【转载 | 翻译】Visualizing A Neural Machine Translation Model(神经机器翻译模型NMT的可视化)
转载并翻译Jay Alammar的一篇博文:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
神经机器翻译模型(基于注意力机制的Seq2Seq模型)的可视化
Sequence to Sequence(以下简称Seq2Seq)模型已经在诸如“机器翻译”、“文本摘要”、“图片描述”等领域取得了不俗的成绩。谷歌翻译也从2016年底开始,在其产品中使用了此模型。(相关细节参见早期的两篇论文:Sutskever et al., 2014, Cho et al., 2014)。
尽管如此,想要深刻理解并实现Seq2Seq模型,需要拆解一系列“错综复杂”的概念。我觉得如果把这些概念及其关联用可视化的方法表现出来,可能会更有助于理解。这就是我写这篇博文的主要目的。当然想要看懂这篇博文,你需要提前学习并掌握一些深度学习的相关知识。总之,期望这篇博文能对你理解上面提到的两篇论文(以及稍后提到的注意力机制论文)带来有用的帮助~!
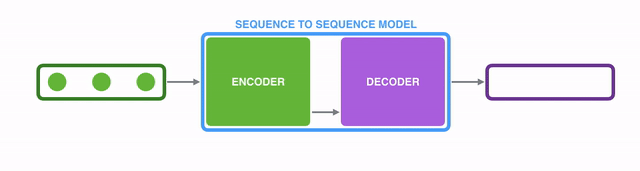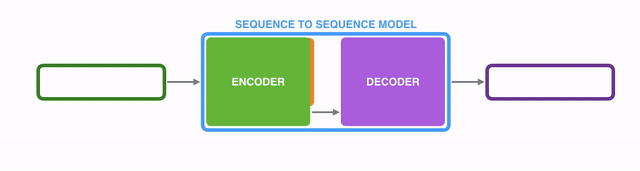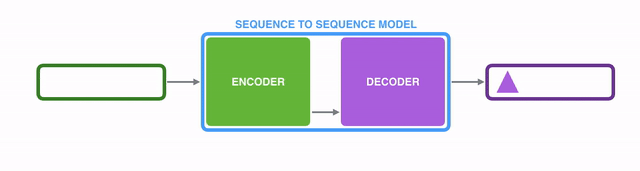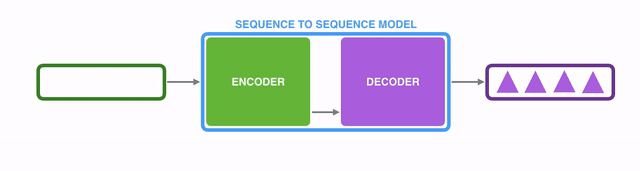
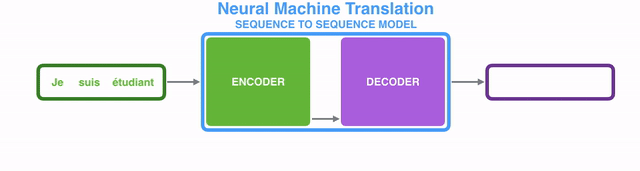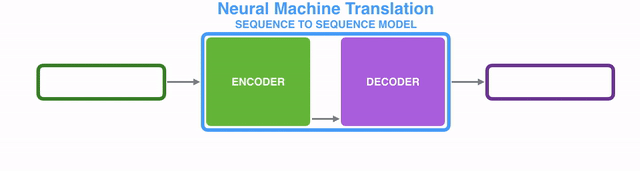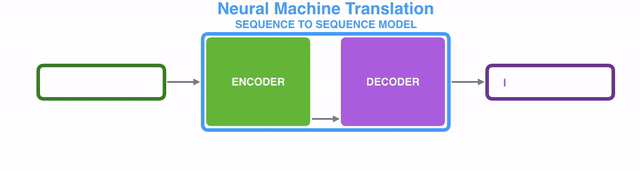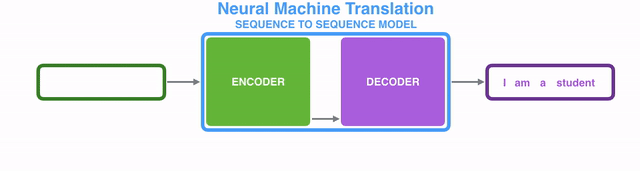
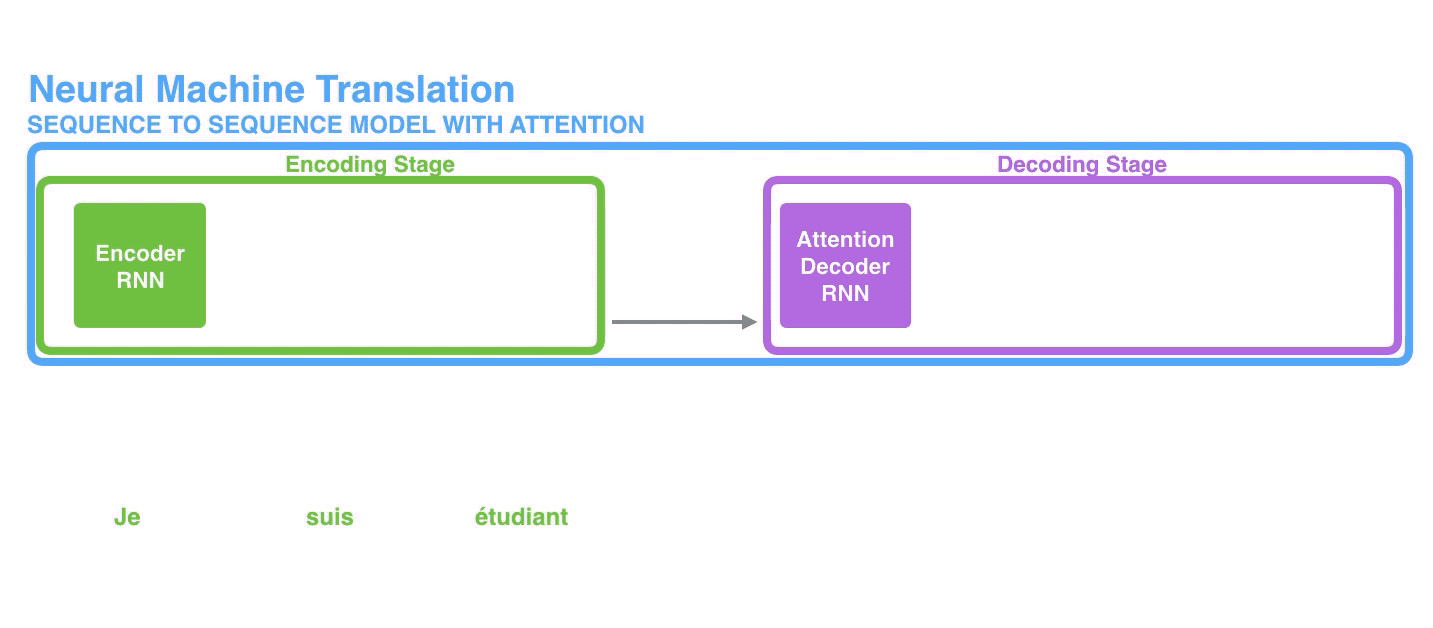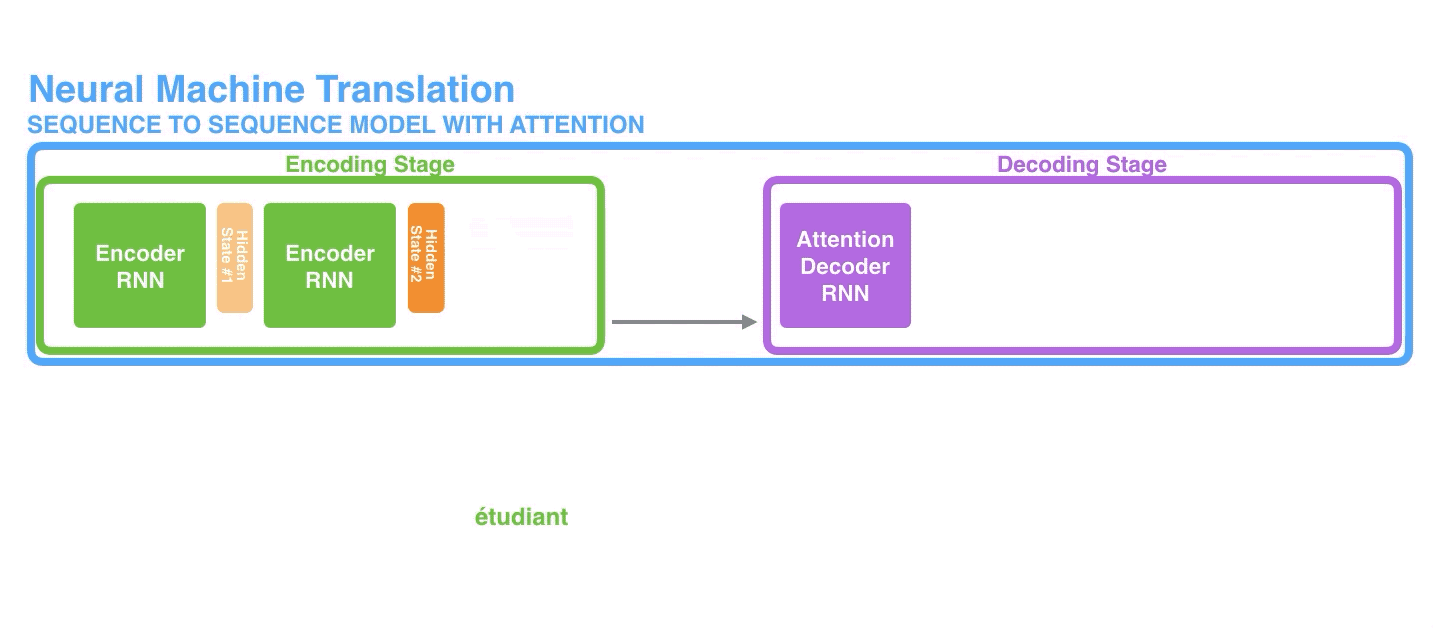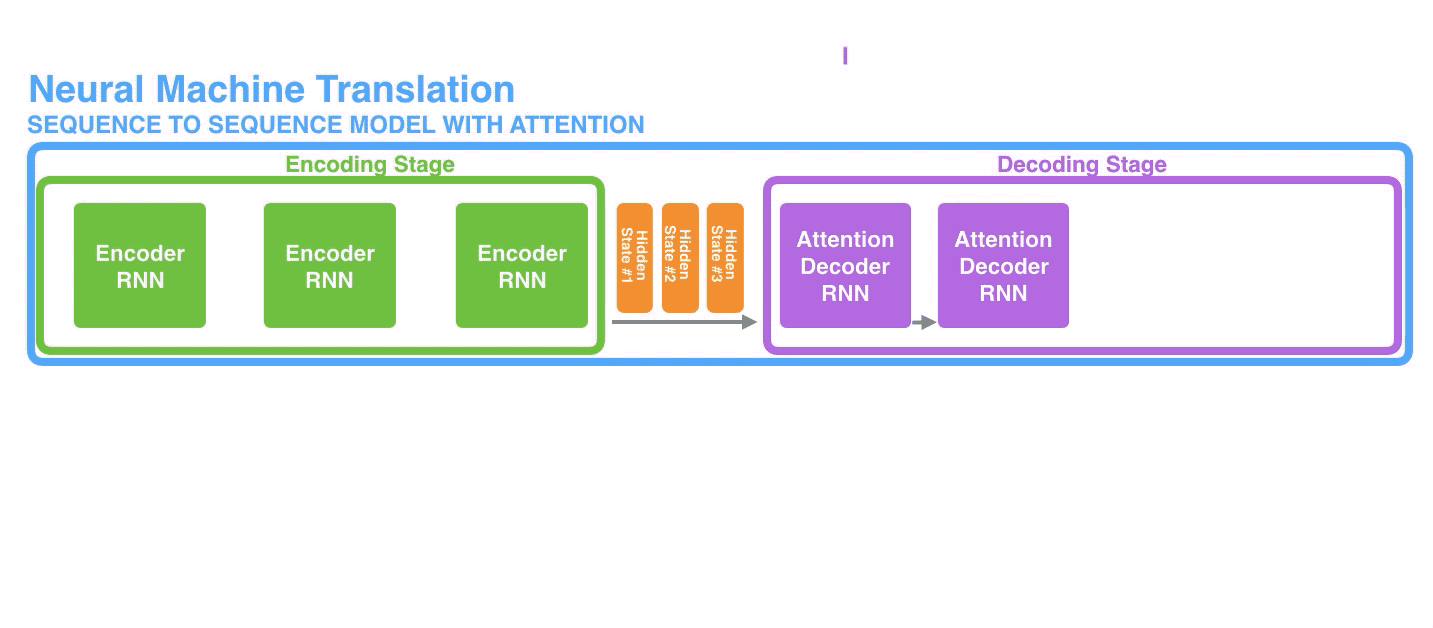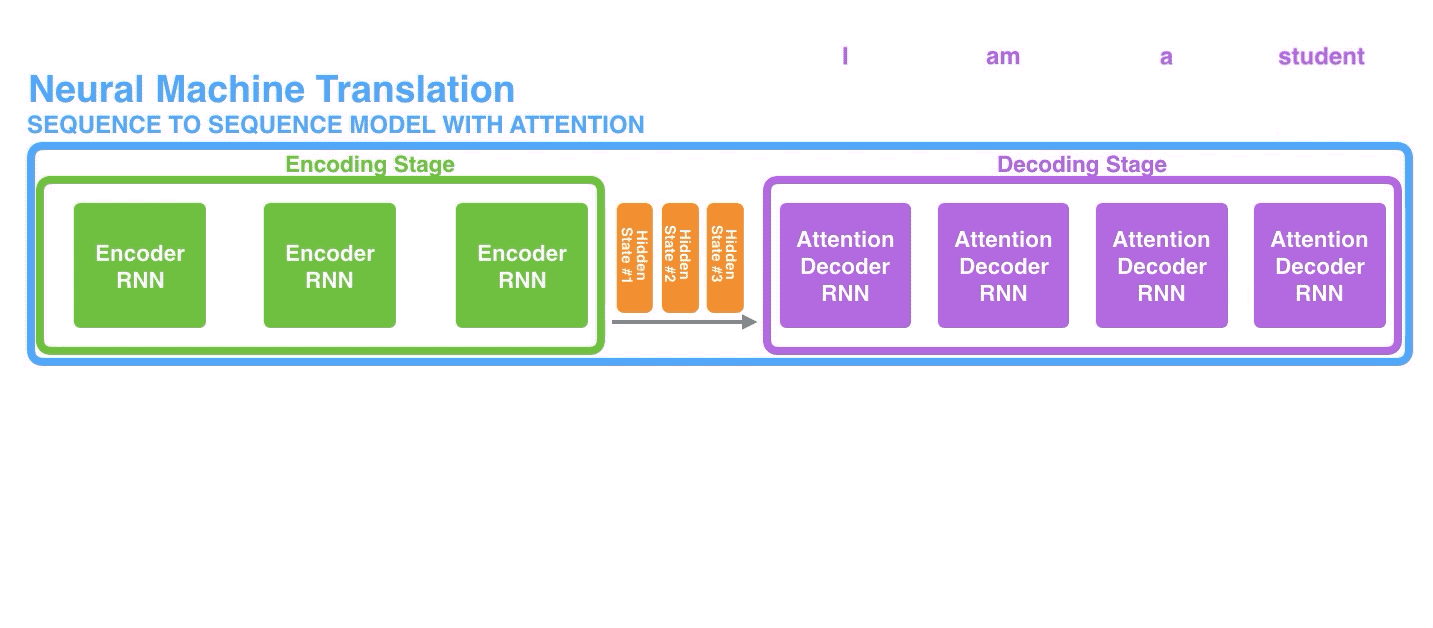
一个典型的Seq2Seq模型会接收一个item序列(其中item可以是单词、字母、特征甚至一幅图像等),然后输出另一个item序列。一个训练好的模型如下图所示:

具体到神经机器翻译NMT(Neural Machine Translation)场景的话,就是将一个(由一系列单词组成的)序列输入到模型中,一个接一个地处理这些单词后,同样输出另一个(由一系列单词组成的)序列:

那么在模型内部都发生了什么呢?
Seq2Seq2模型的内部,是由一个编码器(encoder)和一个解码器(decoder)组成的。
编码器(encoder)逐个处理输入序列中的每个item,并将从其中获取到的信息编译到一个被称为context的vector中;而当整个输入序列都处理完成后,编码器(encoder)就将context发送给解码器(decoder),解码器(decoder)开始逐个item地生成输出序列的内容。【译注:后面翻译中编码器和解码器直接用汉字,不再跟英文了哈。】
类似地,在神经机器翻译NMT的场景下:
在上述机器翻译的例子中,context是一个矢量vector(即一个由数字组成的数组)。编码器和解码器都是循环神经网络(RNN)。

此处context是一个实数矢量。(接下来的博文里,我们会对context中的数字
赋予不同亮度的颜色,即实数值越大颜色越亮,否则越暗)
在创建模型时,context矢量的尺寸可以任意指定。一般情况下,其等同于编码器RNN中隐藏单元的数量。上图中的conext矢量的尺寸是4,但真实应用场景中的尺寸一般是256、512或1024。
按照设计,RNN在每个时间步长(time step)上有两个输入:一个正常的输入(在编码器的例子中,就是输入句子的每个单词)和一个隐藏状态。这里提到的单词需要表示成矢量,将单词转换为矢量的方法称为词嵌入(Word Embedding)算法。这种将单词映射到矢量空间的过程会捕获单词中很多语义级别的信息(例如一个典型的例子:king - man + woman = queen)。
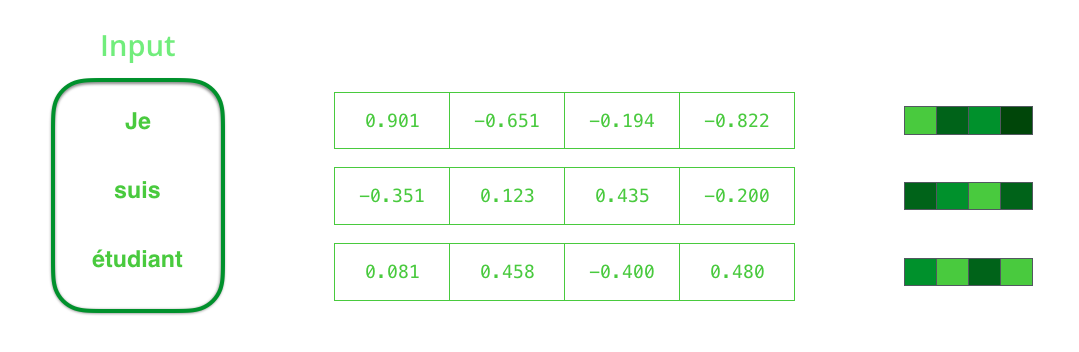
在继续处理单词前,需要先通过词嵌入算法将单词转换为矢量(即词向量)。
获取词向量有很多途径:既可以使用别人预训练好的词向量,也可以在自己的数据集上训练出自己的词向量。
典型的词向量的长度一般是200或300。此处为了演示简便,我们使用了一个长度为4的词向量。
我们已经介绍完了主要的矢量及张量,接下来我们回顾一下RNN的运行机制,并用可视化的方式来描述RNN模型。
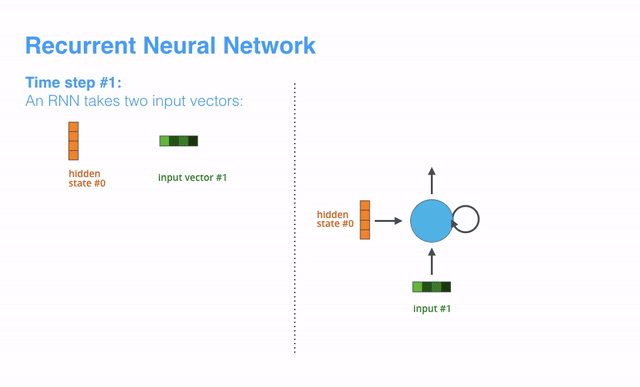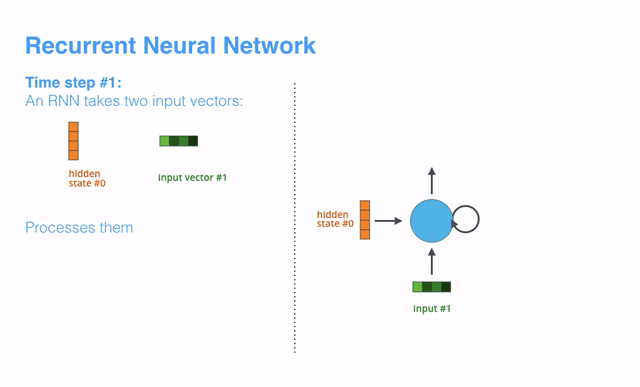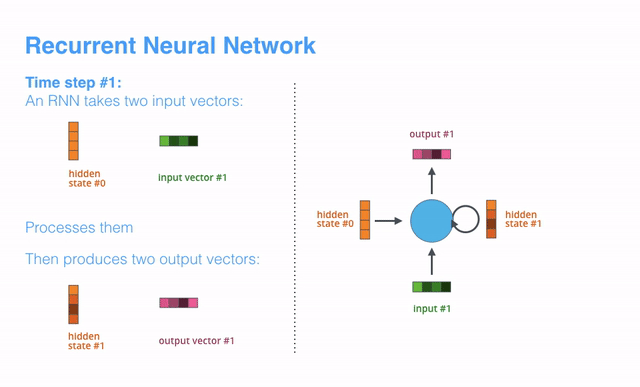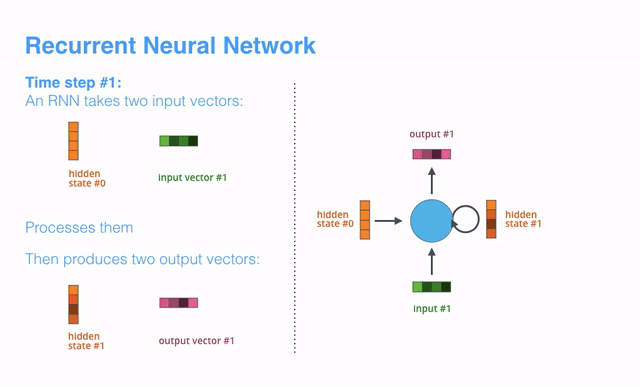
RNN的运作机理是:在每一个时间步长(time step)中,RNN同时获取当前的输入矢量(input vector)和“通过上一步计算产出的”隐藏状态(hidden state),进而生成当前时间步长的输出矢量(output vecotr)。在后面的博文中,我们也将使用一个类似的动画来描述矢量在NMT模型中的运作机理。
下面的动画中,编码器或解码器的每一次解析,都表示RNN在对应的时间步长里接收了一个输入并生成了一个输出。因为编码器和解码器都是RNN,每个时间步长里,每个RNN都会做若干处理,其会根据当前输入和上一个可见的输入来更新隐藏状态。
来具体看下编码器中的隐藏状态的处理过程,注意最后一个隐藏状态实际就是要传递给解码器的那个context。
同样地,解码器在每个时间步长中都会维护一个隐藏状态(我们先关注模型的主要部分,所以上图中没有显示出解码器的隐藏状态的处理过程)
让我们用另一种方式来观察Seq2Seq模型,下面这个动画可以更容易地理解和描述这些模型。我称之为“展开视图”,其并不直接显示一个解码器,而是在每个时间步长显示它的一个副本(就是把每个时间步长中的RNN及其处理过程都叠加到同一个画面里)。通过这种方法我们可以看到每个时间步长里的输入和输出过程。
接下来让我们聚焦于注意力机制(Attention)
在上述模型中,context成了一个瓶颈,其给模型处理长句子的过程中带来了巨大的挑战。 对于这个问题,有两篇论文(Bahdanau et al., 2014 和 Luong et al., 2015 )给出了可行的一个解决方案,这些论文中提出并完善了一项称之为注意力(attention)的技术,其极大地提升了机器翻译系统的运行效果。注意力机制允许模型根据需要来关注输入序列的相应部分。
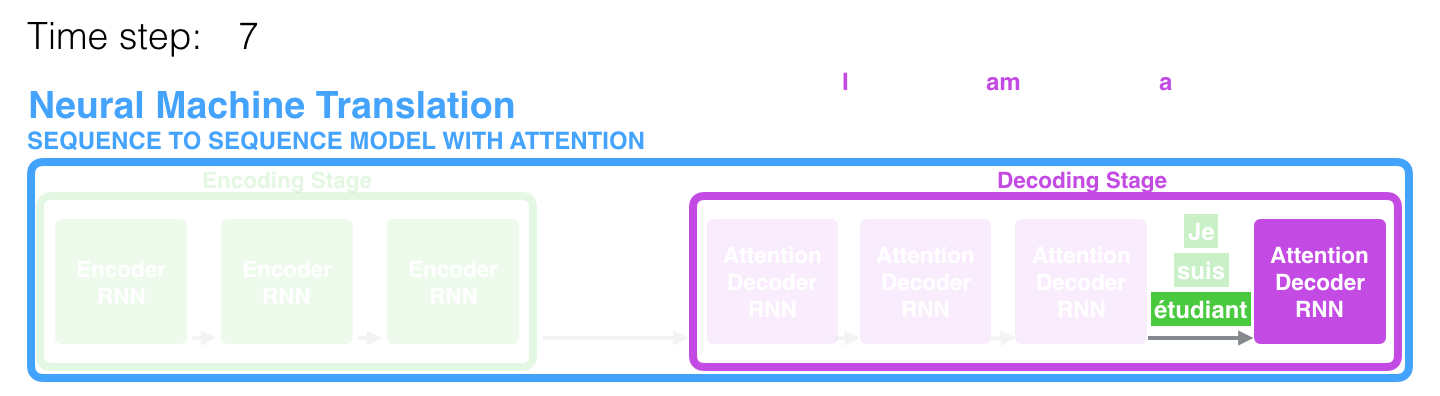
在第7步(即第7个时间步长)中,注意力机制使解码器在生成英语翻译结果之前,先聚焦于单词"étudiant" (法语中的“学生”)。
这种“放大来自输入序列相关部分的信号的”能力使得有注意力机制的模型比没有注意力机制的模型产生更好的结果。
让我们继续从高度抽象的层次上研究注意力模型, 注意力模型与传统的Seq2Seq模型相比,主要有两点不同:
首先,编码器传递给解码器的数据变多了。编码器不再只传递编码阶段最后一个隐藏状态给解码器,而是将编码阶段的所有隐藏状态全都传递给解码器。
其次,带注意力的解码器在生成输入序列之前,会多做一些额外的操作。具体来说,为了将焦点聚集到输入序列中“和当前解码时间步长相应的”的那个部分上,解码器做了如下事情:
1. 观察编码器产出的隐藏状态集合,每个隐藏状态都与输入序列中某个特定单词有着最大的关联性。
2. 为每个隐藏状态打分(具体打分方法此处先不解释)
3. 将每个隐藏状态与其对应的经过归一化(softmaxed)处理的打分相乘,使得分高的隐藏状态突出放大,得分低的隐藏状态被弱化掩盖。

上述这一系列的打分/计算等操作,是在解码器处理阶段的每一个时间步长里都会进行的。
现在让我们把所有环节整合到一起,看看注意力机制是如何工作的。
1. 带有注意力机制的解码器RNN,接收到两个东西:(1) 表示编码结束的特定词向量令牌(即<END>令牌),和(2) 一个经过初始化的解码器隐藏状态;
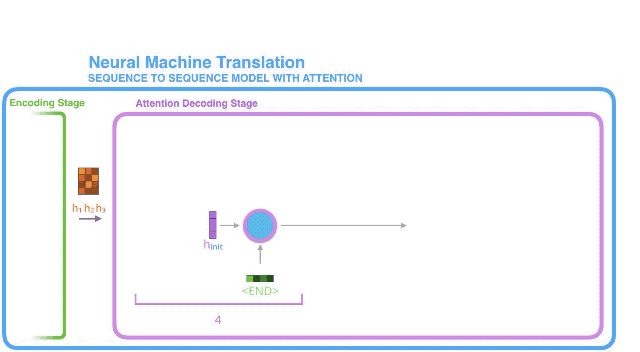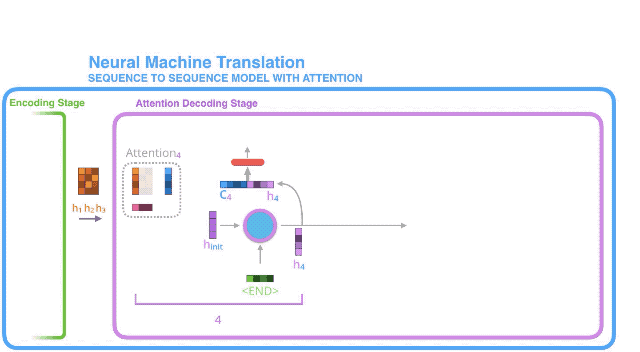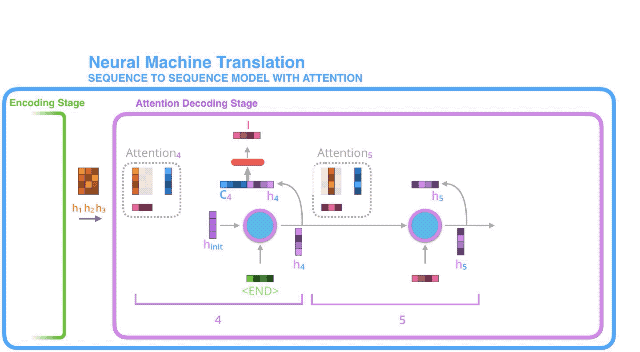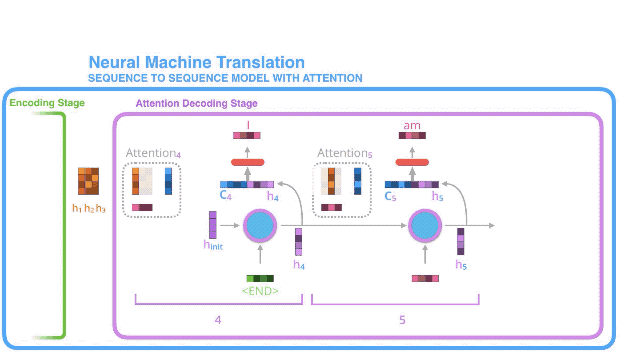
2. 解码器RNN处理上述输入,生成一个输出和一个新的隐藏状态向量(h4),注意这里的输出会被丢弃掉不用。
3. 注意力生效步骤:使用编码器隐藏状态,和上述隐藏状态向量(h4),计算出当前时间步长的context向量(C4);
4. 将h4和C4拼接成一个向量;
5. 将上述向量放到一个与模型共同训练的前馈神经网络中;
6. 前馈神经网络的产出就是当前时间步长生成的输出单词;
7. 继续下一个时间步长的操作;
下面是另一种方式来观察:在每个解码步骤中,我们将注意力集中在输入句子的哪个部分上:

需要注意的是,模型并不只是盲目地将输出中的第一个单词与输入中的第一个单词对齐,它实际上从培训阶段学会了如何排列语言对中的单词(本例中是法语和英语),上面列举的论文中有一个展示这种注意力机制的准确性的例子:

可以看出该模型在输出“European Economic”(欧洲经济区)这个词组时,是如何将注意力正确地聚焦的。
在法语中,“欧洲经济区”这个词组的词序相对英语来说是相反的("zone économique européenne"),而该句子中其他单词的顺序在两种语言中都差不多。
(译注:即模型在一个大部分单词顺序相同的句子翻译任务中,准确地发现了其中需要调整单词顺序的部分!)
如果你觉得已经准备好学习其具体实现,一定要来看看Seq2Seq的tensorflow版本的教程:Neural Machine Translation (seq2seq) Tutorial.
【转载 | 翻译】Visualizing A Neural Machine Translation Model(神经机器翻译模型NMT的可视化)的更多相关文章
- 课程五(Sequence Models),第三周(Sequence models & Attention mechanism) —— 1.Programming assignments:Neural Machine Translation with Attention
Neural Machine Translation Welcome to your first programming assignment for this week! You will buil ...
- Sequence Models Week 3 Neural Machine Translation
Neural Machine Translation Welcome to your first programming assignment for this week! You will buil ...
- 神经机器翻译 - NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE 综述 背景及问题 背景: 翻译: 翻译模型学习条件分布 ...
- 对Neural Machine Translation by Jointly Learning to Align and Translate论文的详解
读论文 Neural Machine Translation by Jointly Learning to Align and Translate 这个论文是在NLP中第一个使用attention机制 ...
- Effective Approaches to Attention-based Neural Machine Translation(Global和Local attention)
这篇论文主要是提出了Global attention 和 Local attention 这个论文有一个译文,不过我没细看 Effective Approaches to Attention-base ...
- On Using Very Large Target Vocabulary for Neural Machine Translation Candidate Sampling Sampled Softmax
[softmax分类器的加速器] https://www.tensorflow.org/api_docs/python/tf/nn/sampled_softmax_loss This is a fas ...
- [笔记] encoder-decoder NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
原文地址 :[1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate (arxiv.org) ...
- Introduction to Neural Machine Translation - part 1
The Noise Channel Model \(p(e)\): the language Model \(p(f|e)\): the translation model where, \(e\): ...
- 论文阅读 | Robust Neural Machine Translation with Doubly Adversarial Inputs
(1)用对抗性的源实例攻击翻译模型; (2)使用对抗性目标输入来保护翻译模型,提高其对对抗性源输入的鲁棒性. 生成对抗输入:基于梯度 (平均损失) -> AdvGen 我们的工作处理由白盒N ...
随机推荐
- centos下Linux C语言MD5的使用
在Linux C变成中用到MD5加密会使用到openssl库,下面给出的是一个简单的小Demo: #include <stdio.h> #include <openssl/md5.h ...
- Join的7中情况
一.左外连接 SELECT * FROM A LEFT JOIN B ON A.KEY = B.KEY 二.右外连接 SELECT * FROM A RIGHT JOIN B ON A.KEY = B ...
- ac自动机(tree+kmp模板)
Keywords Search Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others ...
- C#设计模式:桥接模式(Bridge Pattern)
一,桥接模式,直接上代码 using System; using System.Collections.Generic; using System.Linq; using System.Text; u ...
- 使用git、git-flow与gitlab工作
使用git.git-flow与gitlab工作 1. 摘要 在工作中使用git代替svn也有一段时间了,对于git的一些特性喜爱的同时也一直遇到相同的问题:“这时候应该打什么命令?”.相对于svn或者 ...
- idea 2019.1.3最新注册码
CATF44LT7C-eyJsaWNlbnNlSWQiOiJDQVRGNDRMVDdDIiwibGljZW5zZWVOYW1lIjoiVmxhZGlzbGF2IEtvdmFsZW5rbyIsImFzc ...
- 【LeetCode】栈 stack(共40题)
[20]Valid Parentheses (2018年11月28日,复习, ko) 给了一个字符串判断是不是合法的括号配对. 题解:直接stack class Solution { public: ...
- gcc开启C99或C11标准支持
开启C99支持 gcc -std=c99 forc99.c 开启C11支持 gcc -std=c1x forc11.c 或 gcc -std=c11 forc11.c
- grep正则表达式(一)
新建一批 txt 文件: [me@linuxbox ~]$ ls /bin > dirlist-bin.txt [me@linuxbox ~]$ ls /usr/bin > dirlist ...
- Redis Redis-Cell
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11632679.html 漏斗限流 漏斗限流是最常用的限流方法之一,另一个是令牌桶(比如:Guava R ...