Hadoop基础概念
Apache Hadoop有2个核心的组件,他们分别是:
HDFS: HDFS是一个分布式文件系统集群,它可以将大的文件分裂成块并将他们冗余地分布在多个节点上,HDFS是运行在用户空间的文件系统
MapReduce: MapReduce是函数式编程领域分布式计算中的一个编程模型,这个模型是专门用于查询/处理存储在HDFS中的大量数据
HDFS
NameNode
namenode将整个源数据维护在内存中,这有助于客户端接收快速响应读取请求。因此运行namenode的机器需要很大的内存。文件的数量越多,内存消耗的越多
namenode也维护存储在磁盘上的持久元数据,称为 fsimage
当在集群中 placed/deleted/updated文件时,这些操作会在edits文件中更新,更新edits日志后,在内存中的元数据也相应更新
每次写入操作都不会更新fsimage
重启namenode会发生以下事件:
- 从磁盘读取fsimage文件加载到内存中
- 读取edits日志文件中的每个操作,并把这些操作在内存中应用到fsimage
- 把fsimage持久化到磁盘
Secondary namenode
因为fsimage文件并不会更新每次操作,而edits 日志文件可能会变得非常大,当namenode需要重启的时候,edits日志文件需要合并到fsimage,这会使得重启变得非常慢,而secondary namenode可以解决这个问题
secondary namenode负责定期执行合并来自namenode的edits日志文件和fileimage
如果namenode进程失败,可以利用secondary namenode合并的数据重建文件系统元数据,因为secondary namenode是定时 checkpoint数据,因此会存在一些数据丢失的情况
注意:secondary namenode并不是故障转移节点
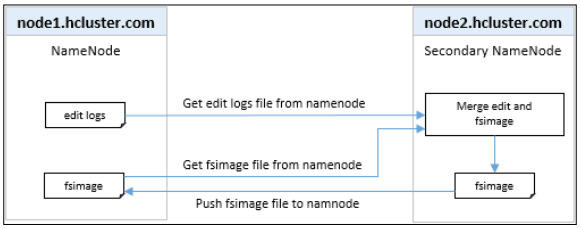
- 从namenode获取edits日志文件
- 从namenode获取 fsimage文件
- 将eidts日志中的所有操作应用到fsimage中
- 把fsimage推送到namenode
上面的操作是周期性的执行,因此无论何时重启namenode,它都会有一个相对较新的fsimage,这样启动时间就会快很多
DataNode
datanode是负载存储实际文件的节点,这些文件作为数据块在集群中进行分割,通常是128MB大小的块,块的大小是可以配置的。Hadoop集群中文件块还会将自己复制到其他的datanode冗余,以便在datanode进程失败的时候不会丢失数据,datanode向namenode发送存储在该节点的文件块的信息,并响应所有的namenode文件系统的操作
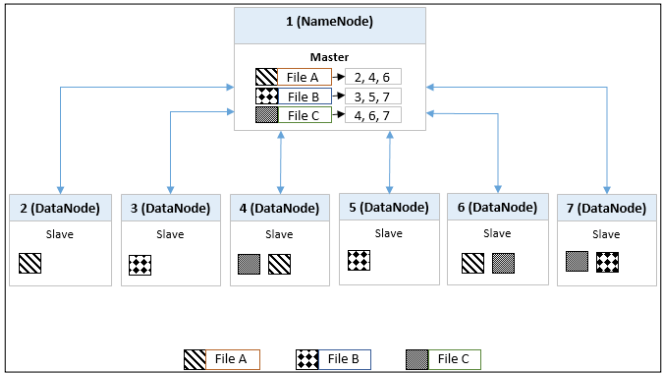
上图示例,文件A、B和C文件块被复制到集群多个节点上冗余,这确保了即使其中一个节点故障,数据仍然可用。这个集群的复制因子为3,表示文件文件块被复制了3次。namenode维护文件在集群中的位置列表,当有客户端需要访问一个文件,namenode会向客户端提供文件在哪个数据节点上,然后客户端会直接从数据节点访问文件
YARN
YARN是在Hadoop集群中处理数据的一个通用的分布式应用程序管理框架, YARN解决了一下两个重要问题:
- 支持大的集群(4000+节点)
- 能够运行MapReduce之外的其他应用程序已经存储在HDFS中的数据,例如MPI和Apache Giraph
YARN 资源管理框架包括 ResourceManager(资源管理器)、Applica-tionMaster、NodeManager(节点管理器)。各个组件描述如下
(1)ResourceManager
ResourceManager 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(ApplicationManager,AM)。
Scheduler 负责分配最少但满足 Application 运行所需的资源量给 Application。Scheduler 只是基于资源的使用情况进行调度,并不负责监视/跟踪 Application 的状态,当然也不会处理失败的 Task。
ApplicationManager 负责处理客户端提交的 Job 以及协商第一个 Container 以供 App-licationMaster 运行,并且在 ApplicationMaster 失败的时候会重新启动 ApplicationMaster(YARN 中使用 Resource Container 概念来管理集群的资源,Resource Container 是资源的抽象,每个 Container 包括一定的内存、IO、网络等资源)。
(2)ApplicationMaster
ApplicatonMaster 是一个框架特殊的库,每个 Application 有一个 ApplicationMaster,主要管理和监控部署在 YARN 集群上的各种应用。
(3)NodeManager
主要负责启动 ResourceManager 分配给 ApplicationMaster 的 Container,并且会监视 Container 的运行情况。在启动 Container 的时候,NodeManager 会设置一些必要的环境变量以及相关文件;当所有准备工作做好后,才会启动该 Container。启动后,NodeManager 会周期性地监视该 Container 运行占用的资源情况,若是超过了该 Container 所声明的资源量,则会 kill 掉该 Container 所代表的进程。
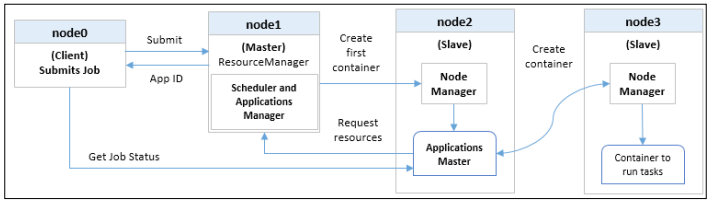
提交作业给YARN一系列步骤
- 当作业提交的集群,Client第一个接收到来自ResourceManager的应用程序ID
- 接下来,Client将作业资源复制到HDFS中的一个位置
- 然后,ResourceManager启动第一个容器NodeManager管理调出ApplicationMaster
- ApplicationMaster基于要执行的作业,请求资源来自ResourceManager
- 一旦ResourceManager调度具有请求的容器资源,ApplicationMaster联系NodeManager启动容器并执行任务。 在MapReduce作业的情况下,该任务将是一个map或reduce任务。
- 客户端检查ApplicationMaster以获取状态更新提交的工作
The read/write operational flow in HDFS
为了更好的理解HDFS,我们需要知道 HDFS是如何进行以下操作的
- A file is written to HDFS
- A file is read from HDFS
HDFS uses a single-write, multiple-read model, where the files are writtern once and read several time.The data cannot be altered once written. However, data can be appended to the file by reopening it(只能追加,不能修改).All files in the HDFS are saved as data blocks.
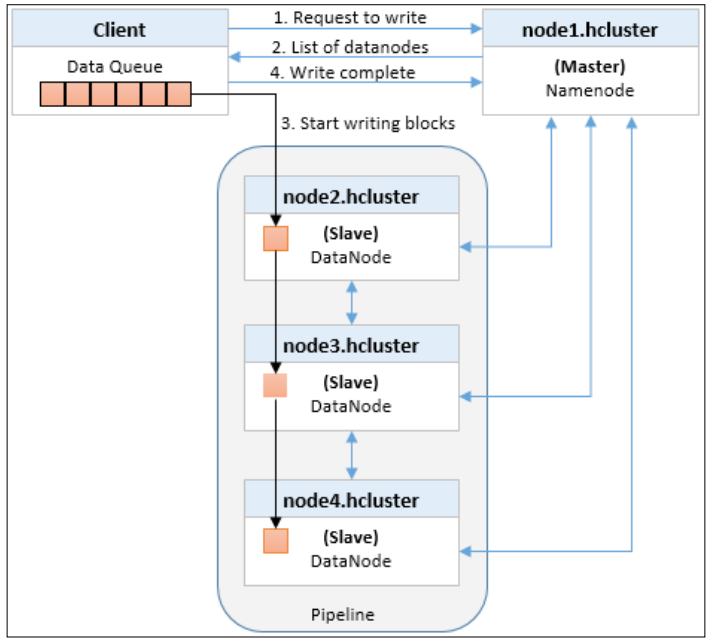
Writing files in HDFS
- client 告知namenode它想要write a file, namenode检查该文件是否已经存在
- 如果存在,将会返回一个消息给client,如果不存在,namenode会给这个新文件创建一个metadata(元数据)
- client会将文件分成数据包并建立数据队列,然后将队列中的数据包以流的形式发送给集群中的datanode
- namenode维护了datanode信息列表,并且配置好了数据副本因子,namenode 提供datanode构建管道执行写入
- 然后将来自数据队列中的第一个数据包传输到第一个datanode,第一个datanode存储了该数据block,然后复制给管道的下一个datanode,这个过程将一直持续到数据包被写入最后一个datanode
- 每一个写在databode上的数据包,会进行确认发送给client
- 如果数据包无法写入其中一个datanode,那么该datanode会从管道中 删除,并且把其余的数据包写入到正常的datanode. namenode意识到副本数不足,会安排另一个datanode进行复制
- 写入所有数据包后,client执行关闭操作,指示数据队列中的数据包已完全传输
- client通知namenode写操作已经完成了
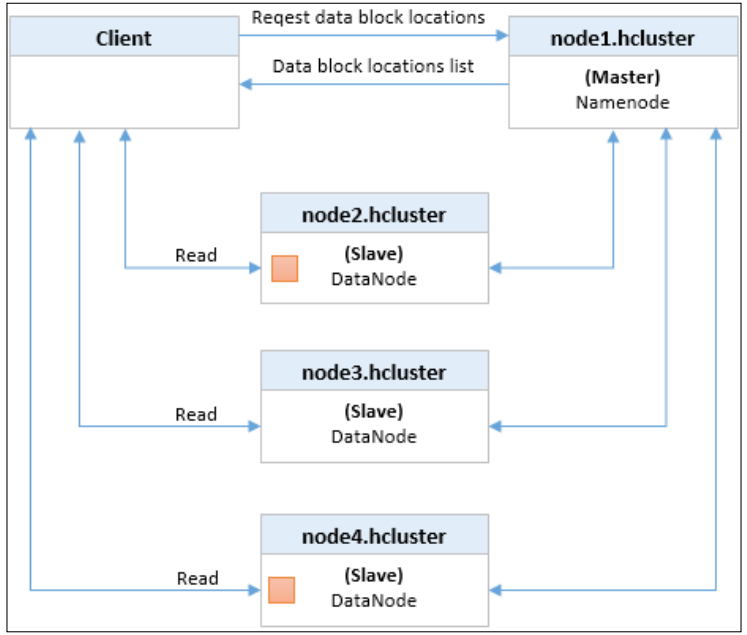
Reading files in HDFS
- client连接namenode获取要读取的文件数据块的位置
- namenode返回数据块所在datanode地址列表
- 对于任何读取操作,HDFS会尝试使用datanode网络最接近client的数据返回
- client有了列表后,就会连接datanode然后以流式进行读取数据块
- 在一个datanode读取完块后,终止该datanode连接并与承载序列中下一个块的datanode进行数据块传输。这个过程将持续到该文件的最后一个块被读取完
Hadoop基础概念的更多相关文章
- Hadoop基础概念介绍
基于YARN的配置信息, 参见: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ hadoop入门 - 基础概念 ...
- hadoop分布式存储(1)-hadoop基础概念(毕业设计)
hadoop是一种用于海量数据存储.管理.分析的分布式系统.需要hadoop需要储备一定的基础知识:1.掌握一定的linux操作命令 2.会java编程.因此hadoop必须安装在有jdk的linux ...
- hadoop分布式存储(1)-hadoop基础概念
hadoop是一种用于海量数据存储.管理.分析的分布式系统.需要hadoop需要储备一定的基础知识:1.掌握一定的linux操作命令 2.会java编程.因此hadoop必须安装在有jdk的linux ...
- 大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法 1.概念介绍 Hadoop是Apache旗下的一个项目.他由HDFS.MapReduce.Hive.HBase和ZooKeeper等成员组成. HDFS是一个高度容 ...
- Hadoop 新生报道(三) hadoop基础概念
一.NameNode,SeconderyNamenode,DataNode NameNode,DataNode,SeconderyNamenode都是进程,运行在节点上. 1.NameNode:had ...
- Hadoop 基础概念
Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰富,包括ZooKe ...
- hadoop基础教程免费分享
提起Hadoop相信大家还是很陌生的,但大数据呢?大数据可是红遍每一个角落,大数据的到来为我们社会带来三方面变革:思维变革.商业变革.管理变革,各行业将大数据纳入企业日常配置已成必然之势.阿里巴巴创办 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
随机推荐
- Java面试题收集(二)
四.Redis简介 redis为什么这么快 4.1 Redis数据类型 String hash 字典,适用于存储对象 list 安照String元素插入顺序排序,最新插入的最先显示.如热点数据 set ...
- 前端MVC、MVVM的简单实现
MVC MVC是一种设计模式,它将应用划分为3个部分:数据(模型).展示层(视图)和用户交互层.结合一下下图,更能理解三者之间的关系.换句话说,一个事件的发生是这样的过程 用户和应用交互 控制器的事件 ...
- C++入门经典-例6.13-指针与二维数组
1:代码如下: // 6.13.cpp : 定义控制台应用程序的入口点. // #include"stdafx.h" #include<iostream> using ...
- 设置iterm可配色
设置终端和ls可配色 终端输入vim ~/.bash_profile 添加如下export #enables colorin the terminal bash shell export export ...
- spring的IOC——依赖注入的两种实现类型
一.构造器注入: 构造器注入,即通过构造函数完成依赖关系的设定.我们看一下spring的配置文件: <constructor-arg ref="userDao4Oracle" ...
- 七、smarty--缓存的控制
1.建议缓存 $smarty->cacheing = true; //设置为2是给每一个模板设置缓存 $smarty->setCacheDir(“”); 2.处理缓存的生命周期 $smar ...
- Fiddlercore拦截并修改HTTPS链接的网页,实现JS注入
原始出处:https://www.cnblogs.com/Charltsing/p/FiddlerCoreHTTPS.html Fiddlercore可以拦截和修改http的网页内容,代码在百度很多. ...
- emqtt emq 的主题访问控制 acl.conf
访问控制(ACL) EMQ 消息服务器通过 ACL(Access Control List) 实现 MQTT 客户端访问控制. ACL 访问控制规则定义: 允许(Allow)|拒绝(Deny) 谁(W ...
- 使用 Supervsior 守护进程
概述 一般来说,在终端开启的服务,如果退出终端的话,就会自动关闭服务.这个时候需要守护这个服务的进程. Supervisor 是一个用 Python 写的进程管理工具,可以很方便的用在 UNIX-li ...
- JavaWeb实现文件上传下载功能实例解析 (好用)
转: JavaWeb实现文件上传下载功能实例解析 转:http://www.cnblogs.com/xdp-gacl/p/4200090.html JavaWeb实现文件上传下载功能实例解析 在Web ...