利用 pandas 进行数据的预处理——离散数据哑编码、连续数据标准化
数据的标准化
数据标准化就是将不同取值范围的数据,在保留各自数据相对大小顺序不变的情况下,整体映射到一个固定的区间中。根据具体的实现方法不同,有的时候会映射到 [ 0 ,1 ],有时映射到 0 附近的一个较小区间内。
这样做的目的是消除数据不同取值范围带来的干扰。
数据标准化的方法,我在这里介绍两种
- min-max标准化
min-man 标准化会把结果映射到 0 与 1 之间,下面是映射的公式。
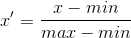
min 是整个样本的最小值,max是整个样本的最大值
- Z-score标准化
Z-score会把结果映射到 0 附近,并服从标准正态分布(平均值为 0,标准差为1),下面是映射的公式
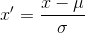
μ 是样本的平均值,σ 是样本的标准差,这些在python中都有函数支持,不用担心计算的问题。
数据的哑编码
哑编码是处理离散型数据的手段。离散型数据的取值范围是有限的(严格在数学上的定义中,无限但可数也就是 countably infinite 的取值空间也属于离散型,但在实际问题中不会碰到,这里不作考虑),比如说星期几就是一个离散型数据,因为一周只有七天,也就只有七种可能的取值。在处理这样的数据的时候,哑编码会把一列数据转换成多列,有多少中可能的取值就转换成多少列。在刚刚提到的星期几的例子中,哑编码会把这一列数据转换成七列数据。
那具体是如何转换的呢?
还是从星期几的例子开始讲
| 编号 | 星期几 |
| 0 | 星期二 |
| 1 | 星期一 |
| 2 | 星期五 |
| 3 | 星期日 |
| 4 | 星期三 |
| 5 | 星期六 |
| 6 | 星期四 |
| 7 | 星期日 |
| 8 | 星期二 |
| 9 | 星期四 |
假设我们有这样的十条数据,现在数据除了编号以外只有一个字段——“星期几”。
哑编码会讲这一个字段扩展成七个字段,也就是七列,每一个新的字段代表原来字段的一种取值,现在表格变成了
| 编号 | 星期几 | 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | 星期六 | 星期日 |
| 0 | 星期二 | |||||||
| 1 | 星期一 | |||||||
| 2 | 星期五 | |||||||
| 3 | 星期日 | |||||||
| 4 | 星期三 | |||||||
| 5 | 星期六 | |||||||
| 6 | 星期四 | |||||||
| 7 | 星期日 | |||||||
| 8 | 星期二 | |||||||
| 9 | 星期四 |
那如何表示原来的数据呢?很简单,如果编号0的数据是星期一,那么在星期一这个字段上的数值是1,在其他所有字段上都是0,现在数据变成了这样
| 编号 | 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | 星期六 | 星期日 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 8 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 |
最后再删去原来的字段,大功告成!
pandas
我们一会儿会用python里的pandas来处理数据,所以这里先简单介绍一下我们一会儿会用到的知识。
- dataframe
简单的理解,dataframe就是一张二维表,和上面例子中关于星期几的表格完全一样。
我们可以通过行号和列明的方式定位表中的某一个元素,dataframe也是这样。
假设我们有一个变量叫df,它是一个dataframe
df[0] # 访问第0行元素
df['column_name'] # 访问列名为 column_name 的一列数据
df.loc[0,'column_name'] # 访问第0行列名为 column_name 的元素
- dtype
dtype是 dataframe中每一列的数据类型,常用的有 float32 float64 int32 int16 等等
可以通过 dtypes 或 dtype 访问数据类型
df.dtypes # 所有列的数据类型
df['column_name'].dtype # 列名为 column_name 的数据类型
数据类型可以通过 astype 函数更改
df["column_name"] = df["column_name"].astype(np.int16) # 讲列名为 column_name 的列的数据类型改为 np.int16
数据标准化的代码实现
下面就是代码实现部分了,我会把我写整个代码的思路一点点的剖析开
首先当然是将要用到的包导入了
import pandas as pd
import numpy as np
上面提到了两种实现方式,但为了便于使用,我不想写两个函数,我希望只暴露给用户一个函数,将这两种实现方法融合在一起。
具体来说,就是用一个参数来确定用户本次调用的到底是哪种实现方式,并可以通过给出参数默认值的方式给出默认实现方式。
def normalize(data, columns, function='min-max'):
if function == 'min-max':
return min_max_scalar(data, columns)
elif function == 'standard':
return standard_scalar(data, columns)
else:
raise ValueError("invalid parameter: function must be 'min-max' or 'standard'.") def min_max_scalar(data, columns):
pass def standard_scalar(data, columns):
pass
- data : 代表需要处理的数据表格,类型是 dataframe
- columns :代表需要处理的列的列明的集合,类型是 list,其中每个元素应该是字符串或是可以转换成字符串
- function :具体指定实现方式,默认为 min-max 标准化
整体的思路就是判断一下function的数值,然后调用相应的函数
现在整个函数的框架搭起来了,接下来的就是具体实现 min_max_scalar(data, columns) 和 standard_scalar(data, columns) 两个函数了
先来实现 min_max_scalar(data, columns)
def min_max_scalar(data, columns):
for column in columns:
maxi = max(data[column])
mini = min(data[column])
if maxi == mini:
raise ValueError("invalid parameter value: maximum element equals to minimum element in the '" + column + "' column.")
else:
diff = maxi - mini
data[column] = ( data[column] - mini ) / diff
return data
很简单吧?不过一定要随时记得处理异常,在这种实现方式中,如果数据的最大值最小值相同,就会造成 ZeroDivisionError 这个异常,所以我们单独判断,处理了一下这种情况。
然后我们实现 standard_scalar(data, columns)
def standard_scalar(data, columns):
for column in columns:
std = np.std(data[column])
if std == 0:
raise ValueError("invalid parameter: standard deviation is 0 in the '" + column + "' column.")
else:
mean = sum(data[column]) / len(data[column])
data[column] = ( data[column] - mean ) / std
return data
这里处理了一下标准差为零的异常情况
图省事的同学就可以往下看哑编码部分的代码了,不过,如果你想让你的函数更加 robust,我们还得加入大量的异常处理代码
我们需要做哪些异常处理?
- 判断 data 的数据类型是否是 dataframe?
- columns 的数据类型是否是list,或者是否能转换成list?
- columns 中每个元素是不是字符串,或者是否能转换成字符串?
- columns 中每个元素代表的列是否真的存在?
- 如果存在,这个列的数据是数值类型的数据么?
- function 是一个字符串么?
- 如果是,那这个字符串是否是 ‘min-max’ 或 ‘standard’ 二者之一么?
直接看代码吧
def normalize(data, columns, function='min-max'):
if type(data) != pd.core.frame.DataFrame:
raise TypeError("invalid parameter: data must be a dataframe.") try:
columns = list(columns)
except TypeError:
raise TypeError("invalid parameter: columns must be a list or can be converted to a list.") try:
for counter in range(len(columns)):
columns[counter] = str(columns[counter])
except TypeError:
raise TypeError("invalid parameter: each column element in columns should be a string or can be converted to a string.") for column in columns:
if column not in data.columns:
raise ValueError("invalid parameter: column '" + column + "' doesn't exist.") is_int = data[column].dtype == np.int8 or data[column].dtype == np.int16 or data[column].dtype == np.int32 or data[column].dtype == np.int64
is_uint = data[column].dtype == np.uint8 or data[column].dtype == np.uint16 or data[column].dtype == np.uint32 or data[column].dtype == np.uint64
is_float = data[column].dtype == np.float16 or data[column].dtype == np.float32 or data[column].dtype == np.float64
if is_int or is_uint or is_float:
data[column] = data[column].astype(np.float64)
else:
raise TypeError("invalid parameter: values in column '" + column + "' should be numbers ") try:
function = str(function)
except TypeError:
raise TypeError("invalid parameter: function must be a string or can be converted to a string.") if function == 'min-max':
return min_max_scalar(data, columns)
elif function == 'standard':
return standard_scalar(data, columns)
else:
raise ValueError("invalid parameter: function must be 'min-max' or 'standard'.")
是不是懵逼了?这异常处理代码写出来比主程序还长 orz~
数据哑编码的代码实现
还是先把大致的框架搭起来
def one_hot_encoder(data, columns):
# 异常处理
pass
# 处理数据
data 和 columns 的含义与上文相同,不再赘述。
这次我们先来处理异常,我们需要考虑
- 判断 data 的数据类型是否是 dataframe?
- columns 的数据类型是否是list,或者是否能转换成list?
- columns 中每个元素是不是字符串,或者是否能转换成字符串?
- columns 中有没有重复的元素?
- columns 中每个元素代表的列是否真的存在?
- columns 中每个元素代表的列的数据是否是字符串,或者是否能转换成字符串?
下面看代码~
def one_hot_encoder(data, columns):
# 异常处理
if type(data) != pd.core.frame.DataFrame:
raise TypeError("invalid parameter: data must be a dataframe.") try:
columns = list(columns)
except TypeError:
raise TypeError("invalid parameter: columns must be a list or can be converted to a list.") try:
for counter in range(len(columns)):
columns[counter] = str(columns[counter])
except TypeError:
raise TypeError("invalid parameter: each element in columns should be a string or can be converted to a string.")
columns = np.unique(columns) # rule out duplicate column name to avoid error for column in columns:
if column not in data.columns:
raise ValueError("invalid parameter: column '" + column + "' doesn't exist.")
try:
data[column] =data[column].astype(str)
except Exception:
raise TypeError("invalid parameter: value in '" + column + "' must be a string or can be converted to a string.") # 处理数据
return help_encoder(data, columns)
我把处理数据的部分写到 help_encoder(data, columns) 函数中了,这里只做调用
接下来就剩下下最后一步,处理数据了,相比于数据标准化,这块的代码稍微复杂一点,需要细心点看。
def help_encoder(data, columns):
for column in columns:
unique_values = np.unique(data[column])
sub_column_names = []
for unique_value in unique_values:
sub_column_names.append(column + '_' + unique_value)
# insert new columns
for sub_column_counter in range(len(sub_column_names)):
data[sub_column_names[sub_column_counter]] = -1
for data_counter in range(len(data)):
data.loc[data_counter, sub_column_names[sub_column_counter]] = int(data[column][data_counter] == unique_values[sub_column_counter])
# remove old columns
del data[column] return data
最后我们测试一下哑编码部分的代码
data = pd.DataFrame([['A'], ['B'], ['C'], ['D'], ['A'], ['E']] ,columns=list('A')) # 创建 dataframe
print('哑编码之前')
print(data)
one_hot_encoder(data, ['A']) #进行哑编码处理
print('哑编码之后')
print(data)
运行结果
哑编码之前
A
0 A
1 B
2 C
3 D
4 A
5 E
哑编码之后
A_A A_B A_C A_D A_E
0 1 0 0 0 0
1 0 1 0 0 0
2 0 0 1 0 0
3 0 0 0 1 0
4 1 0 0 0 0
5 0 0 0 0 1
[Finished in 1.5s]
大功告成!
利用 pandas 进行数据的预处理——离散数据哑编码、连续数据标准化的更多相关文章
- Python利用pandas处理Excel数据的应用
Python利用pandas处理Excel数据的应用 最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做 ...
- 利用pandas库中的read_html方法快速抓取网页中常见的表格型数据
本文转载自:https://www.makcyun.top/web_scraping_withpython2.html 需要学习的地方: (1)read_html的用法 作用:快速获取在html中页面 ...
- (数据科学学习手札63)利用pandas读写HDF5文件
一.简介 HDF5(Hierarchical Data Formal)是用于存储大规模数值数据的较为理想的存储格式,文件后缀名为h5,存储读取速度非常快,且可在文件内部按照明确的层次存储数据,同一个H ...
- 浅谈python之利用pandas和openpyxl读取excel数据
在自学到接口自动化测试时, 发现要从excel中读取测试用例的数据, 假如我的数据是这样的: 最好是每行数据对应着一条测试用例, 为方便取值, 我选择使用pandas库, 先安装 pip instal ...
- 利用 pandas库读取excel表格数据
利用 pandas库读取excel表格数据 初入IT行业,愿与大家一起学习,共同进步,有问题请指出!! 还在为数据读取而头疼呢,请看下方简洁介绍: 数据来源为国家统计局网站下载: 具体方法 代码: i ...
- python-数据描述与分析2(利用Pandas处理数据 缺失值的处理 数据库的使用)
2.利用Pandas处理数据2.1 汇总计算当我们知道如何加载数据后,接下来就是如何处理数据,虽然之前的赋值计算也是一种计算,但是如果Pandas的作用就停留在此,那我们也许只是看到了它的冰山一角,它 ...
- Amazon评论数据的预处理代码(Positive & Negative)
Amazon评论数据的预处理代码,用于情感分析,代码改自 https://github.com/PaddlePaddle/Paddle/tree/develop/demo/quick_start/da ...
- 利用pandas读取Excel表格,用matplotlib.pyplot绘制直方图、折线图、饼图
利用pandas读取Excel表格,用matplotlib.pyplot绘制直方图.折线图.饼图 数据: 折线图代码: import pandas as pdimport matplotlib. ...
- pandas 学习 第14篇:索引和选择数据
数据框和序列结构中都有轴标签,轴标签的信息存储在Index对象中,轴标签的最重要的作用是: 唯一标识数据,用于定位数据 用于数据对齐 获取和设置数据集的子集. 本文重点关注如何对序列(Series)和 ...
随机推荐
- css常用属性2
1 浮动和清除浮动 在上篇的第十一节--定位中说道: CSS 有三种基本的定位机制:普通流.浮动和绝对定位. 普通流和绝对定位已经说完,接下来就是浮动了. 什么是浮动? CSS 的 Float(浮动 ...
- AngularJS–Animations(动画)
点击查看AngularJS系列目录 转载请注明出处:http://www.cnblogs.com/leosx/ 在AngularJS 1.3 中,给一些指令(eg: ngRepeat,ngSw ...
- .h(头文件) .lib(库文件) .dll(动态链接库文件) 之间的关系和作用的区分
.h头文件是编译时必须的,lib是链接时需要的,dll是运行时需要的.附加依赖项的是.lib不是.dll,若生成了DLL,则肯定也生成 LIB文件.如果要完成源代码的编译和链接,有头文件和lib就够了 ...
- ORACLE 本地冷迁移
需求:把oracle数据库的数据文件,redo文件,控制文件迁移到本地的其它目录. 1.测试环境: 操作系统redhat 6.3,数据库oracle 11.2.0.1.0 [root@dbtest1 ...
- git仓库管理笔录
Git是目前世界上最先进的分布式版本控制系统(没有之一). 小明做了个个人博客,放到了Git 仓库里面.第二天换了台电脑,只需要 git clone 克隆一下git 远程仓库的代码到本地即可.然后他 ...
- HttpHelper类使用方法
HttpHelper http = new HttpHelper(); HttpItem item = new HttpItem() { URL = "http://www.sufeinet ...
- jquery系列教程2-style样式操作全解
全栈工程师开发手册 (作者:栾鹏) 快捷链接: jquery系列教程1-选择器全解 jquery系列教程2-style样式操作全解 jquery系列教程3-DOM操作全解 jquery系列教程4-事件 ...
- 批量下载验证码 shell
#!/bin/sh seq 0 699 | xargs -i wget http://www.5184.com/gk/common/checkcode.php -O img/{}.png
- WPF DataGrid自动生成序号
需求和效果 应用WPF技术进行开发的时候,大多都会遇到给DataGrid添加序号的问题,今天分享一下查阅了很多stackoverflow的文章后,总结和改进过来的方法,先看一下效果图,文末附Demo下 ...
- visual studio 2015 warning MSB3246
在我们很高兴的按下 本地计算机运行 按钮,希望看到我们程序运行的时候,垃圾vs就告诉我们,你的程序出现了问题,问题就是: warning MSB3246: 解析的文件包含错误图像.无元数据或不可访问. ...