使用kibana构建各种图
1.3.1:建立索引
以下命令来为莎士比亚数据集设置 mapping(映射):
curl -XPUT http://hadoop01:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
';
索引index
这个参数可以控制字段应该怎样建索引,怎样查询。它有以下三个可用值:
· no: 不把此字段添加到索引中,也就是不建索引,此字段不可查询
· not_analyzed:将字段的原始值放入索引中,作为一个独立的term,它是除string字段以外的所有字段的默认值。
· analyzed:string字段的默认值,会先进行分析后,再把分析的term结果存入索引中
该 mapping(映射)指定了数据集下列特质 :
字段解释:
1. speaker 字段是不分析的字符串。在这个 filed(字段)中的字符串被视为一个单独的单元,即使在这个 fileld(字段)中有多个单词。
2. 这同样适用于 play_name 字段。
3. line_id 和 speech_number 字段是整数。
日志数据集需要映射,通过将 **geo_point**``类型应用于这些字段,将日志中的 latitude(纬度)/longitude(纬度)对标记为地理位置。
使用以下命令建立日志 geo_point mappig(映射):
curl -XPUT http://hadoop01:9200/logstash-2015.05.18 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';
curl -XPUT http://hadoop01:9200/logstash-2015.05.19 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';
curl -XPUT http://hadoop01:9200/logstash-2015.05.20 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';
1.3.2:导入数据
accounts(账目)数据集不需要任何 mapping(映射),所以在这一点上,我们已经准备好使用 Elasticsearch 的 bulk API 加载数据集,使用以下命令 :
curl -XPOST 'hadoop01:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
curl -XPOST 'hadoop01:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
curl -XPOST 'hadoop01:9200/_bulk?pretty' --data-binary @logs.jsonl
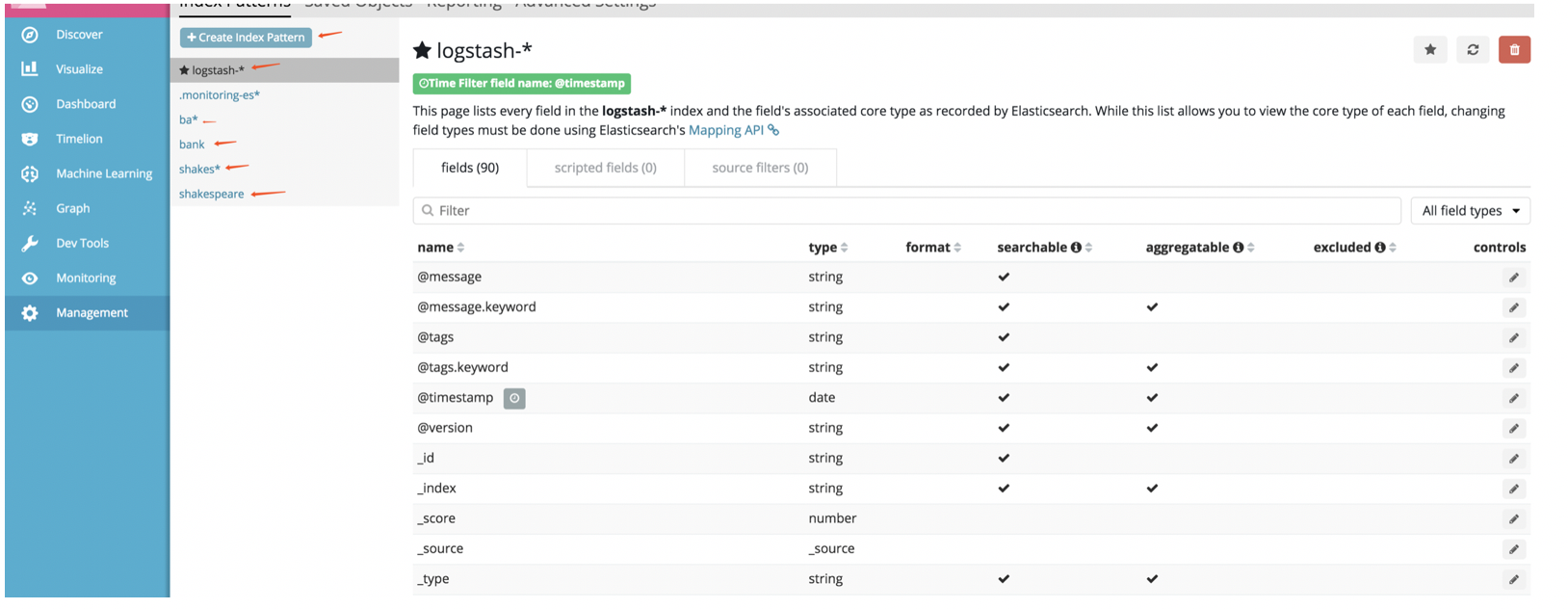
1.3.3:定义索引模式

使用create index Pattern创建一下索引:
Lostash-、ba、bank、shakes*、shakespeare
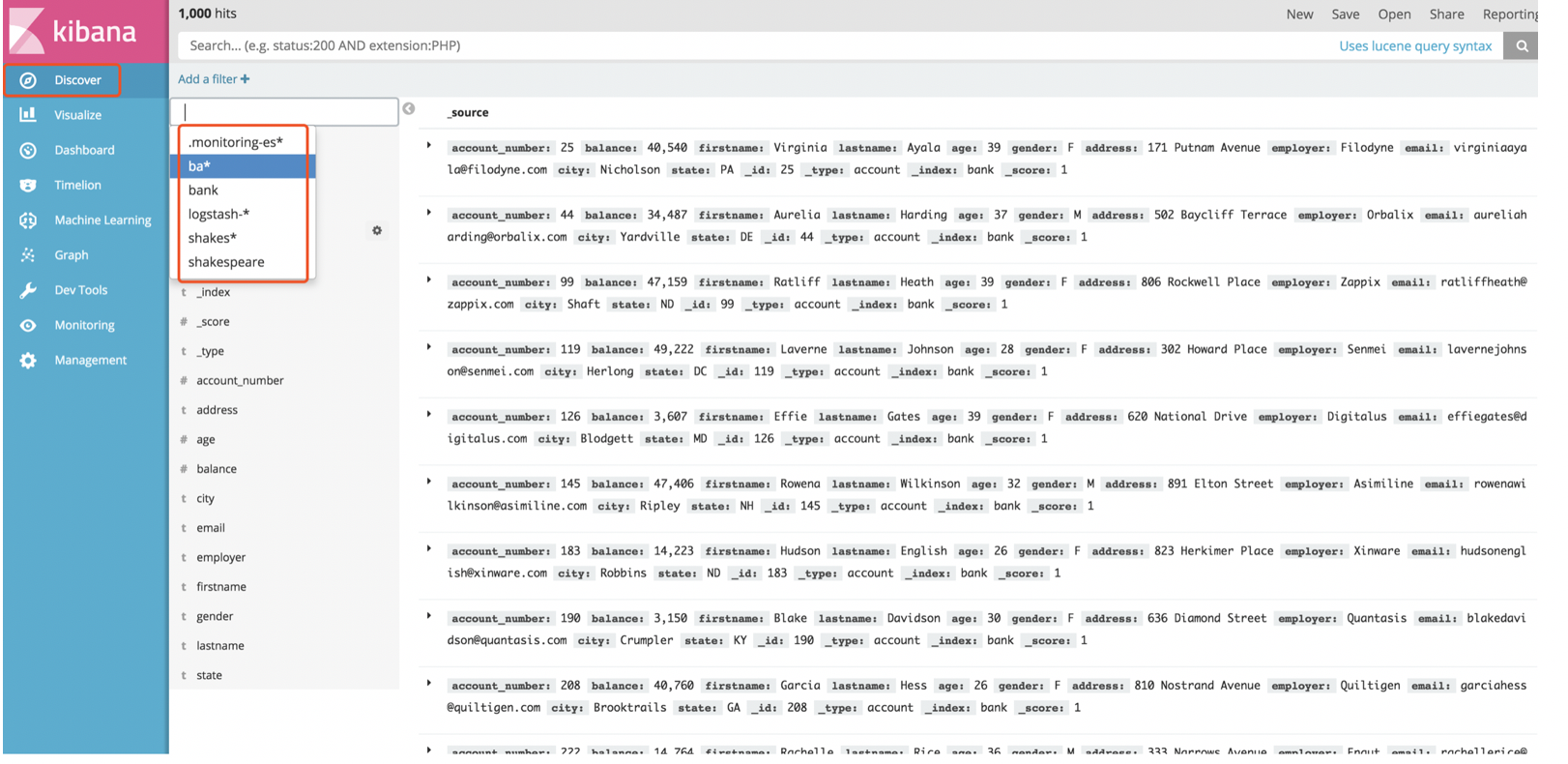
1.3.4:发现数据discover
1.3.5:可视化操作
1.3.5.1:创建饼图
1):步骤:Visualize--》create a visualization

2):选择饼图

选择bank:
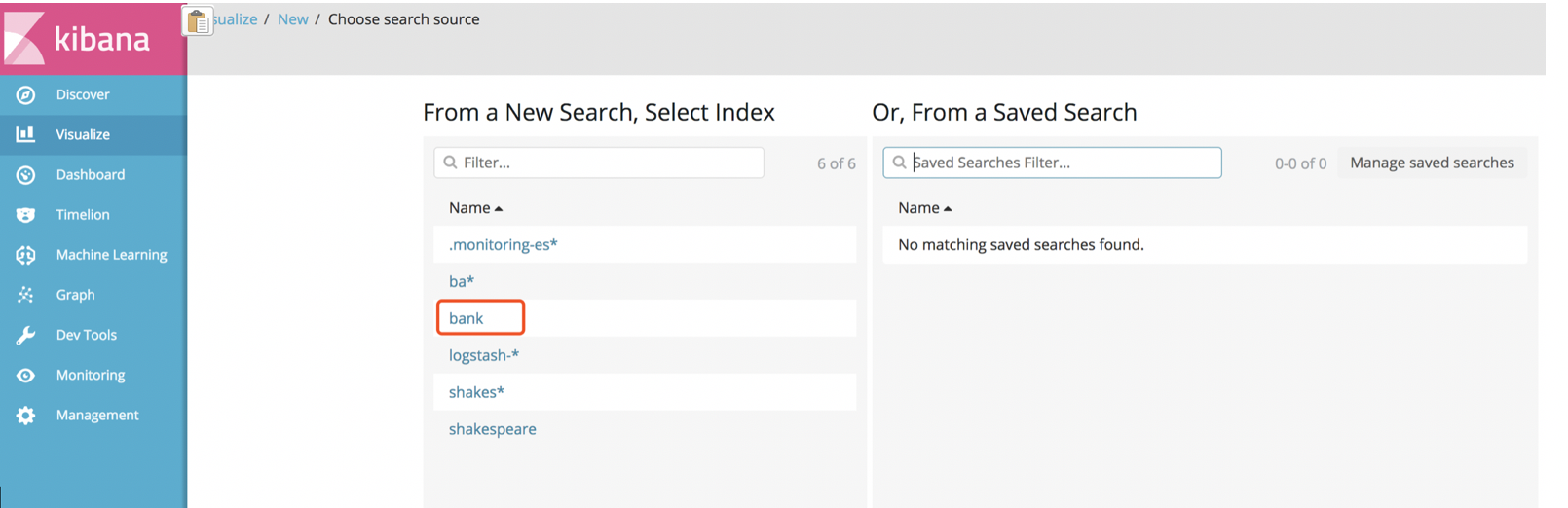
按照账户余额balance进行饼图的划分

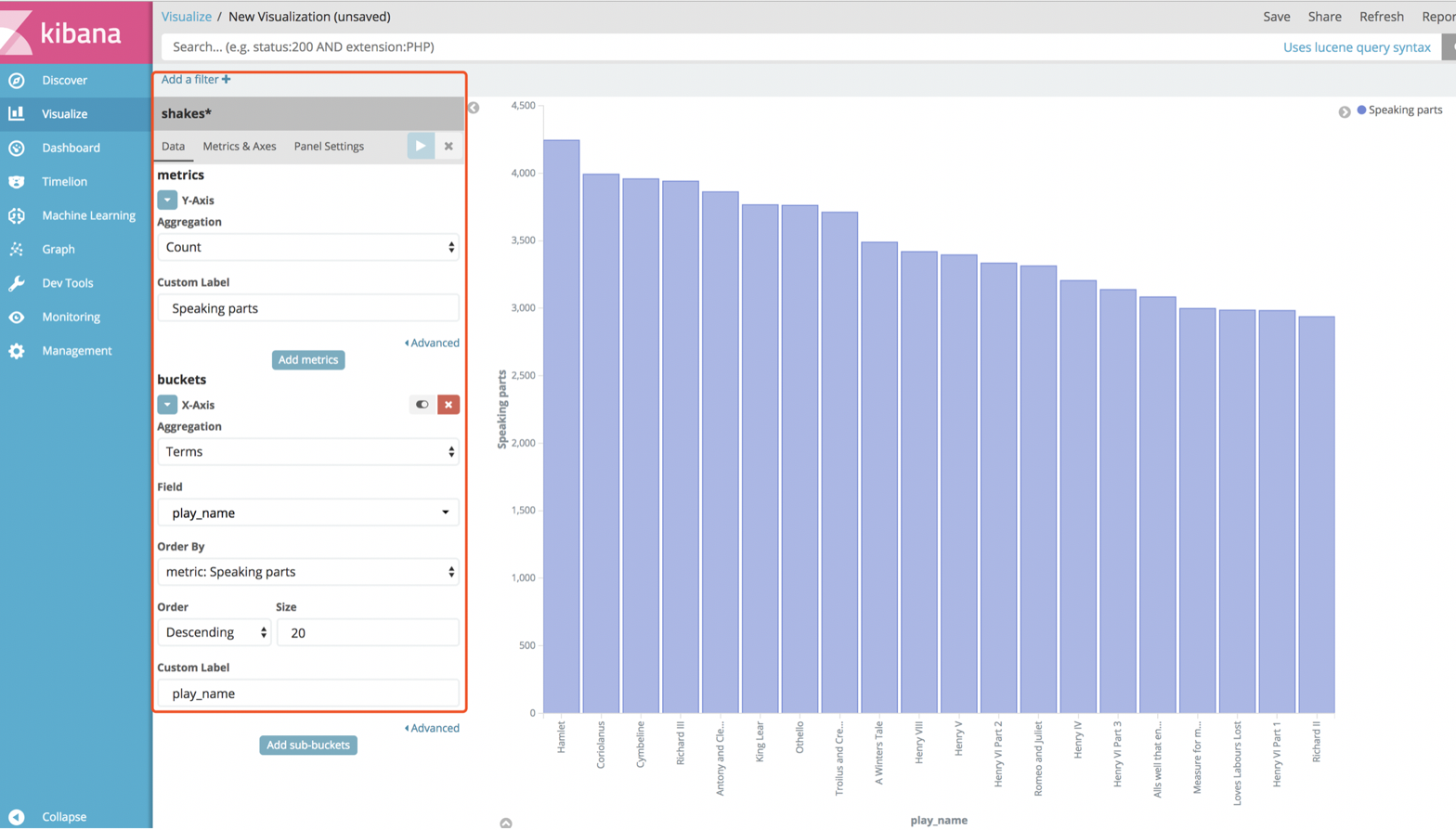
1.3.5.2:构建条形图
1):选择sharks*索引
2):展示每个演员的口语数量
1.3.5.3:构建地图
展示采集的数据中logstash日志文件中,用户的地理位置

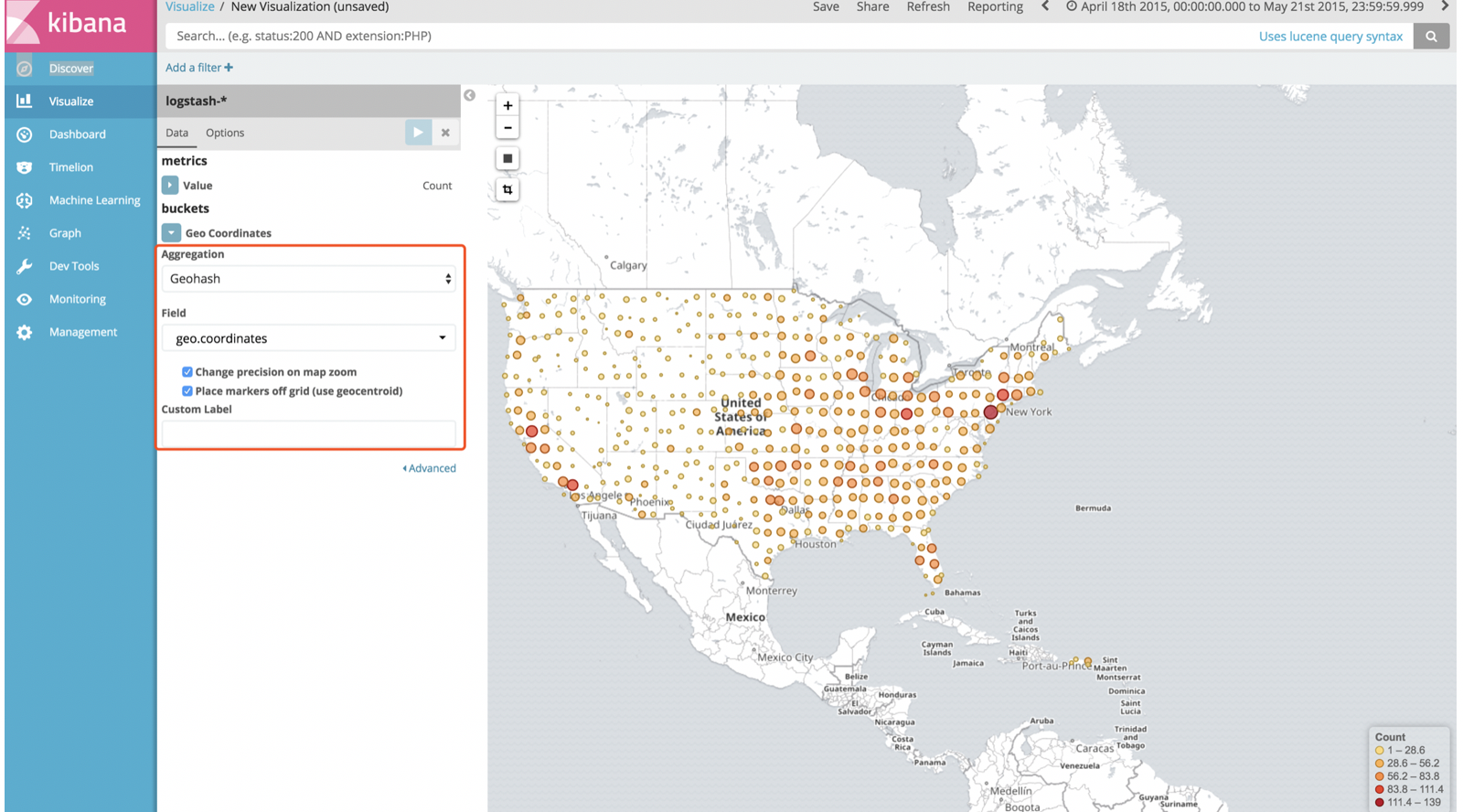
(其中的geo.coordinates是ip所在的经纬度)
使用kibana构建各种图的更多相关文章
- GitHub+PicGo构建免费图床及其高效使用
搭建免费图床全过程! 一.搭建缘由 一开始搭建博客,避免不了要用许多图片,最初使用七牛云来做博客图床,但是后来发现,七牛云只有30天的临时域名,hhhhhhh,果然啊,天下就没有免费的好事啊~后来就发 ...
- DS树+图综合练习--构建邻接表
题目描述 已知一有向图,构建该图对应的邻接表.邻接表包含数组和单链表两种数据结构,其中每个数组元素也是单链表的头结点,数组元素包含两个属性,属性一是顶点编号info,属性二是指针域next指向与它相连 ...
- CentOS7上安装配置破解Elasticsearch+Kibana 6.4.2-6.5.1全过程
最近正在学习服务器应用平台的搭建的相关知识.有幸从朋友与书上了解到Elastic套件的使用,我花了两天的时间把最新的套件部署在我的服务器上,中间踩了数不清的坑.我把整个过程都记录了下来与各位有需要的朋 ...
- 深入理解图优化与g2o:g2o篇
内容提要 讲完了优化的基本知识,我们来看一下g2o的结构.本篇将讨论g2o的代码结构,并带着大家一起写一个简单的双视图bundle adjustment:从两张图像中估计相机运动和特征点位置.你可以把 ...
- 利用 Rational ClearCase ClearMake 构建高性能的企业级构建环境
转载地址:http://www.ibm.com/developerworks/cn/rational/r-cn-clearmakebuild/ 构建管理是 IBM® Rational® ClearCa ...
- 深入理解图优化与g2o:图优化篇
前言 本节我们将深入介绍视觉slam中的主流优化方法——图优化(graph-based optimization).下一节中,介绍一下非常流行的图优化库:g2o. 关于g2o,我13年写过一个文档,然 ...
- 图像分割之(二)Graph Cut(图割)
zouxy09@qq.com http://blog.csdn.net/zouxy09 上一文对主要的分割方法做了一个概述.那下面我们对其中几个比较感兴趣的算法做个学习.下面主要是Graph Cut, ...
- 从 Java 代码逆向工程生成 UML 类图和序列图
from:http://blog.itpub.net/14780914/viewspace-588975/ 本文面向于那些软件架构师,设计师和开发人员,他们想使用 IBM® Rational® Sof ...
- 拉普拉斯特征图降维及其python实现
这种方法假设样本点在光滑的流形上,这一方法的计算数据的低维表达,局部近邻信息被最优的保存.以这种方式,可以得到一个能反映流形的几何结构的解. 步骤一:构建一个图G=(V,E),其中V={vi,i=1, ...
随机推荐
- String.equals()方法、整理String类的Length()、charAt()、 getChars()、replace()、 toUpperCase()、 toLowerCase()、trim()、toCharArray()
equals 是比较的两个字符串是否一样 length() 返回字符串的长度 charAt (int index) 返回index所指定的字符 getChars(int srcBegin,int sr ...
- @OneToMany 一对多 通过表之间的链接
https://blog.csdn.net/qq_38157516/article/details/80146547 一对多 一个人对多张卡,但是一张卡只能对应一个人,典型的一对多关系,下面就用One ...
- Codeforces Round #587 (Div. 3)
https://codeforces.com/contest/1216/problem/A A. Prefixes 题意大概就是每个偶数位置前面的ab数目要相等,很水,被自己坑了 1是没看见要输出修改 ...
- WTF!! Vue数组splice方法无法正常工作
当函数执行到this.agents.splice()时,我设置了断点.发现传参index是0,但是页面上的列表项对应的第一行数据没有被删除, WTF!!! 这是什么鬼!然后我打开Vue Devtool ...
- npm学习(九)之README.md文件
包括文档(readme.md) npm建议您包含一个readme文件来记录您的包.自述文件必须有文件名readme.md.文件扩展名.md表示该文件是一个标记(markdown)文件.当有人发现您的包 ...
- Hadoop基础概念
Apache Hadoop有2个核心的组件,他们分别是: HDFS: HDFS是一个分布式文件系统集群,它可以将大的文件分裂成块并将他们冗余地分布在多个节点上,HDFS是运行在用户空间的文件系统 Ma ...
- python模块导入总结
python模块导入总结 模块导入方式 定义test.py模块 def print_func(): print("hello") import 语句 导入模块语法 import m ...
- pycharm解释器链接如何pymongo
1.pymongo 链接数据库 # pycharm 链接我们的mogodb # 下载pymongo from pymongo import MongoClient # 客户端请求 服务端 # 链接 c ...
- Linux系统Tomcat进程使用shutdown无法关闭进程
问题场景: 若在应用中启动了用户线程,在Linux系统Tomcat进程使用shutdown无法关闭进程. 解决方案: #1.在catalina.sh文件中添加CATALINA_PID [root@lo ...
- Dubble 入门
Dubbo 01 架构模型 传统架构 All in One 测试麻烦,微小修改 全都得重新测 单体架构也称之为单体系统或者是单体应用.就是一种把系统中所有的功能.模块耦合在一个应用中的架构方式.其优点 ...