sciencedirect 网站抓取过程
开发环境
C#+SQLite
软件使用教程:
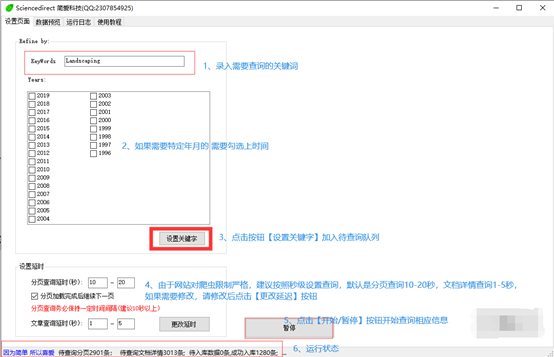
设置页面
1、 首先录入需要查询的关键词,如果需要根据年去查询,可以勾选对应的年,支持多个年份查询。点击【设置关键字】按钮,把待查询关键字加入查询队列。
2、 根据需要修改分页延时和文章查询延时信息,修改后点击【更改延时】按钮生效。
3、 点击【开始/暂停】按钮控制查询操作。
4、 最下方显示待查询的分页数、待查询文章数量、待入库数据数量和已入库数据数量。

运行日志
执行的每一步操作都会有相应的文件描述显示在日志中,包括查询分页、查询文档、运行出错、数据入库、数据校验等所有的日志信息。
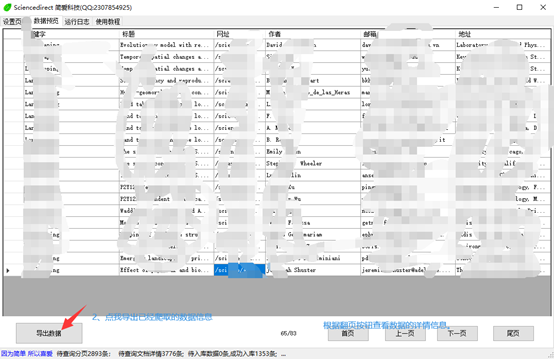
数据预览
所有的数据都会实时存储到SQLite数据库中,数据会永久保存。数据预览主要功能就是分页查询、数据导出功能。
如果不需要该数据后可以删除软件目录下的data.db文件。
开发过程中的问题汇总
数据抓取
所有爬虫的难点从来不是技术,而是网站的数据分析,表面看到的数据可能与想象中的显示有区别。比如文章详情的作者信息等就是通过js处理Json格式数据展示的。为了找到具体的数据需要解析整个Json数据。
Json数据也不是最难得,分析Json数据才是最难得。
KeyValue格式的数据Key=“$”/”$$”/”_”/”Get-Text”等等,总之C#怎么不兼容怎么来。
针对上述数据我能想到的有2中解决方案:
1、 对所有的数据遍历 key/value,然后根据key对应的name或者value的值进行匹配然后获取数据信息。
2、 由于dynamic支持动态类型,所以只要key可以作为变量就能根据名字写死处理。为了能拿到符合规则的名字,只好Replace。
我是不是很聪明,哈哈。
关于IP限制
限制IP无疑是一个很好的手段,针对IP限制,只能放缓查询速度。
再次我通过简单的随机时间访问和访问完一个网页后在访问下一个网页的办法来防止IP被封。
关于网站未来
为了更好的适应网站的查询条件,比如年,会显示从1996年到当前时间的年份。
运行日志
为了更明显的显示日志信息,把执行成功的标记为蓝色,失败的标记为红色。
关于Dapper
刚刚接触Dapper的时候,把他当作一个完美的DbHelper使用的。后来发现无论是事务、确认数据是否存在、先查后插入都需要自己去完整,我心目中的完美Dapper啊

不过SQLite还是比SQLServer有好的地方的,
比如Create Table If Not Exists TableName
比如 Replace Into 减少了很多代码量
数据导出
导出数据到Excel,NPOI永远是利器。
待处理问题
数据中如果存在上下标,还不知道怎么处理和保存。万能的百度没有帮到我,Unicode中不知道a的上标是什么,下标也没有成功显示。求大神们指点…

sciencedirect 网站抓取过程的更多相关文章
- Nutch学习笔记二——抓取过程简析
在上篇学习笔记中http://www.cnblogs.com/huligong1234/p/3464371.html 主要记录Nutch安装及简单运行的过程. 笔记中 通过配置抓取地址http://b ...
- [转]使用Scrapy建立一个网站抓取器
英文原文:Build a Website Crawler based upon Scrapy 标签: Scrapy Python 209人收藏此文章, 我要收藏renwofei423 推荐于 11个月 ...
- 解决Jsoup网页抓取过程中需要cookie的问题
最近在做城觅网的信息抓取,发现城觅网上海与北京的url是一样的.那怎样才确定信息的来源呢?折腾了半天,才发现城觅网是使用cookie的,如果你把网站的cookie禁用了,就无法在上海与北京之间切换了. ...
- PHP登入网站抓取并且抓取数据
有时候需要登入网站,然后去抓取一些有用的信息,人工做的话,太累了.有的人可以很快的做到登入,但是需要在登入后再去访问其他页面始终都访问不了,因为他们没有带Cookie进去而被当做是两次会话.下面看看代 ...
- Nutch2.1+mysql+solr3.6.1+中文网站抓取
1.mysql 数据库配置 linux mysql安装步骤省略. 在首先进入/etc/my.cnf (mysql为5.1的话就不用修改my.cnf,会导致mysql不能启动)在[mysqld] 下添加 ...
- wget整站抓取、网站抓取功能;下载整个网站;下载网站到本地
wget -r -p -np -k -E http://www.xxx.com 抓取整站 wget -l 1 -p -np -k http://www.xxx.com 抓取第一级 - ...
- c#使用WebClient登录网站抓取登录后的网页
C#登录网站实际上就是模拟浏览器提交表单,然后记录浏览器响应返回的会话Cookie值,再次发送请求时带着这个会话cookie值去请求就可以实现模拟登录的效果了. 如下类CookieAwareWebCl ...
- pythonのscrapy抓取网站数据
(1)安装Scrapy环境 步骤请参考:https://blog.csdn.net/c406495762/article/details/60156205 需要注意的是,安装的时候需要根据自己的pyt ...
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
随机推荐
- Django学习——开发你的第一个Django应用2
接着上一节的内容来说.我们将继续关注与上一节制作的polls应用以及Django自动产生额度管理网站. 产生一个管理员用户 首先我们需要产生一个管理员用户,运行如下命令: python manage. ...
- Docker Swanm集群配置
首先 可以用ContOS虚拟机 克隆 5个虚拟机,注意(克隆主机必须装了Docker,克隆后,克隆机都会有Docker) 配置 网络 克隆CentOS虚拟机 最后和到如下结果 打开2377端口 ...
- rpc - rpc 程序号数据库
SYNOPSIS /etc/rpc DESCRIPTION rpc 文件列出了rpc 程序的可读名, 可以此代替rpc 程序号. 每行包含如下信息: 运行rpc 程序的服务名 rpc 程序号 别名 各 ...
- 关于javascript提交到java后台空格去不掉ASCII为160的解决办法
今天正则表达式匹配一个字符串,怎么都不对. 用正则表达式去掉尝试str.replaceAll("\\s*",""); 在或者用replaceAll(" ...
- go语言从例子开始之Example30.通道遍历
在前面的例子中,我们讲过 for 和 range为基本的数据结构提供了迭代的功能.我们也可以使用这个语法来遍历从通道中取得的值 Example: package main import "f ...
- linux的iptables设置---防火墙
1.首先介绍一下指令和相关配置文件 启动指令:service iptables start 重启指令:service iptables restart 关闭指令:service iptables st ...
- 【Leetcode周赛】从contest-81开始。(一般是10个contest写一篇文章)
Contest 81 (2018年11月8日,周四,凌晨) 链接:https://leetcode.com/contest/weekly-contest-81 比赛情况记录:结果:3/4, ranki ...
- html5 图片360旋转
test.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- IBM研究人员开发了一对低功耗,高性能的计算机视觉系统
机器学习算法近年来有了突飞猛进的发展.例如,像Facebook这样的最先进的系统,可以在一小时内训练图像分类算法,而不会牺牲准确性.但是,许多这些系统都是在具有强大GPU的高端机器上进行培训的,随着物 ...
- Java类加载顺序练习题
一.题目 public class Test { public static Test t1 = new Test();// 标记1 // 普通代码块 { System.out.println(&qu ...