RNN以及LSTM简介
转载地址
https://blog.csdn.net/zhaojc1995/article/details/80572098
本文部分参考和摘录了以下文章,在此由衷感谢以下作者的分享!
https://zhuanlan.zhihu.com/p/28054589
https://blog.csdn.net/qq_16234613/article/details/79476763
http://www.cnblogs.com/pinard/p/6509630.html
https://zhuanlan.zhihu.com/p/28687529
http://www.cnblogs.com/pinard/p/6509630.html
https://zhuanlan.zhihu.com/p/26892413
https://zhuanlan.zhihu.com/p/21462488?refer=intelligentunit
RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。首先我们要明确什么是序列数据,摘取百度百科词条:时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系。
RNN的结构及变体
我们从基础的神经网络中知道,神经网络包含输入层、隐层、输出层,通过激活函数控制输出,层与层之间通过权值连接。激活函数是事先确定好的,那么神经网络模型通过训练“学“到的东西就蕴含在“权值“中。
基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。如图。
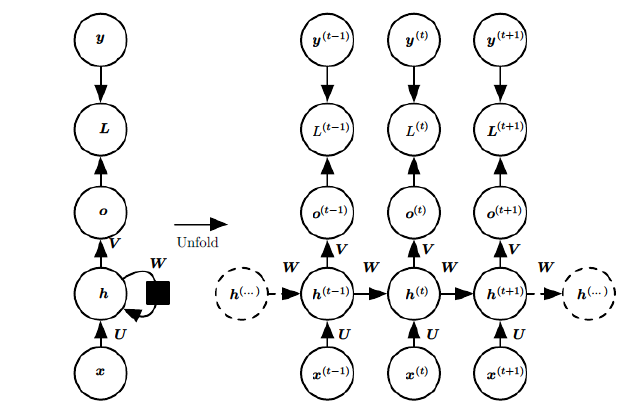
这是一个标准的RNN结构图,图中每个箭头代表做一次变换,也就是说箭头连接带有权值。左侧是折叠起来的样子,右侧是展开的样子,左侧中h旁边的箭头代表此结构中的“循环“体现在隐层。
在展开结构中我们可以观察到,在标准的RNN结构中,隐层的神经元之间也是带有权值的。也就是说,随着序列的不断推进,前面的隐层将会影响后面的隐层。图中O代表输出,y代表样本给出的确定值,L代表损失函数,我们可以看到,“损失“也是随着序列的推荐而不断积累的。
除上述特点之外,标准RNN的还有以下特点:
1、权值共享,图中的W全是相同的,U和V也一样。
2、每一个输入值都只与它本身的那条路线建立权连接,不会和别的神经元连接。
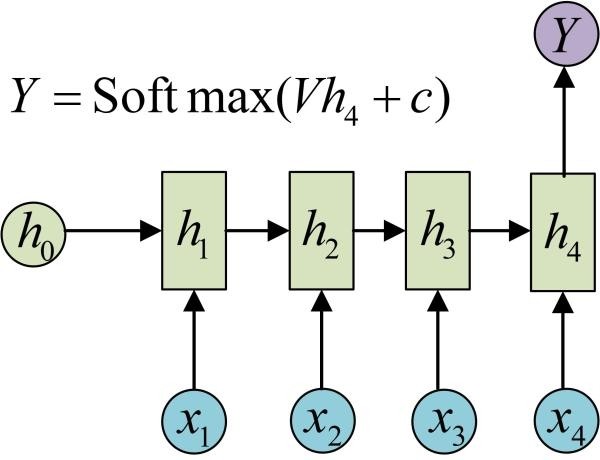
以上是RNN的标准结构,然而在实际中这一种结构并不能解决所有问题,例如我们输入为一串文字,输出为分类类别,那么输出就不需要一个序列,只需要单个输出。如图。
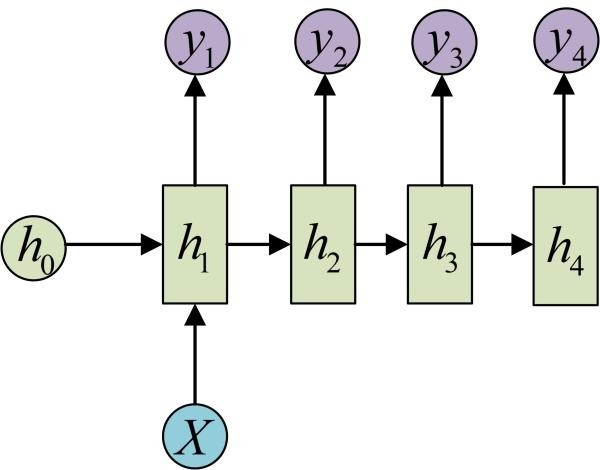
同样的,我们有时候还需要单输入但是输出为序列的情况。那么就可以使用如下结构:
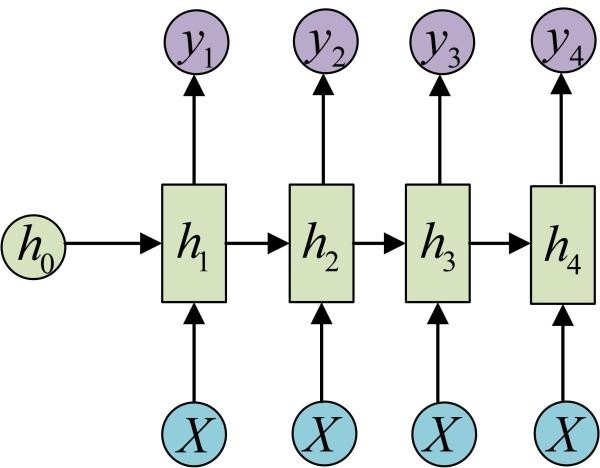
还有一种结构是输入虽是序列,但不随着序列变化,就可以使用如下结构:
原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
下面我们来介绍RNN最重要的一个变种:N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
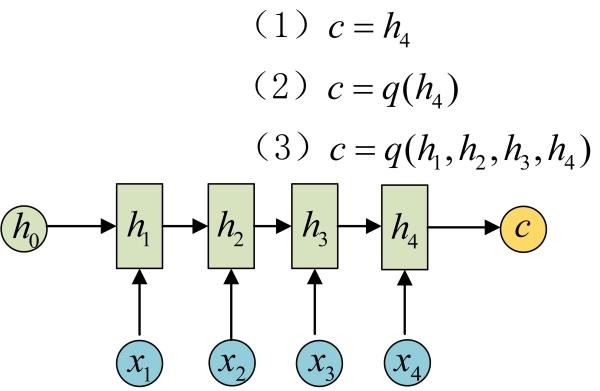
从名字就能看出,这个结构的原理是先编码后解码。左侧的RNN用来编码得到c,拿到c后再用右侧的RNN进行解码。得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
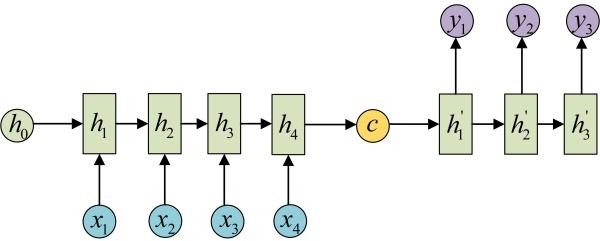
除了以上这些结构以外RNN还有很多种结构,用于应对不同的需求和解决不同的问题。还想继续了解可以看一下下面这个博客,里面又介绍了几种不同的结构。但相同的是循环神经网络除了拥有神经网络都有的一些共性元素之外,它总要在一个地方体现出“循环“,而根据“循环“体现方式的不同和输入输出的变化就形成了多种RNN结构。
标准RNN的前向输出流程
上面介绍了RNN有很多变种,但其数学推导过程其实都是大同小异。这里就介绍一下标准结构的RNN的前向传播过程。
再来介绍一下各个符号的含义:x是输入,h是隐层单元,o为输出,L为损失函数,y为训练集的标签。这些元素右上角带的t代表t时刻的状态,其中需要注意的是,因策单元h在t时刻的表现不仅由此刻的输入决定,还受t时刻之前时刻的影响。V、W、U是权值,同一类型的权连接权值相同。
有了上面的理解,前向传播算法其实非常简单,对于t时刻:
其中ϕ()ϕ()为激活函数,一般来说会选择tanh函数,b为偏置。
t时刻的输出就更为简单:
最终模型的预测输出为:
其中σσ为激活函数,通常RNN用于分类,故这里一般用softmax函数。
RNN的训练方法——BPTT
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,那么求各个参数的梯度便成了此算法的核心。
再次拿出这个结构图观察,需要寻优的参数有三个,分别是U、V、W。与BP算法不同的是,其中W和U两个参数的寻优过程需要追溯之前的历史数据,参数V相对简单只需关注目前,那么我们就来先求解参数V的偏导数。
这个式子看起来简单但是求解起来很容易出错,因为其中嵌套着激活函数函数,是复合函数的求道过程。
RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。
W和U的偏导的求解由于需要涉及到历史数据,其偏导求起来相对复杂,我们先假设只有三个时刻,那么在第三个时刻 L对W的偏导数为:
相应的,L在第三个时刻对U的偏导数为:
可以观察到,在某个时刻的对W或是U的偏导数,需要追溯这个时刻之前所有时刻的信息,这还仅仅是一个时刻的偏导数,上面说过损失也是会累加的,那么整个损失函数对W和U的偏导数将会非常繁琐。虽然如此但好在规律还是有迹可循,我们根据上面两个式子可以写出L在t时刻对W和U偏导数的通式:
整体的偏导公式就是将其按时刻再一一加起来。
前面说过激活函数是嵌套在里面的,如果我们把激活函数放进去,拿出中间累乘的那部分:
或是
我们会发现累乘会导致激活函数导数的累乘,进而会导致“梯度消失“和“梯度爆炸“现象的发生。
至于为什么,我们先来看看这两个激活函数的图像。
这是sigmoid函数的函数图和导数图。

这是tanh函数的函数图和导数图。

它们二者是何其的相似,都把输出压缩在了一个范围之内。他们的导数图像也非常相近,我们可以从中观察到,sigmoid函数的导数范围是(0,0.25],tach函数的导数范围是(0,1],他们的导数最大都不大于1。
这就会导致一个问题,在上面式子累乘的过程中,如果取sigmoid函数作为激活函数的话,那么必然是一堆小数在做乘法,结果就是越乘越小。随着时间序列的不断深入,小数的累乘就会导致梯度越来越小直到接近于0,这就是“梯度消失“现象。其实RNN的时间序列与深层神经网络很像,在较为深层的神经网络中使用sigmoid函数做激活函数也会导致反向传播时梯度消失,梯度消失就意味消失那一层的参数再也不更新,那么那一层隐层就变成了单纯的映射层,毫无意义了,所以在深层神经网络中,有时候多加神经元数量可能会比多家深度好。
你可能会提出异议,RNN明明与深层神经网络不同,RNN的参数都是共享的,而且某时刻的梯度是此时刻和之前时刻的累加,即使传不到最深处那浅层也是有梯度的。这当然是对的,但如果我们根据有限层的梯度来更新更多层的共享的参数一定会出现问题的,因为将有限的信息来作为寻优根据必定不会找到所有信息的最优解。
之前说过我们多用tanh函数作为激活函数,那tanh函数的导数最大也才1啊,而且又不可能所有值都取到1,那相当于还是一堆小数在累乘,还是会出现“梯度消失“,那为什么还要用它做激活函数呢?原因是tanh函数相对于sigmoid函数来说梯度较大,收敛速度更快且引起梯度消失更慢。
还有一个原因是sigmoid函数还有一个缺点,Sigmoid函数输出不是零中心对称。sigmoid的输出均大于0,这就使得输出不是0均值,称为偏移现象,这将导致后一层的神经元将上一层输出的非0均值的信号作为输入。关于原点对称的输入和中心对称的输出,网络会收敛地更好。
RNN的特点本来就是能“追根溯源“利用历史数据,现在告诉我可利用的历史数据竟然是有限的,这就令人非常难受,解决“梯度消失“是非常必要的。解决“梯度消失“的方法主要有:
1、选取更好的激活函数
2、改变传播结构
关于第一点,一般选用ReLU函数作为激活函数,ReLU函数的图像为:

ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了“梯度消失“的发生。但恒为1的导数容易导致“梯度爆炸“,但设定合适的阈值可以解决这个问题。还有一点就是如果左侧横为0的导数有可能导致把神经元学死,不过设置合适的步长(学习旅)也可以有效避免这个问题的发生。
关于第二点,LSTM结构可以解决这个问题。
总结一下,sigmoid函数的缺点:
1、导数值范围为(0,0.25],反向传播时会导致“梯度消失“。tanh函数导数值范围更大,相对好一点。
2、sigmoid函数不是0中心对称,tanh函数是,可以使网络收敛的更好。
LSTM
下面来了解一下LSTM(long short-term memory)。长短期记忆网络是RNN的一种变体,RNN由于梯度消失的原因只能有短期记忆,LSTM网络通过精妙的门控制将短期记忆与长期记忆结合起来,并且一定程度上解决了梯度消失的问题。
由于已经存在了一篇写得非常好的博客,我在这里就直接转载过来,再在其中夹杂点自己的理解。原文连接如下。
作者:朱小虎Neil 链接:https://www.jianshu.com/p/9dc9f41f0b29 來源:简书
在此感谢原作者!
长期依赖(Long-Term Dependencies)问题
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN 可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。

但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。

RNN以及LSTM简介的更多相关文章
- RNN and LSTM saliency Predection Scene Label
http://handong1587.github.io/deep_learning/2015/10/09/rnn-and-lstm.html //RNN and LSTM http://hando ...
- RNN 与 LSTM 的应用
之前已经介绍过关于 Recurrent Neural Nnetwork 与 Long Short-Trem Memory 的网络结构与参数求解算法( 递归神经网络(Recurrent Neural N ...
- Naive RNN vs LSTM vs GRU
0 Recurrent Neural Network 1 Naive RNN 2 LSTM peephole Naive RNN vs LSTM 记忆更新部分的操作,Naive RNN为乘法,LSTM ...
- TensorFlow之RNN:堆叠RNN、LSTM、GRU及双向LSTM
RNN(Recurrent Neural Networks,循环神经网络)是一种具有短期记忆能力的神经网络模型,可以处理任意长度的序列,在自然语言处理中的应用非常广泛,比如机器翻译.文本生成.问答系统 ...
- RNN和LSTM
一.RNN 全称为Recurrent Neural Network,意为循环神经网络,用于处理序列数据. 序列数据是指在不同时间点上收集到的数据,反映了某一事物.现象等随时间的变化状态或程度.即数据之 ...
- 浅谈RNN、LSTM + Kreas实现及应用
本文主要针对RNN与LSTM的结构及其原理进行详细的介绍,了解什么是RNN,RNN的1对N.N对1的结构,什么是LSTM,以及LSTM中的三门(input.ouput.forget),后续将利用深度学 ...
- 3. RNN神经网络-LSTM模型结构
1. RNN神经网络模型原理 2. RNN神经网络模型的不同结构 3. RNN神经网络-LSTM模型结构 1. 前言 之前我们对RNN模型做了总结.由于RNN也有梯度消失的问题,因此很难处理长序列的数 ...
- RNN以及LSTM的介绍和公式梳理
前言 好久没用正儿八经地写博客了,csdn居然也有了markdown的编辑器了,最近花了不少时间看RNN以及LSTM的论文,在组内『夜校』分享过了,再在这里总结一下发出来吧,按照我讲解的思路,理解RN ...
- 深度学习:浅谈RNN、LSTM+Kreas实现与应用
主要针对RNN与LSTM的结构及其原理进行详细的介绍,了解什么是RNN,RNN的1对N.N对1的结构,什么是LSTM,以及LSTM中的三门(input.ouput.forget),后续将利用深度学习框 ...
随机推荐
- Ethical Hacking - Web Penetration Testing(13)
OWASP ZAP(ZED ATTACK PROXY) Automatically find vulnerabilities in web applications. Free and easy to ...
- smartJQueryZoom(smartZoom) 存在的兼容性BUG,以及解决方法
smartJQueryZoom 是一个很好用的库. 它基于jQuery,可以对某个元素(比如 img)进行渲染,渲染之后可以放大这个区域,在做图片浏览时很好用. 但它有一个兼容性BUG: 当浏览器不是 ...
- 关于虎信如何绑定二次验证码_虚拟MFA_两步验证_谷歌身份验证器?
一般点账户名——设置——安全设置中开通虚拟MFA两步验证 具体步骤见链接 虎信如何绑定二次验证码_虚拟MFA_两步验证_谷歌身份验证器? 二次验证码小程序于谷歌身份验证器APP的优势 1.无需下载ap ...
- Python 实现将numpy中的nan和inf,nan替换成对应的均值
nan:not a number inf:infinity;正无穷 numpy中的nan和inf都是float类型 t!=t 返回bool类型的数组(矩阵) np.count_nonzero( ...
- vue学习(十六) 自定义私有过滤器 ES6字符串新方法 填充字符串
<div id="app"> <p>{{data | formatStr('yyyy-MM-dd')}}</p></div> //s ...
- TSGCTF-web Beginner's Web (js内置方法__defineSetter__)
const fastify = require('fastify'); const nunjucks = require('nunjucks'); const crypto = require('cr ...
- 记一次抓包和破解App接口
目录 第一章 · 起源 第二章 · 尝试 第三章 · 脱狱 第四章 · 柳暗花明 第五章 · 终结 第一章 · 起源 某日,想做个爬虫工具,爬某个网站上的数据已做实验之用.大家都知道爬pc网页上的数据 ...
- proj0的具体实现 #CS61B-sp18
https://github.com/Centurybbx/sp18-century/tree/master/proj0 proj0的具体实现在上面的Github中. 在proj0中我明显感受到国外大 ...
- Python File close() 方法
概述 close() 方法用于关闭一个已打开的文件.高佣联盟 www.cgewang.com 关闭后的文件不能再进行读写操作, 否则会触发 ValueError 错误. close() 方法允许调用多 ...
- PHP addcslashes() 函数
实例 在字符 "W" 前添加反斜杠: <?php 高佣联盟 www.cgewang.com$str = addcslashes("Hello World!" ...