MapReduce编程练习(四),统计多个输入文件学生的平均成绩,
问题描述:
在输入文件中,有多个,其中每个输入文件代表一个学生的各科成绩,其中每行的数据形式为<科目,成绩>,你需要将每个文件中的每科目的成绩进行统计,然后求平均值。
输入文件格式:
这里有三个学生:
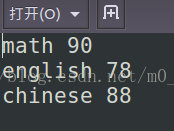
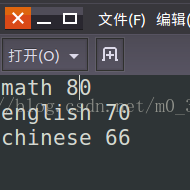
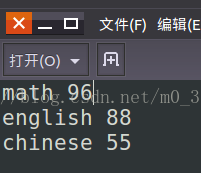
输出文件格式:
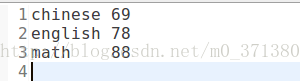
实例代码:
package com.test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class StudentAverage {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
@SuppressWarnings("deprecation")
Job job = new Job(new Configuration(), "StudentAverage");
job.setJarByClass(StudentAverage.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/Student/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/Student/output"));
job.waitForCompletion(true);
System.out.println("运行结束!");
}
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable>{
protected void map(LongWritable key, Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws java.io.IOException, InterruptedException {
String[] data = value.toString().split(" ");
context.write(new Text(data[0]), new IntWritable(Integer.parseInt(data[1])));
};
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, java.lang.Iterable<IntWritable> values, Context context)
throws java.io.IOException, InterruptedException {
int average = 0;
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
average = sum / 3;
context.write(new Text(key), new IntWritable(average));
};
}
}
MapReduce编程练习(四),统计多个输入文件学生的平均成绩,的更多相关文章
- YTU 2626: B 统计程序设计基础课程学生的平均成绩
2626: B 统计程序设计基础课程学生的平均成绩 时间限制: 1 Sec 内存限制: 128 MB 提交: 427 解决: 143 题目描述 程序设计基础课程的学生成绩出来了,老师需要统计出学生 ...
- 问题 C: B 统计程序设计基础课程学生的平均成绩
题目描述 程序设计基础课程的学生成绩出来了,老师需要统计出学生个数和平均成绩.学生信息的输入如下: 学号(num) 学生姓名(name) ...
- MapReduce编程:词频统计
首先在项目的src文件中需要加入以下文件,log4j的内容为: log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j ...
- MapReduce编程实例4
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例2
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例6
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例5
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例3
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- 假期学习【五】RDD编程实验四
今天完成了实验四的第二问和第三问 第二题 对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C.下面是输入文件和输出文件的一个样 ...
随机推荐
- 关于BackTop按钮的实现
今天在处理,首页面的制作的时候,在实现backtop按键的时候,有些思路,作为记录. 功能为,点击backtop即可,立马跳到首页的最上面,且backtop只有在页面后1/2处才显示出来. 首先,我们 ...
- zookeeper选举算法
一.ZAB协议三阶段 – 发现(Discovery),即选举Leader过程– 同步(Synchronization),选举出新的Leader后,Follwer或者Observer从Leader同步最 ...
- github与svn的区别
github与svn都属于版本控件系统,但是两者不同于,github是分布式的,svn不是分布的是属于集中式的. 1) 最核心的区别Git是分布式的,而Svn不是分布的.能理解这点,上手会很容 ...
- light-rtc: 理念与实践
在与同行交流过程中,发现很多同行对 WebRTC 改动太多,导致无法升级 WebRTC 版本.而 WebRTC 开源社区的快速迭代,让他们感到欣喜又焦虑:开源社区的迭代效果,是不是超过了他们对 Web ...
- 解析SwiftUI布局细节(三)地图的基本操作
前言 前面的几篇文章总结了怎样用 SwiftUI 搭建基本框架时候的一些注意点(和这篇文章在相同的分类里面,有需要了可以点进去看看),这篇文章要总结的东西是用地图数据处理结合来说的,通过这篇文章我们能 ...
- SpringBoot 集成Elasticsearch进行简单增删改查
一.引入的pom文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=" ...
- 设计模式之委派模式(Delegate Pattern)深入浅出
学习目标:精简程序逻辑,提升代码的可读性. 内容定位:希望通过对委派模式的学习,让自己写出更加优雅的代码的人群. 委派模式定义: 委派模式(Delegate Pattern)的基本作用是负责任务的调度 ...
- Hadoop伪分布式模式
搭建在单一服务器 基于官方文档 http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster ...
- LeetCode485 最大连续1的个数
给定一个二进制数组, 计算其中最大连续1的个数. 示例 1: 输入: [1,1,0,1,1,1] 输出: 3 解释: 开头的两位和最后的三位都是连续1,所以最大连续1的个数是 3. 注意: 输入的数组 ...
- LeetCode662 二叉树最大宽度
给定一个二叉树,编写一个函数来获取这个树的最大宽度.树的宽度是所有层中的最大宽度.这个二叉树与满二叉树(full binary tree)结构相同,但一些节点为空. 每一层的宽度被定义为两个端点(该层 ...