copy,集合
一、基础数据类型补充:

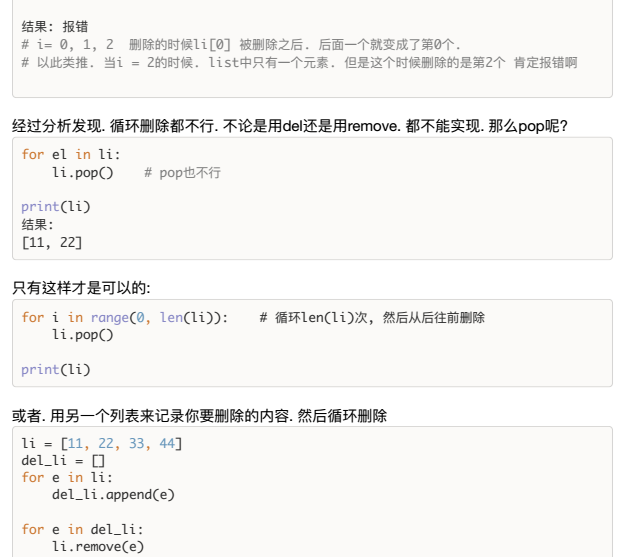


1种方法:删除列表里面的元素时,一定不能循环列表,会出错。可以循环索引,然后循环删除开头或结尾这个位置的元素(原开头结尾的元素被删除之后,会有新的元素顶上来)。
2种方法:把要删除的元素放在一个新列表中,然后循环新列表,删除老列表。(循环过称中元素索引并没有发生变化,所以不会出错)

二、集合:
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
1,集合的创建。
set1 = set({1,2,'barry'})
set2 = {1,2,'barry'}
print(set1,set2) # {1, 2, 'barry'} {1, 2, 'barry'}
2,集合的增。

set1 = {'alex','wusir','ritian','egon','barry'}
set1.add('景女神')
print(set1)
#update:迭代着增加
set1.update('A')
print(set1)
set1.update('老师')
print(set1)
set1.update([1,2,3])
print(set1)
3,集合的删。
set1 = {'alex','wusir','ritian','egon','barry'}
set1.remove('alex') # 删除一个元素
print(set1)
set1.pop() # 随机删除一个元素
print(set1)
set1.clear() # 清空集合
print(set1)
del set1 # 删除集合
print(set1)
4,集合的其他操作:
4.1 交集。(& 或者 intersection)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
4.2 并集。(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7}
print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7}
4.3 差集。(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2)) # {1, 2, 3}
4.4反交集。 (^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
4.5子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
5,frozenset不可变集合,让集合变成不可变类型。
s = frozenset('barry')
print(s,type(s)) # frozenset({'a', 'y', 'b', 'r'}) <class 'frozenset'>
三、深浅copy
1,先看赋值运算。
l1 = [1,2,3,['barry','alex']]
l2 = l1 l1[0] = 111
print(l1) # [111, 2, 3, ['barry', 'alex']]
print(l2) # [111, 2, 3, ['barry', 'alex']] l1[3][0] = 'wusir'
print(l1) # [111, 2, 3, ['wusir', 'alex']]
print(l2) # [111, 2, 3, ['wusir', 'alex']]
对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的。
2,浅拷贝copy。
l1 = [1,2,3,['barry','alex']]
l2 = l1.copy()
print(l1,id(l1)) # [1, 2, 3, ['barry', 'alex']] 2380296895816
print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2380296895048
l1[1] = 222
print(l1,id(l1)) # [1, 222, 3, ['barry', 'alex']] 2593038941128
print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2593038941896
l1[3][0] = 'wusir'
print(l1,id(l1[3])) # [1, 2, 3, ['wusir', 'alex']] 1732315659016
print(l2,id(l2[3])) # [1, 2, 3, ['wusir', 'alex']] 1732315659016
对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
3,深拷贝deepcopy。
import copy
l1 = [1,2,3,['barry','alex']]
l2 = copy.deepcopy(l1) print(l1,id(l1)) # [1, 2, 3, ['barry', 'alex']] 2915377167816
print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2915377167048 l1[1] = 222
print(l1,id(l1)) # [1, 222, 3, ['barry', 'alex']] 2915377167816
print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2915377167048 l1[3][0] = 'wusir'
print(l1,id(l1[3])) # [1, 222, 3, ['wusir', 'alex']] 2915377167240
print(l2,id(l2[3])) # [1, 2, 3, ['barry', 'alex']] 2915377167304
对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变。
copy,集合的更多相关文章
- is == id 的用法;代码块;深浅copy;集合
1 内容总览 is == id 用法 代码块 同一代码块下的缓存机制 (字符串驻留机制) 不同代码块下的缓存机制 (小数据池) 总结 集合(了解) 深浅copy 2 具体内容 id is == # i ...
- python基础3(元祖、字典、深浅copy、集合、文件处理)
本次内容: 元祖 字典 浅copy和深copy 集合 文件处理 1.1元祖 元祖(tuple)与列表类似,不同之处在于元祖的元素不能修改,元祖使用小括号(),列表使用方括号[].元祖创建很简单,只需要 ...
- iOS 集合的深复制与浅复制
概念 对象拷贝有两种方式:浅复制和深复制.顾名思义,浅复制,并不拷贝对象本身,仅仅是拷贝指向对象的指针:深复制是直接拷贝整个对象内存到另一块内存中. 一图以蔽之 再简单些说:浅复制就是指针拷贝:深复制 ...
- 文成小盆友python-num3 集合,函数,-- 部分内置函数
本接主要内容: set -- 集合数据类型 函数 自定义函数 部分内置函数 一.set 集合数据类型 set集合,是一个无序且不重复的元素集合 集合基本特性 无序 不重复 创建集合 #!/bin/en ...
- Day2-列表、字符串、字典、集合
一.列表 定义列表:通过下标访问列表中的内容,从0开始 >>> name = ["zhang","wang","li",& ...
- Python【第二课】 字符串,列表,字典,集合,文件操作
本篇内容 字符串操作 列表,元组操作 字典操作 集合操作 文件操作 其他 1.字符串操作 1.1 字符串定义 特性:不可修改 字符串是 Python 中最常用的数据类型.我们可以使用引号('或&quo ...
- 关于Python元祖,列表,字典,集合的比较
定义 方法 列表 可以包含不同类型的对象,可以增减元素,可以跟其他的列表结合或者把一个列表拆分,用[]来定义的 eg:aList=[123,'abc',4.56,['inner','list'], ...
- Python学习三|列表、字典、元组、集合的特点以及类的一些定义
此表借鉴于他人 定义 使用方法 列表 可以包含不同类型的对象,可以增减元素,可以跟其他的列表结合或者把一个列表拆分,用[]来定义的 eg:aList=[123,'abc',4.56,['inner', ...
- copy&mutableCopy 浅拷贝(shallow copy)深拷贝 (deep copy)
写在前面 其实看了这么多,总结一个结论: 拷贝的初衷的目的就是为了:修改原来的对象不能影响到拷贝出来得对象 && 修改拷贝出来的对象也不能影响到原来的对象 所以,如果原来对象就是imm ...
- python的列表元组字典集合比较
定义 方法 列表 可以包含不同类型的对象,可以增减元素,可以跟其他的列表结合或者把一个列表拆分,用[]来定义的 eg:aList=[123,'abc',4.56,['inner','list'],7- ...
随机推荐
- 远程调用get和post请求 将返回结果转换成实体类
package org.springblade.desk.utils; import org.apache.http.client.ResponseHandler; import org.apache ...
- 什么是ResultSet
概述: 在查询数据库后会返回一个ResultSet,它就像是查询结果集的一张数据表. ResultSet对象维护了一个游标,指向当前的数据行.开始的时候这个游标指向的是第一行. 注意: 如果调用了Re ...
- 【Redis】内部数据结构自顶向下梳理
本博客将顺着自顶向下的思路梳理一下Redis的数据结构体系,从数据库到对象体系,再到底层数据结构.我将基于我的一个项目的代码来进行介绍:daredis.该项目中,使用Java实现了Redis中所有的数 ...
- webapplicationContext之ServletContext等相关概念说明
1)ServletContext是一个全局的储存信息的空间,所有用户共用一个,其信息必须是线程安全且共享的. ServletContext有一个接口定义:ServletContext接口.此接口定义了 ...
- SpringBoot+Prometheus+Grafana实现应用监控和报警
一.背景 SpringBoot的应用监控方案比较多,SpringBoot+Prometheus+Grafana是目前比较常用的方案之一.它们三者之间的关系大概如下图: 关系图 二.开发SpringBo ...
- Element UI组件说明
-<el-card>-查询及展示列表页面-[v-show]属性控制显示隐藏-<el-card class="box-card" >-多标签页面-<el ...
- 性能超四倍的高性能.NET二进制序列化库
二进制序列化在.NET中有很多使用场景,如我们使用分布式缓存时,通常将缓存对象序列化为二进制数据进行缓存,在ASP.NET中,很多中间件(如认证等)也都是用了二进制序列化. 在.NET中我们通常使用S ...
- TCP VS UDP
摘要:计算机网络基础 引言 网络协议是每个前端工程师都必须要掌握的知识,TCP/IP 中有两个具有代表性的传输层协议,分别是 TCP 和 UDP,本文将介绍下这两者以及它们之间的区别. 一.TCP/I ...
- 【C++】《C++ Primer 》第三章
第三章 字符串.向量和数组 一.命名空间的using声明 使用某个命名空间:例如 using std::cin表示使用命名空间std中的名字cin. 头文件的代码一般不应该使用using声明,这是因为 ...
- MySQL45讲笔记-事务隔离级别,为什么你改了数据我看不见
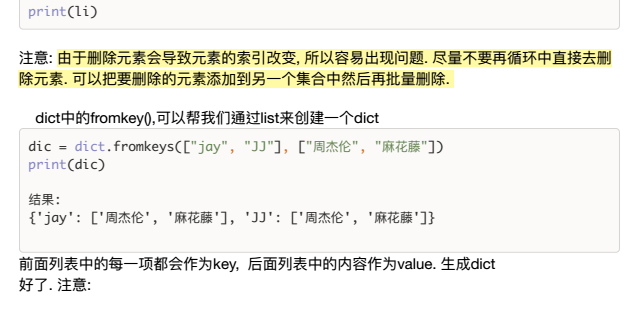
简单来说,事务就是要保证一组数据库操作,要么全部成功,要么全部失败.在MySQL中,事务至此是在引擎层实现的,但并不是所有的MySQL引擎都支持事务,这也是MyISAM被InnoDB取代的原因之一. ...