BloomFilter 与 Cuckoo Filter
BloomFilter 与 CuckooFilter
Bloom Filter 原理
Bloom Filter是一种空间效率很高的随机数据结构,它的原理是,当一个元素被加入集合时,通过K个相互独立的Hash函数将这个元素映射成一个位阵列(Bit array)中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了;如果这些点有任何一个0,则被检索元素一定不在;如果都是1,则被检索元素很可能在。
Bloom Filter的这种高效是有一定代价的,在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,并不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
假设要你写一个网络爬虫程序(web crawler)。由于网络间的链接错综复杂,爬虫在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道爬虫程序已经访问过那些URL。给一个URL,怎样知道爬虫程序是否已经访问过呢?稍微想想,就会有如下几种方案:
- 将访问过的URL保存到数据库。
- 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。
- URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库。
- Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。
其中,方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了:
方法1:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了?
方法2:太消耗内存。随着URL的增多,占用的内存会越来越多。就算只有1亿个URL,每个URL只算50个字符,就需要5GB内存。
方法3:由于字符串经过MD5处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。
方法4:消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的Hash表冲突的各种解决方法么?若要降低冲突发生的概率到1%,就要将BitSet的长度设置为URL个数的100倍。Bloom Filter 与单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第 i 个哈希函数对字符串str哈希的结果记为Hi(str),并且满足:
0 <= Hi(str) < m (1<=i<=k)
(1) 将字符串 str 映射到BitSet中的过程:分别计算H1(str),H2(str),…,Hk(str),然后在BitSet中将对应的位置1。
(2) 检查字符串str是否被BitSet记录过的过程:分别计算H1(str),H2(str),…,Hk(str),然后在BitSet中对应的位检查是否为1。若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则认为字符串str存在。注意:这里也可能存在误判,因为有可能该字符串的所有位都刚好是被其他字符串所对应,这种将该字符串划分错的情况称为false positive 。
(3) 删除字符串过程,字符串加入了就被不能删除了,因为删除会影响到其他字符串。
实在需要删除字符串的可以使用Counting Bloom Filter (CBF),这是一种基本Bloom Filter的变体,CBF将基本Bloom Filter每一个Bit改为一个计数器,这样就可以实现删除字符串的功能了。
Bloom Filter 参数选择
问题:m(bit-map位数), n(待处理的字符串个数), k(哈希函数个数)值,我们该如何取值呢?
当hash函数个数 k = (ln2) * (m/n) 时错误率最小。
在错误率不大于e的情况下,则m >= n*log2(1/e)*log2e 。
这里直接给出了结论,如果对上述公式推导过程感兴趣,可以参考这里。
举个例子我们假设错误率为0.001,则此时m应大概是n的14倍。这样k大概是4个。
Bloom Filter 应用
最后,总结下Bloom Filter 的优点:
- 节约缓存空间(空值的映射),不再需要空值映射;
- 减少数据库或缓存的请求次数;
- 提升业务的处理效率以及业务隔离性。
缺点:
- 存在误判的概率;
- 传统的Bloom Filter不能作删除操作(可以使用CBF来支持删除功能)。
Bloom Filter 可以用来实现数据字典,进行数据的判重,或者集合求交集 。
Cuckoo 布谷鸟哈希
前面提到,Bloom Filter 可能存在误报,并且无法删除元素,而Cuckoo哈希就是解决这两个问题的。
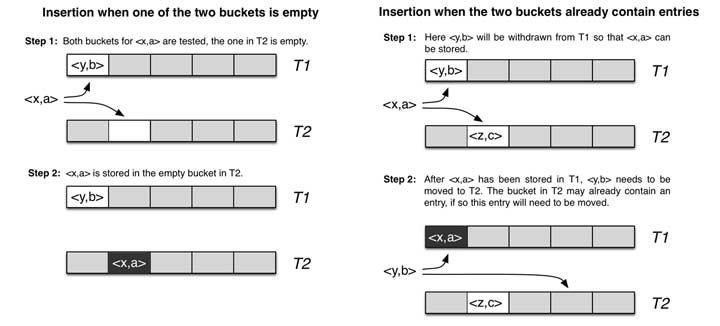
Cuckoo的哈希函数是成对的(具体的实现可以根据需求设计),每一个元素都是两个,分别映射到两个位置,一个是记录的位置,另一个是备用位置,这个备用位置是处理碰撞时用的。
如下图,使用hashA 和hashB 计算对应key x的位置a和b :
- 当两个哈希位置有一个为空时,则插入该空位置;
- 当两个哈希位置均不为空时,随机选择两者之一的位置上key y 踢出,并计算踢出的key y在另一个哈希值对应的位置,若为空直接插入,不为空踢出原元素插入,再对被踢出的元素重新计算,重复该过程,直到有空位置为止。
Cockoo hashing 有两种变形:一种通过增加哈希函数进一步提高空间利用率;另一种是增加哈希表,每个哈希函数对应一个哈希表,每次选择多个张表中空余位置进行放置,三个哈希表可以达到80% 的空间利用率。
Cockoo hashing 的过程可能因为反复踢出无限循环下去,这时候就需要进行一次循环踢出的限制,超过限制则认为需要添加新的哈希函数。
参考文档:
http://blog.csdn.net/v_july_v/article/details/6685894/
http://blog.csdn.net/v_july_v/article/details/7382693
https://github.com/jaybaird/python-bloomfilter/blob/master/pybloom/pybloom.py
http://coolshell.cn/articles/17225.html
BloomFilter 与 Cuckoo Filter的更多相关文章
- 过滤器系列(二)—— Cuckoo filter
这一篇讲的是布谷过滤器(cuckoo fliter),这个名字来源于更早发表的布谷散列(cuckoo hash),尽管我也不知道为什么当初要给这种散列表起个鸟名=_= 由于布谷过滤器本身的思想就源自于 ...
- 硬核 | Redis 布隆(Bloom Filter)过滤器原理与实战
在Redis 缓存击穿(失效).缓存穿透.缓存雪崩怎么解决?中我们说到可以使用布隆过滤器避免「缓存穿透」. 码哥,布隆过滤器还能在哪些场景使用呀? 比如我们使用「码哥跳动」开发的「明日头条」APP 看 ...
- cassandra框架模型之一——Colum排序,分区策略 Token,Partitioner bloom-filter,HASH
转自:http://asyty.iteye.com/blog/1202072 一.Cassandra框架二.Cassandra数据模型 Colum / Colum Family, SuperColum ...
- Cuckoo Hash——Hash冲突的解决办法
参考文献: 1.Cuckoo Filter hash算法 2.cuckoo hash 用途: Cuckoo Hash(布谷鸟散列).问了解决哈希冲突的问题而提出,利用较少的计算换取较大的空间.占用空间 ...
- 看看redis中那些好玩的module (sql on redis, bf/cf on redis)
自从redis加入了module功能之后,redis的生态就很有意思了,每个领域的大佬都会以插件的形式给redis扩展一些新的功能,比如本篇说到的rediSQL,rebloom. 一:rediSQL ...
- 学习索引结构的一些案例——Jeff Dean在SystemML会议上发布的论文(下)
[摘要] 除了范围索引之外,点查找的Hash Map在DBMS中起着类似或更重要的作用. 从概念上讲,Hash Map使用Hash函数来确定性地将键映射到数组内的随机位置(参见图[9 ],只有4位开销 ...
- Redis05——Redis高级运用(管道连接,发布订阅,布隆过滤器)
Redis高级运用 一.管道连接redis(一次发送多个命令,节省往返时间) 1.安装nc yum install nc -y 2.通过nc连接redis nc localhost 6379 3.通过 ...
- Go语言实现布谷鸟过滤器
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/453 介绍 在我们工作中,如果遇到如网页 URL 去重.垃圾邮件识别 ...
- HBase(八): 表结构设计优化
在 HBase(六): HBase体系结构剖析(上) 介绍过,Hbase创建表时,只需指定表名和至少一个列族,基于HBase表结构的设计优化主要是基于列族级别的属性配置,如下图: 目录: BLOOMF ...
随机推荐
- tomcat提示警告: An attempt was made to authenticate the locked user"tomcat"
启动tomcat7之后,运行正常,但是运行一段时间就会提示以下警告: 十二月 04, 2013 5:10:15 下午 org.apache.catalina.realm.LockOutRealm au ...
- 控件(选择类): ListBox, RadioButton, CheckBox, ToggleSwitch
1.ListBox 的示例Controls/SelectionControl/ListBoxDemo.xaml <Page x:Class="Windows10.Controls.Se ...
- log4net在Asp.net Mvc中的应用配置与介绍
log4net在.NET中的地位就不多言语了,此篇文章着重配置.较少介绍使用.因为在网上你可以在网上搜到几十万的文章告诉你怎么用.安装的话也不废话了,很简单.Nuget里搜索一下"log4n ...
- iOS中如何选择delegate、通知、KVO(以及三者的区别)
转载自:http://blog.csdn.net/dqjyong/article/details/7685933 在开发IOS应用的时候,我们会经常遇到一个常见的问题:在不过分耦合的前提下,contr ...
- angularjs 自带的过滤器
一,内置的过滤器 1,uppercase,lowercase大小转换 {{ "lower cap string" | uppercase }} //结果:LOWER CAP ...
- Oracle计算时间差表达式
有两个日期数据START_DATE,END_DATE,欲得到这两个日期的时间差(以天,小时,分钟,秒,毫秒): 天: ROUND(TO_NUMBER(END_DATE - START_DATE)) 小 ...
- BZOJ 1089: [SCOI2003]严格n元树
1089: [SCOI2003]严格n元树 Time Limit: 1 Sec Memory Limit: 162 MBSubmit: 1591 Solved: 795[Submit][Statu ...
- java循环遍历map
import java.util.HashMap; import java.util.Iterator; import java.util.Map; public class MapTest { pu ...
- CF 213A Game(拓扑排序)
传送门 Description Furik and Rubik love playing computer games. Furik has recently found a new game tha ...
- [JavaEE]Get请求URI中带的中文参数在服务端乱码问题的解决方法
在Get请求中,如果请求参数中带有中文,如 http://localhost:8080/DinnerParty/shop/search?query=多伦多, 在服务端拿到的是乱码. 这是因为客户端提交 ...