hadoop-hdfs分布式文件系统
- SecondaryNameNode 在一定程度上可以对NameNode进行备份,但不是热备。
- Block的副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在与第一个副本不同的机架的节点上。
- 第三个副本:与第二个副本相同机架的节点。(在同一个机架上可以保证传输速度,同一个机架一般是一个交换机)
- 更多副本:随机节点

- HDFS读流程

- 1.客户端发送请求,通过调用API 发送请求给NameNode
- 2.获得相应block的位置信息
- 3.通过API 并发的读各个block
- 4,5 并发的读block (block的副本有多个,只读一个从空闲的机器上)
- 6. 返回给客户端,并关闭流
- 注意,这个一般不会读一个超大的文件
- HDFS 写流程
-
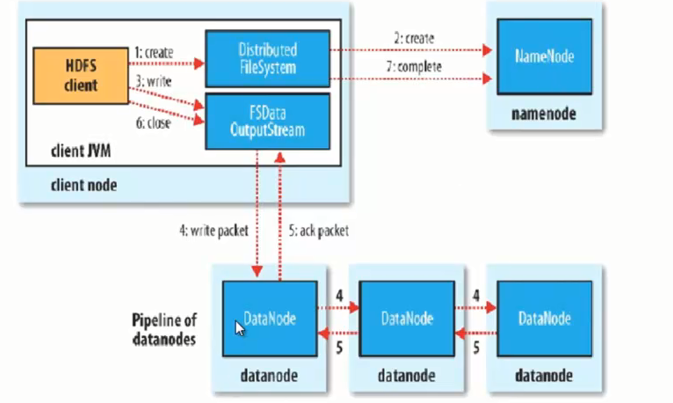
- 注意:副本产生机制是datanode自己进行复制的,不是客户端写三份,dataNode会启动新的线程,进行副本的拷贝。
-
使用3台机器搭建hdfs完全分布式集群 201(NameNode),202(DataNode),203(DataNode)
整体架构
NameNode(192.168.1.201)
DataNode(192.168.1.202,192.168.1.203)
SecondaryNameNode(192.168.1.202)
1.从官网上下载hadoop包,并上传到linux系统上
hadoop-1.2.1.tar.gz
解压
tar -zxvf hadoop-1.2.1.tar.gz linux服务器上需要jdk环境
由于名字长,可以加一条软连
ln -sf /root/hodoop-1.2.1 /home/hodoop-1.2
2.修改 core-site.xml配置文件
vi /home/hadoop-1.2/conf
配置NameNode主机及端口号,配置工作目录
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.201:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-1.2</value>
</property>
</configuration>
默认的工作目录在tmp目录下,linux系统重新启东时会清空tmp目录
在解压hadoop压缩包后
/hadoop-1.2.1/docs/core-default.html
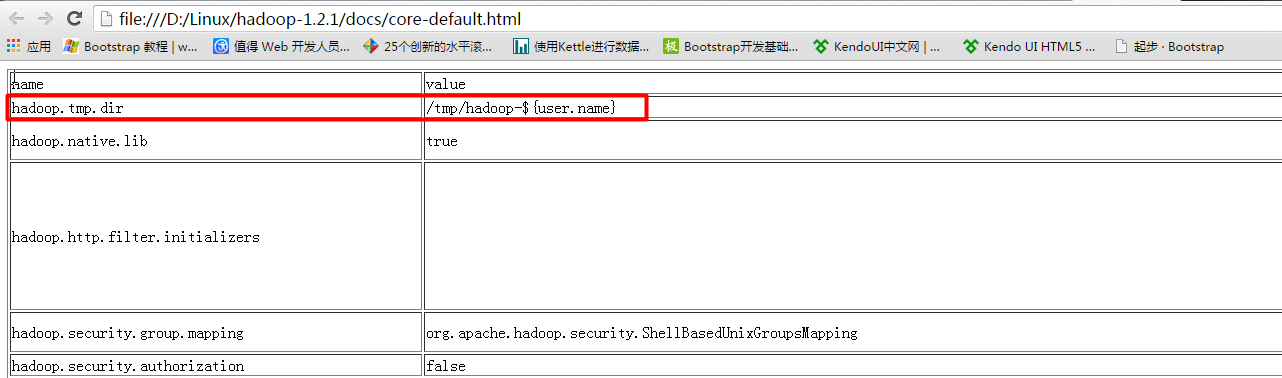
hdfs的工作目录是以tmp临时目录为基础的
3.配置conf/hdfs-site.xml
配置dfs.replication,配置DataNode的副本个数 202,203作为dataNode,所以副本个数 <= 2
同样的副本不能再同一台机器上,副本个数一定是<=DataNode个数
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4.配置dataNode节点
vi /conf/slaves (可以不使用ip地址,使用主机名)

5.配置SecondaryNameNode,注意不能与NameNode在同一台机器上
vi /conf/masters
192.168.1.202
6.配置免密码登录
免密码登录可以在任意一台机器上输入命令,可以启动所有机器上的进程
如果不做免密码登录,需要在每一台机器上输入启动进程命令
配置201上的免密码登录
在201上生成秘钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在.ssh目录下生成
[root@bogon .ssh]# ls
authorized_keys id_dsa id_dsa.pub known_hosts
[root@bogon .ssh]#
id_dsa 为私钥,id_dsa.pub为公钥
配置单台机器的免密码登录
执行下列命令
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
配置跨节点的免密码登录
先执行
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
生成id_dsa.pub公钥
将id_dsa.pub拷贝到将要免密码登录的那台机器上
scp id_dsa.pub root@192.168.1.202:~
在 192.168.1.202 上将id_dsa.pub追加到 authorized_keys 日子文件上
$ cat ~/id_dsa.pub >> ~/.ssh/authorized_keys
使用 more authorized_keys 查看
在201上使用 ssh 192.168.1.202:22 登录到202上
需要先做本地免密码登录,然后做跨节点免密码登录
配置结果为 201-->202,201-->203, 如果需要相反,则主要重复上边相反过程
7.所有节点进行相同配置
拷贝压缩包
scp -r ~/hadoop-1.2.1.tar.gz root@192.168.1.202:~/
解压
tar -zxvf hadoop-1.2.1.tar.gz
创建软连
ln -sf /root/hadoop-1.2.1 /home/hodoop-1.2
进行格式化
[root@bogon bin]# ./hadoop namenode -format
配置JAVA_HOME
[root@bogon conf]# vi hadoop-env.sh
# Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes. # The java implementation to use. Required.
export JAVA_HOME=/usr/java/jdk1.7.0_75 # Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH= # The maximum amount of heap to use, in MB. Default is .
# export HADOOP_HEAPSIZE= # Extra Java runtime options. Empty by default.
# export HADOOP_OPTS=-server # Command specific options appended to HADOOP_OPTS when specified
"hadoop-env.sh" 57L, 2433C
将已配置好的配置文件拷贝到其他机器上(需要拷贝到202,203上)
[root@bogon conf]# scp ./* root@192.168.1.202:/home/hadoop-1.2/conf/
启动
[root@bogon bin]# ./start-dfs.sh
在启动前需要关闭防火墙
service iptables stop
启动后可以使用 jps 查看是否启动成功
hadoop-hdfs分布式文件系统的更多相关文章
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- 我理解中的Hadoop HDFS分布式文件系统
一,什么是分布式文件系统,分布式文件系统能干什么 在学习一个文件系统时,首先我先想到的是,学习它能为我们提供什么样的服务,它的价值在哪里,为什么要去学它.以这样的方式去理解它之后在日后的深入学习中才能 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
- HDFS分布式文件系统资源管理器开发总结
HDFS,全称Hadoop分布式文件系统,作为Hadoop生态技术圈底层的关键技术之一,被设计成适合运行在通用硬件上的分布式文件系统.它和现有的分布式文件系统有很多共同点,但同时,它和其他的分布式 ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
- 通过Thrift访问HDFS分布式文件系统的性能瓶颈分析
通过Thrift访问HDFS分布式文件系统的性能瓶颈分析 引言 Hadoop提供的HDFS布式文件存储系统,提供了基于thrift的客户端访问支持,但是因为Thrift自身的访问特点,在高并发的访问情 ...
- 【转】Hadoop HDFS分布式环境搭建
原文地址 http://blog.sina.com.cn/s/blog_7060fb5a0101cson.html Hadoop HDFS分布式环境搭建 最近选择给大家介绍Hadoop HDFS系统 ...
- 认识HDFS分布式文件系统
1.设计基础目标 (1) 错误是常态,需要使用数据冗余 (2)流式数据访问.数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理. (3)文件采用一次性写多次读的模型, ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
随机推荐
- 纯js代码实现手风琴特效
我知道现在大多数前端开发人员都在使用jQuery等第三方的库来进行开发,这不仅节约了时间,也让效率大大的提高,并让公司的效益增加,何乐而不为呢? 但是,这也会有一定的缺点,比如jQ比js慢,尤其在大型 ...
- Linux下误删除后的恢复操作(ext3/ext4)
Linux是作为一个多用户.多任务的操作系统,文件一旦被删除是难以恢复的.尽管删除命令只是在文件节点中作删除标记,并不真正清除文件内容,但是其他用户和一些有写盘动作的进程会很快覆盖这些数据.在日常工程 ...
- MySql MyISAM和InnoDB的区别
MyISAM:这个是默认类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的 顺序访问方法) 的缩写,它是存储记录和文件的标准方法. ...
- JS/JQ常见兼容辅助插件
1.Respond.js Respond.js 是一个快速.轻量的 polyfill,用于为 IE6-8 以及其它不支持 CSS3 Media Queries 的浏览器提供媒体查询的 min-widt ...
- swift UIImage加载远程图片和圆角矩形
UIImage这个对象是swift中的图像类,可以使用UIImageView加载显示到View上. 以下是UIImage的构造函数: init(named name: String!) -> U ...
- CSS3 动画效果带来的bug
css3 动画效果比如transition:all 2s linear;这种用来计算及时的物体坐标的话会带来一定的问题 比如把一个DIV从A点移动到B点.JS为DIV.style.left=B; 但是 ...
- 直流调速系统Modelica基本模型
为了便于在OpenModelica进行仿真,形成一个完整的仿真模型,没有使用第三方的库,参照了DrModelica的例程,按照Modelica库的开源模型定义了所用的基本元件模型. 首先给出一些基本类 ...
- 探究JVM——运行时数据区
最近在读<深入理解Java虚拟机>,收获颇丰,记录一下,部分内容摘自原书. Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途,以 ...
- ModernUI教程:目录 (完结)
入门 My first Modern UI app (manually) 第一个ModernUI应用(手动编写)(已完成) My first Moder ...
- 单元测试中Assert类的用法
Assert类所在的命名空间为Microsoft.VisualStudio.TestTools.UnitTesting 在工程文件中只要引用Microsoft.VisualStudio.Quality ...