如何将DynamoDB的数据增量迁移到表格存储
Amazon DynamoDB是一个完全托管的NoSQL数据库服务,可以提供快速的、可预期的性能,并且可以实现无缝扩展。由于DynamoDB并可以根据实际需求对表进行扩展和收缩,这个过程既不需要停止对外服务,也不会降低服务性能,一经推出就收到了广大AWS用户的欢迎。
同样,表格存储是构建在阿里云飞天分布式系统之上的分布式NoSQL数据库服务。作为同 DynamoDB 非常相似的 __云NoSQL数据库服务__,表格存储的自动负载均衡机制可以自动对表进行扩展,实现数据规模与访问并发上的无缝扩展,提供海量结构化数据的存储和实时访问。
表格存储可以使用户把操作和扩展分布式数据库的沉重负担,交给阿里云来处理,这样,用户就不需要担心硬件配置、磁盘故障、机器故障、软件安装和升级等工作,可以更专注到业务逻辑中去。
今天,就给大家介绍如何将DynamoDB的数据增量迁移到表格存储。
数据转换规则
表格存储支持的数据格式有:
- String - 可为空,可为主键,为主键列时最大为 1 KB,为属性列时为2MB。
- Integer - 64 bit,整型,可为主键,8 Bytes。
- Binary - 二进制数据,可为空,可为主键,为主键列时最大为 1 KB,为属性列时为2MB。
- Double - 64 bit,Double 类型,8 Bytes。
- Boolean - True/False,布尔类型,1 Byte。
目前 DynamoDB 支持多种数据格式:
- 标量类型 - 标量类型可准确地表示一个值。标量类型包括数字、字符串、二进制、布尔值和 null。
- 文档类型 - 文档类型可表示具有嵌套属性的复杂结构 - 例如您将在 JSON 文档中找到的结构。文档类型包括列表和映射。
- 集类型 - 集类型可表示多个标量值。集类型包括字符串集、数字集和二进制集。
由于DynamoDB支持文档型数据类型,我们需要将文档型转换为一个String类型或者Binary类型存储到表格存储中,在读取时需要反序列化成Json。
故,从DynamoDB迁移到表格存储时,我们做如下的数据转换:
| DynamoDB类型 | 数据示例 | TableStore对应类型 |
|---|---|---|
| id (N) | '123' | Integer |
| level (N) | '2.3' | Double, 不能为主键 |
| afea (NULL) | TRUE | String,空字符串 |
| binary (B) | 0x12315 | binary |
| binary_set (BS) | { 0x123, 0x111 } | binary |
| bool (BOOL) | TRUE | boolean |
| list (L) | [ { "S" : "a" }, { "N" : "1" }] | string |
| map (M) | { "key1" : { "S" : "value1" }} | string |
| str (S) | This is test! | string |
| num_set (NS) | { 1, 2 } | string |
| str_set (SS) | { "a", "b" } | string |
增量实现机制
我们使用DynamoDB的Stream数据流获取DynamoDB表中的增删改操作,将操作同步到表格存储中,为了避免环境搭建,将同步程序运行在Lambda 中,流程如下图:
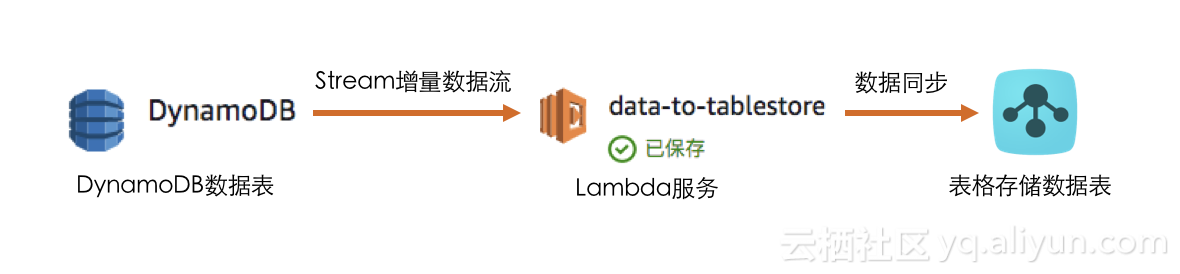
使用Stream数据流中的'eventName'字段来判别数据的增删改操作:
- "INSERT": 插入数据,对应
PutRow "MODIFY" : 修改数据
- 如果OldImage 与 NewImage的key相同,则为更新数据,对应
Update - 若OldImage的Key 数量大于 NewImage的Key数量, 则为删除数据,将两者差集的keys做删除,对应
Delete
- 如果OldImage 与 NewImage的key相同,则为更新数据,对应
- "REMOVE":删除数据,对应
DeleteRow
需要特别注意的是:
- 上述 Stream 中增删改操作转换行为符合业务的期望。
- 表格存储目前还不支持二级索引,故只能同步主表的数据。
- DynamoDB 中表的主键同TableStore中的主键保持一致,且数字类型的主键只能为整型。
- DynamoDB 对单个项目的大小限制为400KB,表格存储中单行虽然没有限制,但一次提交的数据量不能超过4MB。 DynamoDB限制项参考 及 TableStore 限制项参考
- 如果先进行全量数据迁移,则需要在全量迁移之前开启 Stream。由于 DynamoDB Stream 只能保存最近24小时数据,故全量数据需要在24小时内迁移完成,在全量迁移完成后才能开启 Lambda 的迁移任务。
- 数据需要保证最终一致性。增量数据在同步时,可能会有对全量数据的重复写入,比如 T0 时刻开启 Stream 并进行全量迁移,T1 时刻完成,那么 T0 到 T1 之间的时间段内的DynamoDB 数据操作会同步写入到表格存储中。
操作过程
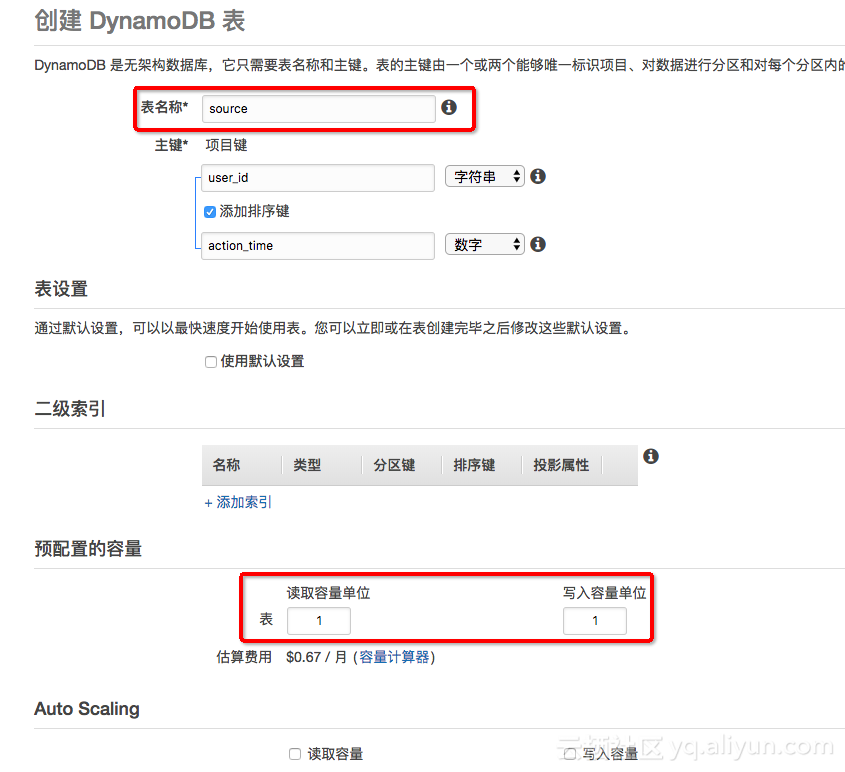
1. 在DynamoDB中创建数据表
我们以表Source为例,主键为user_id(字符串类型),排序键为action_time(数字)。由于DynamoDB的预留设置会影响读写的并发,故需要注意预留的设置。
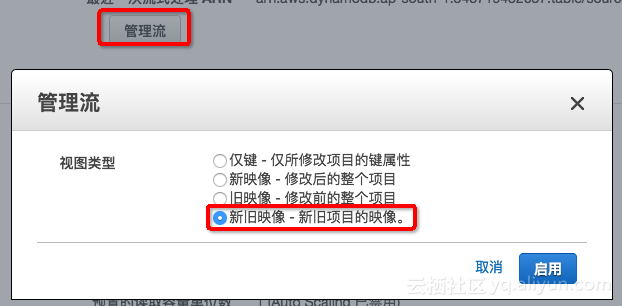
2. 开启source 表的Stream
Stream模式需要为: 新旧映像 - 新旧项目的映像
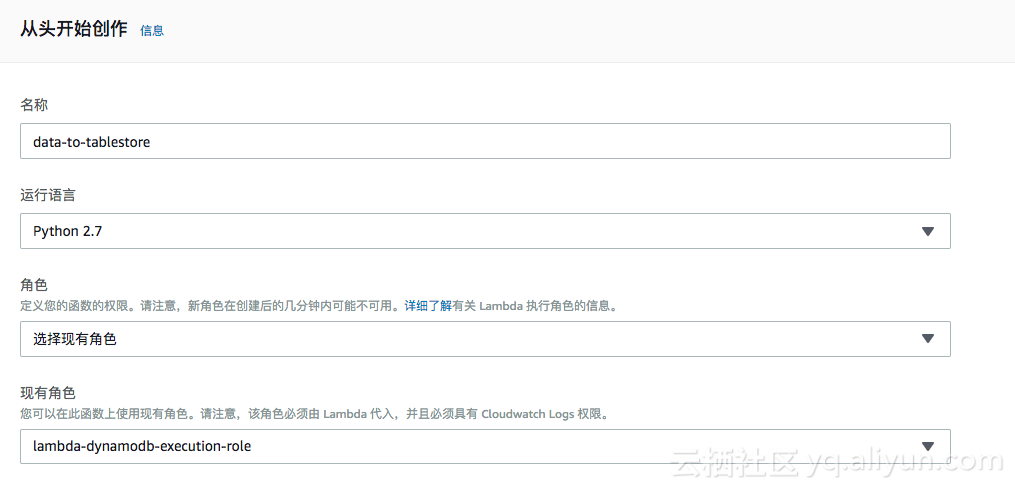
3. 转到Lambda的控制台,创建相关的数据同步函数
实例函数名称为:data-to-table, 运行语言选择为 Python 2.7,使用 lambda-dynamodb-execution-role的角色。
4.关联Lambda的事件源
点击事件源的DynamoDB图标,进行事件源配置,选择 source 数据表批处理大小先选择为10进行小批量验证,在实际运行过程中建议为100,由于表格存储的Batch操作最大为200条数据,故不能超过200。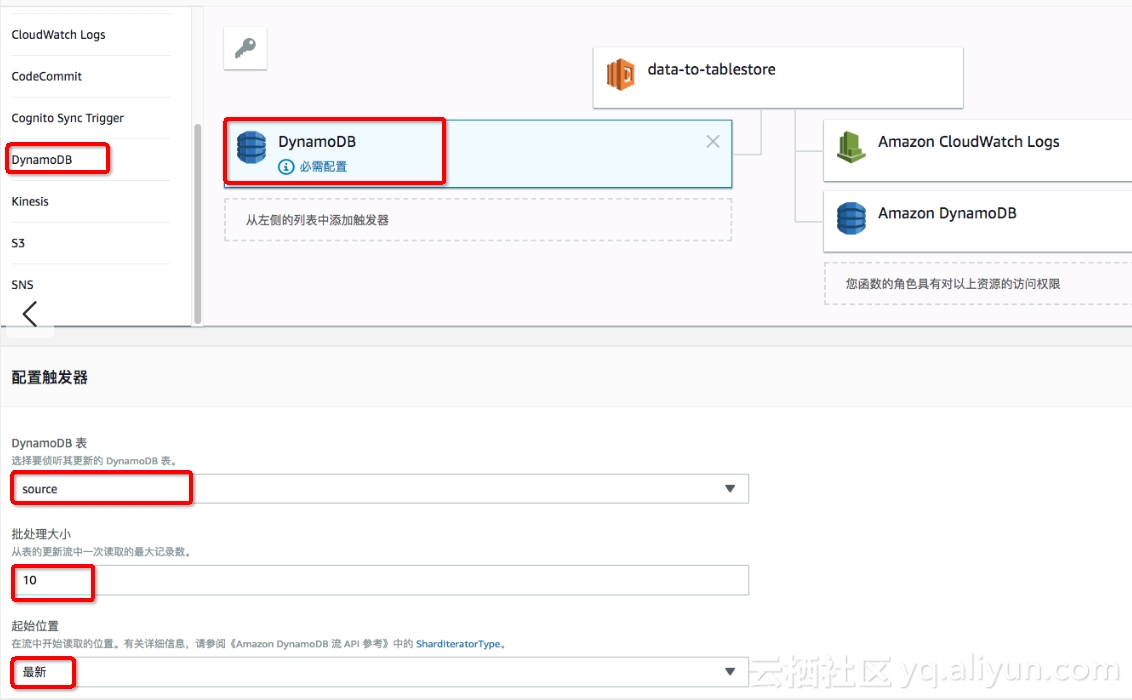
5. 配置Lambda的函数。
点击 Lambda的函数图标,进行函数相关的配置。
由于tablestore需要依赖SDK及 protocolbuf等依赖包,我们按照创建部署程序包 (Python)的方式进行 SDK依赖安装及打包。
使用的函数zip包为:lambda_function.zip 点击下载 可以直接本地上传,也可以先上传到S3。
处理程序入口为默认的 lambda_function.lambda_handler
基本设置中需要将超时事件设置在1分钟以上(考虑到批量提交的延时及网络传输时间)。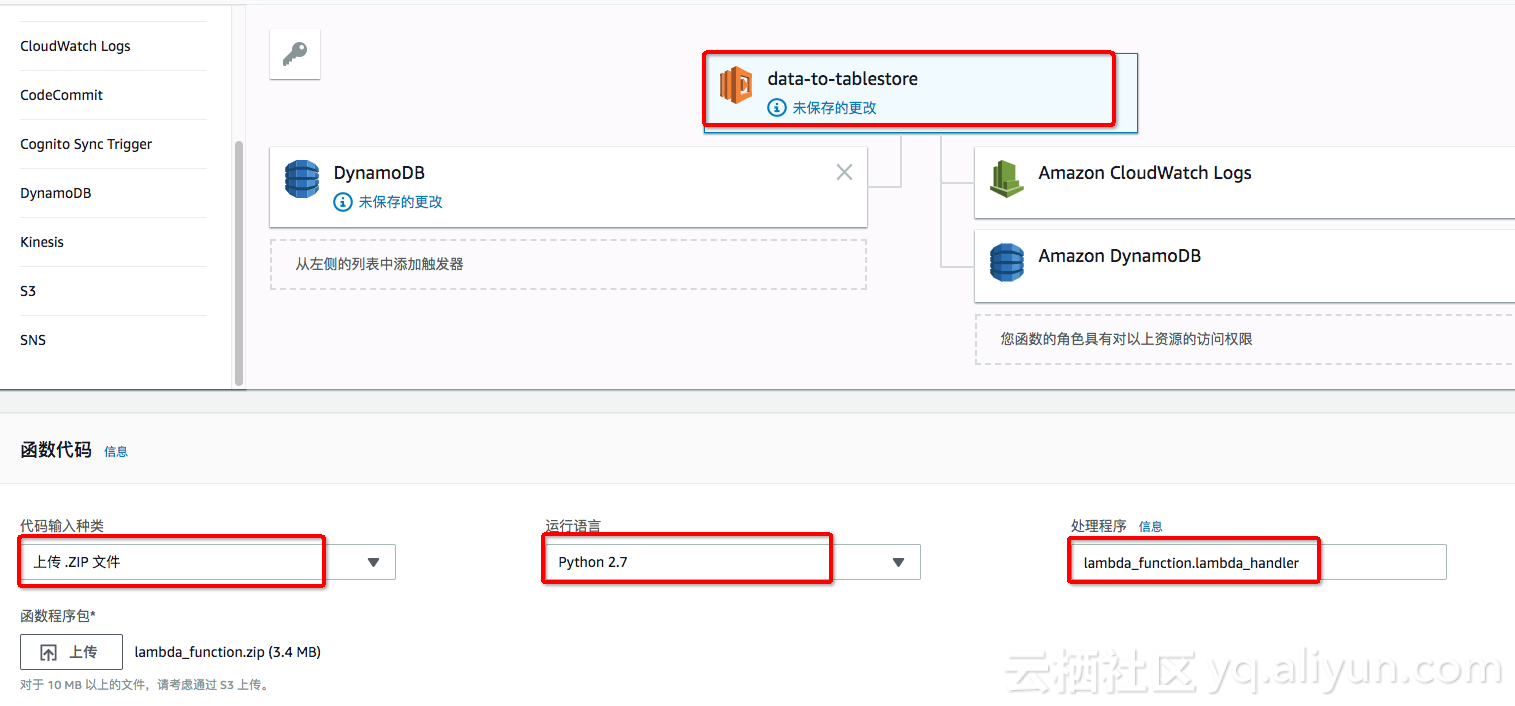
6. 配置Lambda的运行变量
在数据导入时,需要 TableStore 实例名、AK等相关信息,我们可以使用一下两种方式:
- 方案一(推荐):直接在Lambda 中配置相关的环境变量,如下图.
使用 Lambda的环境变量将使得同一函数代码zip包能够灵活的支持不同的数据表,而不需要为每个数据源修改代码包中的配置文件。
参考:Lambda环境变量说明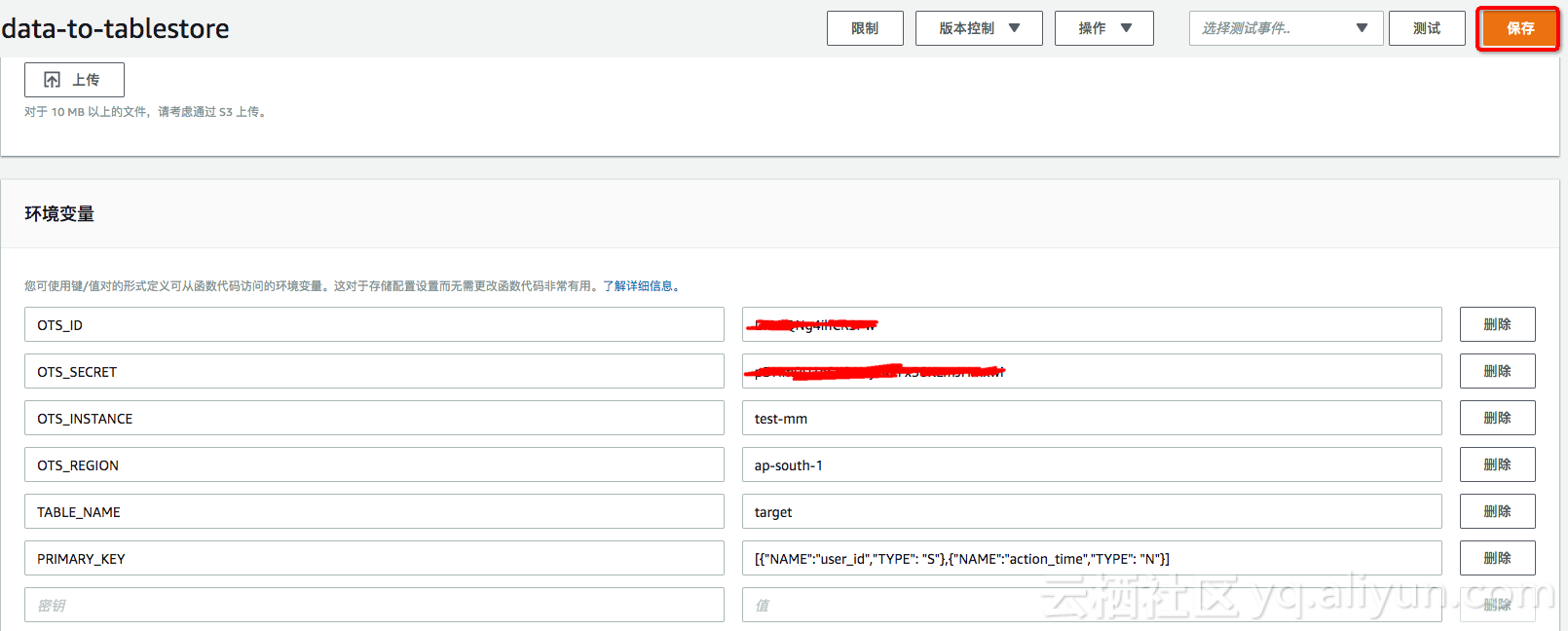
- 方案二: 也可以打开 lambda_function.zip 修改其中的example_config.py,再打包上传,或者上传之后在控制台上进行修改。
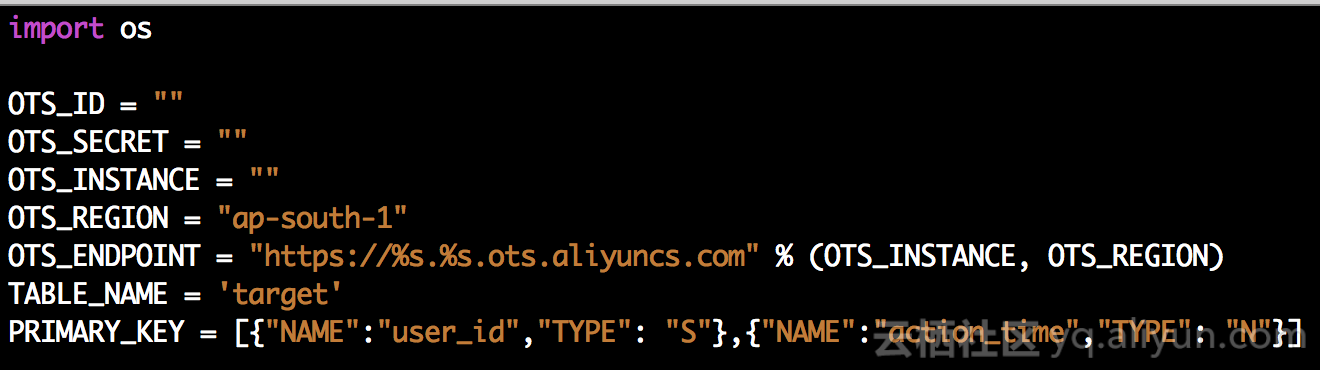
配置说明:
| 环境变量 | 必选 | 意义 |
|---|---|---|
| OTS_ID | 是 | 访问表格存储的AccessKeyId信息 |
| OTS_SECRET | 是 | 访问表格存储的AccessKeySecret信息 |
| OTS_INSTANCE | 是 | 导入的表格存储的实例名称 |
| OTS_ENDPOINT | 否 | 导入的表格存储的域名,如果不存在,则使用默认的实例公网域名 |
| TABLE_NAME | 是 | 导入的表格存储的表名 |
| PRIMARY_KEY | 是 | 导入的表格存储的表的主键信息,需要保证主键顺序,主键名称需要同源表保持一致 |
特别注意:
- 相同的变量名称,优先会从Lambda中变量配置中读取,如果不存在,则会从 example_config.py中读取。
- 由于AK信息代表这资源的访问权限,强烈建议使用只具有表格存储特定资源写权限的子账号的AK,避免AK泄露带来的风险,使用参考
7. 在表格存储中创建数据表。
在表格存储控制台上创建数据表:__target__,主键为 user_id(字符串)和action_time(整型)。
8. 测试调试。
在lambda控制台上编辑事件源进行调试。
点击右上角的 配置测试事件,输入示例事件的json内容。
我们准备了两个示例的 Stream示例事件:
- test_data_put.json 模拟向DynamoDB中插入一条数据的事件,查看文件
- test_data_update.json 模拟向DynamoDB中更新一条数据的事件,查看文件
- test_data_update.json 模拟向DynamoDB中删除一条数据的事件,查看文件
我们将上述三个事件的内容依次保存为putdata、updatedata、deletedata。
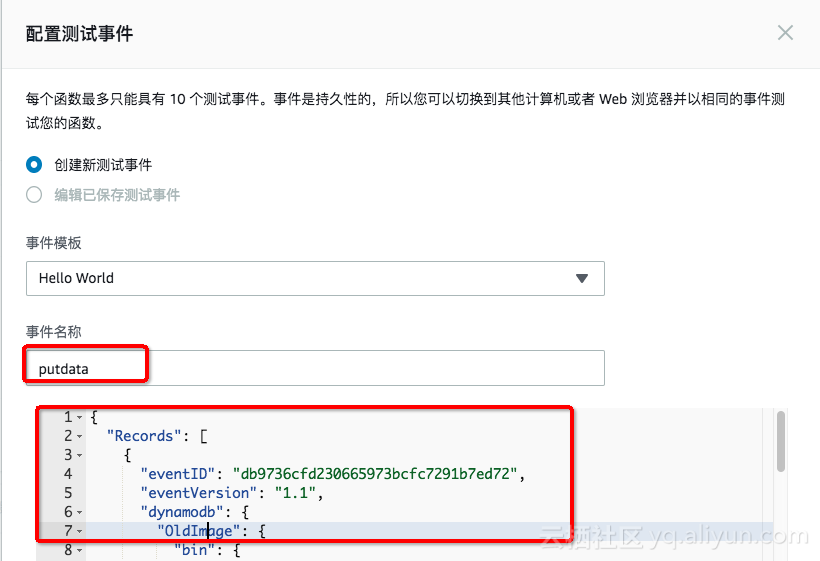
保存之后,选择需要使用的事件,点击测试:
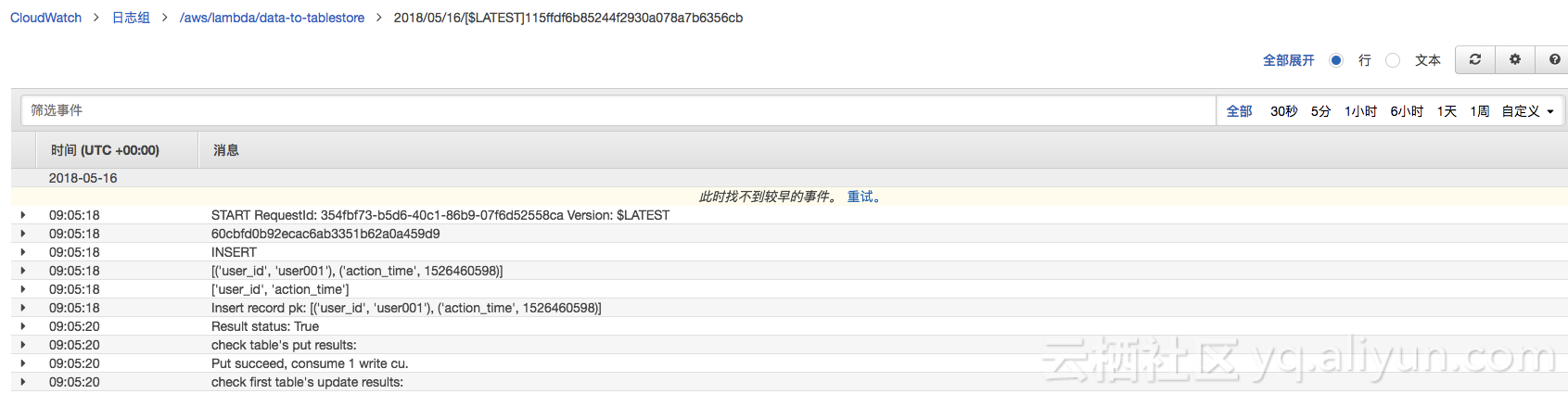
执行结果提示成功的话,则在表格存储的 target表中就可以读到如下的测试数据。
依次选择putdata、updatedata和deletedata,会发现表格存储中的数据也会随之更新和删除。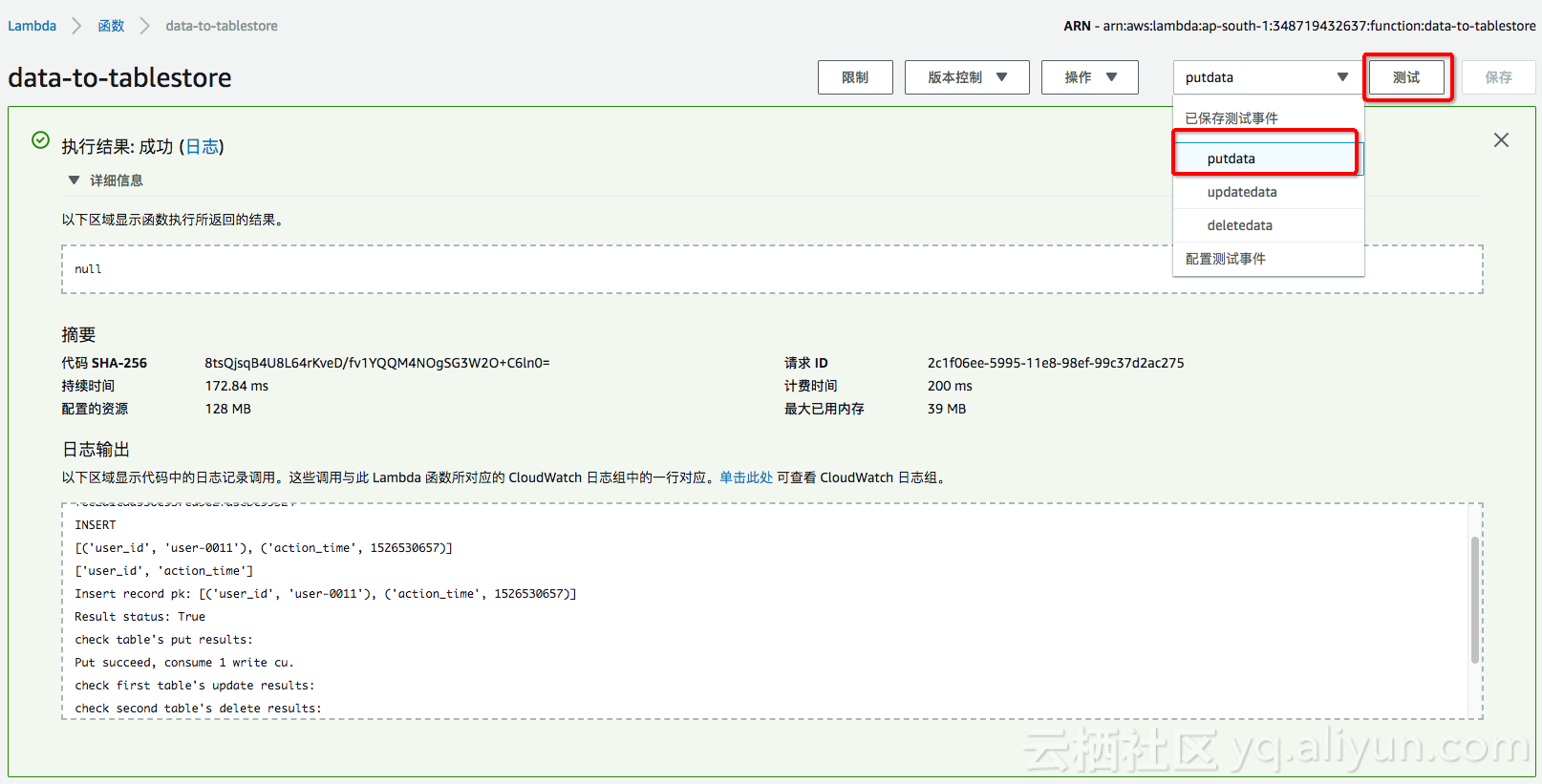

9.正式运行
测试通过之后,我们在DynamoDB中新写入一条数据,在表格存储中马上就可以读到这条数据,如下图。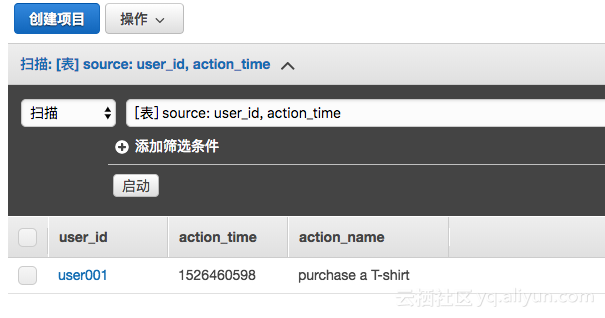
10. 问题调查
Lambda 运行的日志都会写入到 CloudWatch 中,在 CloudWatch 选择对应的函数名,则可以实时查询到 Lambda 的运行状态。
代码解析
Lambda函数中,主要的代码逻辑为lambda_function.py 查看代码,其他则为表格存储SDK的依赖。lambda_function.py中主要包含了一下几个function:
- def batch_write_row(client, put_row_items) - 将组合好的数据 Item (包括增删改)批量写到表格存储中
- def get_primary_key(keys) – 根据变量PRIMARY_KEY 拿到源表和目的表的主键信息。
- def generate_update_attribute(new_image, old_image, key_list) – 解析Stream中的Modify操作,是对部分属性列的更新还是删除了部分属性列。
- def generate_attribute(new_image, key_list) – 获取单个Record中插入的属性列信息。
- def get_tablestore_client() – 根据变量中的实例名、AK信息等初始化表格存储的客户端。
- def lambda_handler(event, context) – Lambda的入口函数。
如果有更复杂的同步逻辑,也可以基于 lambda_function.py 进行修改。
lambda_function.py 中打印的状态日志没有区分 INFO 或者 ERROR,为了保证数据同步的一致性,还需要对日志进行处理,并监控运行状态或者使用 lambda 的错误处理机制保证对异常情况的容错处理。
本文作者:表格存储
如何将DynamoDB的数据增量迁移到表格存储的更多相关文章
- Hbase实用技巧:全量+增量数据的迁移方法
摘要:本文介绍了一种Hbase迁移的方法,可以在一些特定场景下运用. 背景 在Hbase使用过程中,使用的Hbase集群经常会因为某些原因需要数据迁移.大多数情况下,可以跟用户协商用离线的方式进行迁移 ...
- MySQL如何发型不乱的应对半年数十TB数据增量
➠更多技术干货请戳:听云博客 前段时间,Oracle官方发布了MySQL 5.7的GA版本.新版本中实现了真正意义的并行复制(基于Group Commit的Group Replication),而不 ...
- ETL中的数据增量抽取机制
ETL中的数据增量抽取机制 ( 增量抽取是数据仓库ETL(extraction,transformation,loading,数据的抽取.转换和装载)实施过程中需要重点考虑的问 题.在ETL过 ...
- 从SQL Server到MySQL,近百亿数据量迁移实战
从SQL Server到MySQL,近百亿数据量迁移实战 狄敬超(3D) 2018-05-29 10:52:48 212 沪江成立于 2001 年,作为较早期的教育学习网站,当时技术选型范围并不大:J ...
- mongodb 数据块迁移的源码分析
1. 简介 上一篇我们聊到了mongodb数据块的基本概念,和数据块迁移的主要流程,这篇文章我们聊聊源码实现部分. 2. 迁移序列图 数据块迁移的请求是从配置服务器(config server)发给( ...
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
- Oracle数据逻辑迁移综合实战篇
本文适合迁移大量表和数据的复杂需求. 如果你的需求只是简单的迁移少量表,可直接参考这两篇文章即可完成需求: Oracle简单常用的数据泵导出导入(expdp/impdp)命令举例(上) Oracle简 ...
- sqlite升级--浅谈Android数据库版本升级及数据的迁移
Android开发涉及到的数据库采用的是轻量级的SQLite3,而在实际开发中,在存储一些简单的数据,使用SharedPreferences就足够了,只有在存储数据结构稍微复杂的时候,才会使用数据库来 ...
- 【转】ETL数据增量抽取——通过触发器方式实现
在使用Kettle进行数据同步的时候, 共有 1.使用时间戳进行数据增量更新 2.使用数据库日志进行数据增量更新 3.使用触发器+快照表 进行数据增量更新 今天要介绍的是第3中方法. 实验的思路是这样 ...
随机推荐
- 《Using Databases with Python》Week1 Object Oriented Python 课堂笔记
Coursera课程<Using Databases with Python> 密歇根大学 Charles Severance Week1 Object Oriented Python U ...
- 【ABAP系列】SAP ABAP选择屏幕(SELECTION SCREEN)事件解析
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]SAP ABAP选择屏幕(SEL ...
- TNS-01106: Listener using listener name LISTENER has already been started
-- 启动监听,提示已经启动. [oracle@sh ~]$ lsnrctl startLSNRCTL for Linux: Version 12.1.0.2.0 - Production on 06 ...
- 002--PowerDesigner显示注释comment
PowerDesigner显示注释comment 参考博客:https://blog.csdn.net/chao_1990/article/details/52620206 原始样式 显示操作 调出执 ...
- python基础-9.2 单例模式
设计模式 一.单例模式 单例,顾名思义单个实例.创建一个实例 链接池案例 1.单例=>只有一个实例 2.静态方法+静态字段 3.所有的实例中封装的内容相同时用单例模式 class Connect ...
- 第四周课程总结&试验报告
实验二 Java简单类与对象 实验目的 掌握类的定义,熟悉属性.构造函数.方法的作用,掌握用类作为类型声明变量和方法返回值: 理解类和对象的区别,掌握构造函数的使用,熟悉通过对象名引用实例的方法和属性 ...
- [19/05/15-星期三] HTML_body标签(超链接标签和锚点)
一.超链接标签 <html> <head> <meta charset="UTF-8"> <title>04 body超链接标签学习 ...
- Git-第二篇廖雪峰Git教程学习笔记(1)基本命令,版本回退
1.安装Git-2.16.2-64-bit.exe后,设置用户名,用户邮箱 #--global参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地 ...
- java 继承extends 的相关知识点
java只有单继承,不能多继承 子类只能继承父类的非私有成员(成员变量.成员方法) 子类不能继承父类的构造方法,但是可以通过super关键字访问父类的构造方法 继承 要体现子类父类的 继承关系, ”i ...
- HDU 1009 FatMouse' Trade题解
版权声明:本文作者靖心,靖空间地址:http://blog.csdn.net/kenden23/.未经本作者同意不得转载. https://blog.csdn.net/kenden23/article ...