Spark-Core RDD依赖关系
scala> var rdd1 = sc.textFile("./words.txt")
rdd1: org.apache.spark.rdd.RDD[String] = ./words.txt MapPartitionsRDD[16] at textFile at <console>:24
scala> val rdd2 = rdd1.flatMap(_.split(" "))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at flatMap at <console>:26
scala> val rdd3 = rdd2.map((_, 1))
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[18] at map at <console>:28
scala> val rdd4 = rdd3.reduceByKey(_ + _)
rdd4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[19] at reduceByKey at <console>:30
1、查看 RDD 的血缘关系
scala> rdd1.toDebugString
res1: String =
(2) ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd2.toDebugString
res2: String =
(2) MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd3.toDebugString
res3: String =
(2) MapPartitionsRDD[3] at map at <console>:28 []
| MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd4.toDebugString
res4: String =
(2) ShuffledRDD[4] at reduceByKey at <console>:30 []
+-(2) MapPartitionsRDD[3] at map at <console>:28 []
| MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
说明:
圆括号(2): 2表示RDD的并行度,几个分区
2、查看RDD的依赖关系
scala> rdd1.dependencies
res28: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@70dbde75)
scala> rdd2.dependencies
res29: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@21a87972)
scala> rdd3.dependencies
res30: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@4776f6af)
scala> rdd4.dependencies
res31: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@4809035f)
RDD之间的关系可以从两个维度来理解:
(1)一个是RDD从哪些RDD转换而来,也就是RDD的parent RDD(s)是什么
(2)另一个是RDD依赖于parent RDD(s)的哪些 Partitions(s),这种关系称为RDD之间的依赖
RDD依赖的 2 中策略:
(1)窄依赖(transformations with narrow dependencies)
(2)宽依赖(transformations with wide dependencies)
宽依赖对 Spark 去评估一个 transformations 有更加重要的影响, 比如对性能的影响.
3、窄依赖
如果 B-RDD 是由 A-RDD 计算得到的, 则 B-RDD 就是Child RDD, A-RDD 就是 parent RDD.
如果依赖关系在设计的时候就可以确定,而不需要考虑父RDD分区中的记录。并且如果父RDD中的每个分区最多只有一个分区,这样的依赖就是窄依赖
总结:父RDD的每个分区最多被一个RDD的分区使用
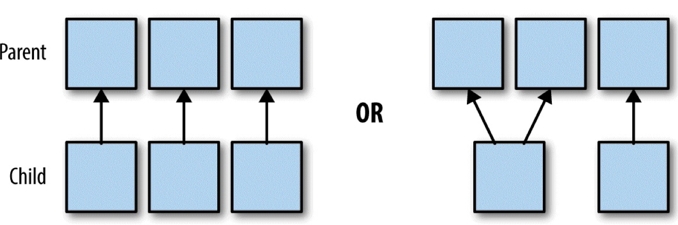
具体来说,窄依赖的时候,子RDD中的分区要么只依赖一个父RDD中的一个分区(map,filter),要么在设计的时候就能确定子RDD是父RDD的一个子集(coalesce)
所以, 窄依赖的转换可以在任何的的一个分区上单独执行, 而不需要其他分区的任何信息.
4、宽依赖
如果 父 RDD 的分区被不止一个子 RDD 的分区依赖, 就是宽依赖.
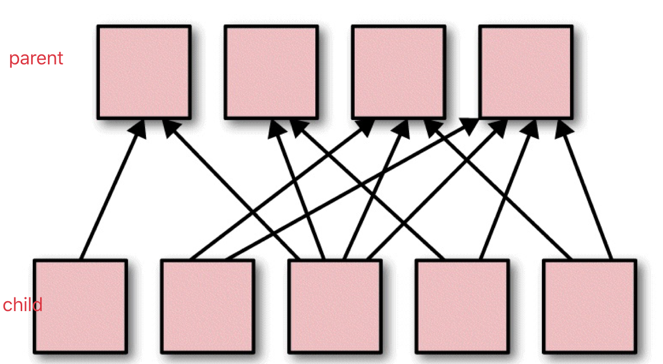
宽依赖工作的时候, 不能随意在某些记录上运行, 而是需要使用特殊的方式(比如按照 key)来获取分区中的所有数据.
例如: 在排序(sort)的时候, 数据必须被分区, 同样范围的 key 必须在同一个分区内. 具有宽依赖的 transformations 包括: sort, reduceByKey, groupByKey, join, 和调用rePartition函数的任何操作.
Spark-Core RDD依赖关系的更多相关文章
- Spark之RDD依赖关系及DAG逻辑视图
RDD依赖关系为成两种:窄依赖(Narrow Dependency).宽依赖(Shuffle Dependency).窄依赖表示每个父RDD中的Partition最多被子RDD的一个Partition ...
- RDD算子、RDD依赖关系
RDD:弹性分布式数据集, 是分布式内存的一个抽象概念 RDD:1.一个分区的集合, 2.是计算每个分区的函数 , 3.RDD之间有依赖关系 4.一个对于key-value的RDD的Partit ...
- (摘)使用 .NET Core 实现依赖关系注入
为什么使用依赖关系注入? 使用 .NET,通过 new 运算符(即,new MyService 或任何想要实例化的对象类型)调用构造函数即可轻松实现对象实例化.遗憾的是,此类调用会强制实施客户端(或应 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- Spark之RDD的定义及五大特性
RDD是分布式内存的一个抽象概念,是一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,能横跨集群所有节点并行计算,是一种基于工作集的应用抽象. RDD底层存储原理:其数据分布存储于多台机器上 ...
- Spark之RDD
Spark学习之路Spark之RDD 目录 一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数 ...
随机推荐
- pyqt5--动画
动画类别继承结构图 天子骄龙
- pyqt5-复合控件中的子控件
天子骄龙
- Quartz.NET常用方法 01
Quartz.NET作为一款定时框架,它的最小可运行程序如下: var scheduler = StdSchedulerFactory.GetDefaultScheduler(); scheduler ...
- 容器内安装nvidia,cuda,cudnn
/var/lib/docker/overlay2 占用很大,清理Docker占用的磁盘空间,迁移 /var/lib/docker 目录 du -hs /var/lib/docker/ 命令查看磁盘使用 ...
- luogu 4927 [1007]梦美与线段树 概率与期望 + 线段树
考场上切了不考虑没有逆元的情况(出题人真良心). 把概率都乘到一起后发现求的就是线段树上每个节点保存的权值和的平方的和. 这个的修改和查询都可以通过打标记来实现. 考场代码: #include < ...
- Python黑科技 | Python中四种运行其他程序的方式
在Python中,可以方便地使用os模块来运行其他脚本或者程序,这样就可以在脚本中直接使用其他脚本或程序提供的功能,而不必再次编写实现该功能的代码.为了更好地控制运行的进程,可以使用win32proc ...
- Android图片缩放 指定尺寸
//使用Bitmap加Matrix来缩放 public static Drawable resizeImage(Bitmap bitmap, int w, int h) { ...
- zabbix配置通过远程命令来发送邮件
1.安装好zabbix后,在/var/log/zabbix可以查看日志. 2.主机通过zabbix-get检查 yum install zabbix-get -y zabbix-get -s 客户主 ...
- spring boot redis session
1. pom.xml 这里 spring parent的版本 2.1.5会报错 2.1.0和2.1.4经过测试正常 <?xml version="1.0" encoding= ...
- DjangoRestFrameWork 版本控制
DRF的版本控制 为什么需要版本控制 API 版本控制允许我们在不同的客户端之间更改行为(同一个接口的不同版本会返回不同的数据). DRF提供了许多不同的版本控制方案. 可能会有一些客户端因为某些原因 ...