Faster-rnnlm代码分析3 - EvaluateLM(前向计算ForwardPropagate)
先采用一个简单的输入文本做测试
[root@cq01-forum-rstree01.cq01.baidu.com rnnlm]# pwd
/home/users/chenghuige/rsc/app/search/sep/anti-spam/rnnlm
[root@cq01-forum-rstree01.cq01.baidu.com rnnlm]# cat shijiebei2.txt
喜欢 观看 巴西 足球 世界杯
喜欢 观看 巴西 足球
喜欢 观看 巴西 足球
喜欢 观看 巴西
喜欢 观看 巴西
喜欢 观看
喜欢
喜欢
[root@cq01-forum-rstree01.cq01.baidu.com rnnlm]# gdb ./rnnlm
(gdb) b 157
Breakpoint 1 at 0x40e0a3: file rnnlm.cc, line 157.
(gdb) r -rnnlm model -train shijiebei2.txt -valid shijiebei2.txt -hidden 5- -direct-order 3 -direct 200 -bptt 4 -bptt-block 10 -threads 1
Starting program: /home/users/chenghuige/rsc/app/search/sep/anti-spam/rnnlm/rnnlm -rnnlm model -train shijiebei.txt -valid shijiebei.txt -hidden 5- -direct-order 3 -direct 200 -bptt 4 -bptt-block 10 -threads 1
Read the vocabulary: 6 words
Restoring existing nnet
Constructing RNN: layer_size=5, layer_type=sigmoid, layer_count=1, maxent_hash_size=199999998, maxent_order=3, vocab_size=6, use_nce=0
Contructed HS: arity=2, height=4
Breakpoint 1, EvaluateLM (nnet=0xf6e300, filename="shijiebei.txt", print_logprobs=false, accurate_nce=true) at rnnlm.cc:157
157 IRecUpdater* rec_layer_updater = nnet->rec_layer->CreateUpdater();
class IRecUpdater {
public:
IRecUpdater(int layer_size)
: size_(layer_size)
, input_(MAX_SENTENCE_WORDS, size_)
, input_g_(MAX_SENTENCE_WORDS, size_)
, output_(MAX_SENTENCE_WORDS, size_)
, output_g_(MAX_SENTENCE_WORDS, size_) {}
virtual ~IRecUpdater() {}
RowMatrix& GetInputMatrix() { return input_; }
RowMatrix& GetInputGradMatrix() { return input_g_; }
RowMatrix& GetOutputMatrix() { return output_; }
RowMatrix& GetOutputGradMatrix() { return output_g_; }
void ForwardSequence(int steps) { return ForwardSubSequence(0, steps); }
void ForwardStep(int step_idx) { return ForwardSubSequence(step_idx, 1); }
virtual void BackwardSequence(int steps, uint32_t truncation_seed, int bptt_period, int bptt) = 0;
virtual void UpdateWeights(int steps, Real lrate, Real l2reg, Real rmsprop, Real gradient_clipping) = 0;
virtual void ForwardSubSequence(int start, int steps) = 0;
// Returns list of pointers on updates
// The order must much one in corresponding methods in weight class
virtual std::vector<WeightMatrixUpdater<RowMatrix>*> GetMatrices() = 0;
virtual std::vector<WeightMatrixUpdater<RowVector>*> GetVectors() = 0;
protected:
const int size_;
RowMatrix input_, input_g_;
RowMatrix output_, output_g_;
};
为了方便观察
我把 MAX_SENTENCE_WORDS设置为10
(gdb) p *rec_layer_updater
$2 = {_vptr.IRecUpdater = 0x7076b0 <vtable for SimpleRecurrentLayer::Updater+16>, size_ = 5,
input_ = { m_storage = {m_data = 0xf7e1a0, m_rows = 10,
m_cols = 5}}, <No data fields>},
所以对应input_,input_g_,output_,output_g_
4个数组都是 (MAX_SENTENCE_WORDS, hidden_size)
整个EvaluateLM的框架流程是这样的(不考虑nce,及一些边界或者特殊情况)
Real logprob_sum = 0;
uint64_t n_words = 0
while (reader.Read()) {
//获取当前句子的
对应查找Vacabulary词典后的数字编号得到一个数组
const WordIndex* sen = reader.sentence();
int seq_length = reader.sentence_length();
Real sen_logprob = 0.0;
//对应该句子前向计算
PropagateForward(nnet, sen, seq_length, rec_layer_updater);
//通过output层
算出对应该句子
当前的log(p)
const Real logprob = nnet->softmax_layer->CalculateLog10Probability(
sen[target], ngram_hashes, maxent_present, kHSMaxentPrunning,
output.row(target - 1).data(), &nnet->maxent_layer);
sen_logprob -= logprob;
n_words += seq_length;
logprob_sum += sen_logprob;
}
Real entropy = logprob_sum / log10(2) / n_words;
return entropy
恩
这里用的是交叉熵,参考之前介绍语言模型的评估,和PPL的关系就是一个2^的关系 PPL = 2^cross_entropy
- 首先看下句子的索引编号数组是咋样的
sen_[0] = 0 //首先添加了<s>
然后读取的时候
以 </s>对应读到0 作为结束
I1110 11:45:06.033421 3878 words.cc:327] buffer -- [喜欢] *wid -- [1]
I1110 11:45:06.033535 3878 words.cc:327] buffer -- [观看] *wid -- [2]
I1110 11:45:06.033542 3878 words.cc:327] buffer -- [巴西] *wid -- [3]
I1110 11:45:06.033548 3878 words.cc:327] buffer -- [足球] *wid -- [4]
I1110 11:45:06.033555 3878 words.cc:327] buffer -- [世界杯] *wid -- [5]
I1110 11:45:06.033562 3878 words.cc:327] buffer -- [</s>] *wid -- [0]
I1110 11:45:06.033573 3878 rnnlm.cc:189] senVec --- 6
I1110 11:45:06.033579 3878 rnnlm.cc:189] 0 0
I1110 11:45:06.033587 3878 rnnlm.cc:189] 1 1
I1110 11:45:06.033592 3878 rnnlm.cc:189] 2 2
I1110 11:45:06.033597 3878 rnnlm.cc:189] 3 3
I1110 11:45:06.033602 3878 rnnlm.cc:189] 4 4
I1110 11:45:06.033607 3878 rnnlm.cc:189] 5 5
I1110 11:45:06.036772 3878 words.cc:327] buffer -- [喜欢] *wid -- [1]
I1110 11:45:06.036780 3878 words.cc:327] buffer -- [观看] *wid -- [2]
I1110 11:45:06.036787 3878 words.cc:327] buffer -- [巴西] *wid -- [3]
I1110 11:45:06.036792 3878 words.cc:327] buffer -- [足球] *wid -- [4]
I1110 11:45:06.036798 3878 words.cc:327] buffer -- [</s>] *wid -- [0]
I1110 11:45:06.036808 3878 rnnlm.cc:189] senVec --- 5
I1110 11:45:06.036813 3878 rnnlm.cc:189] 0 0
I1110 11:45:06.036818 3878 rnnlm.cc:189] 1 1
I1110 11:45:06.036823 3878 rnnlm.cc:189] 2 2
I1110 11:45:06.036828 3878 rnnlm.cc:189] 3 3
I1110 11:45:06.036834 3878 rnnlm.cc:189] 4 4
I1110 11:45:06.036772 3878 words.cc:327] buffer -- [喜欢] *wid -- [1]
I1110 11:45:06.036780 3878 words.cc:327] buffer -- [观看] *wid -- [2]
I1110 11:45:06.036787 3878 words.cc:327] buffer -- [巴西] *wid -- [3]
I1110 11:45:06.036792 3878 words.cc:327] buffer -- [足球] *wid -- [4]
I1110 11:45:06.036798 3878 words.cc:327] buffer -- [</s>] *wid -- [0]
I1110 11:45:06.036808 3878 rnnlm.cc:189] senVec --- 5
I1110 11:45:06.036813 3878 rnnlm.cc:189] 0 0
I1110 11:45:06.036818 3878 rnnlm.cc:189] 1 1
I1110 11:45:06.036823 3878 rnnlm.cc:189] 2 2
I1110 11:45:06.036828 3878 rnnlm.cc:189] 3 3
I1110 11:45:06.036834 3878 rnnlm.cc:189] 4 4
I1110 11:45:06.041893 3878 words.cc:327] buffer -- [喜欢] *wid -- [1]
I1110 11:45:06.041901 3878 words.cc:327] buffer -- [观看] *wid -- [2]
I1110 11:45:06.041908 3878 words.cc:327] buffer -- [巴西] *wid -- [3]
I1110 11:45:06.041913 3878 words.cc:327] buffer -- [</s>] *wid -- [0]
I1110 11:45:06.041921 3878 rnnlm.cc:189] senVec --- 4
I1110 11:45:06.041926 3878 rnnlm.cc:189] 0 0
I1110 11:45:06.041931 3878 rnnlm.cc:189] 1 1
I1110 11:45:06.041936 3878 rnnlm.cc:189] 2 2
I1110 11:45:06.041941 3878 rnnlm.cc:189] 3 3
… 大概这个样子
,看一下对第一个句子的处理
喜欢 观看 巴西 足球 世界杯
I1110 11:45:06.033421 3878 words.cc:327] buffer -- [喜欢] *wid -- [1]
I1110 11:45:06.033535 3878 words.cc:327] buffer -- [观看] *wid -- [2]
I1110 11:45:06.033542 3878 words.cc:327] buffer -- [巴西] *wid -- [3]
I1110 11:45:06.033548 3878 words.cc:327] buffer -- [足球] *wid -- [4]
I1110 11:45:06.033555 3878 words.cc:327] buffer -- [世界杯] *wid -- [5]
I1110 11:45:06.033562 3878 words.cc:327] buffer -- [</s>] *wid -- [0]
I1110 11:45:06.033573 3878 rnnlm.cc:189] senVec --- 6
I1110 11:45:06.033579 3878 rnnlm.cc:189] 0 0
I1110 11:45:06.033587 3878 rnnlm.cc:189] 1 1
I1110 11:45:06.033592 3878 rnnlm.cc:189] 2 2
I1110 11:45:06.033597 3878 rnnlm.cc:189] 3 3
I1110 11:45:06.033602 3878 rnnlm.cc:189] 4 4
I1110 11:45:06.033607 3878 rnnlm.cc:189] 5 5
这里提一下rnnlm的计算思路,参考Mikolov的<<Statistical Language Models Based on Neural Net-Works>>

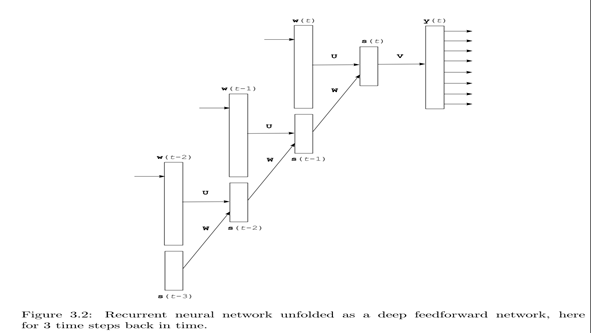
参考图3.1 这里输入w(t)可以看成一个 one-hot的vector,也就是长度为Vacabulary的大小|V|,每个词对应一个位置为1 其余位置为0,本质就是一个词编号作用。
图3.2是一个整体结构图,注意不同t step对应的U,W是相同的
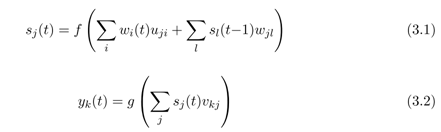
f对应隐层的计算, f可以有多种非线性映射选择,这里简单的可以采用sigmoid
g对应输出层,softmax, softmax意味着概率值之和累加为1

公式


这里 W 对应 H*H
U对应 H*V
U其实对应embedding矩阵,也就是每个词汇对应的一个长度为hidden size的词向量 U (V*H) wU 1 * V V * H -> 1 * H
sW 1 * H H * H -> 1 * H
累加结果
然后softmax输出即可
其实wU 就是简单对应每个单词通过其编号index选取embedding矩阵中词向量的一行即可
前向传播计算对应上面所说的过程
inline void PropagateForward(NNet* nnet, const WordIndex* sen, int sen_length, IRecUpdater* layer) {
RowMatrix& input = layer->GetInputMatrix();
for (int i = 0; i < sen_length; ++i) {
input.row(i) = nnet->embeddings.row(sen[i]); //对应上面提到的wU也就是选取embedding中词向量的一行
}
layer->ForwardSequence(sen_length);
}
看一下ForwardSequence
void SimpleRecurrentLayer::Updater::ForwardSubSequence(int start, int steps) {
output_.middleRows(start, steps) = input_.middleRows(start, steps);
if (use_input_weights_) {
output_.middleRows(start, steps) *= syn_in_.W().transpose();
}
for (int step = start; step < start + steps; ++step) {
if (step != 0) {
output_.row(step).noalias() += output_.row(step - 1) * syn_rec_.W().transpose(); //对应 wU + sW
}
activation_->Forward(output_.row(step).data(), output_.cols()); //对应隐层的非线性f计算
}
}
struct SigmoidActivation : public IActivation {
void Forward(Real* hidden, int size) {
Pval(size);
for (int i = 0; i < size; i++) {
hidden[i] = exp(hidden[i]) / (1 + exp(hidden[i]));
}
}
然后看下EvaluateLM大框架中的
CalculateLog10Probability
const Real logprob = nnet->softmax_layer->CalculateLog10Probability(
sen[target], ngram_hashes, maxent_present, kHSMaxentPrunning,
output.row(target - 1).data(), &nnet->maxent_layer);
看使用HSTree方式的,这里先略过maxent部分
关于
hierarchical softmax 参考
http://www.tuicool.com/articles/7jQbQvr
// see the comment in the header
Real HSTree::CalculateLog10Probability(
WordIndex target_word,
const uint64_t* feature_hashes, int maxent_order,
bool dynamic_maxent_prunning,
const Real* hidden, const MaxEnt* maxent) const {
double softmax_state[ARITY];
//一般使用二叉huffman 也就是softmax_state[2]
Real logprob = 0.;
//从root开始遍历到叶子节点过程(不包括叶子节点)中的每个节点
for (int depth = 0; depth < tree_->GetPathLength(target_word) - 1; depth++) {
int node = tree_->GetPathToLeaf(target_word)[depth];
PropagateNodeForward(
this, node, hidden,
feature_hashes, maxent_order, maxent,
softmax_state);
//获取分支0 or 1
const int selected_branch = tree_->GetBranchPathToLead(target_word)[depth];
logprob += log10(softmax_state[selected_branch]); //从root到叶子内部节点预测的累加

这里再取了log
}
return logprob;
}
这里看下
PropagateNodeForward
inline void PropagateNodeForward(
const HSTree* hs, int node, const Real* hidden,
const uint64_t* feature_hashes, int maxent_order, const MaxEnt* maxent,
double* state) {
Real tmp[ARITY];
//(gdb) p tmp[0]
//$8 = -nan(0x7fcfc0)
//(gdb) p tmp[1]
//$9 = 4.59163468e-41
CalculateNodeChildrenScores(hs, node, hidden, feature_hashes, maxent_order, maxent, tmp);
//(gdb) p tmp[0]
//$10 = 3.87721157
//(gdb) p tmp[1]
//$11 = 4.59163468e-41
double max_score = 0;
state[ARITY - 1] = 1.;
double f = state[ARITY - 1];
for (int i = 0; i < ARITY - 1; ++i) {
state[i] = exp(tmp[i] - max_score);
f += state[i];
}
for (int i = 0; i < ARITY; ++i) {
state[i] /= f;
}
F = 1 + exp^tmp
Result = exp^temp / 1 + exp^tmp 刚好是softmax方式
}
inline void CalculateNodeChildrenScores(
const HSTree* hs, int node, const Real* hidden,
const uint64_t* feature_hashes, int maxent_order, const MaxEnt* maxent,
Real* branch_scores) {
for (int branch = 0; branch < ARITY - 1; ++branch) {
branch_scores[branch] = 0;
int child_offset = hs->tree_->GetChildOffset(node, branch); //2叉不需要考虑branch 就是每个内部节点对应的索引
const Real* sm_embedding = hs->weights_.row(child_offset).data();
for (int i = 0; i < hs->layer_size; ++i) {
branch_scores[branch] += hidden[i] * sm_embedding[i];
//binary soft max
}
}
}
(gdb) p hs->weights_
$16 = {<Eigen::m_storage = {m_data = 0xf6e680, m_rows = 6,
m_cols = 5}}, <No data fields>}
hs->weights_ (word_num, hidden_size)
但是这里注意其实都是对应内部节点的
内部节点的数目 = leafNum - 1
默认的2叉huffman其实就不用考虑branch了
必然是0,
也就是其实是对应每个内部节点
一组权重参数数据
Faster-rnnlm代码分析3 - EvaluateLM(前向计算ForwardPropagate)的更多相关文章
- tensorflow faster rcnn 代码分析一 demo.py
os.environ["CUDA_VISIBLE_DEVICES"]=2 # 设置使用的GPU tfconfig=tf.ConfigProto(allow_soft_placeme ...
- tensorflow笔记:多层LSTM代码分析
tensorflow笔记:多层LSTM代码分析 标签(空格分隔): tensorflow笔记 tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) ten ...
- Faster RCNN代码理解(Python)
转自http://www.infocool.net/kb/Python/201611/209696.html#原文地址 第一步,准备 从train_faster_rcnn_alt_opt.py入: 初 ...
- (转)x264源码分析(1):main、parse、encode、x264_encoder_open函数代码分析
转自:http://nkwavelet.blog.163.com/blog/static/2277560382013103010312144/ x264版本: x264-snapshot-2014 ...
- Android代码分析工具lint学习
1 lint简介 1.1 概述 lint是随Android SDK自带的一个静态代码分析工具.它用来对Android工程的源文件进行检查,找出在正确性.安全.性能.可使用性.可访问性及国际化等方面可能 ...
- 贪吃蛇的java代码分析(二)
代码剖析 贪吃蛇是一款十分经典的小游戏,对初入coding的朋友来说,拿贪吃蛇这样一个案例来练手十分合适,并不高的难度和成功后的成就感都是学习所必须的.下面我将依照我当时的思路,来逐步分析实现的整个过 ...
- 常用 Java 静态代码分析工具的分析与比较
常用 Java 静态代码分析工具的分析与比较 简介: 本文首先介绍了静态代码分析的基 本概念及主要技术,随后分别介绍了现有 4 种主流 Java 静态代码分析工具 (Checkstyle,FindBu ...
- wifi display代码 分析
转自:http://blog.csdn.net/lilian0118/article/details/23168531 这一章中我们来看Wifi Display连接过程的建立,包含P2P的部分和RTS ...
- 【C语言】03-第一个C程序代码分析
前面我们已经创建了一个C程序,接下来分析一下里面的代码. 项目结构如下: 一.代码分析 打开项目中的main.c文件(C程序的源文件拓展名为.c),可以发现它是第一个C程序中的唯一一个源文件,代码如下 ...
随机推荐
- C#高级编程笔记 Day 2, 2016年8月 31日 构造函数
1.构造函数: 实例构造函数(只要创建了对象,就会执行)一般使用 this 关键字区分成员字段和同名的参数.可以把构造函数定义为private 或 protected .这样不相关的类也不能访问他们. ...
- 跟着百度学PHP[4]OOP面对对象编程-8-继承
如下图所示.人就是父类!而NBA球员以及女主播就是子类 要继承一个类,那么在类名的后面加上extends 要继承的类名 具体格式:class Student extends human{} # ...
- 前端之常用标签和CSS初识
外层div的宽度是100%,就是视口的大小,当视口被拉窄到小于内层div的宽度980px时,比如800px,此时 外层div宽度为800px,内层div宽度依然为980px,而css中只设置了外层di ...
- python操作memcached以及分布式
memcached 是以 LiveJournal 旗下 Danga Interactive 公司的 Brad Fitzpatric 为首开发的一款软件.现在已成为 mixi.Facebook.Live ...
- <a href=”#”>与 <a href=”javascript:void(0)” 的区别
<a href=”#”>中的“#”其实是锚点的意思,默认为#top,所以当页面比较长的时候,使用这种方式会让页面刷新到页首(页面的最上部) javascript:void(0)其实是一个死 ...
- RRD
http://my.oschina.net/u/1458120/blog/208857
- Python之队列queue模块使用 常见问题与用法
python 中,队列是线程间最常用的交换数据的形式.queue模块是提供队列操作的模块,虽然简单易用,但是不小心的话,还是会出现一些意外. 1. 阻塞模式 import queue q = queu ...
- linux mysql查看安装信息
ps -ef|grep mysql root ? :: /bin/sh /usr/bin/mysqld_safe --datadir=/var/lib/mys ...
- 解读Unity中的CG编写Shader系列三
转自http://www.itnose.net/detail/6096068.html 在上一个例子中,我们得到了由mesh组件传递的信息经过数学转换至合适的颜色区间以颜色的形式着色到物体上.这篇文章 ...
- python pexpect 学习与探索
pexpect是python交互模块,有两种使用方法,一种是函数:run另外一种是spawn类 1.pexpect module 安装 pexpect属于第三方的,所以需要安装, 目前的版本是 3. ...