spark2.2 DataFrame的一些算子操作
本文持续更新中。。。
Spark Session中的DataFrame类似于一张关系型数据表。在关系型数据库中对单表或进行的查询操作,在DataFrame中都可以通过调用其API接口来实现。
可以参考,Scala提供的DataFrame API。本文将使用SparkSession进行操作。
一、DataFrame对象的生成
val ss = SparkSession.builder()
.appName("ta")
.master("local[4]")
.config("spark.mongodb.input.uri","mongodb://username:password@192.168.1.3:27017/log.")
.config("spark.mongodb.output.uri","mongodb://username:password@192.168.1.3:27017/log")
.config("es.index.auto.create", "true")
.config("es.nodes","192.168.1.1")
.config("es.port","9200")
.getOrCreate()
1.读写mysql数据
val url = "jdbc:mysql://m000:3306/test"
val jdbcDF = ss.read.format( "jdbc" ).options(Map( "url" -> url,"user" -> "xxx","password" -> "xxx", "dbtable" -> "xxx" )).load()
data2DF.write.mode("overwrite").format("jdbc").options(Map("url" ->url, "dbtable" -> "TableName")).save()
2.读写SqlServer数据
val sqlUrl="jdbc:sqlserver://192.168.1.3:1433;DatabaseName=mytable;username=xxxx;password=xxx"
val data2DF = ss.read.format("jdbc").options( Map("url" -> sqlsUrl, "dbtable" -> "TableName")).load()
data2DF.write.mode("overwrite").format("jdbc").options(Map("url" ->sqlUrl, "dbtable" -> "TableName")).save()
3.读写MongoDB数据
import com.mongodb.spark._
import com.mongodb.spark.config.ReadConfig
读取
val data1DF = MongoSpark.load(ss, ReadConfig(Map("collection" -> "TableName"), Some(ReadConfig(ss))))
val data2=ss.sparkContext.loadFromMongoDB(ReadConfig(Map("uri" -> readUrl))).toDF()
第一种方式适用于读取同一个库中的数据,当在不同库中读取数据时,可以使用第二种
MongoSpark.save(datas.write.option("collection", "documentName").mode("append"))
4.读写ES数据
import org.elasticsearch.spark.sql._
ss.esDF("/spark_applog/applog")
df.saveToEs("/spark_applog/applog")
二、DataFrame对象上Action操作
1、show:展示数据
以表格的形式在输出中展示jdbcDF中的数据,类似于select * from spark_sql_test的功能。
show方法有四种调用方式,分别为,
(1)show
只显示前20条记录。且过长的字符串会被截取
示例:jdbcDF.show
(2)show(numRows: Int)
显示numRows条
示例:jdbcDF.show(3)
(3)show(truncate: Boolean)
是否截取20个字符,默认为true。
示例:jdbcDF.show(false)
(4)show(numRows: Int, truncate: Int)
显示记录条数,以及截取字符个数,为0时表示不截取
示例:jdbcDF.show(3, 0)
2、collect:获取所有数据到数组
不同于前面的show方法,这里的collect方法会将jdbcDF中的所有数据都获取到,并返回一个Array对象。
jdbcDF.collect()
结果数组包含了jdbcDF的每一条记录,每一条记录由一个GenericRowWithSchema对象来表示,可以存储字段名及字段值。
3、collectAsList:获取所有数据到List
功能和collect类似,只不过将返回结构变成了List对象,使用方法如下
jdbcDF.collectAsList()
4、describe(cols: String*):获取指定字段的统计信息
这个方法可以动态的传入一个或多个String类型的字段名,结果仍然为DataFrame对象,用于统计数值类型字段的统计值,比如count, mean, stddev, min, max等。
使用方法如下,其中c1字段为字符类型,c2字段为整型,c4字段为浮点型
jdbcDF .describe("c1" , "c2", "c4" ).show()
结果如下,

5、first, head, take, takeAsList:获取若干行记录
这里列出的四个方法比较类似,其中
(1)first获取第一行记录
(2)head获取第一行记录,head(n: Int)获取前n行记录
(3)take(n: Int)获取前n行数据
(4)takeAsList(n: Int)获取前n行数据,并以List的形式展现
以Row或者Array[Row]的形式返回一行或多行数据。first和head功能相同。
take和takeAsList方法会将获得到的数据返回到Driver端,所以,使用这两个方法时需要注意数据量,以免Driver发生OutOfMemoryError
使用和结果略。
三、DataFrame对象上的条件查询和join等操作
以下返回为DataFrame类型的方法,可以连续调用。
1、where条件相关
(1)where(conditionExpr: String):SQL语言中where关键字后的条件
传入筛选条件表达式,可以用and和or。得到DataFrame类型的返回结果,
示例:
jdbcDF .where("id = 1 or c1 = 'b'" ).show()
结果,

(2)filter:根据字段进行筛选
传入筛选条件表达式,得到DataFrame类型的返回结果。和where使用条件相同
示例:jdbcDF .filter("id = 1 or c1 = 'b'" ).show()

2、查询指定字段
(1)select:获取指定字段值
根据传入的String类型字段名,获取指定字段的值,以DataFrame类型返回
示例:
jdbcDF.select( "id" , "c3" )
还有一个重载的select方法,不是传入String类型参数,而是传入Column类型参数。可以实现select id, id+1 from test这种逻辑。
jdbcDF.select(jdbcDF( "id" ), jdbcDF( "id") + 1 ).show( false)
结果:

能得到Column类型的方法是apply以及col方法,一般用apply方法更简便。
(2)selectExpr:可以对指定字段进行特殊处理
可以直接对指定字段调用UDF函数,或者指定别名等。传入String类型参数,得到DataFrame对象。
示例,查询id字段,c3字段取别名time,c4字段四舍五入:
jdbcDF .selectExpr("id" , "c3 as time" , "round(c4)" ).show(false)
结果,

(3)col:获取指定字段
只能获取一个字段,返回对象为Column类型。
val idCol = jdbcDF.col(“id”)
(4)apply:获取指定字段
只能获取一个字段,返回对象为Column类型
示例:
val idCol1 = jdbcDF.apply("id")val idCol2 = jdbcDF("id")
(5)drop:去除指定字段,保留其他字段
返回一个新的DataFrame对象,其中不包含去除的字段,一次只能去除一个字段。
示例:
jdbcDF.drop("id")jdbcDF.drop(jdbcDF("id"))
3、limit
limit方法获取指定DataFrame的前n行记录,得到一个新的DataFrame对象。和take与head不同的是,limit方法不是Action操作。
jdbcDF.limit(3)
4、order by
(1)orderBy和sort:按指定字段排序,默认为升序
示例1,按指定字段排序。加个-表示降序排序。sort和orderBy使用方法相同
jdbcDF.orderBy(- jdbcDF("c4")).show(false) 只能对数字类型和日期类型生效// 或者jdbcDF.orderBy(jdbcDF("c4").desc).show(false)
结果,

(2)sortWithinPartitions
和上面的sort方法功能类似,区别在于sortWithinPartitions方法返回的是按Partition排好序的DataFrame对象。
5、group by
(1)groupBy:根据字段进行group by操作
groupBy方法有两种调用方式,可以传入String类型的字段名,也可传入Column类型的对象。
使用方法如下,
jdbcDF .groupBy("c1" )jdbcDF.groupBy( jdbcDF( "c1"))
(2)cube和rollup:group by的扩展
功能类似于SQL中的group by cube/rollup
原表:
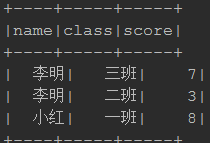
cube: mst.cube("name","class").sum("score").show()
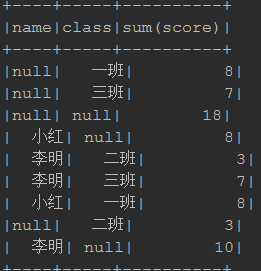
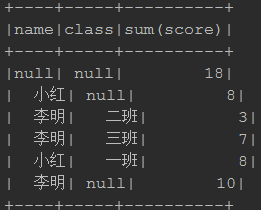
rollup: mst.rollup("name","class").sum("score").show()
(3)GroupedData对象
该方法得到的是GroupedData类型对象,在GroupedData的API中提供了group by之后的操作,比如,
max(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的最大值,只能作用于数字型字段min(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的最小值,只能作用于数字型字段mean(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的平均值,只能作用于数字型字段sum(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的和值,只能作用于数字型字段count()方法,获取分组中的元素个数运行结果示例:
count
max
这里面比较复杂的是以下两个方法,
agg,该方法和下面介绍的类似,可以用于对指定字段进行聚合操作。


pivot
6、distinct
(1)distinct:返回一个不包含重复记录的DataFrame
返回当前DataFrame中不重复的Row记录。该方法和接下来的dropDuplicates()方法不传入指定字段时的结果相同。
示例:
jdbcDF.distinct()
结果,

(2)dropDuplicates:根据指定字段去重
根据指定字段去重。类似于select distinct a, b操作
示例:
jdbcDF.dropDuplicates(Seq("c1"))
结果:

7、聚合
聚合操作调用的是agg方法,该方法有多种调用方式。一般与groupBy方法配合使用。
以下示例其中最简单直观的一种用法,对id字段求最大值,对c4字段求和。
jdbcDF.agg("id" -> "max", "c4" -> "sum")
结果:

8、union
union方法:对两个DataFrame进行合并
示例:
jdbcDF.union(jdbcDF.limit(1))
结果:

9、join
重点来了。在SQL语言中用得很多的就是join操作,DataFrame中同样也提供了join的功能。
接下来隆重介绍join方法。在DataFrame中提供了六个重载的join方法。
(1)、笛卡尔积
joinDF1.join(joinDF2)
(2)、using一个字段形式
下面这种join类似于a join b using column1的形式,需要两个DataFrame中有相同的一个列名,
joinDF1.join(joinDF2, "id")
(3)、using多个字段形式
除了上面这种using一个字段的情况外,还可以using多个字段,如下
joinDF1.join(joinDF2, Seq("id", "name"))
(4)、指定join类型
在上面的using多个字段的join情况下,可以写第三个String类型参数,指定join的类型,如下所示
inner:内连
outer,full,full_outer:全连
left, left_outer:左连
right,right_outer:右连
left_semi:过滤出joinDF1中和joinDF2共有的部分
left_anti:过滤出joinDF1中joinDF2没有的部分
joinDF1.join(joinDF2, Seq("id", "name"), "inner")
(5)、使用Column类型来join
如果不用using模式,灵活指定join字段的话,可以使用如下形式
joinDF1.join(joinDF2 , joinDF1("id" ) === joinDF2( "t1_id"))
结果如下,

(6)、在指定join字段同时指定join类型
如下所示
joinDF1.join(joinDF2 , joinDF1("id" ) === joinDF2( "t1_id"), "inner")
10、获取指定字段统计信息
stat方法可以用于计算指定字段或指定字段之间的统计信息,比如方差,协方差等。这个方法返回一个DataFramesStatFunctions类型对象。
下面代码演示根据c4字段,统计该字段值出现频率在30%以上的内容。在jdbcDF中字段c1的内容为"a, b, a, c, d, b"。其中a和b出现的频率为2 / 6,大于0.3
jdbcDF.stat.freqItems(Seq ("c1") , 0.3).show()
结果如下:

11、获取两个DataFrame中共有的记录
intersect方法可以计算出两个DataFrame中相同的记录,
jdbcDF.intersect(jdbcDF.limit(1)).show(false)
结果如下:

12、获取一个DataFrame中有另一个DataFrame中没有的记录
示例:
jdbcDF.except(jdbcDF.limit(1)).show(false)
结果如下,

13、操作字段名
(1)withColumnRenamed:重命名DataFrame中的指定字段名
如果指定的字段名不存在,不进行任何操作。下面示例中将jdbcDF中的id字段重命名为idx。
jdbcDF.withColumnRenamed( "id" , "idx" )
结果如下:

(2)withColumn:往当前DataFrame中新增一列
whtiColumn(colName: String , col: Column)方法根据指定colName往DataFrame中新增一列,如果colName已存在,则会覆盖当前列。
以下代码往jdbcDF中新增一个名为id2的列,
jdbcDF.withColumn("id2", jdbcDF("id")).show( false)
结果如下,

14、行转列
有时候需要根据某个字段内容进行分割,然后生成多行,这时可以使用explode方法
下面代码中,根据c3字段中的空格将字段内容进行分割,分割的内容存储在新的字段c3_中,如下所示
jdbcDF.explode( "c3" , "c3_" ){time: String => time.split( " " )}
结果如下,

spark2.2 DataFrame的一些算子操作的更多相关文章
- Spark 2.2 DataFrame的一些算子操作
Spark Session中的DataFrame类似于一张关系型数据表.在关系型数据库中对单表或进行的查询操作,在DataFrame中都可以通过调用其API接口来实现. 可以参考,Scala提供的Da ...
- sparkRDD:第3节 RDD常用的算子操作
4. RDD编程API 4.1 RDD的算子分类 Transformation(转换):根据数据集创建一个新的数据集,计算后返回一个新RDD:例如:一个rdd进行map操作后生了一个新的rd ...
- SparkStreaming算子操作,Output操作
SparkStreaming练习之StreamingTest,UpdateStateByKey,WindowOperator 一.SparkStreaming算子操作 1.1 foreachRDD 1 ...
- 【Spark篇】---SparkStreaming算子操作transform和updateStateByKey
一.前述 今天分享一篇SparkStreaming常用的算子transform和updateStateByKey. 可以通过transform算子,对Dstream做RDD到RDD的任意操作.其实就是 ...
- 【SparkStreaming学习之二】 SparkStreaming算子操作
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- spark2.3.0 配置spark sql 操作hive
spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然后在spark引擎中进行sql统计分析,从而,通过spark sql与hive结合实现数据分析将成为一种最佳实践.配置步骤 ...
- Spark中的各种action算子操作(java版)
在我看来,Spark编程中的action算子的作用就像一个触发器,用来触发之前的transformation算子.transformation操作具有懒加载的特性,你定义完操作之后并不会立即加载,只有 ...
- 【Spark】DataFrame关于数据常用操作
文章目录 DSL语法 概述 实例操作 SQL语法 概述 实例操作 DSL语法 概述 1.查看全表数据 -- DataFrame.show 2.查看部分字段数据(有4种方法) (1) DataFram ...
- Flink中的算子操作
一.Connect DataStream,DataStream -> ConnectedStream,连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了同一个流中,内部 ...
随机推荐
- STM32 AD采样电压计算公式
在使用STM32的ADC进行检测电压时必须回涉及到电压值的计算,为了更高效率的获取电压,现在有以下三种方法: 你得到的结果是你当前AD引脚上的电压值相对于3.3V和4096转换成的数字.假如你得到的A ...
- 基于HTML5的WebGL实现json和echarts图表展现在同一个界面
突然有个想法,如果能把一些用到不同的知识点放到同一个界面上,并且放到一个盒子里,这样我如果要看什么东西就可以很直接显示出来,而且这个盒子一定要能打开.我用HT实现了我的想法,代码一百多行,这么少的代码 ...
- Locust性能测试框架,从入门到精通
1. Locust简介 Locust是使用Python语言编写实现的开源性能测试工具,简洁.轻量.高效,并发机制基于gevent协程,可以实现单机模拟生成较高的并发压力. 主要特点如下: 使用普通的P ...
- 正确理解Mysql的列索引和多列索引
MySQL数据库提供两种类型的索引,如果没正确设置,索引的利用效率会大打折扣却完全不知问题出在这. CREATE TABLE test ( id INT NOT NULL, last_ ...
- C#设计模式之十组合模式(Composite)【结构型】
一.引言 今天我们要讲[结构型]设计模式的第四个模式,该模式是[组合模式],英文名称是:Composite Pattern.当我们谈到这个模式的时候,有一个物件和这个模式很像,也符合这个模式要表达 ...
- spring mvc+mybatis+maven集成tkmapper+pagehelper
<!-- maven tkmapper引入--> <dependency> <groupId>tk.mybatis</groupId> <arti ...
- ubuntu 常用软件安装
安装ubuntu远程图形界面 sudo apt-get install xrdp (sudo apt-get install .. 用于安装软件的命令 ) sudo apt-get install ...
- c++ 类的默认八种函数
c++ 类的默认八种函数 #define _CRT_SECURE_NO_WARNINGS #include <iostream> #include <string> #incl ...
- CodeForces - 556A Case of the Zeros and Ones
//////////////////////////////////////////////////////////////////////////////////////////////////// ...
- 不怕你配置不对,就怕你看的资料不对!MIM 与 SharePoint 同步完全配置指南。
为了更好的同步 User Profile,在 SharePoint 2010 中首次引入了 FIM (ForeFront Identity Manager) 用于编辑 User Profile 的同期 ...