基于FPGA的均值滤波算法的实现
前面实现了基于FPGA的彩色图像转灰度处理,减小了图像的体积,但是其中还是存在许多噪声,会影响图像的边缘检测,所以这一篇就要消除这些噪声,基于灰度图像进行图像的滤波处理,为图像的边缘检测做好夯实基础。
椒盐噪声(salt & pepper noise)是数字图像的一个常见噪声,所谓椒盐,椒就是黑,盐就是白,椒盐噪声就是在图像上随机出现黑色白色的像素。椒盐噪声是一种因为信号脉冲强度引起的噪声,产生该噪声的算法也比较简单。
均值滤波的方法将数据存储成3x3的矩阵,然后求这个矩阵。在图像上对目标像素给一个模板,该模板包括了其周围的临近像素(以目标象素为中心的周围 8 个像素,构成一个滤波模板,即去掉目标像素本身),再用模板中的全体像素的平均值来代替原来像素值。
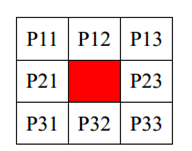
如图所示,我们要进行均值滤波首先要生成一个3x3矩阵。算法运算窗口一般采用奇数点的邻域来计算中值,最常用的窗口有3X3和5X5模型。下面介绍3X3窗口的Verilog实现方法。
(1)通过2个或者3个RAM的存储来实现3X3像素窗口;
(2)通过2个或者3个FIFO的存储来实现3X3像素窗口;
(3)通过2行或者3行Shift_RAM的存储来实现3X3像素窗口;
要想用实现均值滤波和中值滤波,必须要先生成3x3阵列,在Altera系列里,可以用QuatusII调用IP核——shift_RAM,具体设置参数如图所示。
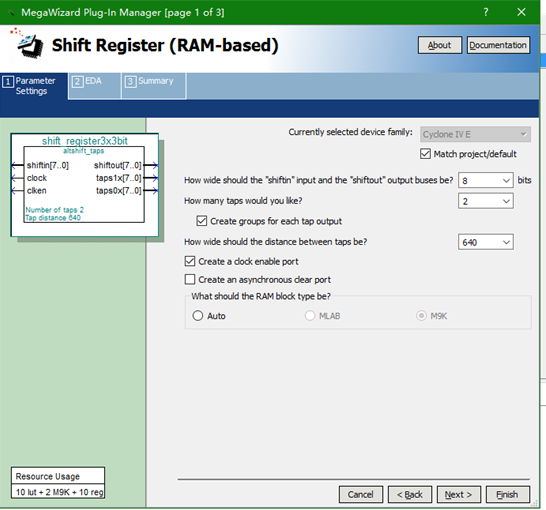
如上图所示,其中shiftin是实时输入的数据,taps1x,taps2x输入数据的第二三行,当数据输入成一行三个时,自动跳到下一行,最终形成每行是三列的一个矩阵,用均值滤波和中值滤波的处理方法即可,这样基本是每一个目标都可以找到自己对应的一个3x3矩阵,最后进行处理。先进入IP核里面的是最开始的的数据,所以在读出的时候也是要放在第一行。
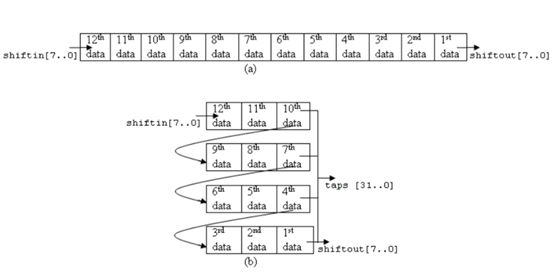
关于shift_ram的更详细的解释可以查看我的另一篇博文:http://www.cnblogs.com/ninghechuan/p/6789399.html。
这学期做比赛用的是国产FPGA,开发软件是PDS,这个软件说实话比较简洁,快,里面也有shift_ram IP core,但是不能设置多行(一个IP只能存储一行),不过只要你理解了shift_ram的工作的原理,完全可以用几个来实现多行处理,我通过PDS开发套件调用两个shift_register IP核来生成3X3矩阵实现3X3像素窗口。shift_register IP核可定义数据宽度、移位的行数、每行的深度。这里我们需要8bit。640个数据每行,同事移位寄存2行即可。同时选择时钟使能端口clken。
shift_ram_end u_shift_ram_end1
(
.din (row3_data),
.clk (shift_clk_en),
.rst (~rst_n),
.dout (row2_data)
); shift_ram_end u_shift_ram_end2
(
.din (row2_data),
.clk (shift_clk_en),
.rst (~rst_n),
.dout (row1_data)
);

如图所示,我们这里将行设置为8,场设置为4,所以可以明显的看到,当数据缓存到一行时,就会移位寄存到下一行,缓存两行后便会生成3X3矩阵。

如图所示,比较缓存的第一行的数据在3x3矩阵中,占第一行,结果相同,显然是正确的。
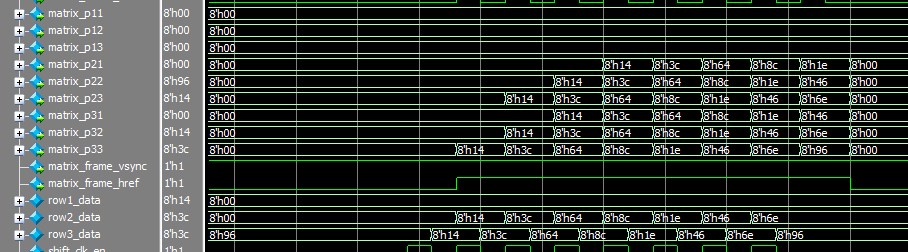
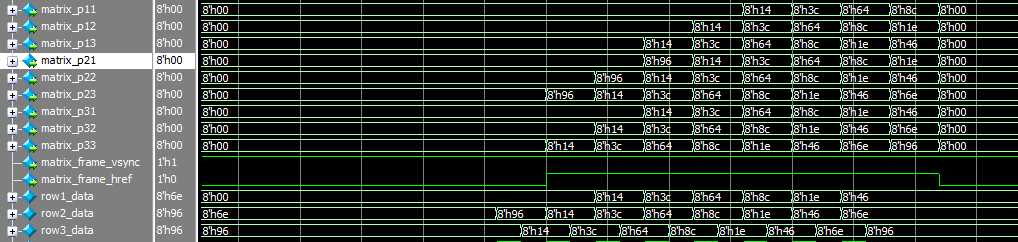
如图所示,第二行、第三行和最终生成的3x3矩阵作比较,结果显然是正确的。
//wire [32:0] matrix_row1 = {matrix_p11, matrix_p12,matrix_p13};//just for test
//wire [32:0] matrix_row2 = {matrix_p21, matrix_p22,matrix_p23};
//wire [32:0] matrix_row3 = {matrix_p31, matrix_p32,matrix_p33};
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)begin
{matrix_p11, matrix_p12, matrix_p13} <= 'h0;
{matrix_p21, matrix_p22, matrix_p23} <= 'h0;
{matrix_p31, matrix_p32, matrix_p33} <= 'h0;
end
else if(read_frame_href)begin
if(read_frame_clken)begin//shift_RAM data read clock enbale
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13, row1_data};//1th shift input
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23, row2_data};//2th shift input
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33, row3_data};//3th shift input
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33};
end
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= 'h0;
{matrix_p21, matrix_p22, matrix_p23} <= 'h0;
{matrix_p31, matrix_p32, matrix_p33} <= 'h0;
end
end
3x3矩阵生成
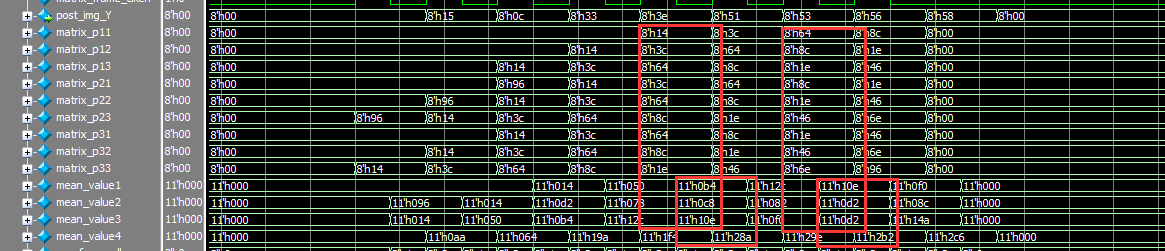
assign post_img_Y = mean_value4[:];//求平均值除以8,向右移位3位
如图所示,将3x3矩阵的中心像素的周围八个点求和,我们上面还是采取了流水线的设计方法,来增加吞吐量,然后再求平均值代替目标像素的值,从波形图上观察,计算的结果显然是正确的。这样便完成了均值滤波的仿真。
//--------------------------------------------
//Generate 8bit 3x3 matrix for video image processor
//Image data has been processd
wire matrix_frame_vsync; //Prepared Image data vsync valid signal
wire matrix_frame_href; //Prepared Image data href vaild signal
wire matrix_frame_clken; //Prepared Image data output/capture enable clock
wire [:] matrix_p11, matrix_p12, matrix_p13;//3x3 materix output
wire [:] matrix_p21, matrix_p22, matrix_p23;
wire [:] matrix_p31, matrix_p32, matrix_p33; shift_RAM_3x3 u_shift_RAM_3x3
(
//global signals
.clk (clk),
.rst_n (rst_n),
//Image data prepred to be processd
.per_frame_vsync (per_frame_vsync), //Prepared Image data vsync valid signal
.per_frame_href (per_frame_href), //Prepared Image data href vaild signal
.per_frame_clken (per_frame_clken), //Prepared Image data output/capture enable clock
.per_img_Y (per_img_Y), //Prepared Image brightness input //Image data has been processd
.matrix_frame_vsync (matrix_frame_vsync), //Prepared Image data vsync valid signal
.matrix_frame_href (matrix_frame_href), //Prepared Image data href vaild signal
.matrix_frame_clken (matrix_frame_clken), //Prepared Image data output/capture enable clock
.matrix_p11 (matrix_p11),
.matrix_p12 (matrix_p12),
.matrix_p13 (matrix_p13), //3X3 Matrix output
.matrix_p21 (matrix_p21),
.matrix_p22 (matrix_p22),
.matrix_p23 (matrix_p23),
.matrix_p31 (matrix_p31),
.matrix_p32 (matrix_p32),
.matrix_p33 (matrix_p33) ); //-----------------------------------------------------------------------
//step1
reg [:] mean_value1, mean_value2, mean_value3;
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)begin
mean_value1 <= 'd0;
mean_value2 <= 'd0;
mean_value3 <= 'd0;
end
else begin
mean_value1 <= matrix_p11 + matrix_p12 + matrix_p13;
mean_value2 <= matrix_p21 + 'd0 + matrix_p23;
mean_value3 <= matrix_p31 + matrix_p32 + matrix_p33;
end
end //step2
reg [:] mean_value4;
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
mean_value4 <= 'd0;
else
mean_value4 <= mean_value1 + mean_value2 + mean_value3;
end
对3x3矩阵求均值
当然,最后为了保持时钟的同步性,将消耗的时钟延时输出。
//------------------------------------------------------------
//delay 2 clk
reg [:] per_frame_clken_r;
reg [:] per_frame_href_r;
reg [:] per_frame_vsync_r; always @(posedge clk or negedge rst_n)
begin
if(!rst_n)begin
per_frame_clken_r <= 'b0;
per_frame_href_r <= 'b0;
per_frame_vsync_r <= 'b0;
end
else begin
per_frame_clken_r <= {per_frame_clken_r[], matrix_frame_clken};
per_frame_href_r <= {per_frame_href_r[], matrix_frame_href};
per_frame_vsync_r <= {per_frame_vsync_r[], matrix_frame_vsync};
end
end assign post_frame_vsync = per_frame_vsync_r[];
assign post_frame_href = per_frame_href_r[];
assign post_frame_clken = per_frame_clken_r[];
保持时钟的同步性


图上为灰度图像,图下为均值滤波后的图像,可以看出滤波后的图像有一些模糊,这是因为均值滤波就是将图像做平滑处理,像素值高的像素会被拉低,像素值低像素会被拉高,趋向于一个平均值,所以图像会变模糊一些。这样基于FPGA的均值滤波就完成了,下一篇我会发布基于FPGA的中值滤波处理,并且比较这两种滤波方式的优劣,最终选取较好的一种滤波方式进行图像边缘检测处理。

转载请注明出处:NingHeChuan(宁河川)
个人微信订阅号:NingHeChuan
如果你想及时收到个人撰写的博文推送,可以扫描左边二维码(或者长按识别二维码)关注个人微信订阅号
知乎ID:NingHeChuan
微博ID:NingHeChuan
原文地址:http://www.cnblogs.com/ninghechuan/p/6984705.html
基于FPGA的均值滤波算法的实现的更多相关文章
- 基于FPGA的均值滤波算法实现
我们为了实现动态图像的滤波算法,用串口发送图像数据到FPGA开发板,经FPGA进行图像处理算法后,动态显示到VGA显示屏上,前面我们把硬件平台已经搭建完成了,后面我们将利用这个硬件基础平台上来实现基于 ...
- 基于MATLAB的均值滤波算法实现
在图像采集和生成中会不可避免的引入噪声,图像噪声是指存在于图像数据中的不必要的或多余的干扰信息,这对我们对图像信息的提取造成干扰,所以要进行去噪声处理,常见的去除噪声的方法有均值滤波.中值滤波.高斯滤 ...
- 基于 OpenMP 的奇偶排序算法的实现
代码: #include <omp.h> #include <iostream> #include <cstdlib> #include <ctime> ...
- 基于FPGA的中值滤波算法实现
在这一篇开篇之前,我需要解决一个问题,上一篇我们实现了基于FPGA的均值滤波算法的实现,最后的显示效果图上发现有一些黑白色的斑点,我以为是椒盐噪声,然后在做基于FPGA的中值滤波算法的实验时,我发现黑 ...
- 基于FPGA的腐蚀膨胀算法实现
本篇文章我要写的是基于的腐蚀膨胀算法实现,腐蚀膨胀是形态学图像处理的基础,,腐蚀在二值图像的基础上做"收缩"或"细化"操作,膨胀在二值图像的基础上做" ...
- 基于FPGA的Sobel边缘检测的实现
前面我们实现了使用PC端上位机串口发送图像数据到VGA显示,通过MATLAB处理的图像数据直接是灰度图像,后面我们在此基础上修改,从而实现,基于FPGA的动态图片的Sobel边缘检测.中值滤波.Can ...
- 【转】基于FPGA的Sobel边缘检测的实现
前面我们实现了使用PC端上位机串口发送图像数据到VGA显示,通过MATLAB处理的图像数据直接是灰度图像,后面我们在此基础上修改,从而实现,基于FPGA的动态图片的Sobel边缘检测.中值滤波.Can ...
- FPGA经典:Verilog传奇与基于FPGA的数字图像处理原理及应用
一 简述 最近恶补基础知识,借了<<Verilog传奇>>,<基于FPGA的嵌入式图像处理系统设计>和<<基千FPGA的数字图像处理原理及应用>& ...
- 基于MATLAB的中值滤波均值滤波以及高斯滤波的实现
基于MATLAB的中值滤波均值滤波以及高斯滤波的实现 作者:lee神 1. 背景知识 中值滤波法是一种非线性平滑技术,它将每一像素点的灰度值设置为该点某邻域窗口内的所有像素点灰度值的中值. 中值滤 ...
随机推荐
- _getch() 函数,应用于输入密码敲入回车前修改
body,table { font-family: 微软雅黑; font-size: 10pt } table { border-collapse: collapse; border: solid g ...
- 阿里云centos 安装和配置 DokuWiki
安装 1) 添加虚拟主机:由于我的 阿里云CentOs服务器 安装了oneinstack的一键部署PHP.JAVA.Nginx等环境,所以域名配置很方便,照着文档一步一步做就可以了 cd /root/ ...
- C++STL中map容器的说明和使用技巧(杂谈)
1.map简介 map是一类关联式容器.它的特点是增加和删除节点对迭代器的影响很小,除了那个操作节点,对其他的节点都没有什么影响.对于迭代器来说,可以修改实值,而不能修改key. 2.map的功能 自 ...
- linux 下创建管理员权限账户
1.添加用户,首先用adduser命令添加一个普通用户,命令如下: #adduser tommy //添加一个名为tommy的用户 #passwd tommy //修改密码 Changing pass ...
- PPT要你好看---读书笔记
PPT要你好看.主要是设计的思维. 下图,对于现阶段的我来说,收获最大的是毕业答辩PPT的制作. 以及整体的PPT制作思路.
- yum 安装redis 及简单命令(推荐测试环境,安装简单)
第1章 redis 入门 1.1 yum 安装 安装repo源 cd /etc/yum.repos.d/ wget http://mirrors.aliyun.com/repo/epel-6.repo ...
- Windows下主机名和IP映射设置
如果需要添加域名和IP的对应关系可以在以下地方进行修改. 打开系统目录:c:/windows/system32/drivers/etc找到hosts文件,打开hosts文件并在最后面添加一条记录 例如 ...
- Lazyman功能实现
题目要求是这样的: 实现一个LazyMan,可以按照以下方式调用: LazyMan("Hank")输出: Hi! This is Hank! LazyMan("Hank& ...
- DokiCam 360°4K相机:为极致运动爱好者而生
去年11月,位于中国苏州的DokiCam为其360°消费像机推出了Kickstarter人群资助活动.随着本次活动圆满结束,这款被称为DokiCam 360°的动作相机现在已经可以购买. 进入360° ...
- linux下fdisk分区管理、文件系统管理、挂载文件系统等
分区管理工具有:fdisk, parted, sfdisk fdisk:对于一块硬盘来讲,最多只能管理15分区: # fdisk -l [-u] [device...] 查看硬盘设备分区信息 # f ...