Coursera 机器学习笔记(三)
主要为第四周、第五周课程内容:神经网络
神经网络模型引入
之前学习的线性回归还是逻辑回归都有个相同缺点就是:特征太多会导致计算量太大。如100个变量,来构建一个非线性模型。即使只采用两两特征组合,都会有接近5000个组成的特征。这对于普通的线性回归和逻辑回归计算特征量太大了。因此,神经网路孕育而生。
神经网络最初产生的目的是制造能模拟大脑的机器,能很好地解决不同的机器学习问题。模型表示为:
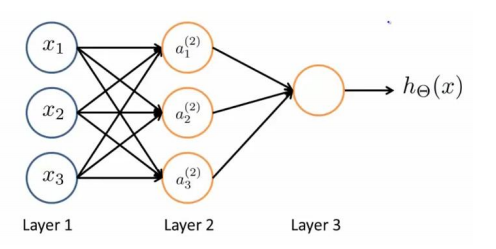
第一层为输入层,最后一层为输出层,中间的层为隐藏层。如把逻辑回归最为神经网络模型的神经元,a(j)I 代表第j层的第i个激活单元,θ(j)表示从第j层映射到第j+1层时的权重矩阵,其尺寸为第j+1层的激活单元数量为行数,第j层的激活单元数+1为列数的矩阵,如θ(1)尺寸为3*4。对于上图所示模型的表达为:
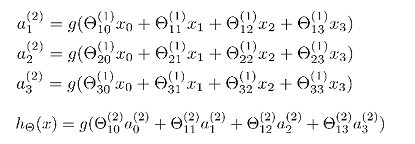
正向传播算法(Forward Propagation)
利用向量化的方法会使计算大为简便。计算上图第二层为例:

这只是针对训练集中一个训练实例所进行的计算。如果我们要对整个训练集进行计算,我们需要将训练集特征矩阵进行转置,使得同一个实例的特征都在同一列里。
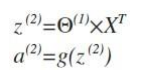
而计算第三层(输出层),可以把第二层看成是输入层,第三层为上述的第二层。

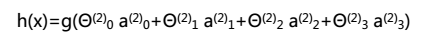
我们可以把 a0,a1,a2,a3看成更为高级的特征值,也就是 x0,x1,x2,x3的进化体,并且它们是由 x 与决定的,因为是梯度下降的,所以 a 是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 x 次方厉害,也能更好的预测新数据。
多分类
当我们有不止两种分类时(也就是 y=1,2,3….),比如以下这种情况,该怎么办?如y=4
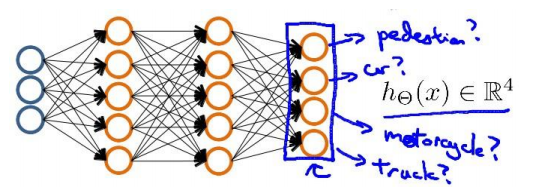
利用one-vs-all思想:神经网络算法的输出结果为四种可能情形之一

代价函数
引入标记表示方法:
- L代表神经网络的层数
- Si代表第i层的处理单元(包括偏见单元)的个数
- SL代表最后一层中的处理单元的个数
- K代表希望分类的个数,与SL相等
逻辑回归中的代价函数为:
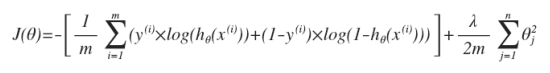
逻辑回归中只有一个输出变量,而在神经网络中有很多输出变量,h(x) 是个一个维度为K的向量,因此因变量也是一个维度为K的向量。神经网络相应的代价函数为:
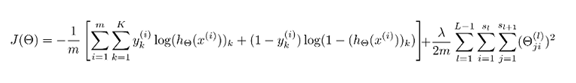
反向传播算法
综合
网络结构:
第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。
- 第一层的单元数即我们训练集的特征数量
- 最后一层的单元数是我们训练集的结果的类的数量
- ,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好
我们真正要决定的是隐藏层的层数和每个中间层的单元数。
训练神经网络:
1. 参数的随机初始化
2. 利用正向传播方法计算所有的 hθ(x)
3. 编写计算代价函数 J 的代码
4. 利用反向传播方法计算所有偏导数
5. 利用数值检验方法检验这些偏导数
6. 使用优化算法来最小化代价函数
Coursera 机器学习笔记(三)的更多相关文章
- coursera机器学习笔记-建议,系统设计
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-多元线性回归,normal equation
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-机器学习概论,梯度下降法
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-神经网络,学习篇
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-神经网络,初识篇
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- Coursera 机器学习笔记(八)
主要为第十周内容:大规模机器学习.案例.总结 (一)随机梯度下降法 如果有一个大规模的训练集,普通的批量梯度下降法需要计算整个训练集的误差的平方和,如果学习方法需要迭代20次,这已经是非常大的计算代价 ...
- Coursera 机器学习笔记(六)
主要为第八周内容:聚类(Clustering).降维 聚类是非监督学习中的重要的一类算法.相比之前监督学习中的有标签数据,非监督学习中的是无标签数据.非监督学习的任务是对这些无标签数据根据特征找到内在 ...
- Coursera 机器学习笔记(四)
主要为第六周内容机器学习应用建议以及系统设计. 下一步做什么 当训练好一个模型,预测未知数据,发现结果不如人意,该如何提高呢? 1.获得更多的训练实例 2.尝试减少特征的数量 3.尝试获得更多的特征 ...
- Coursera 机器学习笔记(七)
主要为第九周内容:异常检测.推荐系统 (一)异常检测(DENSITY ESTIMATION) 核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非 ...
随机推荐
- 对百度WebUploader的二次封装,精简前端代码之图片预览上传(两句代码搞定上传)
前言 本篇文章上一篇: 对百度WebUploader开源上传控件的二次封装,精简前端代码(两句代码搞定上传) 此篇是在上面的基础上扩展出来专门上传图片的控件封装. 首先我们看看效果: 正文 使用方式同 ...
- css过渡模块和2d转换模块
今天,我们一起来研究一下css3中的过渡模块.2d转换模块和3d转换模块 一.过渡模块transition (一)过度模块的三要素: 1.必须要有属性发生变化 2.必须告诉系统哪个属性需要执行过渡效果 ...
- 2017-4-24 WinForm开发基础、窗体的属性CenterScreen
WinForm中文名称: Windows窗体,是·Net开发平台中对Windows Form的一种称谓. 客户端应用程序:C/S 客户端很重要的特点:可以操作用户电脑上的文件 窗体属性:窗体种类: + ...
- 根据GPS经纬度判断当前所属的市区
这个事情分两步走 1. 拿到行政区划的地理围栏数据 2. 根据GPS定位判断一个点是否落在地理围栏的多边形区域里. 1. 获取行政区划的地理围栏数据可以利用百度API.打开以前我的一个例子在chrom ...
- bootstrap快速入门笔记(二)-栅格系统,响应式类
一,栅格系统大致有以下: 1,行row必须包含在 .container (固定宽度)或 .container-fluid (100% 宽度)中,一行有12列 2.“列(column)”在水平方向创建一 ...
- 关于li标签之间的间隔如何消除!
问题:li标签用了display:inline之后虽然成功的合并在一行,但是li标签之间出现了间距. 原因:按enter键换行之后li标签之间存在着空格,正是这些空格占据了li标签之间的空间. 解决方 ...
- Bootstrap Flat UI的select下拉框显示不出来 问题解决
Bootstrap Flat UI的select下拉框显示不出来?看这里,恰巧今天我也遇到了这个问题: 点击Messages后并没有出现下拉列表,然而官网的index.html却能显示出来. 经过一番 ...
- ubuntu16.04 编译运行 LSD-SLAM
下载编译LSDSLAM,可能会出现 CreateGlutWindowAndWind is not a member of pangolin 以及 该函数参数报错的问题: 原因是在新的pangolin版 ...
- hdu2612 Find a way BFS
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2612 思路: 裸的BFS,对于Y,M分别进行BFS,求出其分别到达各个点的最小时间: 然后对于@的点, ...
- JS解决通过按钮切换图片的问题
我是JS初学者,本想通过JS解决轮播图的特效,上网看了下:大部分都是JQ解决的,对于初学者的我来说理解上有点困难.于是我自己只做了一个不那么高大上的JS轮播图,下面我简单介绍下我的步骤:在HTML中创 ...