手工实现一个ThreadPoolExecutor
以下代码的实现逻辑出自于公众号 码农翻身
《你管这破玩意叫线程池?》
- PS:刘欣老师在我心中是软件技术行业的大刘。
线程池接口


public interface Executor {
public void execute(Runnable r);
}
接口中只有一个抽象方法,execute(Runnable r);它接收一个Runnable,无返回值实现它的子类只需要将传入的Runnable执行即可。
NewsThreadExecutor
package com.datang.bingxiang.run;
import com.datang.bingxiang.run.intr.Executor;
public class NewsThreadExecutor implements Executor {
//每次调用都创建一个新的线程
@Override
public void execute(Runnable r) {
new Thread(r).start();
}
}
这个实现类最简单也最明白,真的每次调用我们都创建一个Thread将参数Runnable执行。这么做的弊端就是每个调用者发布一个任务都需要创建一个新的线程,线程使用后就被销毁了,对内存造成了很大的浪费。
SingThreadExecutor
package com.datang.bingxiang.run; import java.util.concurrent.ArrayBlockingQueue; import com.datang.bingxiang.run.intr.Executor; //只有一个线程,在实例化后就启动线程。用户调用execute()传递的Runnable会添加到队列中。
//队列有一个固定的容量3,如果队列满则抛弃任务。
//线程的run方法不停的循环,从队列里取Runnable然后执行其run()方法。
public class SingThreadExecutor implements Executor { // ArrayBlockingQueue 数组类型的有界队列
// LinkedBlockingDeque 链表类型的有界双端队列
// LinkedBlockingQueue 链表类型的有界单向队列
private ArrayBlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(1); //线程不停的从队列获取任务
private Thread worker = new Thread(() -> {
while (true) {
try {
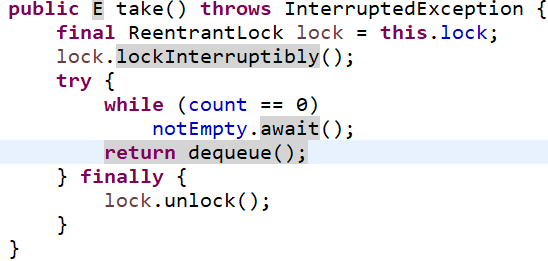
//take会在获取不到任务时阻塞。并且也有Lock锁
Runnable r = queue.take();
r.run();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} }
}); // 构造函数启动线程
public SingThreadExecutor() {
worker.start();
} @Override
public void execute(Runnable r) {
// 这个offer和add不同的是offer有Lock锁,如果队列满则返回false。
// add则是队列满抛出异常,并且没有Lock锁。
if (!queue.offer(r)) {
System.out.println("线程等待队列已满,不可加入。本次任务丢弃!");
}
} }
改变下思路,这次线程池实现类只创建一个线程,调用者发布的任务都存放到一个队列中(队列符合先进先出的需求)但是注意我们设计线程池一定要选择有界队列,因为我们不能无限制的往队列中添加任务。在队列满后,在进来的任务就要被拒绝掉。ArrayBlockingQueue
是一个底层有数组实现的有界阻塞队列,实例化一个ArrayBlockingQueue传递参数为1,表示队列长度最大为1.唯一的一个工作线程也是成员变量,线程执行后不断的自旋从队列中获取任务,take()方法将队列头的元素出队,若队列为空则阻塞,这个方法是线程安全的。
execute(r)方法接收到任务后,将任务添加到队列中,offer()方法将元素添加到队列若队列已满则返回false。execute(r)则直接拒绝掉本次任务。


CorePollThreadExecutor
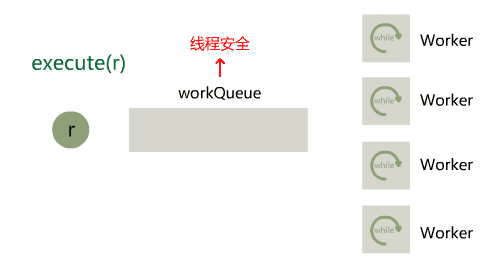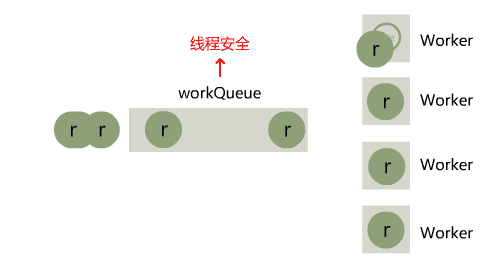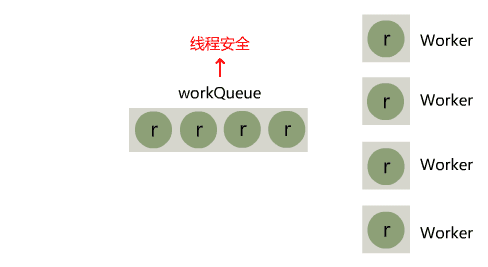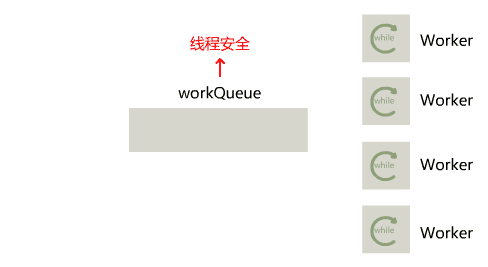
SingThreadExecutor线程池的缺点是只有一个工作线程,这样显然是不够灵活,CorePollThreadExecutor中增加了corePollSize核心线程数参数,由用户规定有需要几个工作线程。这次我们选用的队列为LinkedBlockingQueue这是一个数据结构为链表的有界阻塞单向队列。
initThread()方法根据corePollSize循环创建N个线程,线程创建后同样调用take()方法从阻塞队列中获取元素,若获取成功则执行Runnable的run()方法,若获取队列中没有元素则阻塞。execute(r)则还是负责将任务添加到队列中。
CountCorePollThreadExecutor
CorePollThreadExecutor中有三个问题
1 当队列满时线程池直接拒绝了任务,这应该让用户决定被拒绝的任务如何处理。
2 线程的创建策略也应该交给用户做处理。
3 初始化后就创建了N个核心线程数,但是这些线程可能会用不到而造成浪费。
RejectedExecutionHandler接口的实现应该让用户决定如何处理队列满的异常情况。
package com.datang.bingxiang.run.intr;
public interface RejectedExecutionHandler {
public void rejectedExecution();
}
package com.datang.bingxiang.run;
import com.datang.bingxiang.run.intr.RejectedExecutionHandler;
public class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution() {
System.out.println("队列已经满了!!!!当前task被拒绝");
}
}
ThreadFactory接口的实现应该让用户决定创建线程的方法。
package com.datang.bingxiang.run.intr;
public interface ThreadFactory {
public Thread newThread(Runnable r);
}
package com.datang.bingxiang.run;
import com.datang.bingxiang.run.intr.ThreadFactory;
public class CustomThreadFactory implements ThreadFactory {
@Override
public Thread newThread(Runnable r) {
System.out.println("创建了新的核心线程");
return new Thread(r);
}
}
CountCorePollThreadExecutor的构造函数接收三个参数corePollSize,rejectedExecutionHandler,threadFactory。因为现在我们需要按需创建核心线程,所以需要一个变量workCount记录当前已经创建的工作线程,为了保证线程之间拿到的workCount是最新的(可见性),我们需要给变量workCount加上volatile修饰,保证改变了的修改能被所有线程看到。execute(r)首先要调用initThread(r)判断是否有线程被创建,如果没有线程创建则表示工作线程数已经和核心线程数相同了,此时需要将新的任务添加到队列中,如果队列满,则执行传入的拒绝策略。重要的方法在于initThread(r)。initThread(r)方法返回true表示有工作线程被创建任务将被工作线程直接执行,无需入队列。返回false则将任务入队,队列满则执行拒绝策略。
fill变量表示核心线程数是否全部创建,为了保证多线程的环境下不会创建多于corePoolSize个数的线程,所以需要使用同步锁,initThread(r)都要使用锁则会降低效率,尤其是当工作线程数已经到达核心线程数后,所以这一块代码使用到了双重判断,当加锁后在此判断工作线程是否已满。如果已满返回false。接下来使用threadFactory工厂创建线程,在线程中使用代码块,保证当前任务可以被新创建的工作线程执行。新的工作线程依然是从队列中获取任务并执行。线程开启后工作线程++,如果工作线程数等于核心线程数则改变fill标记。返回true,成功创建线程,不要忘记在finally中释放锁。
package com.datang.bingxiang.run; import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock; import com.datang.bingxiang.run.intr.Executor;
import com.datang.bingxiang.run.intr.RejectedExecutionHandler;
import com.datang.bingxiang.run.intr.ThreadFactory; public class CountCorePollThreadExecutor implements Executor { // 核心线程数
private Integer corePollSize; // 工作线程数,也就是线程实例的数量
private volatile Integer workCount = 0; // 线程是否已满
private volatile boolean fill = false; // 拒绝策略,由调用者传入,当队列满时,执行自定义策略
private RejectedExecutionHandler rejectedExecutionHandler; // 线程工厂,由调用者传入
private ThreadFactory threadFactory; public CountCorePollThreadExecutor(Integer corePollSize, RejectedExecutionHandler rejectedExecutionHandler,
ThreadFactory threadFactory) {
this.corePollSize = corePollSize;
this.rejectedExecutionHandler = rejectedExecutionHandler;
this.threadFactory = threadFactory;
} // 这次使用链表类型的单向队列
LinkedBlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(1); @Override
public void execute(Runnable r) {
// 如果没有创建线程
if (!initThread(r)) {
// offer和ArrayBlockingQueue的offer相同的作用
if (!queue.offer(r)) {
rejectedExecutionHandler.rejectedExecution();
}
} } // 同步锁,因为判断核心线程数和工作线程数的操作需要线程安全
Lock lock = new ReentrantLock(); public boolean initThread(Runnable r) {
// 如果工作线程没有创建满则需要创建。
if (!fill) {
try {
lock.lock();// 把锁 加在判断里边是为了不让每次initThread方法执行时都加锁
// 此处进行双重判断,因为可能因为多线程原因多个线程都判断工作线程没有创建满,但是不要紧
// 只有一个线程可以进来,如果后续线程二次判断已经满了就直接返回。
if (fill) {
return false;
}
Thread newThread = threadFactory.newThread(() -> {
// 因为线程是由任务触发创建的,所以先把触发线程创建的任务执行掉。
{
r.run();
} while (true) {
// 然后该线程则不停的从队列中获取任务
try {
Runnable task = queue.take();
task.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
newThread.start();
// 工作线程数+1
workCount++;
// 如果工作线程数已经与核心线程数相等,则不可创建
if (workCount == corePollSize) {
fill = true;
}
return true;
} finally {
lock.unlock();// 释放锁
}
} else {
// 工作线程已满则不创建
return false;
} } }

ThreadPoolExecutor
最后考虑下,当工作线程数到达核心线程数后,队列也满了以后,任务就被拒绝了。能不能想个办法,当工作线程满后,多增加几个线程工作,当任务不多时在将扩展的线程销毁。ThreadPoolExecutor的构造函数中新增三个参数maximumPoolSize最大线程数keepAliveTime空闲时间,unit空闲时间的单位。
和CountCorePollThreadExecutor相比较在流程上讲我们只需要在队列满时判断工作线程是否和最大线程数相等,如果不相等则创建备用线程,并且在备用线程长时间不工作时需要销毁掉工作线程。create()方法双重判断workCount==maximumPoolSize如果已经相等表示已经不能创建线程了,此时只能执行拒绝策略。否则创建备用线程,备用线程创建后自旋的执行poll(l,u)方法,该方法也是取出队列头元素,和take()不同的是,poll如果一段时间后仍然从队列中拿不到元素(队列为空)则返回null,此时我们需要将该备用线程销毁。在创建线程后将workCount++。此外需要注意,因为当前队列满了,所以才会创建备用线程所以不要将当前的任务给忘了,LinkedBlockingQueue的put(r)方法会阻塞的添加元素,直到添加成功。最后 stop()判读如果workCount>corePollSize则在线程安全的环境下将线程停止,并且将workCount--。
package com.datang.bingxiang.run; import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock; import com.datang.bingxiang.run.intr.Executor;
import com.datang.bingxiang.run.intr.RejectedExecutionHandler;
import com.datang.bingxiang.run.intr.ThreadFactory; public class ThreadPoolExecutor implements Executor { // 核心线程数
private Integer corePollSize; // 工作线程数,也就是线程实例的数量
private Integer workCount = 0; // 当队列满时,需要创建新的Thread,maximumPoolSize为最大线程数
private Integer maximumPoolSize; // 当任务不多时,需要删除多余的线程,keepAliveTime为空闲时间
private long keepAliveTime; // unit为空闲时间的单位
private TimeUnit unit; // 线程是否已满
private boolean fill = false; // 拒绝策略,由调用者传入,当队列满时,执行自定义策略
private RejectedExecutionHandler rejectedExecutionHandler; // 线程工厂,由调用者传入
private ThreadFactory threadFactory; // 这次使用链表类型的单向队列
BlockingQueue<Runnable> workQueue; public ThreadPoolExecutor(Integer corePollSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory,
RejectedExecutionHandler rejectedExecutionHandler) {
this.corePollSize = corePollSize;
this.rejectedExecutionHandler = rejectedExecutionHandler;
this.threadFactory = threadFactory;
this.workQueue = workQueue;
this.maximumPoolSize = maximumPoolSize;
this.keepAliveTime = keepAliveTime;
this.unit = unit;
} @Override
public void execute(Runnable r) {
// 如果没有创建线程
if (!initThread(r)) {
// offer和ArrayBlockingQueue的offer相同的作用
if (!workQueue.offer(r)) {
// 队列满了以后先不走拒绝策略而是查询线程数是否到达最大线程数
if (create()) {
Thread newThread = threadFactory.newThread(() -> {
while (true) {
// 然后该线程则不停的从队列中获取任务
try {
Runnable task = workQueue.poll(keepAliveTime, unit);
if (task == null) {
stop();
} else {
task.run();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
newThread.start();
// 工作线程数+1
workCount++;
// 增加线程后,还需要将本应该被拒绝的任务添加到队列
try {
// 这个put()方法会在队列满时阻塞添加,直到添加成功
workQueue.put(r);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
rejectedExecutionHandler.rejectedExecution();
}
}
} } Lock clock = new ReentrantLock(); private boolean create() {
//双重检查
if (workCount == maximumPoolSize) {
return false;
}
try {
clock.lock();
if (workCount < maximumPoolSize) {
return true;
} else {
return false;
}
} finally {
clock.unlock();
} } Lock slock = new ReentrantLock(); // 销毁线程
private void stop() {
slock.lock();
try {
if (workCount > corePollSize) {
System.out.println(Thread.currentThread().getName() + "线程被销毁");
workCount--;
Thread.currentThread().stop();
}
} finally {
slock.unlock();
} } // 获取当前的工作线程数
public Integer getworkCount() {
return workCount;
} // 同步锁,因为判断核心线程数和工作线程数的操作需要线程安全
Lock lock = new ReentrantLock(); public boolean initThread(Runnable r) {
// 如果工作线程没有创建满则需要创建。
if (!fill) {
try {
lock.lock();// 把锁 加在判断里边是为了不让每次initThread方法执行时都加锁
// 此处进行双重判断,因为可能因为多线程原因多个线程都判断工作线程没有创建满,但是不要紧
// 只有一个线程可以进来,如果后续线程二次判断已经满了就直接返回。
if (fill) {
return false;
}
Thread newThread = threadFactory.newThread(() -> {
// 因为线程是由任务触发创建的,所以先把触发线程创建的任务执行掉。
{
r.run();
} while (true) {
// 然后该线程则不停的从队列中获取任务
try {
Runnable task = workQueue.take();
task.run();
} catch (InterruptedException e) {
e.printStackTrace();
} }
});
newThread.start();
// 工作线程数+1
workCount++;
// 如果工作线程数已经与核心线程数相等,则不可创建
if (workCount == corePollSize) {
fill = true;
}
return true;
} finally {
lock.unlock();// 释放锁
}
} else {
// 工作线程已满则不创建
return false;
}
} }


测试代码
package com.datang.bingxiang.run.test; import java.time.LocalDateTime;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit; import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController; import com.datang.bingxiang.run.CorePollThreadExecutor;
import com.datang.bingxiang.run.CountCorePollThreadExecutor;
import com.datang.bingxiang.run.CustomRejectedExecutionHandler;
import com.datang.bingxiang.run.CustomThreadFactory;
import com.datang.bingxiang.run.NewsThreadExecutor;
import com.datang.bingxiang.run.SingThreadExecutor;
import com.datang.bingxiang.run.ThreadPoolExecutor;
import com.datang.bingxiang.run.intr.Executor; @RestController
public class TestController { private int exe1Count = 1;
Executor newsThreadExecutor = new NewsThreadExecutor(); // 每次都创建新的线程执行
@GetMapping(value = "exe1")
public String exe1() {
newsThreadExecutor.execute(() -> {
System.out.println("正在执行" + exe1Count++);
});
return "success";
} /*
* 等待队列长度为1,三个线程加入,第一个加入后会迅速的出队列。剩下两个只有一个可以成功 加入,另一个 则会被丢弃
*/
private int exe2Count = 1;
Executor singThreadExecutor = new SingThreadExecutor(); @GetMapping(value = "exe2")
public String exe2() {
singThreadExecutor.execute(() -> {
System.out.println("正在执行" + exe2Count++);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
return "success";
} private int exe3Count = 1;
Executor corePollThreadExecutor = new CorePollThreadExecutor(2); @GetMapping(value = "exe3")
public String exe3() {
corePollThreadExecutor.execute(() -> {
System.out.println("正在执行" + exe3Count++);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
return "success";
} private int exe4Count = 1;
Executor countCorePollThreadExecutor = new CountCorePollThreadExecutor(2, new CustomRejectedExecutionHandler(),
new CustomThreadFactory()); @GetMapping(value = "exe4")
public String exe4() {
countCorePollThreadExecutor.execute(() -> {
System.out.println("正在执行" + exe4Count++);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
return "success";
} // 第一次创建线程并执行 1
// 第二次进入队列 2
// 第三次创建线程取出队列中的2,将3添加到队列
// 第四次拒绝
// 等待3秒后只剩下一个队列
private int exe5Count = 1;
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 2, 3, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1), new CustomThreadFactory(), new CustomRejectedExecutionHandler()); @GetMapping(value = "exe5")
public String exe5() {
threadPoolExecutor.execute(() -> {
System.out.println("正在执行" + exe5Count++);
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
return "success";
} @GetMapping(value = "workCount")
public Integer getWorkCount() {
return threadPoolExecutor.getworkCount();
}
}
手工实现一个ThreadPoolExecutor的更多相关文章
- 在VS中手工创建一个最简单的WPF程序
如果不用VS的WPF项目模板,如何手工创建一个WPF程序呢?我们来模仿WPF模板,创建一个最简单的WPF程序. 第一步:文件——新建——项目——空项目,创建一个空项目. 第二步:添加引用,Presen ...
- 纯手工撸一个vue框架
前言 vue create 真的很方便,但是很多人欠缺的是手动撸一遍.有些人离开脚手架都不会开发了. Vue最简单的结构 步骤 搭建最基本的结构 打开空文件夹,通过 npm init 命令生成pack ...
- oozie调度中的重试和手工rerun一个workflow
在oozie中有Bundle.Coordinator和Workflow三种类型的job,他们之间可以有以下包含关系. Bundle > Coordinator > Workflow. 1. ...
- ThreadPoolExecutor源码学习(1)-- 主要思路
ThreadPoolExecutor是JDK自带的并发包对于线程池的实现,从JDK1.5开始,直至我所阅读的1.6与1.7的并发包代码,从代码注释上看,均出自Doug Lea之手,从代码上看JDK1. ...
- java 线程池ThreadPoolExecutor 如何与 AsyncTask() 组合使用。
转载请声明出处谢谢!http://www.cnblogs.com/linguanh/ 这里主要使用Executors中的4种静态创建线程池实例方法中的 newFixedThreadPool()来举例讲 ...
- C++标准库:std_map作为一个关联数组
摘要:std::map作为一个容器存在一个典型应用就是作为关联数组来作用.在诸如Java等等语言中,关联数组广泛存在.std::map是一个容器,在它的概念框架中存在两个词:键和值,std::map把 ...
- 如何手动添加Windows服务和如何把一个服务删除
windows 手动添加服务方法一:修改注册表 在注册表编辑器,展开分支"HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services" ...
- java多线程 ThreadPoolExecutor 策略的坑
无论是使用jdk的线程池ThreadPoolExecutor 还是spring的线程池ThreadPoolTaskExecutor 都会使用到一个阻塞队列来进行存储线程任务. 当线程不够用时,则将后续 ...
- 用scala实现一个sql执行引擎-(下)
执行 上一篇讲述了如何通过scala提供的内置DSL支持,实现一个可以解析sql的解析器,这篇讲如何拿到了解析结果-AST以后,如何在数据上进行操作,得到我们想要的结果.之前说到,为什么选择scala ...
随机推荐
- Codeforces Round #274 (Div. 2) C. Exams (贪心)
题意:给\(n\)场考试的时间,每场考试可以提前考,但是记录的是原来的考试时间,问你如何安排考试,使得考试的记录时间递增,并且最后一场考试的时间最早. 题解:因为要满足记录的考试时间递增,所以我们用结 ...
- Windows下pip使用清华源
一.下列内容更换成批处理,直接运行即可 @echo off md "C:\Users\Administrator\AppData\pip" echo [global] >C: ...
- codeforces 1037E-Trips 【构造】
题目:戳这里 题意:n个点,每天早上会在这n个点中加一条边,每天晚上最大的子图满足子图中每个点都有k条或以上的边. 解题思路:看了官方题解,先把所有的点都连上,再从最后一天往前减边,用set维护最大的 ...
- HDU - 4455 Substrings(非原创)
XXX has an array of length n. XXX wants to know that, for a given w, what is the sum of the distinct ...
- Leetcode(35)-搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引.如果目标值不存在于数组中,返回它将会被按顺序插入的位置. 你可以假设数组中无重复元素. 这个题目很简单,因为它是给定的排序数组而且没有重 ...
- HDU 4280 Island Transport(HLPP板子)题解
题意: 求最大流 思路: \(1e5\)条边,偷了一个超长的\(HLPP\)板子.复杂度\(n^2 \sqrt{m}\).但通常在随机情况下并没有isap快. 板子: template<clas ...
- Redis 集合统计(HyperLogLog)
统计功能是一类极为常见的需求,比如下面这个场景: 为了决定某个功能是否在下个迭代版本中保留,产品会要求统计页面在上新前后的 UV 作为决策依据. 简单来说就是统计一天内,某个页面的访问用户量,如果相同 ...
- μC/OS-III---I笔记8---事件标志
当任务需要同步时可以使用信号量.A任务给B任务发送消息后B任务才能继续运行.如果需要A任务给任务B传递数据的时候就可以采用消息队列.但对于繁杂任务的同步,比如多个时间发生以后执行一个事件,或者是C任务 ...
- GitHub new features 2020 All In One
GitHub new features 2020 All In One Discussions Discussions is the space for your community to have ...
- ES6 Map All In One
ES6 Map All In One Map 字典/地图 Set 集合 https://developer.mozilla.org/en-US/docs/Web/JavaScript/Referenc ...