2. RDD(弹性分布式数据集Resilient Distributed dataset)
*以下内容由《Spark快速大数据分析》整理所得。
读书笔记的第二部分是讲RDD。RDD 其实就是分布式的元素集合。在 Spark 中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用RDD操作进行求值。而在这一切背后,Spark 会自动将RDD中的数据分发到集群上,并将操作并行化执行。
一、创建RDD
二、操作RDD
1. 普通RDD转化操作
2. Pair RDD转化操作
3. 普通RDD行动操作
4. Pair RDD行动操作
一、创建RDD
创建RDD两种方式:
(1) 读取外部数据集:例如读取字符串 lines=sc.textFile("/path/to/README.md")
(2) 在驱动器程序中对一个集合进行并行化(适用于开发原型和测试,用的不多,因为会将数据先存入内存中): lines=sc.parallelize(["pandas","i like pandas"])
二、操作RDD
RDD支持两种类型的操作:转化操作(transformation)和行动操作(action)。
- 转化操作:由一个RDD生成一个新的RDD。
- 行动操作:对RDD计算出结果。
转化出的RDD是惰性求值的,只有在行动操作中用到这些RDD才会被计算。
为了更好解释RDD操作,我们先走一遍Spark程序或shell会话就行了:
# step1: 从外部数据创建出输入RDD
lines = sc.textFile("README.md")
# step2: 使用如filter()这样的转化操作对RDD进行转化,以定义新的RDD
pythonLines = lines.filter(lambda line: "Python" in line)
# step3: 告诉Spark对需要被重用的中间结果RDD执行persist()操作
# 注:RDD.persist():让Spark把这个RDD缓存下来,使得在多个行动操作中能重用同一个RDD。
pythonLines.persist()
# step4: 使用行动操作(如count()和first()等)来触发一次并行计算,Spark会对计算进行优化后再执行。
pythonLines.count()
或
pythonLines.first()
1. 普通RDD转化操作:
(1.1) map: 用于RDD每个函数,返回结果作为RDD中对应的值。
# 计算RDD中各值的平方
nums = sc.parallelize([1,2,3,4]) # 创建一个RDD
squared = nums.map(lambda x: x * x).collect() # 获得所有计算平方值的结果
for num in squared:
print "%i " % (num)
(1.2) flapMap: 将返回的迭代器”拍扁“。
# 将行数据切分为单词:
lines = sc.parallelize(["hello world", "hi"])
words = lines.map(lambda line: line.split(" "))
word.first() # 返回["hello", "world"]
words = lines.flapMap(lambda line: line.split(" "))
word.first() # 返回"hello"
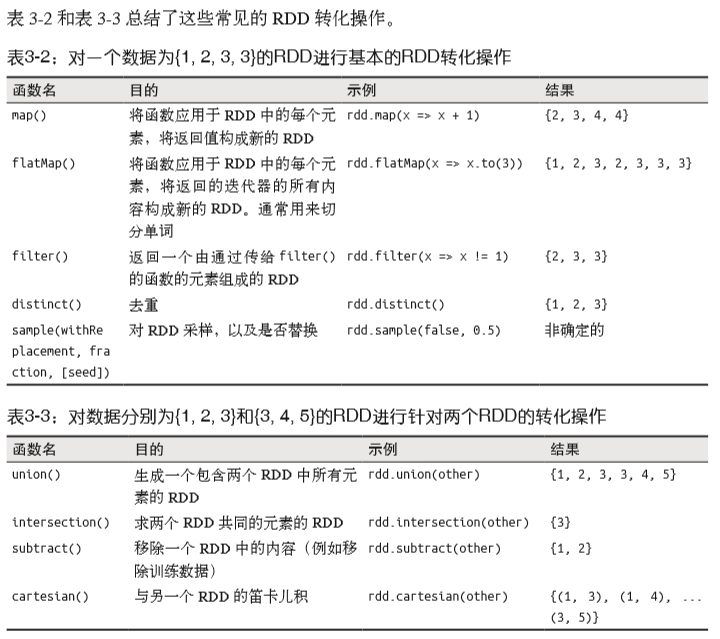
(1.3) 集合操作:有 distinct(), union(), intersection(), subtract() ,笛卡尔积 cartesian() 。
2. Pair RDD转化操作
Pair RDD转化操作:pair RDD是键值对类型的RDD - 由(键,值)二元组组成。

(2.1) 聚合操作:
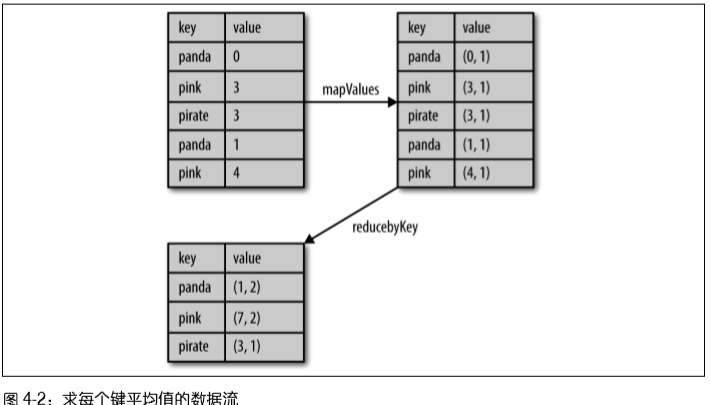
例子1 - 图4-2:计算每个键对应的平均值方法1:用reduceByKey()和mapValues()
rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
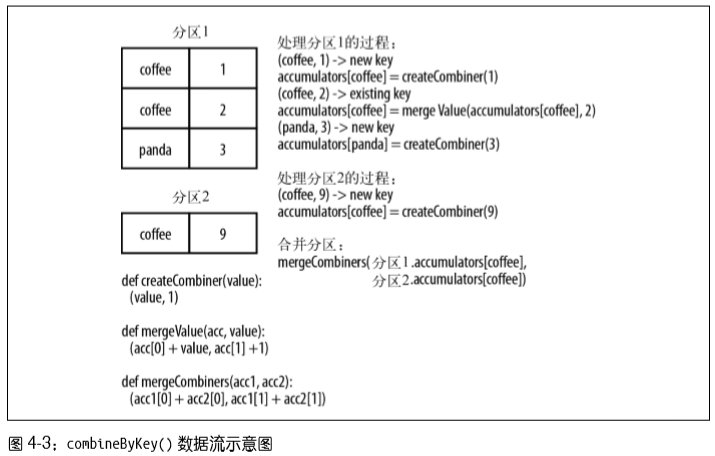
例子2 - 图4-3:计算每个键对应的平均值方法2:用combineByKey()
sumCount = nums.combineByKey((lambda x: (x, 1)),
(lambda x, y: (x[0] + y, x[1] + 1)),
(lambda x, y: (x[0] + y[0], x[1] + y[1])))
sumCount.map(lambda key, xy: (key, xy[0]/xy[1])).collectAsMap()
例子3:单词计数方法1
rdd = sc.textFile("s3://...")
words = rdd.flatMap(lambda x: x.split(" "))
result = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
例子4:单词计数方法2
result= rdd.flatMap(lambda x: x.split(" ")).countByValue()
(2.2) 数据分组:
- groupByKey() : 使用RDD的键对数据进行分组。对于一个有类型K的键和类型V的值组成的RDD,所得结果RDD类型会是[K, Iterable[V]].
- cogroup() : 对多个共享同一个键的RDD进行分组,对两个键的类型均为K,而值的类型分别为V和W的RDD进行cogroup(),得到结果是[K, (Iterable[V], Iterable[W])]。
(2.3) 连接
支持右外连接、左外连接、交叉连接以及内连接: leftOuterJoin(), rightOuterJoin() 和 join() 。
(2.4) 排序
例:以字符串顺序对整数进行自定义升序排序
rdd.sortByKey(ascending=True, numPartitions=None, keyfunc=lambda x: str(x))
3. 普通RDD行动操作
- count() :返回计数结果。
- take() : 收集RDD中的一些元素,然后方便在本地遍历这些元素。
- collect() : 获取整个RDD中的数据,前提是整个数据集在放的进内存,不建议在大规模数据上使用。
例子:
print "Input had " + badLinesRDD.count() + " concerning lines"
print "Here are 10 examples:"
for line in badLinesRDD.take(10):
print line
4. Pair RDD行动操作

2. RDD(弹性分布式数据集Resilient Distributed dataset)的更多相关文章
- RDD(弹性分布式数据集)及常用算子
RDD(弹性分布式数据集)及常用算子 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据 处理模型.代码中是一个抽象类,它代表一个 ...
- RDD弹性分布式数据集的基本操作
RDD的中文解释是弹性分布式数据集.构造的数据集的时候用的是List(链表)或者Array数组类型/* 使用makeRDD创建RDD */ /* List */ val rdd01 = sc.make ...
- 第1章 RDD概念 弹性分布式数据集
第1章 RDD概念 弹性分布式数据集 1.1 RDD为什么会产生 RDD是Spark的基石,是实现Spark数据处理的核心抽象.那么RDD为什么会产生呢? Hadoop的MapReduce是一种基于 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- Scala当中什么是RDD(Resilient Distributed Datasets)弹性分布式数据集
RDD(Resilient Distributed Datasets)弹性分布式数据集.你不好理解的话,可以把RDD就可以看成是一个简单的"动态数组"(比如ArrayList),对 ...
- Spark - RDD(弹性分布式数据集)
org.apache.spark.rddRDDabstract class RDD[T] extends Serializable with Logging A Resilient Distribut ...
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
随机推荐
- yii2框架路径相关
调用YII框架中jquery:Yii::app()->clientScript->registerCoreScript('jquery'); framework/web/js/source ...
- 微信小程序中使用 npm包管理 (保姆式教程)
打开自己的微信小程序项目,在勾选这个选项 然后在第一次应该是失败的提示"没有找到可以构建的npm包". 在 小程序的根目录下比如我的项目如图: 右击鼠标在终端中打开. 然后输入:n ...
- linux网卡驱动程序架构
以cs89x0网卡驱动为例:
- 多测师讲解自动化 _rf自动化需要总结的问题(2)_高级讲师肖sir
1.口述整个自动化环境搭建的过程.以及环境搭建需要哪些工具包以及对应的工具包的作用?2.RF框架的原理?常见的功能?3.公司自动化测试的流程?1.自动化需求的评审2.自动化场景的选择3.自动化工具的选 ...
- 非科班8k,靠这套知识体系收入暴涨100%!
我是18年毕业,非科班,毕业即进入互联网行业.坐标深圳,java程序员,当时到手薪资8k左右. bat等大厂月薪薪资动辄20k,25k,还不包括"签字费",福利和奖金.当然,薪资也 ...
- utf-8和utf-8-sig的区别
前言:在写入csv文件中,出现了乱码的问题. 解决:utf-8 改为utf-8-sig 区别如下: 1."utf-8" 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有 ...
- js 判断客户端 和 asp.net/C#判断客户端类型
1.js 判断客户端 <script language="JavaScript"> <!-- onload = function browserRedirect( ...
- 无法为数据库 'tempdb' 中的对象分配空间,因为 'PRIMARY' 文件组已满
错误描述 消息 1105,级别 17,状态 2,第 1 行无 法为数据库 'tempdb' 中的对象 'dbo.SORT temporary run storage: 140737503494144 ...
- Sentinel流控规则
流控规则 注:Sentinel的监控页面一开始是没有东西,需要对监控的服务发起请求后才会出现 资源名:唯一名称,默认请求路径 针对来源:Sentinel可以针对调用者进行限流,填写微服务名,指定对哪个 ...
- LeetCode 45跳跃游戏&46全排列
原创公众号:bigsai,回复进群加入力扣打卡群. 昨日打卡:LeetCode 42字符串相乘&43通配符匹配 跳跃游戏 题目描述: 给定一个非负整数数组,你最初位于数组的第一个位置. 数组中 ...