Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库
url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6
1.分析网页的源代码:右键--查看网页源代码.
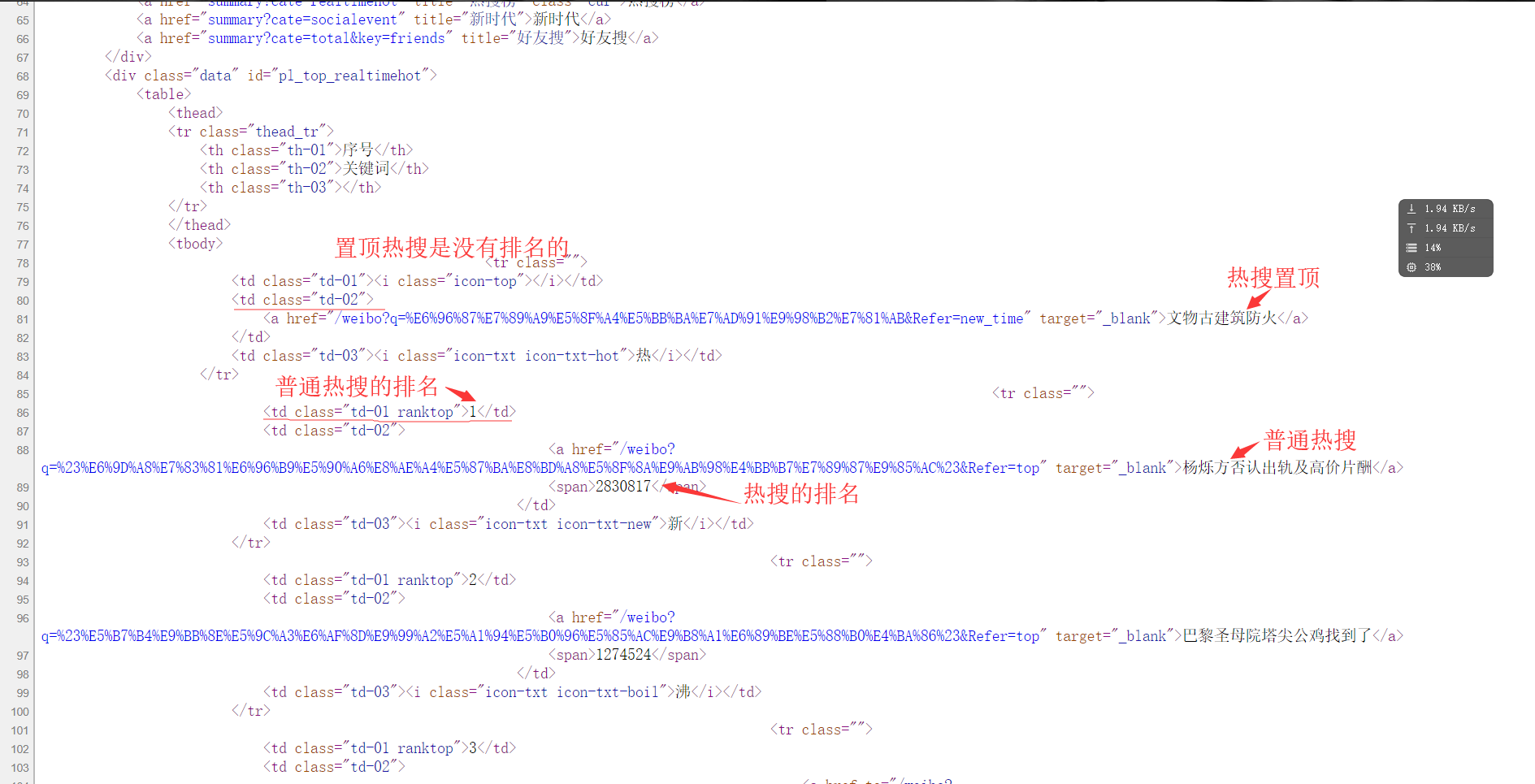
从网页代码中可以获取到信息
(1)热搜的名字都在<td class="td-02">的子节点<a>里
(2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是没有排名的!)
(3)热搜的访问量都在<td class="td-02">的子节点<span>里
2.requests获取网页
(1)先设置url地址,然后模拟浏览器(这一步可以不用)防止被认出是爬虫程序。
###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器,这个请求头windows下都能用
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
(2)利用requests库的get()和lxml的etree()来获取网页代码
###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
3.构造xpath路径
上面第一步中三个xath路径分别是:
affair=html.xpath('//td[@class="td-02"]/a/text()')
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
view=html.xpath('//td[@class="td-02"]/span/text()')
xpath的返回结果是列表,所以affair、rank、view都是字符串列表
4.格式化输出
需要注意的是affair中多了一个置顶热搜,我们先将他分离出来。
top=affair[0]
affair=affair[1:]
这里利用了python的切片。
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
这里还是没能做到完全对齐。。。 5.全部代码
###导入模块
import requests
from lxml import etree ###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'} ###主函数
def main():
###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
affair=html.xpath('//td[@class="td-02"]/a/text()')
view = html.xpath('//td[@class="td-02"]/span/text()')
top=affair[0]
affair=affair[1:]
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
main()
结果展示:

Python网络爬虫-爬取微博热搜的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- nodejs实现定时爬取微博热搜
The summer is coming " 我知道,那些夏天,就像青春一样回不来. - 宋冬野 青春是回不来了,倒是要准备渡过在西安的第三个夏天了. 废话 我发现,自己对 coding 这 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- BeautifulSoup爬取微博热搜榜
获取url 设定请求头 requests发出get请求 实例化BeautifulSoup对象 BeautifulSoup提取数据 import requests 2 from bs4 import B ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
- Python网络爬虫 - 爬取中证网银行相关信息
最终版:07_中证网(Plus -Pro).py # coding=utf-8 import requests from bs4 import BeautifulSoup import io impo ...
- Python爬取微博热搜以及链接
基本操作,不再详述 直接贴源码(根据当前时间创建文件): import requests from bs4 import BeautifulSoup import time def input_to_ ...
随机推荐
- python+selenium下拉列表option对象操作方法一
参考官方文档:https://selenium.dev/selenium/docs/api/py/webdriver_support/selenium.webdriver.support.select ...
- linux中编写查看内存使用率的shell脚本,并以高亮颜色输出结果
编辑脚本内容: #!/bin/bash MEMUSER=`free -m|grep -i mem|awk '{print $3/$2*100"%"}'` echo -e " ...
- win10创建扩展分区
1.开始菜单中选择命令提示符,以管理员身份运行. 2.运行“diskpart”命令. 3.DISKPART>后面输入list disk命令,显示磁盘列表. 4.选择磁盘,select disk ...
- SQL基本语法和书写格式
插入 insert [into] 表名 [(列名列表)] values (值列表) insert into 新表名 (列名列表) select 列名列表 from 表名 select 表名.列名 in ...
- 下载JSON数据
最近学习MongoDB,需要获取大量Json在线数据,例如: http://media.mongodb.org/zips.json 此处使用c#,直接给出代码: HttpWebRequest requ ...
- 单调栈 && 洛谷 P2866 [USACO06NOV]糟糕的一天Bad Hair Day(单调栈)
传送门 这是一道典型的单调栈. 题意理解 先来理解一下题意(原文翻译得有点问题). 其实就是求对于序列中的每一个数i,求出i到它右边第一个大于i的数之间的数字个数c[i].最后求出和. 首先可以暴力求 ...
- [BZOJ2588]Count on a tree(LCA+主席树)
题面 给定一棵N个节点的树,每个点有一个权值,对于M个询问(u,v,k),你需要回答u xor lastans和v这两个节点间第K小的点权.其中lastans是上一个询问的答案,初始为0,即第一个询问 ...
- poj 2248 Addition Chains (迭代加深搜索)
[题目描述] An addition chain for n is an integer sequence with the following four properties: a0 = 1 am ...
- linux搭建tomcat集群+nginx
安装JDK 一.官方下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 下 ...
- latex算法步骤如何去掉序号
想去掉latex算法步骤前面的序号,如下 我想去掉每个算法步骤前面的数字序号,1,2,3,因为我已经写了step.我们只需要引用a lgorithmic这个包就可以了,代码如下: \usepackag ...