PyQuery爬取历史天气信息
1.准备工作:
网址:https://lishi.tianqi.com/xian/index.html
爬虫类库:PyQuery,requests
2.网页分析:

红线部分可更改为需要爬取的城市名,如:beijing

红框选中部分即为我们所需要爬取的每个月份的信息. 目测应该是ui li,使用Chrome F12 查看下源代码
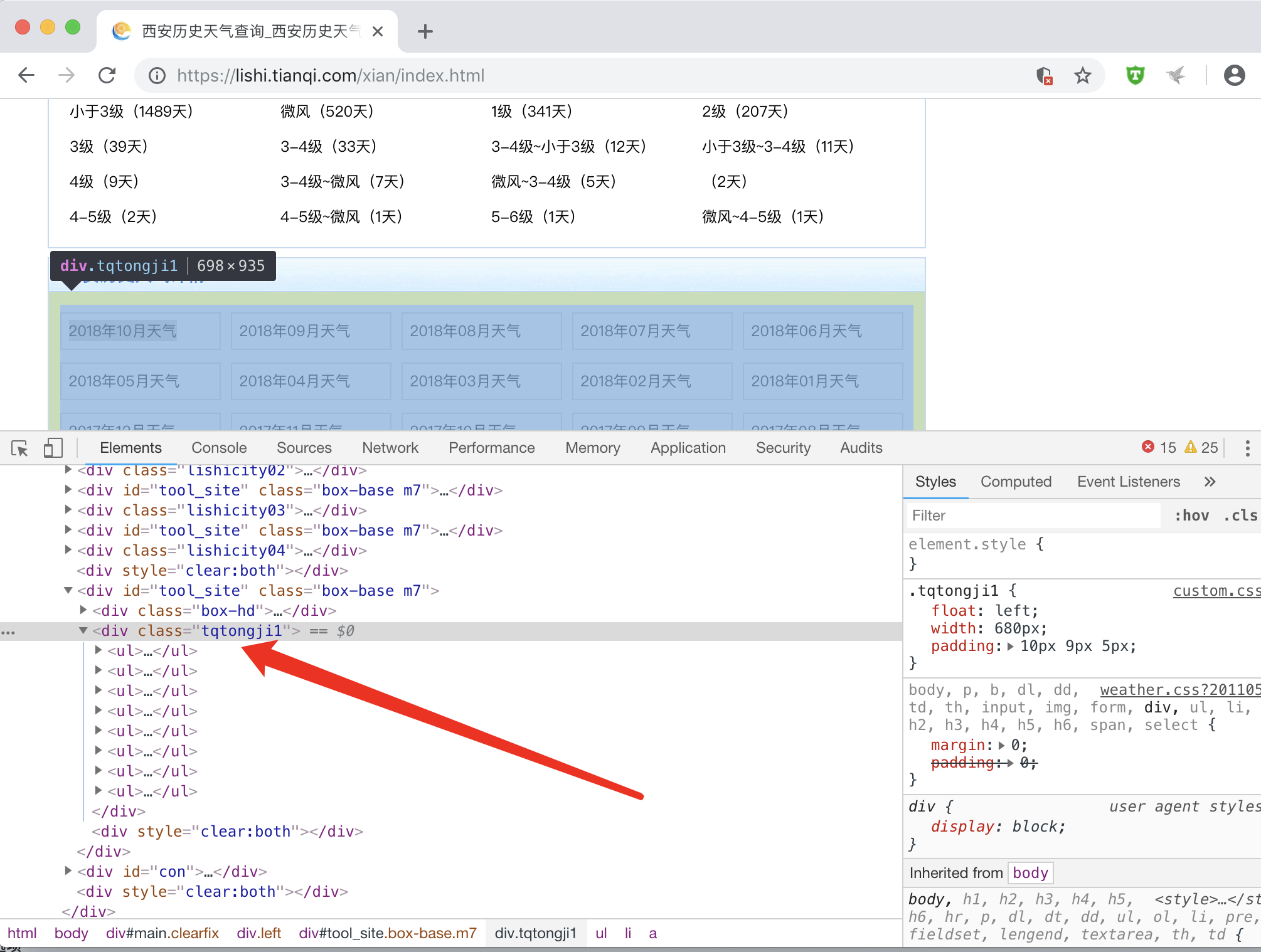
PyQuery的css 选择器可以起床了..
莫慌莫慌。在瞅瞅具体月份点击进入后的页面效果
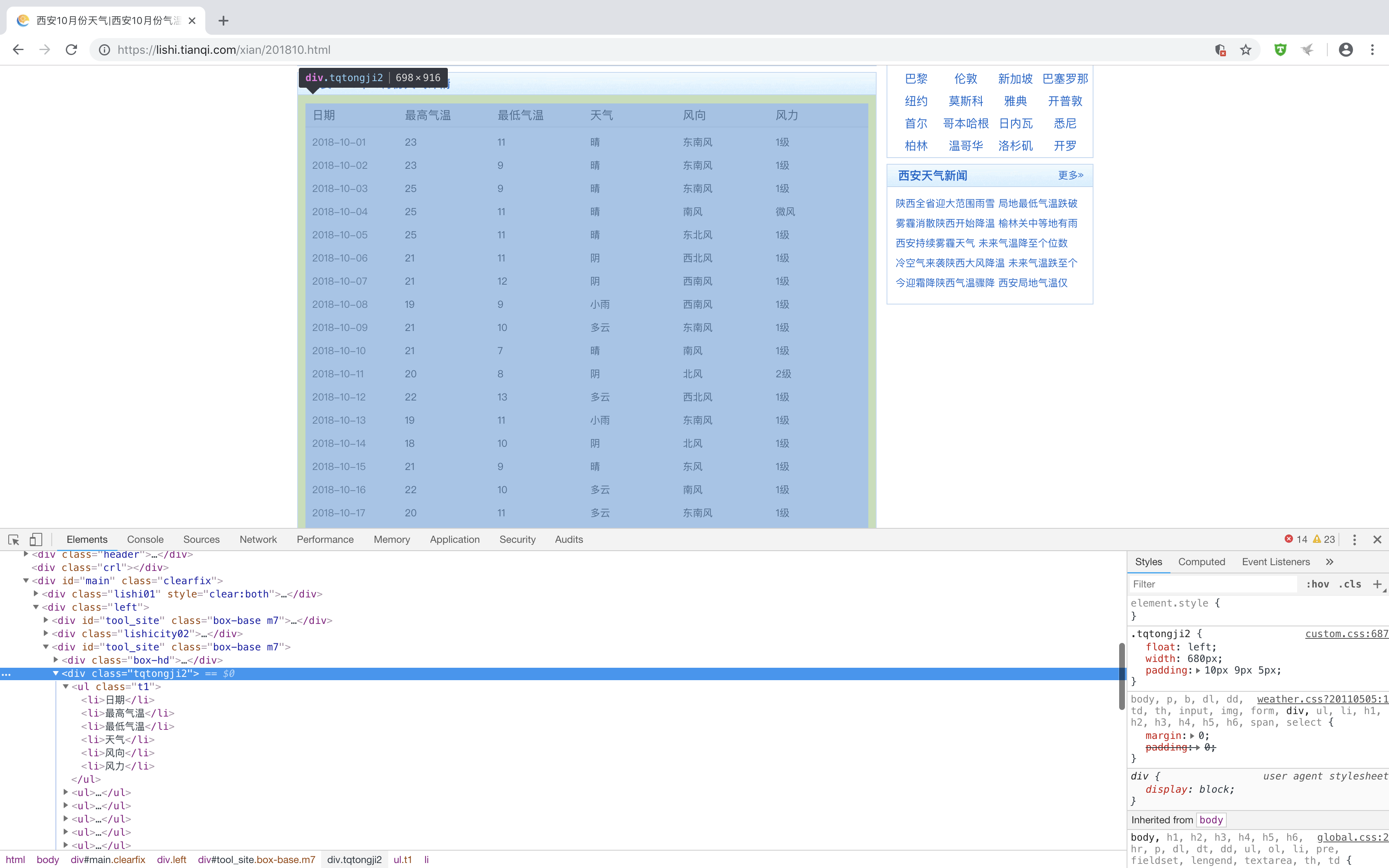
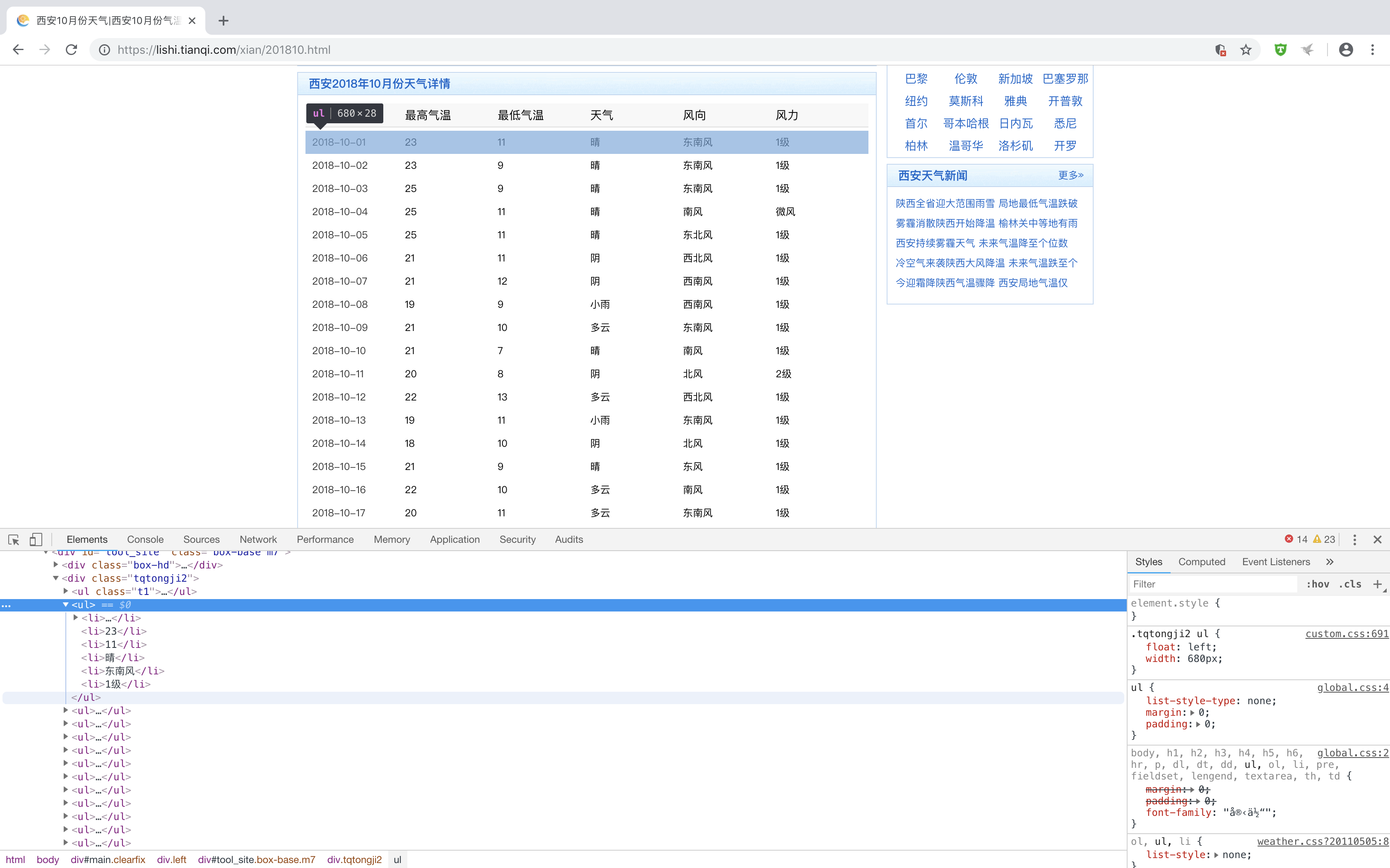
所有的具体每一天的天气信息都被包裹在ul li..
PyQuery.. 开工..
# 获取所有的月份的a标签连接。
def get_html():
links = []
url = 'https://lishi.tianqi.com/xian/index.html'
r1 = requests.get(url,headers)
html_doc = pq(r1.text)
ul = html_doc('.tqtongji1 > ul:nth-child(1)')
lis = ul('li').items()
for li in lis:
a = li('a')
links.append(a.attr('href'))
return links
# 获取详细页的具体天气信息
def get_detail(url):
r1 = requests.get(url,headers)
html_doc = pq(r1.text)
uls = html_doc('.tqtongji2').find('ul')
lis = uls.items('li')
list = []
l = '.'.join(li.text() for li in lis).split('.')
# 由于标题信息只有['日期', '最高气温', '最低气温', '天气', '风向', '风力']所以需要字符串截取
for i in range(len(l)):
if i%6 == 0:
temp = l[i:i+5]
list.append(temp)
return list
# 保存至weather.csv
def save_to_csv(data):
with open('weather.csv','a') as csv_file:
writer = csv.writer(csv_file)
for row in data:
writer.writerow(row)
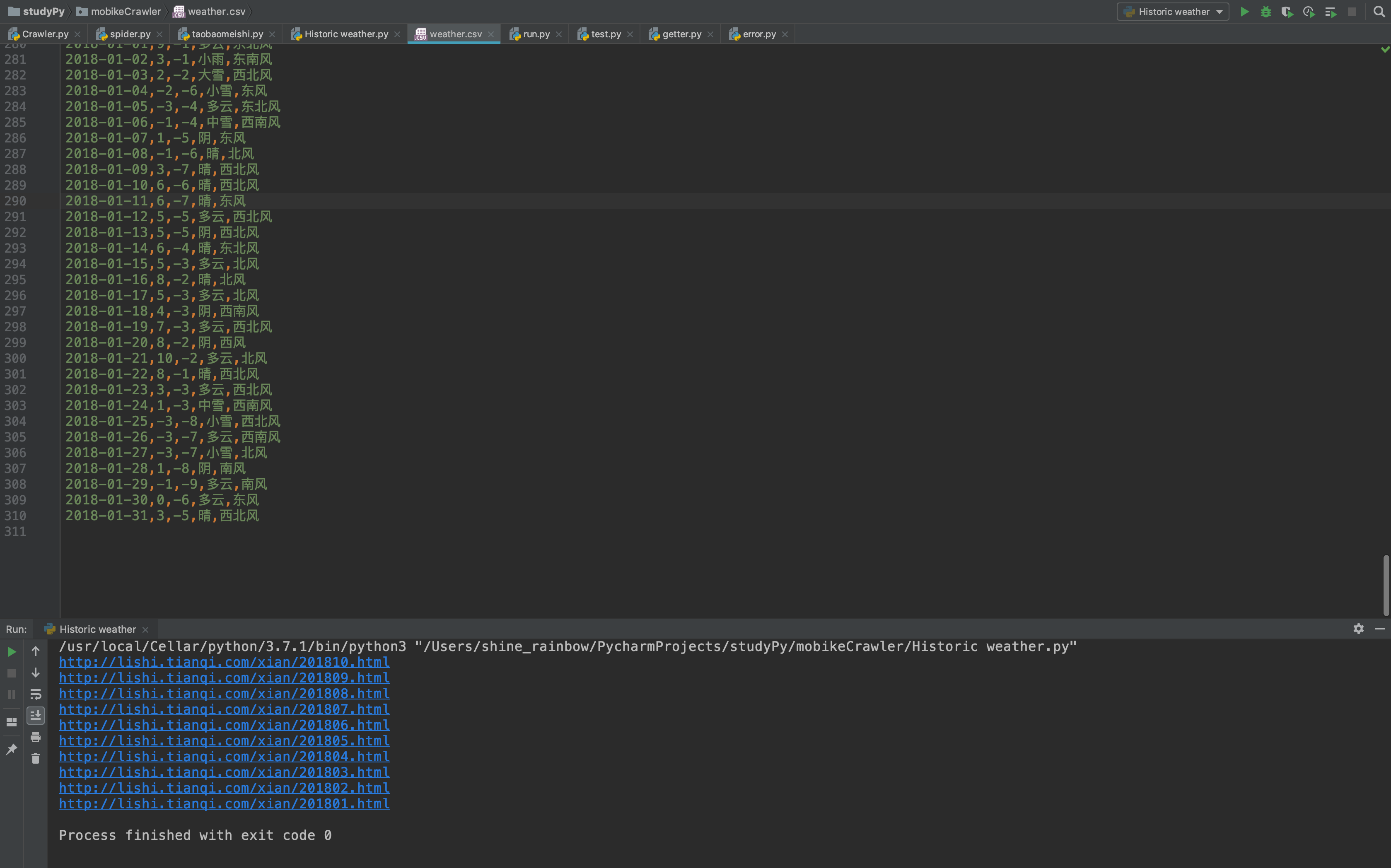
考虑到需要源代码的小伙伴, 已上传至github.. https://github.com/shinefairy/spider/
git clone https://github.com/shinefairy/spider
end~
PyQuery爬取历史天气信息的更多相关文章
- PHP爬取历史天气
PHP爬取历史天气 PHP作为宇宙第一语言,爬虫也是非常方便,这里爬取的是从天气网获得中国城市历史天气统计结果. 程序架构 main.php <?php include_once(". ...
- python 爬取历史天气
python 爬取历史天气 官网:http://lishi.tianqi.com/luozhuangqu/201802.html # encoding:utf-8 import requests fr ...
- Scrapy实战篇(五)之爬取历史天气数据
本篇文章我们以抓取历史天气数据为例,简单说明数据抓取的两种方式: 1.一般简单或者较小量的数据需求,我们以requests(selenum)+beautiful的方式抓取数据 2.当我们需要的数据量较 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
- python3爬取墨迹天气并发送给微信好友,附源码
需求: 1. 爬取墨迹天气的信息,包括温湿度.风速.紫外线.限号情况,生活tips等信息 2. 输入需要查询的城市,自动爬取相应信息 3. 链接微信,发送给指定好友 思路比较清晰,主要分两块,一是爬虫 ...
- 初识python 之 爬虫:爬取中国天气网数据
用到模块: 获取网页并解析:import requests,html5lib from bs4 import BeautifulSoup 使用pyecharts的Bar可视化工具"绘制图表& ...
随机推荐
- SVG绘制随机的柱形图+php
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- hash-散列笔记
散列基础与整数散列 散列(hash哈希)的基本思想--"将元素通过一个函数转换为整数,使该整数可以尽量唯一地代表这个元素".其中把这个转换函数称为散列函数H,元素在转换前为key, ...
- Git005--工作区和暂存区
Git--工作区和暂存区 本文来自于:https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b0 ...
- Learning OSG programing---osgAnimation(2)
osg::Node* createBase(const osg::Vec3& center,float radius) { ; ; *radius; *radius; osg::Vec3 v0 ...
- JNDI配置笔记
先在tomcat Context.xml配置文件中配置 <Resource name="jdbc/elifecrm" type="javax.sql.DataSou ...
- jmeter uniq 取值方式设置
- CodeChef Sereja and GCD
Sereja and GCD Problem code: SEAGCD Submit All Submissions All submissions for this problem ar ...
- thinkphp开发微信小程序后台流程
thinkphp开发微信小程序后台流程,简单分享一下微信开发流程 1,注册微信小程序账号 2,注册好后,登陆微信小程序,下载微信小程序开发工具 3,用thinkphp开发企业后台,前台数据用json返 ...
- L The Digits String(没有写完,有空补)
链接:https://ac.nowcoder.com/acm/contest/338/L来源:牛客网 Consider digits strings with length n, how many d ...
- 【转】通俗理解Java序列化与反序列化
一.序列化和反序列化的概念 把对象转换为字节序列的过程称为对象的序列化. 把字节序列恢复为对象的过程称为对象的反序列化. 对象的序列化主要有两种用途: 1) 把对象的字节序列永久地保存到硬盘上,通常存 ...