了解Greenplum (2)
一、目的
1、 理解Greenplum中的数据分布策略(random 和 distribution),分析不同分布策略的优劣;
2、 理解查询执行中的数据广播和数据重分布,分析在何种情况下选择哪种策略,以具体实验验证;
3、借助explain指令,分析select、join、group等常用sql语句的执行流程;
4、查看相关文档理解SQL中窗口函数的语义,分析窗口函数的执行语义,以实验验证。
(复制)
二、 使用环境
主机数量:3台虚拟机,1台master单核2G内存,2台slave单核1.5G内存
虚拟机:VMware 10.0
操作系统:CentOS 6.7
Greenplum版本:4.3.99.00(PostgreSQL 8.3.23)
二、实验过程
1、Greenplum数据分布策略random与hash-distribution
首先,创建一张原始表,输入一些数据,不指定分布键,默认以第一列作为分布键。
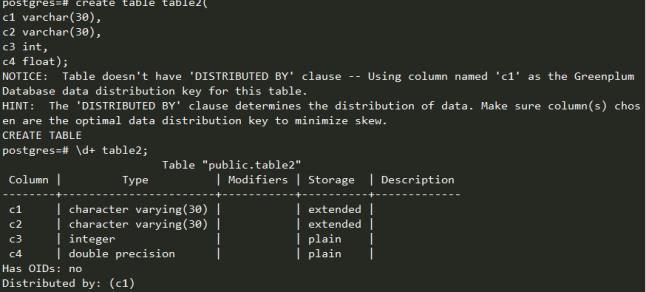
可以修改分布键,按c3列分布。
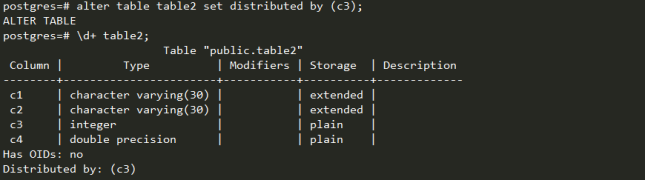
插入一些数据,然后查看数据分布。
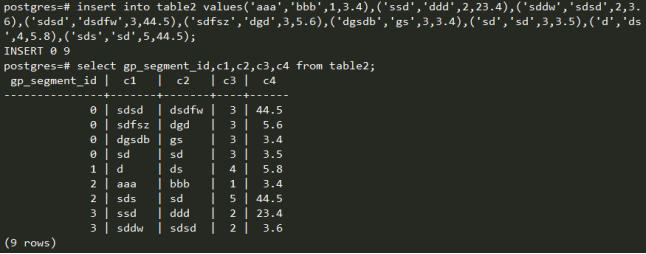
可以观察到,按c3列的值进行哈希分布。c3=3的值全部分布到seg0,因此可以看出,若分布键不均匀,以hash分布的方式分布数据,存在数据偏移。
修改分布策略为随机分布,查看数据分布。
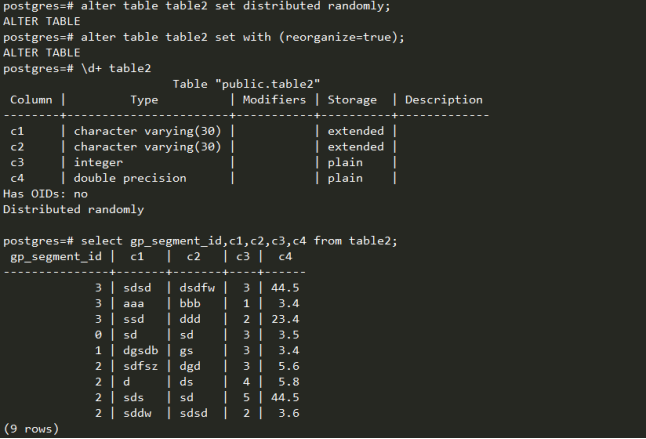
咋一看,数据分布也不均匀,但是这可能是由于数据量过少,随机分布出现的偏差。重新组织数据,再次查看,发现数据分布比较均匀了。而且,可以看到,c3=3的行被分散到不同的seg中去。
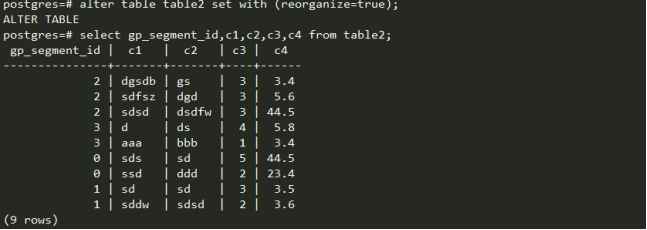
总结GP的分布策略,采用随机的分布方式,数据分布较为均匀。按分布键的方式进行哈希分布,不一定能够保证数据不会存在偏移,但是对于读取数据应该较为友好。可以不必遍历所有的seg节点。
2、数据广播和数据重分布
关联数据在不同节点上的,需要通过网络流入到一个节点上执行连接操作,产生了数据迁移,GP中的数据迁移方式为数据广播和数据重分布。
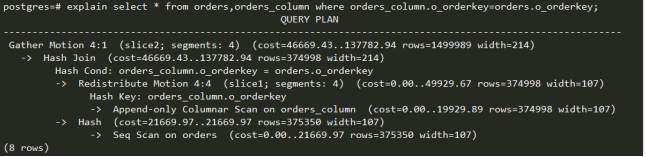
数据重分布,使用上次作业所导入的表,进行连接操作,发现查询计划使用了数据重复布执行。
数据广播,创建一个小表oders_replay,使其与大表做连接,发现查询的执行方式变成数据广播方式。
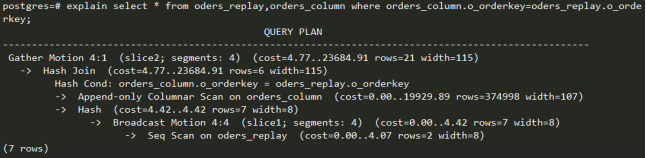
因此,总结上面GP策略的选择上,若数据量相差比较大的情况下,将小表广播到各个seg节点上,会执行的更快。若数据量基本相当,则使用数据重分布的方式,通常代价比较小。
3、sql执行流程
Select语句执行:
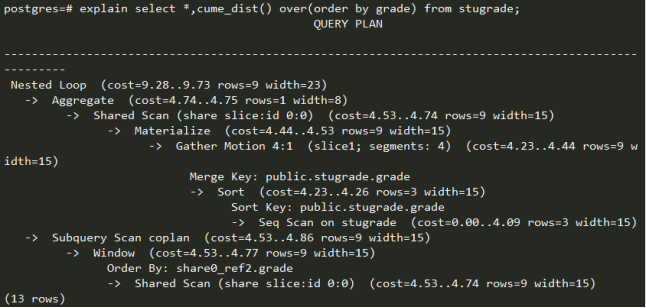
根据上图所示,”select *,cume_dist() over(order by grade) from stugrade;”语句是一个嵌套循环查询,循环内先做调用聚集函数。分布式执行过程采用Gather Motion(N:1)方式将所有子节点汇合数据到slice 1(master)上。顺序扫描全表,按grade合并,再排序。
Join 语句执行:
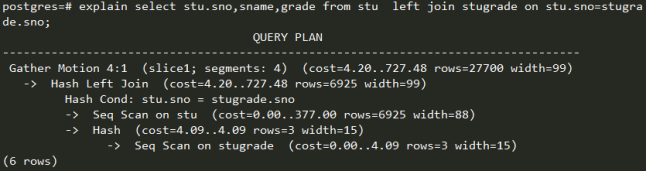
上面的Join语句同样是采用Gather Motion(N:1)方式迁移数据,之后采用hash join的方式进行连接。
Group 语句执行:
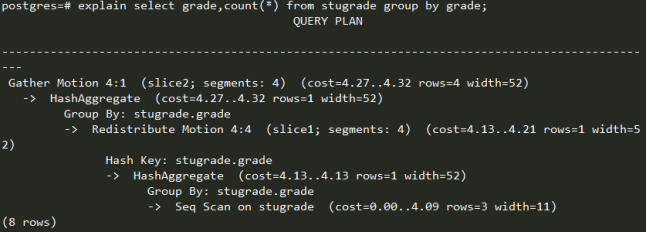
Group语句以grade属性进行成组,统计各grade的人数,sql执行过程是,数据按grade键重分布,顺序扫描stugrade表,然后使用hash方式是以grade属性成组,最后迁移到一个节点进行统计返回结果。
4、窗口函数
窗口函数是只能在select语句中使用的一直函数类型,每一行返回一个值,结果按照当前行或行所对应的窗口分隔、框架来说明,使用时带有over语句。所有窗口函数都使用over()语句作为条件,可在括号中指定应用的函数。
窗口函数表:
|
函数 |
返回类型 |
语法 |
描述 |
|
cume_dist() |
double precision |
CUME_DIST() OVER ( [PARTITION BY expr ] ORDER BY expr ) |
计算一组只中值的累计分布。具有相同值的行有相同的累计分布值。 |
|
dense_rank() |
bigint |
DENSE_RANK () OVER ( [PARTITION BY expr ] ORDER BY expr ) |
计算在一个无跳过的有序组中的行的排行值。 |
|
first_value(expr) |
same as input expr type |
FIRST_VALUE( expr ) OVER ( [PARTITION BY expr ] ORDER BY expr [ROWS|RANGE frame_expr ] ) |
返回一个有序集合中的第一个元素的值 |
|
lag(expr[,offset] [,default]) |
same as input expr type |
LAG( expr [, offset ] [, default ]) OVER ( [PARTITION BY expr ] ORDER BY expr ) |
提供一个访问同一个表的多行数据,而不用做自连接。从查询中返回一系列行的游标。LAG提供在给定偏移上的一行的访问。默认偏移是1。如果偏移超过范围,讲返回默认值。若默认值没有指定,则默认值为空。 |
|
last_value(expr) |
same as input expr type |
LAST_VALUE(expr) OVER ( [PARTITION BY expr ] ORDER BY expr [ROWS|RANGE frame_expr ] ) |
返回一个有序集合中的最后一个元素的值 |
|
lead(expr [,offset] [,default]) |
same as input expr type |
LEAD(expr [,offset] [,exprdefault]) OVER ( [PARTITION BY expr ] ORDER BY expr ) |
提供一个访问同一个表的多行数据,而不用做自连接。从查询中返回一系列行的游标。Lead提供在给定偏移上的一行的访问。默认偏移是1。如果偏移超过范围,讲返回默认值。若默认值没有指定,则默认值为空。 |
|
ntile(expr) |
bigint |
NTILE(expr) OVER ( [PARTITION BY expr ] ORDER BY expr ) |
将一个有序的数据集划分成若干桶(由表达式定义),假设每一行放进一个桶中。 |
|
percent_rank() |
double precision |
PERCENT_RANK () OVER ( [PARTITION BY expr ] ORDER BY expr ) |
计算在数据集中的百分比。 |
|
rank() |
bigint |
RANK () OVER ( [PARTITION BY expr ] ORDER BY expr ) |
计算一个有序组中的排名,相同值的排名相同,所以排名可能不连续。 |
|
row_number() |
bigint |
ROW_NUMBER () OVER ( [PARTITION BY expr ] ORDER BY expr ) |
将一个唯一的数字分配给分区中的每一行或这个查询的每一行。 |
简单的对上面的几个窗口函数进行测试。
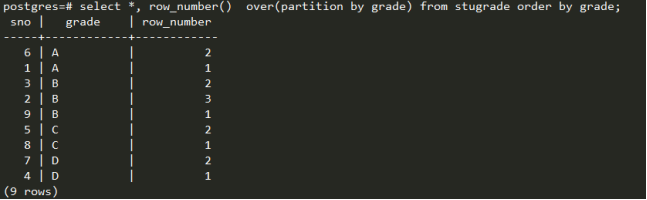
Row_number():
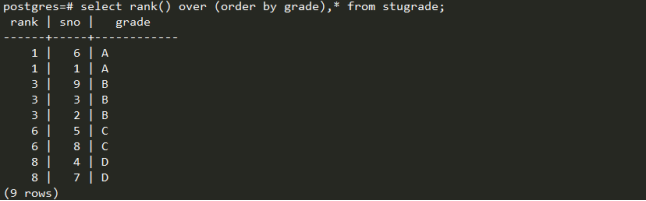
Rank():
Percent_rank(): 这里的百分比是指在之前n-1行的百分比累计值。相同行值的百分比值相同。
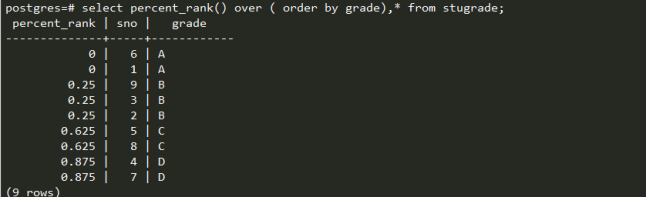
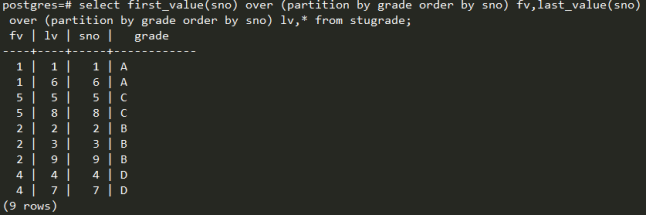
last_value(expr) 和first_value(expr):last取分区内最后一个元素,first区第一个元素。
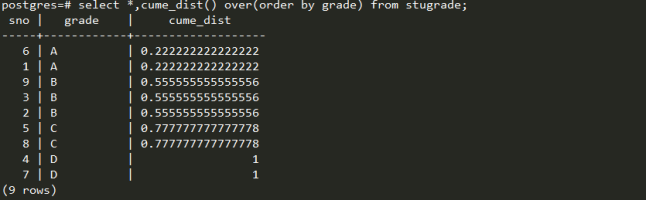
Cume_dist():
5.附注
*
了解Greenplum (2)的更多相关文章
- Greenplum 的分布式框架结构
Greenplum 的分布式框架结构 1.基本架构 Greenplum(以下简称 GPDB)是一款典型的 Shared-Nothing 分布式数据库系统.GPDB 拥有一个中控节点( Master ) ...
- 海量数据处理利器greenplum——初识
简介及适用场景 如果想在数据仓库中快速查询结果,可以使用greenplum. Greenplum数据库也简称GPDB.它拥有丰富的特性: 第一,完善的标准支持:GPDB完全支持ANSI SQL 200 ...
- GreenPlum高效去除表重复数据
1.针对PostgreSQL数据库表的去重复方法基本有三种,这是在网上查找的方法,在附录1给出.但是这些方法对GreenPlum来说都不管用. 2.数据表分布在不同的节点上,每个节点的ctid是唯一的 ...
- 实现从Oracle增量同步数据到GreenPlum
简介: GreenPlum是一个基于PostgreSQL数据库开发的MPP架构的数据库仓库,适用于OLAP系统,支持50PB(1PB=1000TB)级海量数据的存储和处理. 背景: 目前有一个业务是需 ...
- Greenplum 源码安装教程 —— 以 CentOS 平台为例
Greenplum 源码安装教程 作者:Arthur_Qin 禾众 Greenplum 主体以及orca ( 新一代优化器 ) 的代码以可以从 Github 上下载.如果不打算查看代码,想下载编译好的 ...
- 大数据系列-java用官方JDBC连接greenplum数据库
这个其实非常简单,之所以要写此文是因为当前网上搜索到的文章都是使用PostgreSQL的驱动,没有找到使用greenplum官方驱动的案例,两者有什么区别呢? 一开始我也使用的是PostgreSQL的 ...
- Greenplum安装
最近需要安装Greenplum测试一些东西,在安装过程中出现了许多问题,所以在这里将安装过程整理一下,主要参考<Greenplum企业应用实践>和http://jxzhfei.blog.5 ...
- Greenplum查询计划分析
这里对查询计划的学习主要是对TPC-H中Query2的分析. 1.Query的查询语句 select s_acctbal, s_name, n_name, p_partkey, p_mfgr, s_a ...
- Greenplum 数据库安装部署(生产环境)
Greenplum 数据库安装部署(生产环境) 硬件配置: 16 台 IBM X3650, 节点配置:CPU 2 * 8core,内存 128GB,硬盘 16 * 900GB,万兆网卡. 万兆交换机. ...
- Greenplum测试环境部署
1.准备3台主机 本实例是部署实验环境,采用的是Citrix的虚拟化环境,分配了3台RHEL6.4的主机. |------|------| |Master|创建模板后,额外添加20G一块磁盘/dev/ ...
随机推荐
- size_t是什么?
在32位编译器下size_t可看做unsigned int: 在64位编译器下size_t可看做unsigned long long: sizeof返回的数据类型就为size_t. C++之size_ ...
- session.flush()与session.clear()的区别
session.flush()和session.clear()就针对session的一级缓存的处理. 简单的说, 1 session.flush()的作用就是将session的缓存中的数据与数据库同步 ...
- Python 学习笔记(基础语法 restful 、 Flask 和 Requests)
input 函数 #!/usr/bin/env python3 name = input("\n\n按下 enter 键后退出.") print(name) print() 在 p ...
- mysql中的collate关键字是什么意思?
CREATE TABLE `tb_order` ( `order_id` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '订单id', `paym ...
- Linux 用户必须知道的 14 个常用 Linux 终端快捷键
简介:以下是一些每个 Linux 用户必须使用的键盘快捷键. 使用命令行时,这些 Linux 快捷键将提升你的工作效率和效率. 你知道什么把专业用户和普通用户分开的吗?掌握键盘快捷键. 好的!这虽不是 ...
- Android animation summary
Android animation 动画定义 动画的意思就是一连串画面动起来了,根据这一连串画面的产生原理可分为两类:补间动画(Tween animation)和帧动画(frame animation ...
- (转)C#_WinForm接收命令行参数
本文转载自:http://blog.csdn.net/lysc_forever/article/details/38356007 首先,我要仔细的声明下,本文讲的是接受命令行参数,让程序启动.而不是启 ...
- tensorflow和keras的安装
1 卸载tensorflow方法,在终端输入: 把protobuf删除了才能卸载干净. sudo pip uninstall protobuf sudo pip uninstall tensorfl ...
- C++ 命名管道示例
想做一个 Hook CreateFile 重定向到内存的功能,貌似可以假借命名管道实现这个功能.不熟悉命名管道,做了几个demo,如下: Server: // NamedPipeServer.cpp ...
- oracle--多表联合查询sql92版
sql92学习 -查询员工姓名,工作,薪资,部门名称 sql的联合查询(多表查询) --1.sql92标准 ----笛卡尔积:一件事情的完成需要很多步骤,而不同的步骤有很多种方式,完成这件事情的所有方 ...