DS-哈希表浅析
1.哈希表
2.哈希函数
3.哈希冲突
哈希表
哈希表是一种按key-value存储的数据结构,也称散列表。
之前的数组、树和图等等查找一个值时都要与结构中的值相比较,查找的效率取决于比较的次数。
而哈希表因为key与value对应,则可以在较少的比较次数中找到元素。
哈希函数
哈希表是对于给定的一个key,建立一个函数H(key),y =H(key)即为元素key在数组内的储存位置。
1.直接定址法
直接建立一个与key相关的线性函数形如:H(key)=k*key+b
2.数字分析法
就是找找规律,尽量让大多数H(key)落在不同区间,例如对于身份证号码,前面的数字重复率太高,可以考虑用出生年月日计算当key。
3.平方取中法
取关键字平方后的中间几位当做哈希地址。
4.折叠法
将关键字分成位数相同的几个部分(最后一部分位数可以不同),然后取这几部分的叠加和作为哈希地址。
关键字位数很多,并且数字分步均匀时可以考虑采用折叠法。
5.除留余数法
形如H(key) = key %m.
6.随机数法(还莫得理解)
哈希冲突
当key过多时,就容易发生多个key对于H出现同样的结果,就是它们会占用数组同一个位置,这就是哈希冲突。
冲突是不可避免的,我们要做的就是要尽可能的使冲突达到最小。
常用的处理冲突的方法有:
1.开放定址法
这个时候H* = (H(key)+di)%m , di = 1、2、3........m-1
这里对于di 的值又有三种取法:
1)线性探测再散列:
顾名思义,di取值为1,2,3.....m-1,也就是当前位置已经有元素时,会像下一个位置走。
2)二次探测再散列
这里di 取值为 1^2 、 -1^2 、2^2、-2^2.......- (m/2)^2 , m为散列表长度,若是算出key+di为负数,则加上m再取余,也就是移到了后面,即-1就移到最后一位。
3)伪随机探测再散列(这个还没搞懂)
2.链地址法
链地址法,看图理解。
经过哈希函数后,对于处于同一位置的元素,用链表将它们储存。
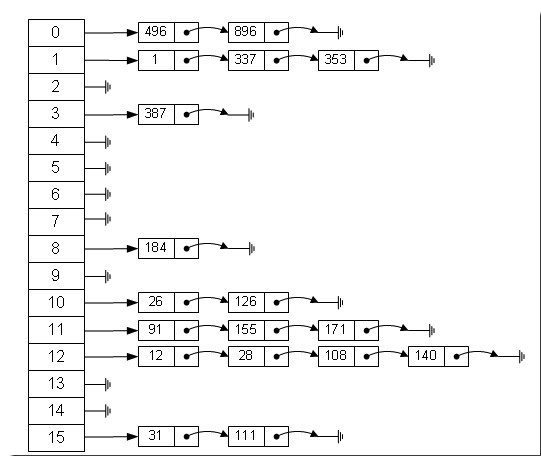
(图源自网络)
3.再哈希法
Hi = RHi(key), i = 1,2,3.....k
RHi 是不同的函数,在用一个哈希函数产生冲突时就调用另一个,直到不产生冲突为止。
4.建立公共溢出表
也就是建立另一个区间,产生冲突的都放进另一个区间。感觉不太好用,冲突多了比较次数又多了。
下面用除余法和链地址法(尾接法)写的代码如下:
#include<iostream>
using namespace std; #define hashsize 11 struct Node{//链表节点
int data;
Node *next;
int flag;
Node(){
flag=;
next=NULL;
}
Node (int num){
flag=;
data=num;
next=NULL;
}
}; class Hash{
private:
Node *hashtable;
int len;//记录现在数据个数 public:
Hash(){
len=;
hashtable = new Node[hashsize];
}
~Hash(){
}
//获得key值 ,哈希函数
int getKey(int num){
return num%hashsize;
}
//往表中插入元素 ,链接法
void insertData(int num){
int key = getKey(num);//获得key值 if(hashtable[key].flag==){//此时当前key位置无数据
hashtable[key].data=num;
hashtable[key].flag=;
}
else{//尾插入法
Node *tmp = &hashtable[key];//指针要获得地址才能赋值
while(tmp->next!=NULL)
tmp=tmp->next;
tmp->next = new Node(num);
}
len++;
}
//查找hash表中是否有这个元素,有则返回查找次数,无则返回-1
int find(int num){
int sum=;
int key = getKey(num);//获取该数键值
if(hashtable[key].flag==){
insertData(num);
return -;
}
else{
Node *tmp = &hashtable[key];
while(tmp->data!=num){
sum++;
if(tmp->next==NULL){
insertData(num);
return -;
}
tmp=tmp->next;
}
//能退出上面的while说明找到相等的了,return sum
return sum;
}
}
}; int main(){
int n;
cin>>n;
int num[];
for(int i=;i<n;i++)
cin>>num[i]; Hash *hash = new Hash();
for(int i=;i<n;i++)
hash->insertData(num[i]); cin>>n;
for(int i=;i<n;i++){
cin>>num[i];
if(hash->find(num[i])!=-)
cout<<hash->getKey(num[i])<<" "<<hash->find(num[i])<<endl;
else cout<<"error"<<endl;
}
这里待测样例如下:
样例输出:
接下来是用除余法与二次散列再分配写的代码:
//该程序使用二次散列再查找的方式处理冲突构建哈希表
//哈希函数选择除于11的方法 #include<iostream>
using namespace std;
#define modnum 11 struct HashData{
int data;
int flag;
HashData(){
flag=;//当查找次数
}
}; class Hash{ private:
HashData *hashtable;//哈希表
int len;
int *value;
public:
Hash(int n){
hashtable = new HashData[n];
len=n;
int flag = -;
int pos=;
value = new int [len];
for(int i=;i<len/;i++){
value[pos++]=i*i;
value[pos++]=flag*i*i;
}
}
~Hash(){
}
int getKey(int num){
return num%modnum;
}
void insert(int num){
int key = getKey(num); if(hashtable[key].flag==){
hashtable[key].data = num;
hashtable[key].flag = ;
}
else{
int flag1=;
for(int i=;i<len;i++){
//二次散列 ,找到空的位置
flag1++;
//如果此时key+value[i] 是负数就去到H()+len的位置
if(hashtable[(key+value[i]+len)%len].flag==){
hashtable[(key+value[i]+len)%len].data = num;
hashtable[(key+value[i]+len)%len].flag = flag1;
return ;
}
}
}
}
int find(int num){
int key = getKey(num);//获得键值
if(hashtable[key].data==num){
return key+;
}
else{
for(int i=;i<len;i++){
if(hashtable[(key+value[i]+len)%len].data==num){
return (key+value[i]+len)%len+;
}
}
return -;
}
}
int getSum(int num){
int key = find(num);//获得键值
if(key != -)
return hashtable[key-].flag;
else{
int sum=;
for(int i=;i<len;i++){
sum++;
//说明找不到这个元素
if(hashtable[(key+value[i]+len)%len].flag==)
break;
}
return sum;
}
}
void show(){
for(int i=;i<len-;i++){
if(hashtable[i].flag!=){
cout<<hashtable[i].data<<" ";
}
else
cout<<"NULL ";
}
if(hashtable[len-].flag!=){
cout<<hashtable[len-].data<<endl;
}
else
cout<<"NULL"<<endl; for(int i=;i<len;i++)
cout<<hashtable[i].flag<<" ";
cout<<endl;
} void deleteData(int num){
int key = find(num);
if(key!=-){
if(hashtable[key-].flag!=){
hashtable[key-].flag=;
}
}
}
}; int main(){
int n,m;
cin>>m>>n;
Hash *hash = new Hash(m);
int a[];
for(int i=;i<n;i++){
cin>>a[i];
hash->insert(a[i]);
}
hash->show();
//查找
cin>>n;
for(int i=;i<n;i++){
cin>>a[i];
if(hash->find(a[i])!=-){
cout<<<<" "<<hash->getSum(a[i])<<" "<<hash->find(a[i])<<endl;
}
else
cout<<<<" "<<hash->getSum(a[i])<<endl;
}
//删除
cin>>n;
for(int i=;i<n;i++){
cin>>a[i];
hash->deleteData(a[i]);
hash->show();
}
}
样例输入(不包括新加的删除样例):
样例输出:
哈希的就先到这里,那些高端操作拜拜了您下次再看。
DS-哈希表浅析的更多相关文章
- 操作系统 之 哈希表 Linux 内核 应用浅析
1.基本概念 散列表(Hash table.也叫哈希表).是依据关键码值(Key value)而直接进行訪问的数据结构. 也就是说,它通过把关键码值映射到表中一个位置来訪问记录.以 ...
- 【点分治】【map】【哈希表】hdu4670 Cube number on a tree
求树上点权积为立方数的路径数. 显然,分解质因数后,若所有的质因子出现的次数都%3==0,则该数是立方数. 于是在模意义下暴力统计即可. 当然,为了不MLE/TLE,我们不能存一个30长度的数组,而要 ...
- [PHP内核探索]PHP中的哈希表
在PHP内核中,其中一个很重要的数据结构就是HashTable.我们常用的数组,在内核中就是用HashTable来实现.那么,PHP的HashTable是怎么实现的呢?最近在看HashTable的数据 ...
- Java 哈希表运用-LeetCode 1 Two Sum
Given an array of integers, find two numbers such that they add up to a specific target number. The ...
- ELF Format 笔记(十五)—— 符号哈希表
ilocker:关注 Android 安全(新手) QQ: 2597294287 符号哈希表用于支援符号表的访问,能够提高符号搜索速度. 下表用于解释该哈希表的组织,但该格式并不属于 ELF 规范. ...
- Java基础知识笔记(一:修饰词、向量、哈希表)
一.Java语言的特点(养成经常查看Java在线帮助文档的习惯) (1)简单性:Java语言是在C和C++计算机语言的基础上进行简化和改进的一种新型计算机语言.它去掉了C和C++最难正确应用的指针和最 ...
- 什么叫哈希表(Hash Table)
散列表(也叫哈希表),是根据关键码值直接进行访问的数据结构,也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度.这个映射函数叫做散列函数,存放记录的数组叫做散列表. - 数据结构 ...
- 【哈希表】CodeVs1230元素查找
一.写在前面 哈希表(Hash Table),又称散列表,是一种可以快速处理插入和查询操作的数据结构.哈希表体现着函数映射的思想,它将数据与其存储位置通过某种函数联系起来,其在查询时的高效性也体现在这 ...
- openssl lhash 数据结构哈希表
哈希表是一种数据结构,通过在记录的存储位置和它的关键字之间建立确定的对应关系,来快速查询表中的数据: openssl lhash.h 为我们提供了哈希表OPENSSL_LHASH 的相关接口,我们可以 ...
随机推荐
- python学习笔记(9):容器
一.容器 0.判断所有的容器是否为空,用if not xxx(容器名):来进行判断 1.list 列表 序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一 ...
- http请求中的Content-Length作用机制与分块chunked
httpclient-4.5.9.jar org.apache.http: auth 身份 client 端 conn 连接 cookie 本地 impl: 实现 exe ...
- 国内下载Flutter
出现镜像错误等现象属于源码包不全面,国内下载镜像添加环境变量. ①:Linux执行如下操作 export PUB_HOSTED_URL=https://pub.flutter-io.cn export ...
- node npm vue.js 笔记
cnpm 下载包的速度更快一些. 地址:http://npm.taobao.org/ 安装cnpm: npm install -g cnpm --registry=https://registry.n ...
- [译]深度学习(Yann LeCun)
深度学习 严恩·乐库 约书亚•本吉奥 杰弗里·希尔顿 摘要深度学习是计算模型,是由多个处理层学习多层次抽象表示的数据.这些方法极大地提高了语音识别.视觉识别.物体识别.目标检测和许多其他领域如药物 ...
- 脚本_使用awk提取linux主机参数
#!bin/bash#功能:使用awk提取Linux主机的参数信息,如内容剩余容量,根分区剩余容量,本机IP,本机能登录的用户个数,CPU负载.#作者:liusingbon#使用awk提取内存剩余容量 ...
- tf.cast()用法
把布尔类型转化成0和1类型,true是1,false是0反之,亦成立.
- php函数漏洞
1.ereg — 正则表达式匹配 此函数遇 %00 截断. <?php $a = $_GET['pwd']; var_dump(ereg ("^[0-9]+$", $a)); ...
- css3 动画实例
animation 动画 animation-duration 代码实例: <!DOCTYPE html> <html> <head> <meta chars ...
- Tarjan 复习小结
总算把这几个东西策清楚了. 在\(Tarjan\)算法里面,有两个时间戳非常重要,一个是\(dfn\),意为深度优先数,即代表访问顺序:一个是\(low\),意为通过反向边能到达的最小\(dfn\), ...