elasticsearch 基础 —— Mapping参数boost、coerce、copy_to、doc_values、dynamic、
boost
在查询时,各个字段可以自动提升 - 更多地依赖于相关性得分,boost参数如下:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"boost": 2
},
"content": {
"type": "text"
}
}
}
}
}title字段上的匹配将是content字段的两倍权重,默认字段的提升率为1。
增强仅适用于术语查询(前缀,范围和模糊查询不会被提升)。
通过在查询中直接使用boost参数,可以获得相同的效果,例如,以下查询(带有字段时间boost):
POST _search
{
"query": {
"match" : {
"title": {
"query": "quick brown fox"
}
}
}
}相当于:
POST _search
{
"query": {
"match" : {
"title": {
"query": "quick brown fox",
"boost": 2
}
}
}
}使用
_all字段中的值复制时,也会应用提升。这意味着,在查询_all字段时,源自字段的单词title将比源自content字段的单词具有更高的分数。此功能需_all要付出代价:使用字段提升时,字段上的查询速度会变慢。
在5.0.0中弃用。
不推荐使用index time boost。相反,字段映射提升在查询时应用。对于在5.0.0之前创建的索引,仍将在索引时应用提升。
为什么索引时提升是一个坏主意
我们建议不要使用索引时间提升,原因如下:
- 如果
boost不重新索引所有文档,则无法更改索引时间值。- 每个查询都支持查询时间提升,从而实现相同的效果。不同之处在于您
boost无需重新索引即可调整值。- 索引时间提升存储为一部分,
norm只有一个字节。这降低了场长归一化因子的分辨率,这可能导致较低质量的相关性计算
coerce
数据并不总是干净的。根据它的生成方式,数字可能会在JSON正文中呈现为真正的JSON数字,例如5,但它也可能呈现为字符串,例如"5"。或者,应该是整数的数字可以替代地呈现为浮点,例如5.0,或甚至"5.0"。
强制尝试清除脏值以适合字段的数据类型。例如:
- 字符串将被强制转换为数字。
- 浮点将被截断为整数值。
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"number_one": {
"type": "integer"
},
"number_two": {
"type": "integer",
"coerce": false
}
}
}
}
}
PUT my_index/_doc/1
{
"number_one": "10" ①
}
PUT my_index/_doc/2
{
"number_two": "10" ②
}
|
|
该 |
|
|
该文件将被拒绝,因为禁用强制。 |
coerce允许该设置对同一索引中的同名字段具有不同的设置。可以使用PUT映射API在现有字段上更新其值。
Index-level default索引级默认
index.mapping.coerce可以在索引级别设置该设置,以在所有映射类型中全局禁用强制:
PUT my_index
{
"settings": {
"index.mapping.coerce": false
},
"mappings": {
"_doc": {
"properties": {
"number_one": {
"type": "integer",
"coerce": true
},
"number_two": {
"type": "integer"
}
}
}
}
}
PUT my_index/_doc/1
{ "number_one": "10" }
PUT my_index/_doc/2
{ "number_two": "10" } |
|
该 |
|
|
此文档将被拒绝,因为该 |
copy_to
该copy_to参数允许您创建自定义 _all字段。换句话说,可以将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询。例如,可以将first_name和last_name字段复制到full_name字段,如下所示:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name" ①
},
"last_name": {
"type": "text",
"copy_to": "full_name" ②
},
"full_name": {
"type": "text"
}
}
}
}
}
PUT my_index/_doc/1
{
"first_name": "John",
"last_name": "Smith"
}
GET my_index/_search
{
"query": {
"match": {
"full_name": { ③
"query": "John Smith",
"operator": "and"
}
}
}
}|
|
|
|
|
该 |
一些要点:
- 它是复制的字段值,而不是术语(由分析过程产生的)。
_source不会修改 原始字段以显示复制的值。- 可以将相同的值复制到多个字段中
"copy_to": [ "field_1", "field_2" ]
Doc Values
为什么要有 Doc Values
我们都知道 ElasticSearch之所以搜索这么快速,归功于他的倒排索引的设计,然而它也不是万能的,倒排索引的检索性能是非常快的,但是在字段值排序时却不是理想的结构。下面是一个简单的倒排索引的结构
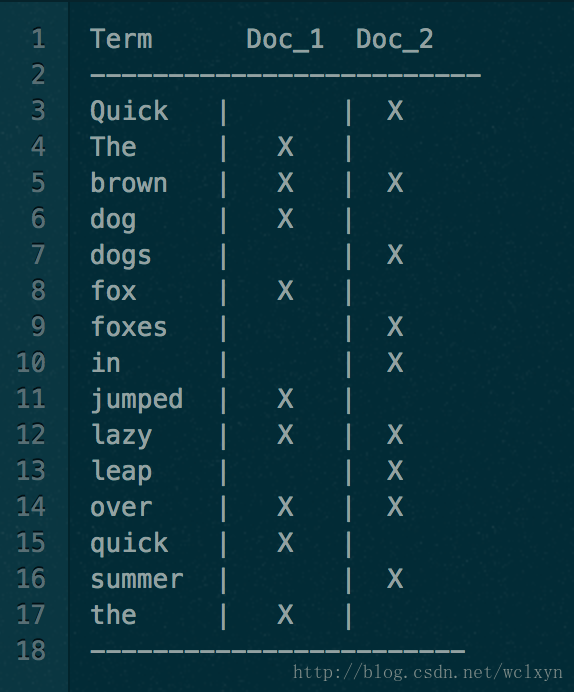
如上表便可以看出,他只有词对应的doc,但是并不知道每一个doc中的内容,那么如果想要排序的话每一个doc都去获取一次文档内容岂不非常耗时?Doc Values的出现使得这个问题迎刃而解。
Doc Values 是什么
其实大部分NoSQL在创建多个索引的时候也采用这种方式,就是再使用另一种方式存储一份文本,使得可以增强搜索。Doc values 通过转置两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档,Doc values 将文档映射到它们包含的词项:
当数据被转置之后,想要收集到每个文档行,获取所有的词项就非常简单了。所以搜索使用倒排索引查找文档,聚合操作收集和聚合 Doc Values 里的数据,这就是 ElasticSearch。
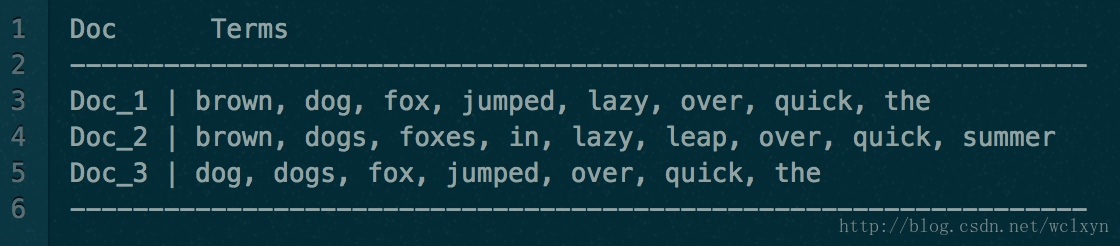
深入理解 ElasticSearch Doc Values
Doc Values 是在索引时与倒排索引同时生成。也就是说 Doc Values 和倒排索引一样,基于 Segement 生成并且是不可变的。同时 Doc Values 和倒排索引一样序列化到磁盘,这样对性能和扩展性有很大帮助。
Doc Values 通过序列化把数据结构持久化到磁盘,我们可以充分利用操作系统的内存,而不是 JVM 的 Heap 。 当 working set 远小于系统的可用内存,系统会自动将 Doc Values 保存在内存中,使得其读写十分高速; 不过,当其远大于可用内存时,操作系统会自动把 Doc Values 写入磁盘。很显然,这样性能会比在内存中差很多,但是它的大小就不再局限于服务器的内存了。如果是使用 JVM 的 Heap 来实现那么只能是因为 OutOfMemory 导致程序崩溃了。
Doc Values 压缩
从广义来说,Doc Values 本质上是一个序列化的 列式存储,这个结构非常适用于聚合、排序、脚本等操作。而且,这种存储方式也非常便于压缩,特别是数字类型。这样可以减少磁盘空间并且提高访问速度。下面来看一组数字类型的 Doc Values:

你会注意到这里每个数字都是 100 的倍数,Doc Values 会检测一个段里面的所有数值,并使用一个 最大公约数 ,方便做进一步的数据压缩。我们可以对每个数字都除以 100,然后得到:[1,10,15,12,3,19,42] 。现在这些数字变小了,只需要很少的位就可以存储下,也减少了磁盘存放的大小。
Doc Values 在压缩过程中使用如下技巧。它会按依次检测以下压缩模式:
- 如果所有的数值各不相同(或缺失),设置一个标记并记录这些值
- 如果这些值小于 256,将使用一个简单的编码表
- 如果这些值大于 256,检测是否存在一个最大公约数
- 如果没有存在最大公约数,从最小的数值开始,统一计算偏移量进行编码
当然如果存储String类型,其一样可以通过顺序表对String类型进行数字编码,然后再把数字类型构建Doc Values。
禁用 Doc Values
Doc Values 默认对所有字段启用,除了 analyzed strings。也就是说所有的数字、地理坐标、日期、IP 和不分析(not_analyzed)字符类型都会默认开启。
analyzed strings 暂时还不能使用 Doc Values,是因为经过分析以后的文本会生成大量的Token,这样非常影响性能。
虽然Doc Values非常好用,但是如果你存储的数据确实不需要这个特性,就不如禁用他,这样不仅节省磁盘空间,也许会提升索引的速度。
要禁用 Doc Values ,在字段的映射(mapping)设置 doc_values: false 即可。例如,这里我们创建了一个新的索引,字段 "session_id" 禁用了 Doc Values:
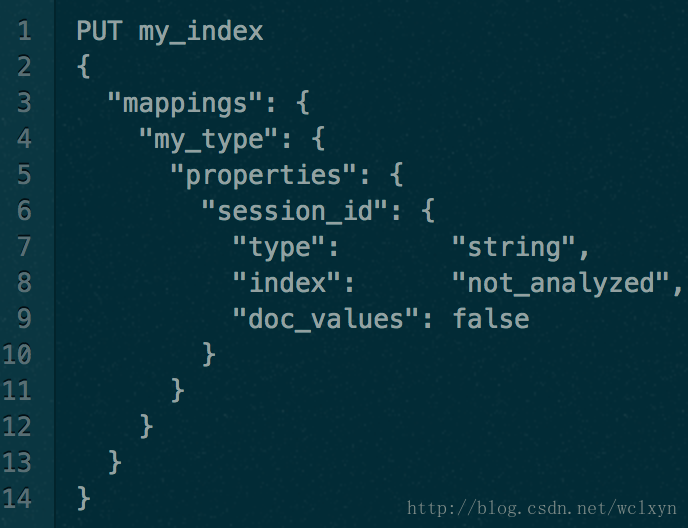
通过设置 doc_values: false ,这个字段将不能被用于聚合、排序以及脚本操作
同样可以禁用倒排索引,使它不能被正常搜索,但是可以排序,例如:通过设置 doc_values: true 和 index: no ,我们得到一个只能被用于聚合/排序/脚本的字段。
dynamic动态映射
默认情况下,只需索引包含新字段的文档,即可将字段动态添加到文档或文档中的 内部对象。例如:
PUT my_index/_doc/1 ①
{
"username": "johnsmith",
"name": {
"first": "John",
"last": "Smith"
}
}
GET my_index/_mapping ②
PUT my_index/_doc/2 ③
{
"username": "marywhite",
"email": "mary@white.com",
"name": {
"first": "Mary",
"middle": "Alice",
"last": "White"
}
}
GET my_index/_mapping ④|
|
本文档介绍字符串字段 |
|
|
检查映射以验证上述情况。 |
|
|
本文档添加了两个字符串字段: |
|
|
检查映射以验证更改。 |
动态映射中解释了如何检测新字段并将其添加到映射的详细信息。
该dynamic设置控制是否可以动态添加新字段。它接受三种设置:
|
|
新检测到的字段将添加到映射中。(默认) |
|
|
新检测到的字段将被忽略。这些字段不会被编入索引,因此无法搜索,但仍会出现在 |
|
|
如果检测到新字段,则抛出异常并拒绝该文档。必须将新字段显式添加到映射中。 |
dynamic可以在映射类型级别和每个内部对象上设置该设置 。内部对象从其父对象或映射类型继承该设置。例如:
PUT my_index
{
"mappings": {
"_doc": {
"dynamic": false, ①
"properties": {
"user": { ②
"properties": {
"name": {
"type": "text"
},
"social_networks": {
"dynamic": true, ③
"properties": {}
}
}
}
}
}
}
}
|
|
在类型级别禁用动态映射,因此不会动态添加新的顶级字段。 |
|
|
该 |
|
|
该 |
enabled启用
Elasticsearch尝试索引您提供的所有字段,但有时您只想存储字段而不对其进行索引。例如,假设您使用Elasticsearch作为Web会话存储。您可能希望索引会话ID和上次更新时间,但不需要在会话数据本身上查询或运行聚合。
该enabled设置只能应用于映射类型和 object字段,导致Elasticsearch完全跳过对字段内容的解析。仍然可以从_source字段中检索JSON ,但它不可搜索或以任何其他方式存储:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"user_id": {
"type": "keyword"
},
"last_updated": {
"type": "date"
},
"session_data": {
"enabled": false ①
}
}
}
}
}
PUT my_index/_doc/session_1
{
"user_id": "kimchy",
"session_data": { ②
"arbitrary_object": {
"some_array": [ "foo", "bar", { "baz": 2 } ]
}
},
"last_updated": "2015-12-06T18:20:22"
}
PUT my_index/_doc/session_2
{
"user_id": "jpountz",
"session_data": "none", ③
"last_updated": "2015-12-06T18:22:13"
}|
|
该 |
|
|
任何任意数据都可以传递给 |
|
|
该 |
整个映射类型也可能被禁用,在这种情况下,文档存储在_source字段中,这意味着它可以被检索,但其内容都不会以任何方式编入索引:
PUT my_index
{
"mappings": {
"_doc": { ①
"enabled": false
}
}
}
PUT my_index/_doc/session_1
{
"user_id": "kimchy",
"session_data": {
"arbitrary_object": {
"some_array": [ "foo", "bar", { "baz": 2 } ]
}
},
"last_updated": "2015-12-06T18:20:22"
}
GET my_index/_doc/session_1 ②
GET my_index/_mapping ③|
|
整个 |
|
|
可以检索该文档。 |
|
|
检查映射表明没有添加任何字段。 |
elasticsearch 基础 —— Mapping参数boost、coerce、copy_to、doc_values、dynamic、的更多相关文章
- ElasticSearch(5)-Mapping
一.Mapping概述 映射 为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成全文本(Full-text)或精确的字符串值,Elasticsearch需要知道每个字段里面都包含了 ...
- elasticsearch的mapping映射
Mapping简述 Elasticsearch是一个schema-less的系统,但并不代表no shema,而是会尽量根据JSON源数据的基础类型猜测你想要的字段类型映射.Elasticsearch ...
- 一文搞懂 Elasticsearch 之 Mapping
这篇文章主要介绍 Mapping.Dynamic Mapping 以及 ElasticSearch 是如何自动判断字段的类型,同时介绍 Mapping 的相关参数设置. 首先来看下什么是 Mappin ...
- Elasticsearch基础知识学习
概要 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Ap ...
- curl方式创建elasticsearch的mapping
curl方式创建elasticsearch的mapping curl -XPUT 'http://192.168.1.105:9200/bank/item2/_mapping' -d '{ " ...
- Elasticsearch 基础入门
原文地址:Elasticsearch 基础入门 博客地址:http://www.extlight.com 一.什么是 ElasticSearch ElasticSearch是一个基于 Lucene 的 ...
- elasticsearch 基础知识汇总
索引分片: 从策略层面,控制分片分配的选择 磁盘限额 为了保护节点数据安全,ES 会定时(cluster.info.update.interval,默认 30 秒)检查一下各节点的数据目录磁盘使用情况 ...
- ElasticSearch 基础 1
ElasticSearch 基础=============================== 索引创建 ========================== 1. RESTFUL APIAPI 基本 ...
- Elasticsearch基础但非常有用的功能之二:模板
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484584&idx=1&sn=accfb65 ...
随机推荐
- mvn 打包排除test
mvn clean package compile -Dmaven.test.skip=true
- 前端面试题:CSS实现水平垂直居中
这是一个挺常见的前端面试题,但是没有做过总结.有的时候可能会使用完了,很长一段时间不去使用,会慢慢忘记.所以,温故而知新,还是很有必要的. 一.绝对定位元素的居中实现 这一种工作中用的应该是最多的,兼 ...
- Linux命令行工具之vmstat命令
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11484608.html vmstat是一款指定采样周期和次数的功能性监测工具,可以使用它监控进程上下文 ...
- php-redis 使用命令
PHP 使用redis 一些命令参考:https://www.jianshu.com/p/68b7114a1d70
- linux运维、架构之路-内网NTP时间服务器
一.环境 [root@m01 tmp]# cat /etc/redhat-release CentOS release 6.9 (Final) [root@m01 tmp]# hostname -I ...
- php array()函数 语法
php array()函数 语法 作用:生成一个数组 语法:索引数组:array(value1,value2,value3,etc.);关联数组:array(key=>value,key=> ...
- [CSP-S模拟测试]:柱状图(树状数组+二分+三分)
题目描述 $WTH$获得了一个柱状图,这个柱状图一共有$N$个柱子,最开始第$i$根柱子的高度为$x_i$,他现在要将这个柱状图排成一个屋顶的形状,屋顶的定义如下:$1.$屋顶存在一个最高的柱子,假设 ...
- Vue子组件传递数据给父组件
子组件通过this.$emit(event,data)传递数据到父组件 以下是例子: father.vue 父组件 <template> <div> <child @ne ...
- Gym 100917F Find the Length
题目链接:http://codeforces.com/gym/100917/problem/F ---------------------------------------------------- ...
- EZOJ #387字符串
分析 似乎ttl的模拟赛t3总是折半搜索? 先把所有串转化为每个字母的0/1状态 之后我们将所有字符串分为两半 分别枚举状态 我们发现只有左右两边的字母状态相等才能保证这个集合合法 所以我们在搜左半边 ...