可能更难直接构造,特别是对于复杂的语言,但它可以通过从NFA转换得到。
- 运行效率:DFA在运行时通常更高效,因为它在处理输入时不需要考虑多种可能的状态路径。
理论上,NFA和DFA等效,它们都可以识别相同的语言类型。但在实际应用中,它们各有优势:NFA更适合于表示和构造复杂模式,而DFA在执行时更高效。
如果以上描述不能理解,这里其实可以做个不是特别恰当的比喻:广度优先搜索BFS和深度优先搜索DFS。
- NFA可以转移到多个不同的状态。这就像是在图中有多条边从一个节点出发一样。如果将NFA的操作类比为一种搜索算法,它更接近于广度优先搜索(BFS)。在匹配过程中,NFA可以同时探索多条路径(或状态转换),就像BFS在搜索时会先访问所有邻接节点。然而,NFA通常不会存储所有可能的状态转换路径,而是在运行时动态生成它们。
- DFA只能转移到一个唯一确定的状态。这就像是图中的每个节点仅有一条出边一样。尽管DFA在每一步只选择一条路径,但将其类比为深度优先搜索(DFS)并不准确。DFS是一种搜索算法,用于探索所有可能的路径直到它达到目标或结束条件。DFA则是一种确定性的状态机,它不需要“搜索”;它只是在状态之间单一确定地转换。
在正则表达式的实现中,有的基于DFA,有的基于NFA;尽管DFA的搜索路径比NFA短,但实际场景中,NFA更适合复杂模式的正则搜索。因此大多数正则实现还是基于NFA。
java中的正则表达式是基于NFA的实现
使用局限
当然了,正则表达式的实现到底是NFA还是DFA,并不是今天讨论的重点。
资源消耗
无论是NFA还是DFA,它们在匹配之前,都会先构造基于图的数据结构,因此,使用正则表达式进行敏感词匹配,一定逃不开构建这个数据结构的性能消耗和内存占用。回溯陷阱
在使用正则表达式进行敏感词匹配时,如果是基于NFA实现的正则算法,则很有可能出现回溯陷阱。上面提到NFA在匹配时是会进行回溯的,因为它不知道后面有没有可能还会匹配成功,但是DFA从一开始就是确定的有限自动机,DFA是知道所有的匹配成功的情况,所以在使用NFA时,如果表达式写的不注意,很可能出现大量回溯。这样大量的回溯很可能造成在进行正则表达式的匹配时,CPU会飚高的情况。
解决方案
- 资源消耗很好解决:对于服务器来说,只需要在启动服务器之前,对配置好的敏感词做好正则表达式的初始化即可,即便是需要灵活配置,也可以通过动态加载再进行内存替换来解决。
- 要解决NFA回溯问题,也有很多方式:比如表达式中尽可能提取公共部分、适当拆分、不要量词嵌套、使用非贪婪模式等多种优化手段。这些优化手段都是从表达式本身入手,这意味着所有人在编写敏感词匹配的正则表达式时,都需要时刻注意回溯陷阱,并且对每一个表达式都要做好性能测试。
如果注意好以上点,使用正则表达式进行敏感词匹配在业务场景中也是可行的。甚至于对于复杂语义的敏感词配置来说,只有正则表达式能实现需求

三、DFA
上文中其实已经提到,相比于NFA的不确定性,DFA是具有确定性的有限自动机。它之所以具有确定性,从结构上来说,它的每一个状态都只对应一个状态转换,因此它也无需进行回溯,因此它的匹配性能也比NFA要高。
当然了DFA的缺点就是它很难处理复杂的语义。但是对于敏感词来说,为了效率,我们其实可以把那些复杂的语义简单化;另外一个和正则匹配一样的点,就是构建DFA有向图所带来的开销和内存占用,这一点也能通过服务器启动加载和动态内存替换解决。
所以其实一旦我们解决掉DFA的痛点,便能扬长避短,既享受DFA高效率,又使其能胜任业务场景。
不过需要注意的是,这里我们就不再使用正则表达式进行敏感词匹配了,而是直接实现一套基于DFA的敏感词匹配算法。你可能会有疑问,既然正则表达式也可以使用DFA,那我们为什么不使用基于DFA的正则表达式呢?
这也很好理解,使用正则表达式,我们只能把每一条表达式单独构建成一个个图的数据结构,它的粒度只能到每一条表达式。而我们自己实现DFA,则可以把所有的敏感词全部构建成同一个大的DFA图,它维度则是全服所有敏感词。这样既可以省去一定的内存空间,也可以减少匹配次数。
使用原理
使用DFA来实现敏感词匹配的原理,其实是在初始化时,把所有的敏感词拆成一个个的字,然后组织成一个很大的有向图的结构。其实也是用到编程思想中的空间换时间思想。比如有以下敏感词:
- 打死你
- 打死他
- 打他
- 揍他
经过DFA的树组织,最终会得到以下结构:
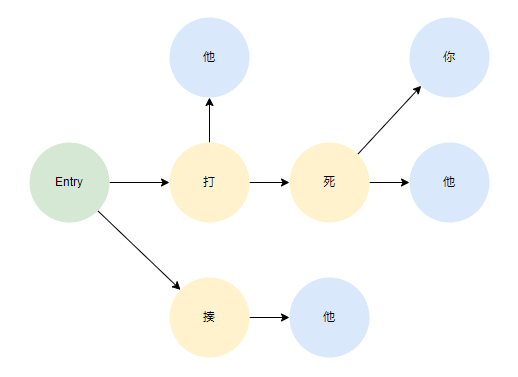
其中,绿色的Entry代表入口节点,而蓝色的代表中止节点,当玩家输入一句话时,会通过遍历玩家发的每一个字,再去这个DFA有向图中去匹配
如果玩家发送“我要揍他”,那么“揍他”两个字就能通过“Entry->揍->他”这样的路径匹配上
如果玩家发送“我要揍你”,那么“揍”字能通过“Entry->揍”这样的路径匹配上,但因为“揍”不是中止节点,所以这句话不能算敏感词
逻辑实现
1. DFA初始化
这一步作用是构建DFA图
public boolean initialize(String[] keyWords) {
clear();
// 构造DFA
for (int s = 0; s < keyWords.length; s++) {
String _keyword = keyWords[s];
if (_keyword == null || (_keyword = _keyword.trim()).length() == 0) {
continue;
}
char[] patternTextArray = _keyword.toCharArray();
DFANode currentDFANode = dfaEntrance;
for (int i = 0; i < patternTextArray.length; i++) {
final char _c = patternTextArray[i];
// 逐点加入DFA
final Character _lc = toLowerCaseWithoutConfict(_c);
DFANode _next = currentDFANode.dfaTransition.get(_lc);
if (_next == null) {
_next = new DFANode();
currentDFANode.dfaTransition.put(_lc, _next);
}
currentDFANode = _next;
}
if (currentDFANode != dfaEntrance) {
currentDFANode.isTerminal = true;
}
}
buildFailNode();
return true;
}
2. DFA匹配检测
匹配字检测,一旦检测到中止节点,则返回true
public boolean contain(final String inputMsg) {
char[] input = inputMsg.toCharArray();
DFANode currentDFANode = dfaEntrance;
DFANode _next = null;
for (int i = 0; i < input.length; i++) {
final Character _lc = this.toLowerCaseWithoutConfict(input[i]);
if (!isIgnore(_lc)) {
_next = currentDFANode.dfaTransition.get(_lc);
while (_next == null && currentDFANode != dfaEntrance) {
currentDFANode = currentDFANode.failNode;
_next = currentDFANode.dfaTransition.get(_lc);
}
}
if (_next != null) {
// 找到状态转移,可继续
currentDFANode = _next;
}
// 看看当前状态可退出否
if (currentDFANode.isTerminal) {
// 可退出,记录,可以替换到这里
return true;
}
}
return false;
}
3. DFA字符替换
根据节点搜索匹配,走到中止节点则回溯依次替换
public String filt(String s) {
char[] input = s.toCharArray();
char[] result = s.toCharArray();
boolean _filted = false;
DFANode currentDFANode = dfaEntrance;
DFANode _next = null;
int replaceFrom = 0;
int ignoreLength = 0;
boolean endIgnore = false;
for (int i = 0; i < input.length; i++) {
final Character _lc = this.toLowerCaseWithoutConfict(input[i]);
_next = currentDFANode.dfaTransition.get(_lc);
while (_next == null && !isIgnore(_lc) && currentDFANode != dfaEntrance) {
currentDFANode = currentDFANode.failNode;
_next = currentDFANode.dfaTransition.get(_lc);
}
if (_next != null) {
// 找到状态转移,可继续
currentDFANode = _next;
if(currentDFANode.level == 1) {
ignoreLength = 0;
}
}
if (!endIgnore && currentDFANode != dfaEntrance && isIgnore(_lc)) {
ignoreLength++;
}
// 看看当前状态可退出否
if (currentDFANode.isTerminal) {
endIgnore = true;
// 可退出,记录,可以替换到这里
int j = i - (currentDFANode.level - 1) - ignoreLength;
if (j < replaceFrom) {
j = replaceFrom;
}
replaceFrom = i + 1;
for (; j <= i; j++) {
result[j] = this.subChar;
_filted = true;
}
currentDFANode = dfaEntrance;
ignoreLength = 0;
endIgnore = false;
}
}
if (_filted) {
return String.valueOf(result);
} else {
return s;
}
}

怎么选择
- 使用原生api进行遍历匹配在数据达到一定量级时一定会有性能问题的,一般不采用这种方式。
- 使用正则表达式优势在于灵活配置,但需注意回溯陷阱问题;正则表达式预编译会占用一定内存空间。
- 使用DFA在简单确定的语义中优势明显,但难以处理复杂语义;DFA初始化构建有向图会占用内存空间,一般敏感词数量是会达到二三十万的量级的,有向图大小会达到M级别,好在现在内存并不值钱,空间换时间是一个可取的办法。
DFA应用场景
- 编译器设计:DFA常用于词法分析器,用于识别关键字、运算符、标识符等
- 字符串搜索和匹配:常用于字符串匹配算法,比如文本编辑器,敏感词等
- 网络安全检测:DFA用快速识别恶意流量模式
- 自然语言(NPL)处理:用于文本分析和处理任务
- 正则表达式引擎:虽然很多正则表达式引擎基于非确定性有限自动机(NFA),但也有一些引擎或工具使用DFA来提高匹配效率,特别是在匹配简单模式时
- 更多...

更多技术干货,欢迎关注我!

构建健康游戏环境:DFA算法在敏感词过滤的应用的更多相关文章
- DFA算法实现敏感词过滤
DFA算法:即确定有穷自动机,简单点说就是,它是是通过event和当前的state得到下一个state,即event+state=nextstate.理解为系统中有多个节点,通过传递进入的event, ...
- Java 利用DFA算法 屏蔽敏感词
原文:http://www.open-open.com/code/view/1435214601278 import java.io.BufferedReader; import java.io.Fi ...
- 使用DFA算法对敏感词进行过滤
项目目录结构如下: 其中resources资源目录中: stopwd.txt :停顿词,匹配时间直接过滤. wd.txt:敏感词库. 1.WordFilter敏感词过滤类: package com.s ...
- Java实现敏感词过滤 - DFA算法
Java实现DFA算法进行敏感词过滤 封装工具类如下: 使用前需对敏感词库进行初始化: SensitiveWordUtil.init(sensitiveWordSet); package cn.swf ...
- 敏感词过滤的算法原理之DFA算法
参考文档 http://blog.csdn.net/chenssy/article/details/26961957 敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有 ...
- DFA和trie特里实现敏感词过滤(python和c语言)
今天的项目是与完成python开展,需要使用做关键词检查,筛选分类,使用前c语言做这种事情.有了线索,非常高效,内存小了,检查快. 到达python在,第一个想法是pip基于外观的c语言python特 ...
- Jsp敏感词过滤
Jsp敏感词过滤 大部分论坛.网站等,为了方便管理,都进行了关于敏感词的设定. 在多数网站,敏感词一般是指带有敏感政治倾向(或反执政党倾向).暴力倾向.不健康色彩的词或不文明语,也有一些网站根据自身实 ...
- Java实现敏感词过滤
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
- Java实现敏感词过滤(转)
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
- 转:Java实现敏感词过滤
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
随机推荐
- Solution -「营业」「ABC 209F」Deforestation
Description Link. 有 \(n\) 棵树,每棵的高度为 \(a(i)\),看到一棵树对答案的贡献为 \(a(i-1)+a(i)+a(i+1)\)(未定义范围为 \(0\)),求 ...
- 【爬虫笔记】Python爬虫简单运用爬取代理IP
一.前言 近些年来,网络上的爬虫越来越多,很多网站都针对爬虫进行了限制,封禁了一些不规则的请求.为了实现正常的网络爬虫任务,爬虫常用代理IP来隐藏自己的真实IP,避免被服务器封禁.本文将介绍如何使用P ...
- Python基础——二分法、面向过程编程思想、有名函数、lambda、max、_min的应用、sorted排序、map的应用、filter的应用、reduce的应用
文章目录 内容回顾 二分法 伪代码模板 面向过程编程思想 函数式 def用于定义有名函数 lambda用于定义匿名函数 调用匿名函数 匿名函数作用 匿名函数的示范 max的应用 min的应用 sort ...
- 客制开发tiptop程序随记-pta表结构问题-误删表的恢复
添加字段的语法:alter table tablename add (column datatype [default value][null/not null],-.); 删除字段的语法:alter ...
- sql分组后排序计算
用法:RANK() OVER(PARTITION BY 分组字段 ORDER BY 排序字段 ) 例子:要得到n4列 ---创建测试数据create table tb(n1 varchar2(40) ...
- 快速启动Stable Diffusion WebUI
快速启动Stable Diffusion WebUI详情 产品文档 输入文档关键字查找 机器学习PAI 产品概述 快速入门 操作指南 准备工作 开通PAI并创建默认工作空间 开通并授权依 ...
- CF707B
题目简化和分析: 这题看着玄胡很水实际. 我们需要做什么? 只需对每个工厂周围的面包店遍历一遍打擂台取最小 注意只对面包店遍历,所以对工厂设标记 如果打完擂台发现 \(ans=inf\) 则说明全是工 ...
- js下IE和FF的一些兼容写法总结
一.脚本差异: 1.事件绑定:addEventListener 与 attachEvent 事件处理函数中this指向不同, IE中指向window 2.获取事件对象 :事件处理函数 win ...
- 洛谷P1990
这是一道dp的题,好像也不算dp.需要递推,感觉能训练思维!!!很棒的一道题. 覆盖墙壁 关于这道题的分析 状态表示:f[i][0]表示前i列全部填满的所有方案,f[i][1]表示前i列全部填满缺一个 ...
- 不可复制的PDF转成双层可复制PDF
有些PDF是通过扫描或者虚拟打印机生成的,这些PDF不可复制里边的内容 市面上的工具一般都是收费或者有水印,所以就萌生了自己搞一个的想法: 使用了以下三个开源库 PdfiumViewer PDF预览及 ...