使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入
数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好、更快的决策。Amazon Simple Storage Service(amazon S3)是针对结构化和非结构化数据的高性能对象存储服务,可以用来作为数据湖底层的存储服务。
然而许多用例,如从上游关系数据库执行变更数据捕获(CDC)到基于Amazon S3的数据湖,都需要在记录级别处理数据,执行诸如从数据集中插入、更新和删除单条记录的操作需要处理引擎读取所有对象(文件),进行更改,并将整个数据集重写为新文件。此外为使数据湖中的数据以近乎实时的方式被访问,通常会导致数据被分割成许多小文件,从而导致查询性能较差。Apache Hudi是一个开源的数据管理框架,它使您能够在Amazon S3 数据湖中以记录级别管理数据,从而简化了CDC管道的构建,并使流数据摄取变得高效,Hudi管理的数据集使用开放存储格式存储在Amazon S3中,通过与Presto、Apache Hive、Apache Spark和AWS Glue数据目录的集成,您可以使用熟悉的工具近乎实时地访问更新的数据。Amazon EMR已经内置Hudi,在部署EMR集群时选择Spark、Hive或Presto时自动安装Hudi。
本篇文章将展示如何构建一个CDC管道,该管道使用AWS数据库迁移服务(AWS DMS)从Amazon关系数据库服务(Amazon RDS)for MySQL数据库中捕获数据,并将这些更改应用到Amazon S3中的一个数据集上。Apache Hudi包含了HoodieDeltaStreamer实用程序,它提供了一种从许多源(如分布式文件系统DFS或Kafka)摄取数据的简单方法,它可以自己管理检查点、回滚和恢复,因此不需要跟踪从源读取和处理了哪些数据,这使得使用更改数据变得很容易,同时还可以在接收数据时对数据进行基于SQL的轻量级转换,有关详细信息,请参见写Hudi表。ApacheHudi版本0.5.2提供了对带有HoodieDeltaStreamer的AWS DMS支持,并在Amazon EMR 5.30.x和6.1.0上可用。
2. 架构
下图展示了构建CDC管道而部署的体系结构。
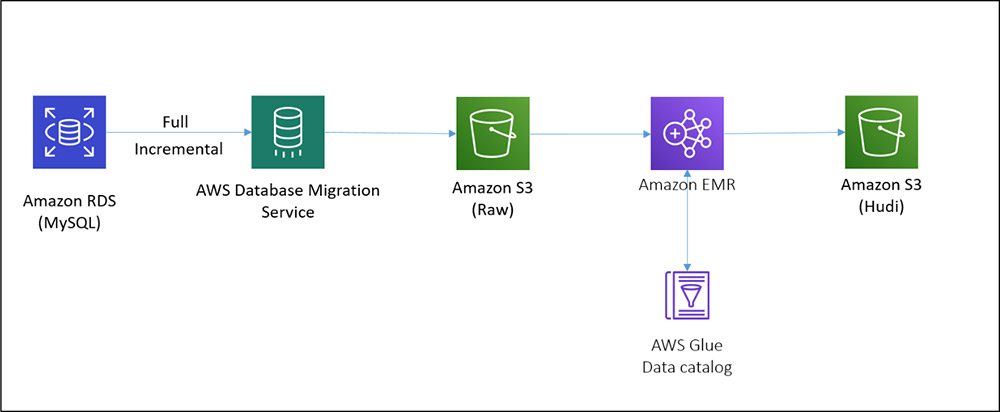
在该架构中,我们在Amazon RDS上有一个MySQL实例,AWS-DMS将完整的增量数据(使用AWS-DMS的CDC特性)以Parquet格式存入S3中,EMR集群上的HoodieDeltaStreamer用于处理全量和增量数据,以创建Hudi数据集,当更新MySQL数据库中的数据后,AWS-DMS任务将获取这些更改并将它们变更到原始的S3存储桶中。HoodieDeltastreamer作业可以在EMR集群上以特定的频率或连续模式运行,以将这些更改应用于Amazon S3数据湖中的Hudi数据集,然后可以使用SparkSQL、Presto、运行在EMR集群上的Apache Hive和Amazon Athena等工具查询这些数据。
3. 部署解决方案资源
使用AWS CloudFormation在AWS帐户中部署这些组件,选择一个AWS区域部署以下服务:
- Amazon EMR
- AWS DMS
- Amazon S3
- Amazon RDS
- AWS Glue
- AWS Systems Manager
在部署CloudFormation模板之前需要先满足如下条件:
- 拥有一个至少有两个公共子网的专有网络(VPC)。
- 有一个S3存储桶来从EMR集群收集日志,需要在同一个AWS区域。
- 具有AWS身份和访问管理(IAM)角色DMS VPC角色
dms-vpc-role。 - 如果要使用AWS Lake Formation权限模型在帐户中部署,请验证以下设置:
- 用于部署技术栈的IAM用户需要被添加为Lake Formation下的data lake administrator,或者用于部署堆栈的IAM用户具有在AWS Glue data Catalog中创建数据库的IAM权限。
- Lake Formation下的数据目录(Data Catalog)设置配置为仅对新数据库和新数据库中的新表使用IAM访问控制,这将确保仅使用IAM权限控制对数据目录(Data Catalog)中新创建的数据库和表的所有访问权限。

IAMAllowedPrincipals在Lake Formation database creators页面上被授予数据库创建者权限。

如果此权限不存在,请通过选择授予并选择授予创建数据库权限。
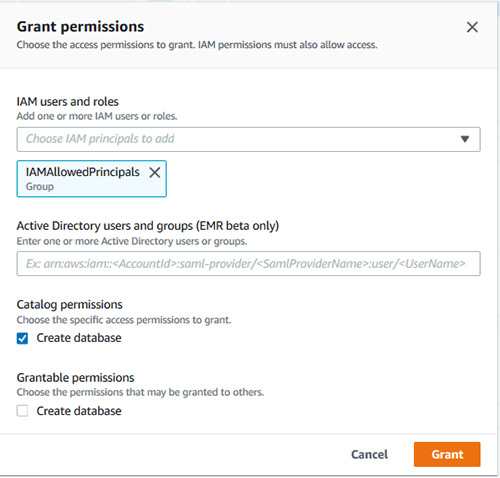
这些设置是必需的,以便仅使用IAM控制对数据目录对象的所有权限。
4. 启动CloudFormation
要启动CloudFormation栈,请完成以下步骤
选择启动CloudFormation栈
在Parameters部分提供必需的参数,包括一个用于存储Amazon EMR日志的S3 Bucket和一个您想要访问Amazon RDS for MySQL的CIDR IP范围。

遵循CloudFormation创建向导,保持其余默认值不变。
在最后一个页面上,选择允许AWS CloudFormation可能会使用自定义名称创建IAM资源。
选择
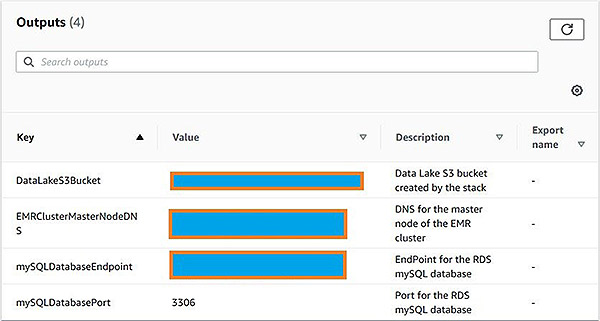
创建。当创建完成后,在CloudFormation堆栈的Outputs选项卡上记录S3 Bucket、EMR集群和Amazon RDS for MySQL的详细信息。
CloudFormation模板为EMR集群使用m5.xlarge和m5.2xlarge实例,如果这些实例类型在你选择用于部署的区域或可用性区域中不可用,那么CloudFormation将会创建失败。如果发生这种情况,请选择实例类型可用的区域或子网。
CloudFormation还使用必要的连接属性(如dataFormat、timestampColumnName和parquetTimestampInMillisecond)创建和配置AWS DMS端点和任务。
作为CloudFormation栈的一部分部署的数据库实例已经被创建,其中包含AWS-DMS在数据库的CDC模式下工作所需的设置。
binlog_format=ROWbinlog_checksum=NONE
另外在RDS DB实例上启用自动备份,这是AWS-DMS进行CDC所必需的属性。
5. 运行端到端数据流
CloudFormation部署好后就可以运行数据流,将MySQL中的完整和增量数据放入数据湖中的Hudi数据集。
- 作为最佳实践,请将binlog保留至少24小时。使用SQL客户端登录Amazon RDS for MySQL数据库并运行以下命令:
call mysql.rds_set_configuration('binlog retention hours', 24)
- 在dev数据库中创建表:
create table dev.retail_transactions(
tran_id INT,
tran_date DATE,
store_id INT,
store_city varchar(50),
store_state char(2),
item_code varchar(50),
quantity INT,
total FLOAT);
- 创建表时,将一些测试数据插入数据库:
insert into dev.retail_transactions values(1,'2019-03-17',1,'CHICAGO','IL','XXXXXX',5,106.25);
insert into dev.retail_transactions values(2,'2019-03-16',2,'NEW YORK','NY','XXXXXX',6,116.25);
insert into dev.retail_transactions values(3,'2019-03-15',3,'SPRINGFIELD','IL','XXXXXX',7,126.25);
insert into dev.retail_transactions values(4,'2019-03-17',4,'SAN FRANCISCO','CA','XXXXXX',8,136.25);
insert into dev.retail_transactions values(5,'2019-03-11',1,'CHICAGO','IL','XXXXXX',9,146.25);
insert into dev.retail_transactions values(6,'2019-03-18',1,'CHICAGO','IL','XXXXXX',10,156.25);
insert into dev.retail_transactions values(7,'2019-03-14',2,'NEW YORK','NY','XXXXXX',11,166.25);
insert into dev.retail_transactions values(8,'2019-03-11',1,'CHICAGO','IL','XXXXXX',12,176.25);
insert into dev.retail_transactions values(9,'2019-03-10',4,'SAN FRANCISCO','CA','XXXXXX',13,186.25);
insert into dev.retail_transactions values(10,'2019-03-13',1,'CHICAGO','IL','XXXXXX',14,196.25);
insert into dev.retail_transactions values(11,'2019-03-14',5,'CHICAGO','IL','XXXXXX',15,106.25);
insert into dev.retail_transactions values(12,'2019-03-15',6,'CHICAGO','IL','XXXXXX',16,116.25);
insert into dev.retail_transactions values(13,'2019-03-16',7,'CHICAGO','IL','XXXXXX',17,126.25);
insert into dev.retail_transactions values(14,'2019-03-16',7,'CHICAGO','IL','XXXXXX',17,126.25);
现在使用AWS DMS将这些数据推送到Amazon S3。
- 在AWS DMS控制台上,运行hudiblogload任务。
此任务将表的全量数据加载到Amazon S3,然后开始写增量数据。

如果第一次启动AWS-DMS任务时系统提示测试AWS-DMS端点,那么可以先进行测试,在第一次启动AWS-DMS任务之前测试源和目标端点通常是一个好的实践。
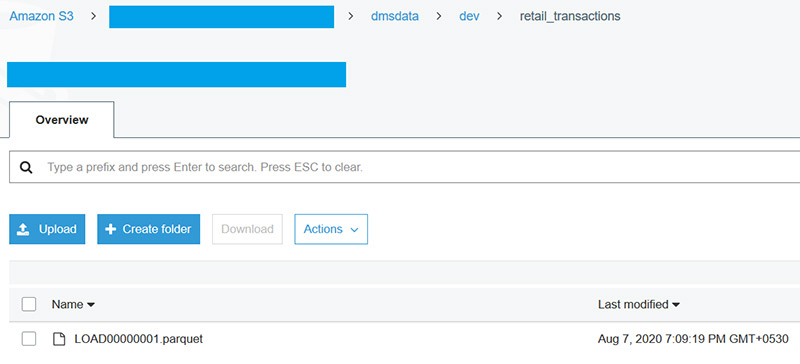
几分钟后,任务的状态将变更为"加载完成"、"复制正在进行",这意味着已完成全量加载,并且正在进行的复制已开始,可以转到由CloudFormation创建的S3 Bucket,应该会在S3 Bucket的dmsdata/dev/retail_transactions文件夹下看到一个.parquet文件。
在EMR集群的Hardware选项卡上,选择主实例组并记录主实例的EC2实例ID。
在Systems Manager控制台上,选择会话管理器。
选择"启动会话"以启动与群集主节点的会话。
通过运行以下命令将用户切换到Hadoop
sudo su hadoop
在实际用例中,AWS DMS任务在全量加载完成后开始向相同的Amazon S3位置写入增量文件,区分全量加载和增量加载文件的方法是,完全加载文件的名称以load开头,而CDC文件名具有日期时间戳,如在后面步骤所示。从处理的角度来看,我们希望将全部负载处理到Hudi数据集中,然后开始增量数据处理。为此,我们将满载文件移动到同一S3存储桶下的另一个S3文件夹中,并在开始处理增量文件之前处理这些文件。
在EMR集群的主节点上运行以下命令(将<s3-bucket-name>替换为实际的bucket name):
aws s3 mv s3://<s3-bucket-name>/dmsdata/dev/retail_transactions/ s3://<s3-bucket-name>/dmsdata/data-full/dev/retail_transactions/ --exclude "*" --include "LOAD*.parquet" --recursive
有了datafull文件夹中的全量表转储,接着使用EMR集群上的HoodieDeltaStreamer实用程序来向Amazon S3上写入Hudi数据集。
- 运行以下命令将Hudi数据集填充到同一个S3 bucket中的Hudi文件夹中(将<S3 bucket name>替换为CloudFormation创建的S3 bucket的名称):
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--packages org.apache.hudi:hudi-utilities-bundle_2.11:0.5.2-incubating,org.apache.spark:spark-avro_2.11:2.4.5 \
--master yarn --deploy-mode cluster \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.hive.convertMetastoreParquet=false \
/usr/lib/hudi/hudi-utilities-bundle_2.11-0.5.2-incubating.jar \
--table-type COPY_ON_WRITE \
--source-ordering-field dms_received_ts \
--props s3://<s3-bucket-name>/properties/dfs-source-retail-transactions-full.properties \
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource \
--target-base-path s3://<s3-bucket-name>/hudi/retail_transactions --target-table hudiblogdb.retail_transactions \
--transformer-class org.apache.hudi.utilities.transform.SqlQueryBasedTransformer \
--payload-class org.apache.hudi.payload.AWSDmsAvroPayload \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--enable-hive-sync
前面的命令运行一个运行HoodieDeltaStreamer实用程序的Spark作业。有关此命令中使用的参数的详细信息,请参阅编写Hudi表。
当Spark作业完成后,可以导航到AWS Glue控制台,找到在hudiblogdb数据库下创建的名为retail_transactions的表,表的input format是org.apache.hudi.hadoop.HoodieParquetInputFormat.

接下来查询数据并查看目录中retail_transactions表的数据。
在先前建立的Systems Manager会话中,运行以下命令(确保已完成post的所有先前条件,包括在Lake Formation中将IAMAllowedPrincipals添加为数据库创建者):
spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" --conf "spark.sql.hive.convertMetastoreParquet=false" \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.spark:spark-avro_2.11:2.4.5 \
--jars /usr/lib/hudi/hudi-spark-bundle_2.11-0.5.2-incubating.jar,/usr/lib/spark/external/lib/spark-avro.jar对retail_transactions表运行以下查询:
spark.sql("select * from hudiblogdb.retail_transactions order by tran_id").show()
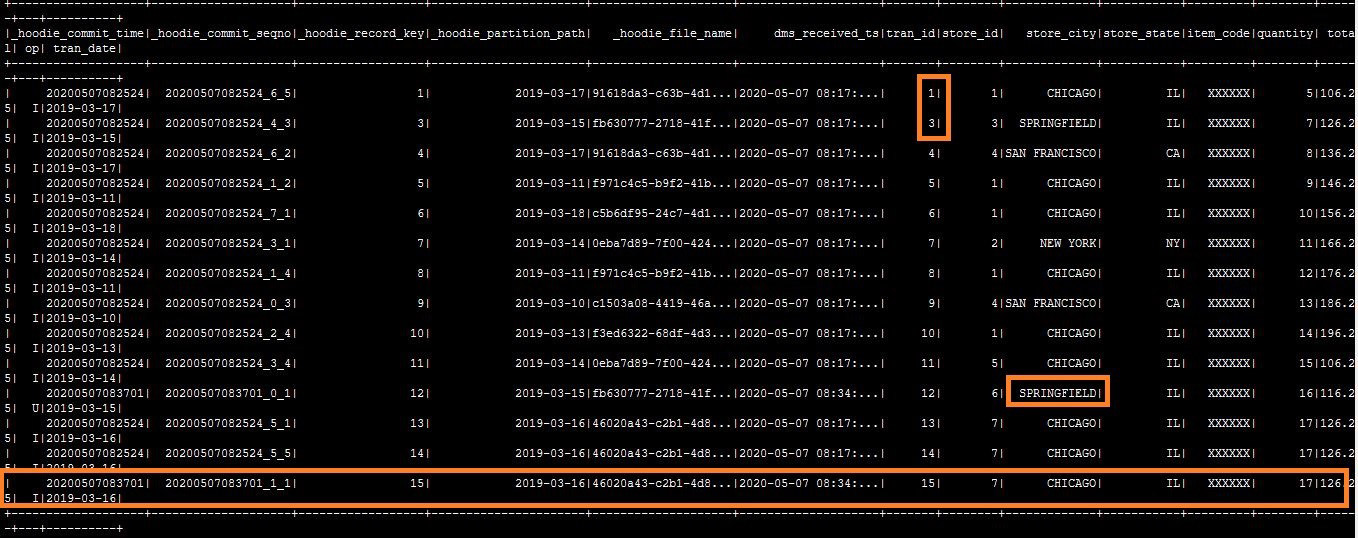
接着可以在表中看到与MySQL数据库相同的数据,其中有几个列是由HoodieDeltaStreamer自动添加Hudi元数据。

现在在MySQL数据库上运行一些DML语句,并将这些更改传递到Hudi数据集。
- 在MySQL数据库上运行以下DML语句
insert into dev.retail_transactions values(15,'2019-03-16',7,'CHICAGO','IL','XXXXXX',17,126.25);
update dev.retail_transactions set store_city='SPRINGFIELD' where tran_id=12;
delete from dev.retail_transactions where tran_id=2;
几分钟后将看到在S3存储桶中的dmsdata/dev/retail_transactions文件夹下创建了一个新的.parquet文件。

在EMR集群上运行以下命令,将增量数据获取到Hudi数据集(将<s3 bucket name>替换为CloudFormation模板创建的s3 bucket的名称):
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--packages org.apache.hudi:hudi-utilities-bundle_2.11:0.5.2-incubating,org.apache.spark:spark-avro_2.11:2.4.5 \
--master yarn --deploy-mode cluster \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.hive.convertMetastoreParquet=false \
/usr/lib/hudi/hudi-utilities-bundle_2.11-0.5.2-incubating.jar \
--table-type COPY_ON_WRITE \
--source-ordering-field dms_received_ts \
--props s3://<s3-bucket-name>/properties/dfs-source-retail-transactions-incremental.properties \
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource \
--target-base-path s3://<s3-bucket-name>/hudi/retail_transactions --target-table hudiblogdb.retail_transactions \
--transformer-class org.apache.hudi.utilities.transform.SqlQueryBasedTransformer \
--payload-class org.apache.hudi.payload.AWSDmsAvroPayload \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--enable-hive-sync \
--checkpoint 0
此命令与上一个命令之间的关键区别在于属性文件,该文件包含–-props和--checkpoint参数,对于先前执行全量加载的命令,我们使用
dfs-source-retail-transactions-full.properties进行全量加载、dfs-source-retail-transactions-incremental.properties进行增量加载,这两个属性文件之间的区别是:- 源数据的位置在AmazonS3中的全量数据和增量数据之间发生变化。
- SQL transformer查询包含了一个全量任务的
Op字段,因为AWS DMS首次全量加载不包括parquet数据集的Op字段,Op字段可有I、U和D值,表示插入、更新和删除。
本文后面的"部署到生产环境时的注意事项"部分讨论--checkpoint参数的详细信息。
- 作业完成后,在spark shell中运行相同的查询。
将会看到这些更新应用于Hudi数据集。
另外还可以使用Hudi Cli来管理Hudi数据集,以查看有关提交、文件系统、统计信息等的信息。
为此在Systems Manager会话中,运行以下命令
/usr/lib/hudi/cli/bin/hudi-cli.sh
在Hudi Cli中,运行以下命令(将<s3 bucket name>替换为CloudFormation模板创建的s3 bucket的名称):
connect --path s3://<s3-bucket-name>/hudi/retail_transactions
要检查Hudi数据集上的提交(commit),请运行以下命令
commits show

还可以从Hudi数据集查询增量数据,这对于希望将增量数据用于下游处理(如聚合)时非常有用,Hudi提供了多种增量提取数据的方法,Hudi快速入门指南中提供了如何使用此功能的示例。
6. 部署到生产环境时的注意事项
前面展示了一个如何从关系数据库到基于Amazon S3的数据湖构建CDC管道的示例,但如果要将此解决方案用于生产,则应考虑以下事项:
- 为了确保高可用性,可以在多AZ配置中设置AWS-DMS实例。
- CloudFormation将deltastreamer实用程序所需的属性文件部署到S3://<s3bucket name>/properties/处的S3 bucket中,你可以根据需求定制修改,其中有几个参数需要注意
- deltastreamer.transformer.sql – 此属性是Deltastreamer实用程序的一个非常强大的特性:它使您能够在数据被摄取并保存在Hudi数据集中时动态地转换数据,在本文中,我们展示了一个基本的转换,它将
tran_date列强制转换为字符串,但是您可以将任何转换作为此查询的一部分应用。 - parquet.small.file.limit– 此字段以字节为单位,是一个关键存储配置,指定Hudi如何处理Amazon S3上的小文件,由于每个分区的每个插入操作中要处理的记录数,可能会出现小文件,设置此值允许Hudi继续将特定分区中的插入视为对现有文件的更新,从而使文件的大小小于此值
small.file.limit被重写。 - parquet.max.file.size – 这是Hudi数据集中单个parquet文件的最大文件大小,之后将创建一个新文件来存储更多数据。对于Amazon S3的存储和数据查询需求,我们可以将其保持在256MB-1GB(256x1024x1024=268435456)。
- [Insert|Upsert|bulkinsert].shuffle.parallelism。本篇文章中我们只处理了少量记录的小数据集。然而,在实际情况下可能希望在第一次加载时引入数亿条记录,然后增量CDC数据达百万,当希望对每个Hudi数据集分区中的文件数量进行非常可预测的控制时,需要设置一个非常重要的参数,这也需要确保在处理大量数据时,不会达到Apache Spark对数据shuffle的2GB限制。例如,如果计划在第一次加载时加载200 GB的数据,并希望文件大小保持在大约256 MB,则将此数据集的shuffle parallelism参数设置为800(200×1024/256)。有关详细信息,请参阅调优指南。
- deltastreamer.transformer.sql – 此属性是Deltastreamer实用程序的一个非常强大的特性:它使您能够在数据被摄取并保存在Hudi数据集中时动态地转换数据,在本文中,我们展示了一个基本的转换,它将
- 在增量加载deltastreamer命令中,我们使用了一个附加参数:--checkpoint 0。当Deltastreamer写Hudi数据集时,它将检查点信息保存在.hoodie文件夹下的.commit文件中,它在随后的运行中使用这些信息,并且只从Amazon S3读取数据,后者是在这个检查点时间之后创建的,在生产场景中,在启动AWS-DMS任务之后,只要完成全量加载,该任务就会继续向目标S3文件夹写入增量数据。在接下来的步骤中,我们在EMR集群上运行了一个命令,将全量文件手动移动到另一个文件夹中,并从那里处理数据。当我们这样做时,与S3对象相关联的时间戳将更改为最新的时间戳,如果在没有checkpoint参数的情况下运行增量加载,deltastreamer在手动移动满载文件之前不会提取任何写入Amazon S3的增量数据,要确保Deltastreamer第一次处理所有增量数据,请将检查点设置为0,这将使它处理文件夹中的所有增量数据。但是,只对第一次增量加载使用此参数,并让Deltastreamer从该点开始使用自己的检查点方法。
- 对于本文,我们手动运行Spark submit命令,但是在生产集群中可以运行这一步骤。
- 可以使用调度或编排工具安排增量数据加载命令以固定间隔运行,也可以通过向spark submit命令传递附加参数
--min-sync-interval-seconds *XX* –continuous,以特定的频率以连续方式运行它,其中XX是数据拉取每次运行之间的秒数。例如,如果要每5分钟运行一次处理,请将XX替换为300。
7. 清理
当完成对解决方案的探索后,请完成以下步骤以清理CloudFormation部署的资源
- 清空CloudFormation堆栈创建的S3 bucket
- 删除在s3://<EMR-Logs-s3-Bucket>/HudiBlogEMRLogs/下生成的任何Amazon EMR日志文件。
- 停止AWS DMS任务Hudiblogload。
- 删除CloudFormation。
- 删除CloudFormation模板后保留的所有Amazon RDS for MySQL数据库快照。
8. 结束
越来越多的数据湖构建在Amazon S3,当对数据湖的数据进行变更时,使用传统方法处理数据删除和更新涉及到许多繁重的工作,在这篇文章中,我们看到了如何在Amazon EMR上使用AWS DMS和HoodieDeltaStreamer轻松构建解决方案。我们还研究了在将数据集成到数据湖时如何执行轻量级的记录级转换,以及如何将这些数据用于聚合等下游流程。我们还讨论了使用的重要设置和命令行选项,以及如何修改它们以满足个性化的需求。
使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖的更多相关文章
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- 使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模.可靠性.成本效率等方面.最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 官宣!ASF官方正式宣布Apache Hudi成为顶级项目
马萨诸塞州韦克菲尔德(Wakefield,MA)- 2020年6月 - Apache软件基金会(ASF).350多个开源项目和全职开发人员.管理人员和孵化器宣布:Apache Hudi正式成为Apac ...
- Apache Hudi与Apache Flink集成
感谢王祥虎@wangxianghu 投稿 Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目.是当前最 ...
- 划重点!AWS的湖仓一体使用哪种数据湖格式进行衔接?
此前Apache Hudi社区一直有小伙伴询问能否使用Amazon Redshift查询Hudi表,现在它终于来了. 现在您可以使用Amazon Redshift查询Amazon S3 数据湖中Apa ...
- 详解Amazon S3上传/下载数据
AWS简单储存服务(Amazon S3)是非常坚牢的存储服务,拥有99.999999999%的耐久性(记住11个9的耐久性). 使用CloudBerry Explorer,从Amazon S3下载数据 ...
- centos6.8 上传文件到amazon s3
centos6.8 上传文件到amazon s3 0.参考 AWS CLI Cinnabd Reference Possible to sync a single file with aws s3 s ...
- Amazon S3数据一致性模型
左右Amazon S3有两种类型的数据的一致性模型的: 最后,一致性和读一致性. 有下面几种行为: 1 写一个新的object,然后開始读它.直到全部的变化都传播完(副本),你才干读到它,否则就是ke ...
随机推荐
- 054 01 Android 零基础入门 01 Java基础语法 06 Java一维数组 01 数组概述
054 01 Android 零基础入门 01 Java基础语法 06 Java一维数组 01 数组概述 本文知识点:数组概述 为什么要学习数组? 实际问题: 比如我们要对学生的成绩进行排序,一个班级 ...
- 【题解】[USACO09NOV]A Coin Game S
Link \(\text{Solution:}\) 菜鸡自己想出来了状态设计,但是没有实现出来--菜死了 设\(dp[i][j]\)表示该选第\(i\)个,最多选\(j\)个的最优解.注意这里的定义仅 ...
- python中remove函数的坑
摘要:对于python中的remove()函数,官方文档的解释是:Remove first occurrence of value.大意也就是移除列表中等于指定值的第一个匹配的元素. 常见用法: a ...
- TP5发送邮件
1,前提去qq邮箱开启smtp 2,生成授权码 2,发送短信给 3,附上代码 贴上代码如下 <?phpnamespace app\mails\controller;use \think\Cont ...
- MonkeyRunner+Python自动化测试一
MonkeyRunner介绍 1.monkeyrunner 工具提供了一个 API,用于编写可从 Android 代码外部控制 Android 设备或模拟器的程序.使用 monkeyrunner,您可 ...
- CSGO 服务端扩展插件开发记录之"DropClientReason"(1)
最近开始接触到了CSGO这款游戏,还是老套路,就是想千方百计的从里面增添新的游戏功能,当然刚开始想做到游刃有余是有点困难, 跟之前做CS1.6的第三方开发一样,都得自己慢慢的摸索过来,纵然CSGO所使 ...
- MeteoInfoLab脚本示例:地图投影
在用axesm函数创建地图坐标系的时候可以指定地图投影(设置projinfo参数),地图投影可以通过projinfo函数来创建,里面的参数依据proj4投影字符串,可以参考此网页:http://rem ...
- day32 Pyhton 模块02复习 序列化
一. 什么是序列化 在我们存储数据或者网络传输数据的时候. 需要对我们的对象进行处理. 把对象处理成方便存储和传输的数据格式. 这个过程叫序列化 不同的序列化, 结果也不同. 但是目的是一样的. 都是 ...
- mysql中事件失效如何解决
重启Mysql服务可能会导致event_scheduler关闭,事件失效.解决方法如下: 1.解决办法: #查看是否开启 show variables like 'event_scheduler'; ...
- mac 安装appium
mocOS 10.15.5 开启方式:设置->默认编辑器->Markdown编辑器