MYSQL学习(三) --索引详解
创建高性能索引
(一)索引简介
索引的定义
索引,在数据结构的查找那部分知识中有专门的定义。就是把关键字和它对应的记录关联起来的过程。索引由若干个索引项组成。每个索引项至少包含两部分内容。关键字和关键字对应记录在存储器位置信息。索引是组织磁盘文件的一种重要的技术。
数据库的数据量通常比较大,都是存储在磁盘上。通过存储引擎对磁盘文件的数据进行管理。而索引是存储引擎御用快速找到记录的一种数据结构。
2.索引的优点
(1)大大减少服务器需要扫描的数据量。
(2)索引可以帮助服务器避免排序和临时表。
(3)索引可以将随机IO转换成顺序IO。
3.索引三星系统原则
(1)第一星:索引将相关的记录放在一起。即在一系列必要的列上建立索引,不必为where条件里的所有得列建立索引。
(2)第二星:索引中数据的顺序和排序要求的数据的顺序一致。通常将选择性更高的列放在索引列的最前面。
(3)第三星:索引中的列包含查询所需要的所有列。因为索引中已经包含查询所需的全部字段,所以不需要在进行行查询(覆盖索引的定义)。
(二)索引类型
其中,索引是在存储引擎层实现的。因此,不同的执行引擎,自己选择使用实现自己的索引类型。
1.B-Tree 索引
(1)B+树数据结构
B+树的定义是在B树的基础之上定义的。相比B+树,区别部分有两点。
A.非叶子结点只存key,不存储指向数据的指针(ROWID)。
B.叶子结点都保存一个指向相邻节点的指针。
区别A.非叶子节点不存储ROWID,索引项更小。一块可以存储更多的索引项。所以,可以存储更多的非叶子索引项。一个索引项能定位更多的叶子结点。
区别B.叶子节点根据指针链接,范围查询非常简单(如果是B树结构的话,范围查找需要 叶子节点和内部结点之间不停的往返)。
(2)使用B+树索引的存储引擎
InnoDB和MyISAM。
B+树索引是逻辑结构是B+树、物理存储结构是链式存储。
(3)B+树索引适合的查询类型
- 键值范围
- 键前缀查找(只使用最左前缀查找)
- 只访问索引的查询(覆盖索引)
- 全键值
其实是覆盖索引。即索引中的字段能覆盖查询语句中的全部字段(包括分组、排序字段)。
2. 哈希索引
哈希索引是线性索引。是基于哈希表实现。只有精确匹配索引的所有列的查询才有效。
哈希索引存储在哈希表中。逻辑结构是线性表,物理存储结构是顺序存储。
不同的key通过哈希函数计算,可能产生相同的结果。即冲突。哈希索引用的冲突解决算法是链地址法(索引相同的记录指针放在一个链表中)
索引表是线性表的顺序存储。存储在连续的存储空间中。
(1).哈希索引的索引项包含哈希值和行指针。
哈希值:由索引列按照哈希函数计算,获得的哈希值。
行指针:当前哈希值对应的行的指针。
(2).哈希索引特点
- 哈希索引只包含哈希值和行指针。不包含其它列信息。因此,无法避免读取行(无法实现覆盖索引)。
- 哈希索引的索引项不是按照索引值顺序存储的。所以,无法避免排序。
- 哈希索引不支持索引列的匹配查找。
3. 全文索引
全文索引和哈希索引一样,也是一种线程索引。本质是倒序索引。
4.B+树索引和哈希索引的区别
- 哈希索引的特殊性,索引的检索可以一次定位。而B树索引的检索需要工根节点到树枝结点,最后再到叶子结节点。这样多次IO访问。所以,哈希索引的效率远高于B树索引。
- 哈希索引无法避免排序(按照哈希码顺序存储的,不是按照索引列进行顺序存储的)。B树索引在特殊情况下是可以避免排序操作的(索引列作为索引key)。
- 哈希索引只能使用全部索引键来查询,不能用部分索引键来查询。(哈希函数是一种对应关系,所以,必须要所有的参数才能得到哈希码,部分索引建是不可以的)
(三)高性能索引策略
1.独立的列
索引列不能是表达式,也不能是函数。
例如:SELECT actor_id FROM actor WHERE actor_id+1=5 这种写法,就算在actor_id上建立了索引,也不起效。索引列actor_id需要是独立的列才可以。
2.多列索引
多列索引也叫符合索引。即同时对多个列建立索引。比如(A,B,C)。
(1). 需要使用多列索引的场景
- 服务器需要对多个索引进行相交运算(通常是AND条件)。
- 服务器需要对多个索引进行联合操作(通常是OR条件)。
(2).多列索引的生效规则
比如(a,b,c),a,b,c都是排好序的。在任何一段a的下面b都是排好序的。在任何一段b的下面c都是排好序的。多列索引生效原则是从前向后依次生效。如果中间索引列没有起作用,则该索引列之前的索引列起作用。
例如 (1)select * from mytable where a=3 and b>7 and c=3; --a用到了,b也用到了,c没有用到,这个地方b是范围值,也算断点,只不过自身用到了索引。
3.聚簇索引
聚簇索引:不是一种索引类型,是一种数据存储方式。
InnoDB的聚簇索引,在同一个结构中保存了B-Tree索引和数据行。
当表有聚簇索引的时候,它的数据实际上是存储在索引的叶子页(leaf page)中。数据只有一份,所以,一个表只有一个聚簇索引。聚簇是指键值相邻的数据行紧簇的保存在一起。
聚簇索引的叶子节点也是数据节点。而非聚簇索引的叶子结点仍然是索引节点。只不过,它有指向对应数据块的指针。
(1).聚簇索引和二级索引
聚簇索引的定义
在InnoDB中,聚簇索引就是主键索引。如果表中没有定义主键,则InnoDB选择一个唯一的非空索引作为主键。如果没有这样的索引,InnoDB会隐式的定义一个主键来做聚簇索引。
2.聚簇索引特征
数据存储和索引放在一起,找到索引,就找到数据。
由于聚簇索引是将数据跟索引结构放到一块,因此一个表仅有
二级索引定义
非主键索引就是二级索引。
二级索引特征
将数据存储和索引存储分开的结构,索引结构的叶子节点指向数据的对应行。
在InnoDB存储引擎中,在聚簇索引之上创建的索引称之为辅助索引。即二级索引。辅助索引总是需要二次查找的。辅助索引叶子结点存储的不是行的物理位置,而是主键值。(然后根据主键值去聚簇索引中查询数据)
(2).MyISAM和InnoDB的主键索引、二级索引对照图
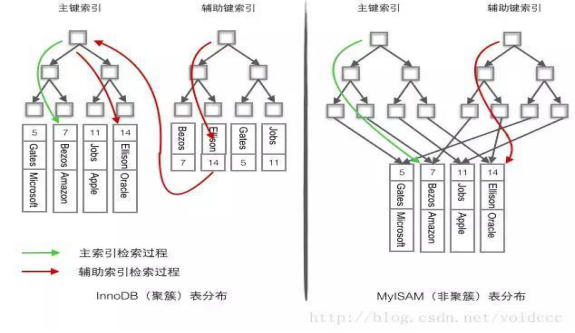
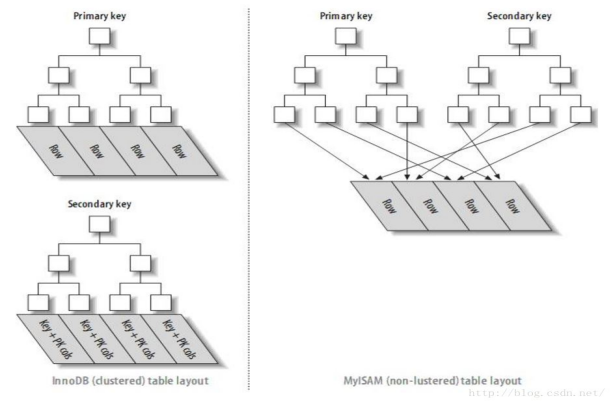
熟悉两种引擎的数据和索引分布,就真正理解了MYSQL的存储和索引查询。
- MyISAM数据分布
如上图所示,MyISAM的数据和索引分开储存的。MyISAM是按照插入的顺序,顺序的存储在磁盘上。类似数组那样顺序存储。
2. MyISAM索引
它对应的不论主键索引还是二级索引,都是典型的B+树索引形式。叶子结点对应的是行指针(行在磁盘中的具体位置)。
3. InnoDB数据分布
如上图所示,InnoDB支持聚簇索引。其中,聚簇索引就是数据。在聚簇索引的叶子节点上,除了主键外,还有事务ID,回滚指针和其余非主键字段。所以,通过主键索引可以直接找到数据.
4. InnoDB主键索引
InnoDB的主键索引和数据分布内容一样。主键索引就是其数据分布。
5.InnoDB二级索引
二级索引也是标准的B树索引。只是叶子结点指的不是行指针,而是主键值。所以,整个叶子结点的索引项是[key+主键]。
6. 聚簇索引的选择和重建
聚簇索引默认是按照主键建立的主键索引。如果没有定义主键,InnoDB会选择一个唯一的非空索引替代。
InnoDB的数据插入是按照主键顺序插入行的。
4.覆盖索引
如果一个索引包含(或者说覆盖)查询的所有字段(查询字段和where条件字段)的值,我们称之为覆盖索引。【由此可见,覆盖索引是索引的一个分类而已】
覆盖索引效率高的几个原因
- 覆盖索引,只需要查找索引,不需要二次查找数据行。少一次操作。
- 覆盖索引是按照索引字段顺序存储。因而,支持范围查找。
5.使用索引扫描来排序
核心思路是:因为索引是有序的。如果排序要求的顺序和索引的顺序一致,就可以直接使用索引的顺序。从而减少对排序的操作。
ORDER BY和查找型查询的限制是一样的:需要满足索引的最左前缀原则,否则,MySQL无法使用索引排序。但有一个特殊情况:就是前导列为常量。例如,有一个索引为(A,B,C),那么这样的SQL语句也会用索引排序。
select id from table where A=2 order by B,C;
第一个索引列A为常量2,2后面对应的B,C也是有序的。所以,这个查出的数据是有序的。
select id from table where A>2 order by B,C; 这个不可以。
(四)维护索引和表
索引如此重要,所以需要对索引和表进行实时维护。确保索引正常工作。
1.找到并修复损坏的表
检查:通过CHECK TABLE来检查引擎是否发生表损坏。
维修:使用 ALTER TABLE innoDB_tbl ENGINE = INNODB;
2.更新索引统计信息
ANALYZE TABLE
3.减少索引和数据碎片
数据存储的碎片有
(1).行碎片
数据行被存在多个地方的多个片段中。
(2).行间碎片
逻辑上顺序的也,或者行在磁盘上不是顺序存储的。行间碎片对全表扫描和聚簇索引扫描影响较大。
(3).剩余空间碎片
数据页中有大量的剩余空间。从而导致服务器读取大量不需要的数据。
修复: OPTIMIZE TABLE ;或者 ALTER TABLE innoDB_tbl ENGINE= <engine>;
(五)为什么 绝大多数索引选择B+树?
MYSQL查询的本质是在一个数据集合中的查找数据。查找常见方式以及场景如下
1.顺序查找,场景:无序,数据量较小。
2.折半(二分)查找,场景:顺序线性表存储。数据量较小。
3.二叉树查找(AVL):场景:二叉树或者平衡二叉树存储(有序链式存储),数据量中等或者较小。
4.多路查找树(B树或B+树):场景:B+树存储(有序存储),可以处理数据量很大的数据。
因为B树存储可以让树的阶(深度)控制在较小的分为内。阶(深度)每少一层,查询就会少一次索引的获取。因而,B树这个类型的存储是MYSQL选择索引数据结构的一个很好的方案。
为什么选择B+树而不是B树?
- B+树非叶子结点不存数据,所以,可以存储更多的结点,因而,树的阶就越小。从树形上来看越矮胖。可以较少IO操作。
- 叶子结点都添加一个指向相邻叶子的指针。范围扫描更容易。
MYSQL学习(三) --索引详解的更多相关文章
- Mysql探索之索引详解,又能和面试官互扯了~
前言 索引是什么?有什么利弊?一旦在面试中被问道,对于新入门的小白可能是个棘手的问题. 本篇文章将会详细讲述什么是索引.索引的优缺点.数据结构等等常见的知识. 什么是索引 索引就是一种的数据结构,存储 ...
- Hibernate学习三----------session详解
© 版权声明:本文为博主原创文章,转载请注明出处 如何获取session对象 1. openSession 2. getCurrentSession - 如果使用getCurrentSession需要 ...
- Struts2框架学习(三)——配置详解
一.struts.xml配置 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE struts ...
- 重新学习MySQL数据库7:详解MyIsam与InnoDB引擎的锁实现
重新学习Mysql数据库7:详解MyIsam与InnoDB引擎的锁实现 说到锁机制之前,先来看看Mysql的存储引擎,毕竟不同的引擎的锁机制也随着不同. 三类常见引擎: MyIsam :不支持事务,不 ...
- Quartz学习——SSMM(Spring+SpringMVC+Mybatis+Mysql)和Quartz集成详解(转)
通过前面的学习,你可能大致了解了Quartz,本篇博文为你打开学习SSMM+Quartz的旅程!欢迎上车,开始美好的旅程! 本篇是在SSM框架基础上进行的. 参考文章: 1.Quartz学习——Qua ...
- 【详细解析】MySQL索引详解( 索引概念、6大索引类型、key 和 index 的区别、其他索引方式)
[详细解析]MySQL索引详解( 索引概念.6大索引类型.key 和 index 的区别.其他索引方式) MySQL索引的概念: 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分 ...
- MySQL 联合索引详解
MySQL 联合索引详解 联合索引又叫复合索引.对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分.例如索引是key index (a,b,c ...
- 最全面的 MySQL 索引详解
什么是索引? 1.索引 索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据.对于索引,会保存在额外的文件中. 2.索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构 ...
- mysql学习3:mysql之my.cnf详解
mysql之my.cnf详解 本文转自:https://www.cnblogs.com/panwenbin-logs/p/8360703.html 以下是 my.cnf 配置文件参数解释: #*** ...
随机推荐
- k8s 命令创建pod
[root@master kubernetes]# kubectl create deploy ngx-dep --image=nginx:1.14-alpine deployment.apps/ng ...
- centos 开机启动服务 systemctl
systemctl 实现开机自启服务 转载起一个好听的名字 最后发布于2018-06-26 13:49:06 阅读数 13473 收藏 展开 systemctl是RHEL 7 的服务管理工具中主要的 ...
- laravel服务容器 转
laravel框架底层解析 本文参考陈昊<Laravel框架关键技术解析>,搭建一个属于自己的简化版服务容器.其中涉及到反射.自动加载,还是需要去了解一下. laravel服务容器 建立项 ...
- 五分钟详解MySQL并发控制及事务原理
在如今互联网业务中使用范围最广的数据库无疑还是关系型数据库MySQL,之所以用"还是"这个词,是因为最近几年国内数据库领域也取得了一些长足进步,例如以TIDB.OceanBase等 ...
- Python之tuple元组详解
元组:有序,一级元素不可以修改.不能被增加或删除(元组是可迭代对象) 一般写法括号内最后面加个英文逗号用来区分: test = (,) test1 = (11,22,) 例: test = (12 ...
- C# 将dataset数据导出到excel中
//添加引用 NPOI.dll //添加 using NPOI.HSSF.UserModel; /// <summary> /// 导出数据到Excel /// </summary& ...
- Redis五种常用数据类型
string 字符串常用操作 1.存入字符串键值对 SET key value 2.批量存储字符串键值对 MSET key value [key value ...] 3.获取一个字符串键值 G ...
- Spark RDD详解 | RDD特性、lineage、缓存、checkpoint、依赖关系
RDD(Resilient Distributed Datasets)弹性的分布式数据集,又称Spark core,它代表一个只读的.不可变.可分区,里面的元素可分布式并行计算的数据集. RDD是一个 ...
- SLF4J :Failed to load class "org.slf4j.impl.StaticLoggerBinder".
错误提示 SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to ...
- user.ini Operation not permitted
rm: cannot remove '/public/.user.ini': Operation not permitted chattr -i .user.ini rm -f .user.ini