通过hadoop + hive搭建离线式的分析系统之快速搭建一览
最近有个需求,需要整合所有店铺的数据做一个离线式分析系统,曾经都是按照店铺分库分表来给各自商家通过highchart多维度展示自家的店铺经营
状况,我们知道这是一个以店铺为维度的切分,非常适合目前的在线业务,这回老板提需求了,曾经也是一位数据分析师,sql自然就溜溜的,所以就来了
一个以买家维度展示用户画像,从而更好的做数据推送和用户行为分析,因为是离线式分析,目前还没研究spark,impala,drill了。
一:搭建hadoop集群
hadoop的搭建是一个比较繁琐的过程,采用3台Centos,废话不过多,一图胜千言。。。
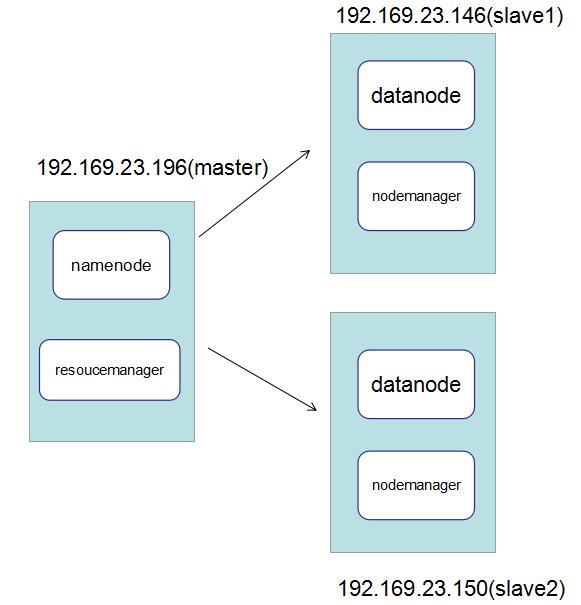
二: 基础配置
1. 关闭防火墙
[root@localhost ~]# systemctl stop firewalld.service #关闭防火墙
[root@localhost ~]# systemctl disable firewalld.service #禁止开机启动
[root@localhost ~]# firewall-cmd --state #查看防火墙状态
not running
[root@localhost ~]#
2. 配置SSH免登录
不管在开启还是关闭hadoop的时候,hadoop内部都要通过ssh进行通讯,所以需要配置一个ssh公钥免登陆,做法就是将一个centos的公钥copy到另一
台centos的authorized_keys文件中。
<1>: 在196上生成公钥私钥 ,从下图中可以看到通过ssh-keygen之后会生成 id_rsa 和 id_rsa.pub 两个文件,这里我们
关心的是公钥id_rsa.pub。
[root@localhost ~]# ssh-keygen -t rsa -P ''
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
::cc:f4:c3:e7::c9:9f:ee:f8::ec::be:a1 root@localhost.localdomain
The key's randomart image is:
+--[ RSA ]----+
| .++ ... |
| +oo o. |
| . + . .. . |
| . + . o |
| S . . |
| . . |
| . oo |
| ....o... |
| E.oo .o.. |
+-----------------+
[root@localhost ~]# ls /root/.ssh/id_rsa
/root/.ssh/id_rsa
[root@localhost ~]# ls /root/.ssh
id_rsa id_rsa.pub
<2> 通过scp复制命令 将公钥copy到 146 和 150主机,以及将id_ras.pub 追加到本机中
[root@master ~]# scp /root/.ssh/id_rsa.pub root@192.168.23.146:/root/.ssh/authorized_keys
root@192.168.23.146's password:
id_rsa.pub % .4KB/s :
[root@master ~]# scp /root/.ssh/id_rsa.pub root@192.168.23.150:/root/.ssh/authorized_keys
root@192.168.23.150's password:
id_rsa.pub % .4KB/s :
[root@master ~]# cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
<3> 做host映射,主要给几台机器做别名映射,方便管理。
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.23.196 master
192.168.23.150 slave1
192.168.23.146 slave2
[root@master ~]#
<4> java安装环境
hadoop是java写的,所以需要安装java环境,具体怎么安装,大家可以网上搜一下,先把centos自带的openjdk卸载掉,最后在profile中配置一下。
[root@master ~]# cat /etc/profile
# /etc/profile # System wide environment and startup programs, for login setup
# Functions and aliases go in /etc/bashrc # It's NOT a good idea to change this file unless you know what you
# are doing. It's much better to create a custom.sh shell script in
# /etc/profile.d/ to make custom changes to your environment, as this
# will prevent the need for merging in future updates. pathmunge () {
case ":${PATH}:" in
*:"$1":*)
;;
*)
if [ "$2" = "after" ] ; then
PATH=$PATH:$
else
PATH=$:$PATH
fi
esac
} if [ -x /usr/bin/id ]; then
if [ -z "$EUID" ]; then
# ksh workaround
EUID=`id -u`
UID=`id -ru`
fi
USER="`id -un`"
LOGNAME=$USER
MAIL="/var/spool/mail/$USER"
fi # Path manipulation
if [ "$EUID" = "" ]; then
pathmunge /usr/sbin
pathmunge /usr/local/sbin
else
pathmunge /usr/local/sbin after
pathmunge /usr/sbin after
fi HOSTNAME=`/usr/bin/hostname >/dev/null`
HISTSIZE=
if [ "$HISTCONTROL" = "ignorespace" ] ; then
export HISTCONTROL=ignoreboth
else
export HISTCONTROL=ignoredups
fi export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL # By default, we want umask to get set. This sets it for login shell
# Current threshold for system reserved uid/gids is
# You could check uidgid reservation validity in
# /usr/share/doc/setup-*/uidgid file
if [ $UID -gt ] && [ "`id -gn`" = "`id -un`" ]; then
umask
else
umask
fi for i in /etc/profile.d/*.sh ; do
if [ -r "$i" ]; then
if [ "${-#*i}" != "$-" ]; then
. "$i"
else
. "$i" >/dev/null
fi
fi
done unset i
unset -f pathmunge export JAVA_HOME=/usr/big/jdk1.8
export HADOOP_HOME=/usr/big/hadoop
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH [root@master ~]#
二: hadoop安装包
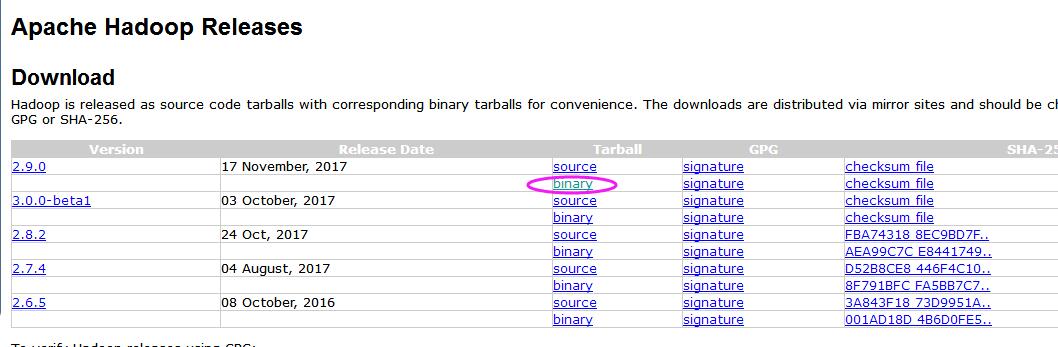
1. 大家可以到官网上找一下安装链接:http://hadoop.apache.org/releases.html, 我这里选择的是最新版的2.9.0,binary安装。
2. 然后就是一路命令安装【看清楚目录哦。。。没有的话自己mkdir】
[root@localhost big]# pwd
/usr/big
[root@localhost big]# ls
hadoop-2.9. hadoop-2.9..tar.gz
[root@localhost big]# tar -xvzf hadoop-2.9..tar.gz
3. 对core-site.xml ,hdfs-site.xml,mapred-site.xml,yarn-site.xml,slaves,hadoop-env.sh的配置,路径都在etc目录下,
这也是最麻烦的。。。
[root@master hadoop]# pwd
/usr/big/hadoop/etc/hadoop
[root@master hadoop]# ls
capacity-scheduler.xml hadoop-policy.xml kms-log4j.properties slaves
configuration.xsl hdfs-site.xml kms-site.xml ssl-client.xml.example
container-executor.cfg httpfs-env.sh log4j.properties ssl-server.xml.example
core-site.xml httpfs-log4j.properties mapred-env.cmd yarn-env.cmd
hadoop-env.cmd httpfs-signature.secret mapred-env.sh yarn-env.sh
hadoop-env.sh httpfs-site.xml mapred-queues.xml.template yarn-site.xml
hadoop-metrics2.properties kms-acls.xml mapred-site.xml
hadoop-metrics.properties kms-env.sh mapred-site.xml.template
[root@master hadoop]#
<1> core-site.xml 下的配置中,我指定了hadoop的基地址,namenode的端口号,namenode的地址。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/myapp/hadoop/data</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
<2> hdfs-site.xml 这个文件主要用来配置datanode以及datanode的副本。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3. mapred-site.xml 这里配置一下启用yarn框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4. yarn-site.xml文件配置
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
</configuration>
5. 在etc的slaves文件中,追加我们在host中配置的salve1和slave2,这样启动的时候,hadoop才能知道slave的位置。
[root@master hadoop]# cat slaves
slave1
slave2
[root@master hadoop]# pwd
/usr/big/hadoop/etc/hadoop
[root@master hadoop]#
6. 在hadoop-env.sh中配置java的路径,其实就是把 /etc/profile的配置copy一下,追加到文件末尾。
[root@master hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/big/jdk1.8
不过这里还有一个坑,hadoop在计算时,默认的heap-size是512M,这就容易导致在大数据计算时,堆栈溢出,这里将512改成2048。
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx2048m $HADOOP_PORTMAP_OPTS" # The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS"
# set heap args when HADOOP_HEAPSIZE is empty
if [ "$HADOOP_HEAPSIZE" = "" ]; then
export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS"
fi
7. 不要忘了在/usr目录下创建文件夹哦,然后在/etc/profile中配置hadoop的路径。
/usr/hadoop
/usr/hadoop/namenode
/usr/hadoop/datanode
export JAVA_HOME=/usr/big/jdk1.8
export HADOOP_HOME=/usr/big/hadoop
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
8. 将196上配置好的整个hadoop文件夹通过scp到 146 和150 服务器上的/usr/big目录下,后期大家也可以通过svn进行hadoop文件夹的
管理,这样比较方便。
scp -r /usr/big/hadoop root@192.168.23.146:/usr/big
scp -r /usr/big/hadoop root@192.168.23.150:/usr/big
三:启动hadoop
1. 启动之前通过hadoop namede -format 格式化一下hadoop dfs。
[root@master hadoop]# hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it. 17/11/24 20:13:19 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.23.196
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.9.0
2. 在master机器上start-all.sh 启动hadoop集群。
[root@master hadoop]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
root@master's password:
master: starting namenode, logging to /usr/big/hadoop/logs/hadoop-root-namenode-master.out
slave1: starting datanode, logging to /usr/big/hadoop/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to /usr/big/hadoop/logs/hadoop-root-datanode-slave2.out
Starting secondary namenodes [0.0.0.0]
root@0.0.0.0's password:
0.0.0.0: starting secondarynamenode, logging to /usr/big/hadoop/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/big/hadoop/logs/yarn-root-resourcemanager-master.out
slave1: starting nodemanager, logging to /usr/big/hadoop/logs/yarn-root-nodemanager-slave1.out
slave2: starting nodemanager, logging to /usr/big/hadoop/logs/yarn-root-nodemanager-slave2.out
[root@master hadoop]# jps
8851 NameNode
9395 ResourceManager
9655 Jps
9146 SecondaryNameNode
[root@master hadoop]#
通过jps可以看到,在master中已经开启了NameNode 和 ResouceManager,那么接下来,大家也可以到slave1和slave2机器上看一下是不是把NodeManager
和 DataNode都开起来了。。。
[root@slave1 hadoop]# jps
7112 NodeManager
7354 Jps
6892 DataNode
[root@slave1 hadoop]#
[root@slave2 hadoop]# jps
7553 NodeManager
7803 Jps
7340 DataNode
[root@slave2 hadoop]#
四:搭建完成,查看结果
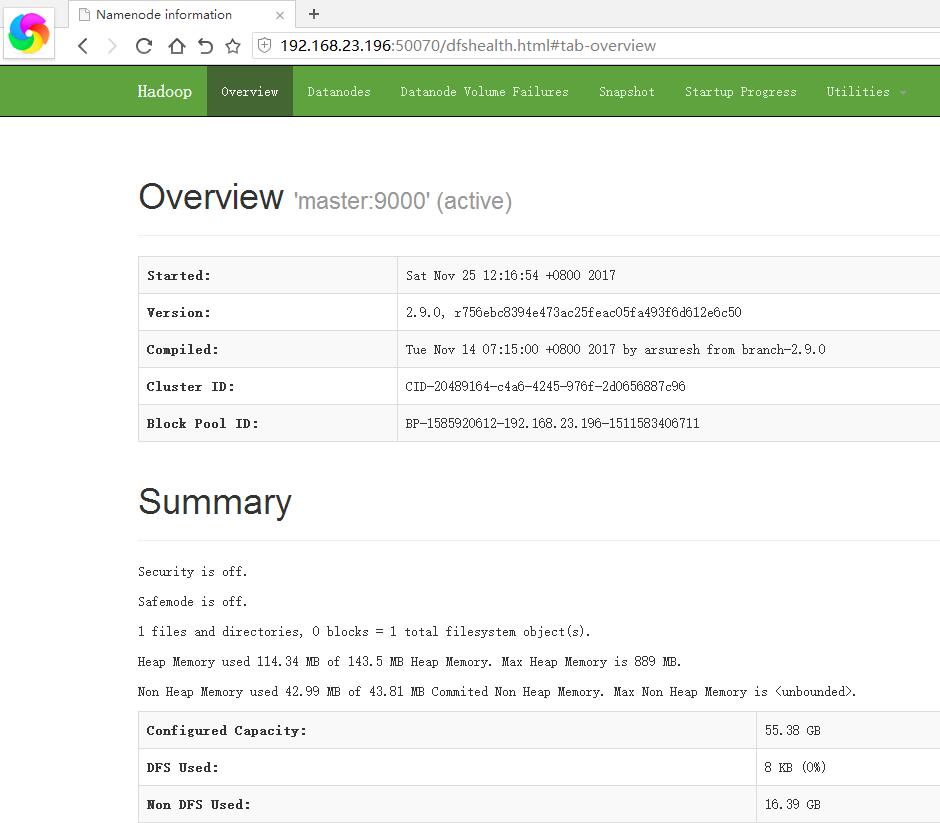
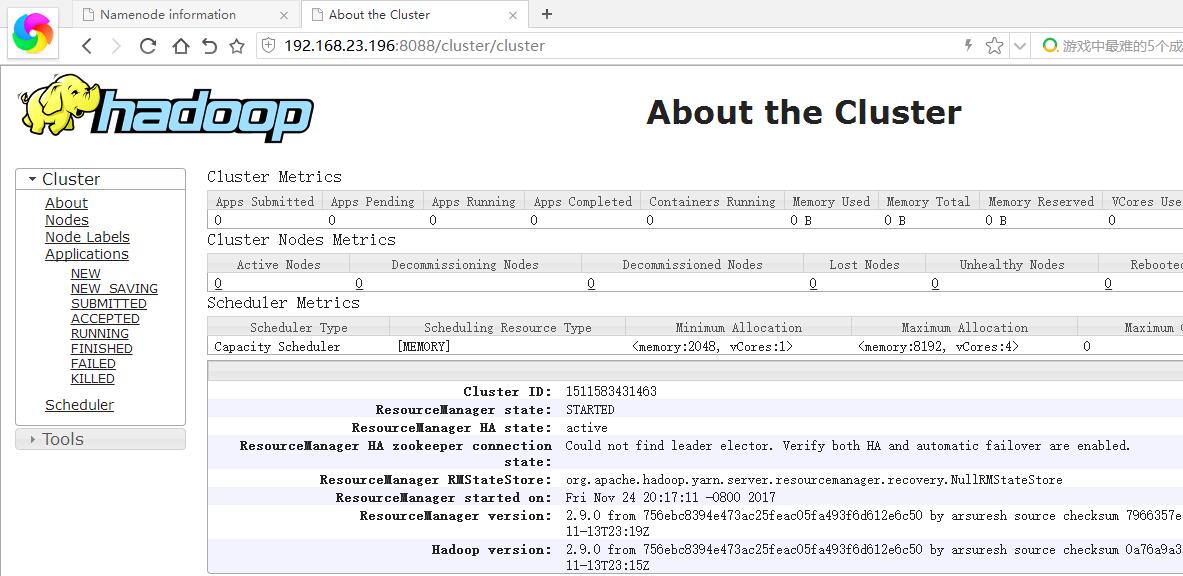
通过下面的tlnp命令,可以看到50070端口和8088端口打开,一个是查看datanode,一个是查看mapreduce任务。
[root@master hadoop]# netstat -tlnp

五:最后通过hadoop自带的wordcount来结束本篇的搭建过程。
在hadoop的share目录下有一个wordcount的测试程序,主要用来统计单词的个数,hadoop/share/hadoop/mapreduce/hadoop-mapreduce-
examples-2.9.0.jar。
1. 我在/usr/soft下通过程序生成了一个39M的2.txt文件(全是随机汉字哦。。。)
[root@master soft]# ls -lsh 2.txt
39M -rw-r--r--. 1 root root 39M Nov 24 00:32 2.txt
[root@master soft]#
2. 在hadoop中创建一个input文件夹,然后在把2.txt上传过去
[root@master soft]# hadoop fs -mkdir /input
[root@master soft]# hadoop fs -put /usr/soft/2.txt /input
[root@master soft]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2017-11-24 20:30 /input
3. 执行wordcount的mapreduce任务
[root@master soft]# hadoop jar /usr/big/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount /input/2.txt /output/v1
17/11/24 20:32:21 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
17/11/24 20:32:21 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
17/11/24 20:32:21 INFO input.FileInputFormat: Total input files to process : 1
17/11/24 20:32:21 INFO mapreduce.JobSubmitter: number of splits:1
17/11/24 20:32:21 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1430356259_0001
17/11/24 20:32:22 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
17/11/24 20:32:22 INFO mapreduce.Job: Running job: job_local1430356259_0001
17/11/24 20:32:22 INFO mapred.LocalJobRunner: OutputCommitter set in config null
17/11/24 20:32:22 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
17/11/24 20:32:22 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
17/11/24 20:32:22 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
17/11/24 20:32:22 INFO mapred.LocalJobRunner: Waiting for map tasks
17/11/24 20:32:22 INFO mapred.LocalJobRunner: Starting task: attempt_local1430356259_0001_m_000000_0
17/11/24 20:32:22 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
17/11/24 20:32:22 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
17/11/24 20:32:22 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
17/11/24 20:32:22 INFO mapred.MapTask: Processing split: hdfs://192.168.23.196:9000/input/2.txt:0+40000002
17/11/24 20:32:22 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
17/11/24 20:32:22 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
17/11/24 20:32:22 INFO mapred.MapTask: soft limit at 83886080
17/11/24 20:32:22 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
17/11/24 20:32:22 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
17/11/24 20:32:22 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
17/11/24 20:32:23 INFO mapreduce.Job: Job job_local1430356259_0001 running in uber mode : false
17/11/24 20:32:23 INFO mapreduce.Job: map 0% reduce 0%
17/11/24 20:32:23 INFO input.LineRecordReader: Found UTF-8 BOM and skipped it
17/11/24 20:32:27 INFO mapred.MapTask: Spilling map output
17/11/24 20:32:27 INFO mapred.MapTask: bufstart = 0; bufend = 27962024; bufvoid = 104857600
17/11/24 20:32:27 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 12233388(48933552); length = 13981009/6553600
17/11/24 20:32:27 INFO mapred.MapTask: (EQUATOR) 38447780 kvi 9611940(38447760)
17/11/24 20:32:32 INFO mapred.MapTask: Finished spill 0
17/11/24 20:32:32 INFO mapred.MapTask: (RESET) equator 38447780 kv 9611940(38447760) kvi 6990512(27962048)
17/11/24 20:32:33 INFO mapred.MapTask: Spilling map output
17/11/24 20:32:33 INFO mapred.MapTask: bufstart = 38447780; bufend = 66409804; bufvoid = 104857600
17/11/24 20:32:33 INFO mapred.MapTask: kvstart = 9611940(38447760); kvend = 21845332(87381328); length = 13981009/6553600
17/11/24 20:32:33 INFO mapred.MapTask: (EQUATOR) 76895558 kvi 19223884(76895536)
17/11/24 20:32:34 INFO mapred.LocalJobRunner: map > map
17/11/24 20:32:34 INFO mapreduce.Job: map 67% reduce 0%
17/11/24 20:32:38 INFO mapred.MapTask: Finished spill 1
17/11/24 20:32:38 INFO mapred.MapTask: (RESET) equator 76895558 kv 19223884(76895536) kvi 16602456(66409824)
17/11/24 20:32:39 INFO mapred.LocalJobRunner: map > map
17/11/24 20:32:39 INFO mapred.MapTask: Starting flush of map output
17/11/24 20:32:39 INFO mapred.MapTask: Spilling map output
17/11/24 20:32:39 INFO mapred.MapTask: bufstart = 76895558; bufend = 100971510; bufvoid = 104857600
17/11/24 20:32:39 INFO mapred.MapTask: kvstart = 19223884(76895536); kvend = 7185912(28743648); length = 12037973/6553600
17/11/24 20:32:40 INFO mapred.LocalJobRunner: map > sort
17/11/24 20:32:43 INFO mapred.MapTask: Finished spill 2
17/11/24 20:32:43 INFO mapred.Merger: Merging 3 sorted segments
17/11/24 20:32:43 INFO mapred.Merger: Down to the last merge-pass, with 3 segments left of total size: 180000 bytes
17/11/24 20:32:43 INFO mapred.Task: Task:attempt_local1430356259_0001_m_000000_0 is done. And is in the process of committing
17/11/24 20:32:43 INFO mapred.LocalJobRunner: map > sort
17/11/24 20:32:43 INFO mapred.Task: Task 'attempt_local1430356259_0001_m_000000_0' done.
17/11/24 20:32:43 INFO mapred.LocalJobRunner: Finishing task: attempt_local1430356259_0001_m_000000_0
17/11/24 20:32:43 INFO mapred.LocalJobRunner: map task executor complete.
17/11/24 20:32:43 INFO mapred.LocalJobRunner: Waiting for reduce tasks
17/11/24 20:32:43 INFO mapred.LocalJobRunner: Starting task: attempt_local1430356259_0001_r_000000_0
17/11/24 20:32:43 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
17/11/24 20:32:43 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
17/11/24 20:32:43 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
17/11/24 20:32:43 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@f8eab6f
17/11/24 20:32:43 INFO mapreduce.Job: map 100% reduce 0%
17/11/24 20:32:43 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=1336252800, maxSingleShuffleLimit=334063200, mergeThreshold=881926912, ioSortFactor=10, memToMemMergeOutputsThreshold=10
17/11/24 20:32:43 INFO reduce.EventFetcher: attempt_local1430356259_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
17/11/24 20:32:43 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1430356259_0001_m_000000_0 decomp: 60002 len: 60006 to MEMORY
17/11/24 20:32:43 INFO reduce.InMemoryMapOutput: Read 60002 bytes from map-output for attempt_local1430356259_0001_m_000000_0
17/11/24 20:32:43 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 60002, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->60002
17/11/24 20:32:43 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
17/11/24 20:32:43 INFO mapred.LocalJobRunner: 1 / 1 copied.
17/11/24 20:32:43 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
17/11/24 20:32:43 INFO mapred.Merger: Merging 1 sorted segments
17/11/24 20:32:43 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 59996 bytes
17/11/24 20:32:43 INFO reduce.MergeManagerImpl: Merged 1 segments, 60002 bytes to disk to satisfy reduce memory limit
17/11/24 20:32:43 INFO reduce.MergeManagerImpl: Merging 1 files, 60006 bytes from disk
17/11/24 20:32:43 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
17/11/24 20:32:43 INFO mapred.Merger: Merging 1 sorted segments
17/11/24 20:32:43 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 59996 bytes
17/11/24 20:32:43 INFO mapred.LocalJobRunner: 1 / 1 copied.
17/11/24 20:32:43 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
17/11/24 20:32:44 INFO mapred.Task: Task:attempt_local1430356259_0001_r_000000_0 is done. And is in the process of committing
17/11/24 20:32:44 INFO mapred.LocalJobRunner: 1 / 1 copied.
17/11/24 20:32:44 INFO mapred.Task: Task attempt_local1430356259_0001_r_000000_0 is allowed to commit now
17/11/24 20:32:44 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1430356259_0001_r_000000_0' to hdfs://192.168.23.196:9000/output/v1/_temporary/0/task_local1430356259_0001_r_000000
17/11/24 20:32:44 INFO mapred.LocalJobRunner: reduce > reduce
17/11/24 20:32:44 INFO mapred.Task: Task 'attempt_local1430356259_0001_r_000000_0' done.
17/11/24 20:32:44 INFO mapred.LocalJobRunner: Finishing task: attempt_local1430356259_0001_r_000000_0
17/11/24 20:32:44 INFO mapred.LocalJobRunner: reduce task executor complete.
17/11/24 20:32:44 INFO mapreduce.Job: map 100% reduce 100%
17/11/24 20:32:44 INFO mapreduce.Job: Job job_local1430356259_0001 completed successfully
17/11/24 20:32:44 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=1087044
FILE: Number of bytes written=2084932
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=80000004
HDFS: Number of bytes written=54000
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=1
Map output records=10000000
Map output bytes=80000000
Map output materialized bytes=60006
Input split bytes=103
Combine input records=10018000
Combine output records=24000
Reduce input groups=6000
Reduce shuffle bytes=60006
Reduce input records=6000
Reduce output records=6000
Spilled Records=30000
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=1770
Total committed heap usage (bytes)=1776287744
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=40000002
File Output Format Counters
Bytes Written=54000
4. 最后我们到/output/v1下面去看一下最终生成的结果,由于生成的汉字太多,我这里只输出了一部分
[root@master soft]# hadoop fs -ls /output/v1
Found 2 items
-rw-r--r-- 2 root supergroup 0 2017-11-24 20:32 /output/v1/_SUCCESS
-rw-r--r-- 2 root supergroup 54000 2017-11-24 20:32 /output/v1/part-r-00000
[root@master soft]# hadoop fs -ls /output/v1/part-r-00000
-rw-r--r-- 2 root supergroup 54000 2017-11-24 20:32 /output/v1/part-r-00000
[root@master soft]# hadoop fs -tail /output/v1/part-r-00000
1609
攟 1685
攠 1636
攡 1682
攢 1657
攣 1685
攤 1611
攥 1724
攦 1732
攧 1657
攨 1767
攩 1768
攪 1624
好了,搭建的过程确实是麻烦,关于hive的搭建,我们放到后面的博文中去说吧。。。希望本篇对你有帮助。
通过hadoop + hive搭建离线式的分析系统之快速搭建一览的更多相关文章
- 【手摸手,带你搭建前后端分离商城系统】01 搭建基本代码框架、生成一个基本API
[手摸手,带你搭建前后端分离商城系统]01 搭建基本代码框架.生成一个基本API 通过本教程的学习,将带你从零搭建一个商城系统. 当然,这个商城涵盖了很多流行的知识点和技术核心 我可以学习到什么? S ...
- Kubernetes-20:日志聚合分析系统—Loki的搭建与使用
日志聚合分析系统--Loki 什么是Loki? Loki 是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统.它的设计非常经济高效且易于操作,因为它不会 ...
- docker:搭建ELK 开源日志分析系统
ELK 是由三部分组成的一套日志分析系统, Elasticsearch: 基于json分析搜索引擎,Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片 ...
- Hadoop Hive sql 语法详细解释
Hive 是基于Hadoop 构建的一套数据仓库分析系统.它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,能够将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- Hadoop Hive基础sql语法
目录 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的 ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- [转]Hadoop Hive sql语法详解
转自 : http://blog.csdn.net/hguisu/article/details/7256833 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式 ...
- Hadoop Hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询 ...
- 【转载】Hadoop Hive基础sql语法
转自:http://www.cnblogs.com/HondaHsu/p/4346354.html Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在H ...
随机推荐
- GPUImage库的使用
GPUImage开源项目地址:https://github.com/BradLarson/GPUImage GPUImage使用说明:https://github.com/BradLarson/GPU ...
- win10 uwp MVVM 轻量框架
如果在开发过程,遇到多个页面之间,需要传输信息,那么可能遇到设计的问题.如果因为一个页面内包含多个子页面和多个子页面之间的通信问题找不到一个好的解决方法,那么请看本文.如果因为ViewModel代码越 ...
- 量化投资:第8节 A股市场的回测
作者: 阿布 阿布量化版权所有 未经允许 禁止转载 abu量化系统github地址(欢迎+star) 本节ipython notebook 之前的小节回测示例都是使用美股,本节示例A股市场的回测. 买 ...
- [Java Web 第一个项目]客户关系处理系统(CRM)项目总结
一.table的应用: 1.表格的常用属性 基本属性有:width(宽度).height(高度).border(边框值).cellspacing(表格的内宽,即表格与tr之间的间隔).cellpadd ...
- 探索equals()和hashCode()方法
探索equals()和hashCode()方法 在根类Object中,实现了equals()和hashCode()这两个方法,默认: equals()是对两个对象的地址值进行的比较(即比较引用是否相同 ...
- Ubuntu on win10
大家看到这个题目应该都知道这个东西吧,或许也都知道咋安装啥的,我只是想分享一下自己安装它的过程同时可以对那些有需要的人给予帮助!!! 1. 打开开发者模式(如下图) 像上面这样打开开发人员模式,过程会 ...
- 最详细的浏览器css hack
注意点: 网上很多资料中常常把!important也作为一个hack手段,其实这是一个误区.!important常常被我们用来更改样式,而不是兼容hack.造成这个误区的原因是IE6在某些情况下不主动 ...
- Django+Nginx+uWSGI部署
一.介绍 Django的部署可以有多种方式,采用nginx+uwsgi的方式是最常见的一种方式.在这种方式中,将nginx作为服务器前端,接收WEB的所有请求,统一管理请求.nginx把所有静态请求自 ...
- 4天精通arcgis
真是掉进了一个史无前例的坑 --ArcGIS产品线为用户提供一个可伸缩的,全面的GIS平台. 这是百科的介绍,简单来讲,这就是一个地图,可以搞事情. 学的是ArcGIS API for JavaScr ...
- WinForm 菜单控件
一:MenuStrip 菜单条 MenuStrip 是应用程序菜单条的容器. 二:ToolStripMenuItem 像上面图中, 文件 格式 等这些菜单当中的一级菜单以及文件中的 新建 打开 分割条 ...