SpringBoot学习之整合Druid的简单应用
一、Druid介绍
Druid简介
Druid是目前Java语言中最好的数据库连接池之一。结合了 C3P0、DBCP 等 DB 池的优点,同时加入了日志监控。Druid 是一个分布式的、支持实时多维 OLAP 分析的数据处理系统。它既支持高速的数据实时摄入处理,也支持实时且灵活的多维数据分析查询。
Druid已经在阿里巴巴部署了超过600个应用,经过生产环境大规模部署的严苛考验。Spring Boot 2.0 以上默认使用 Hikari 数据源,可以说 Hikari 与 Driud 都是当前 Java Web 上最优秀的数据源。
Druid特性
支持
- 亚秒响应的交互式查询,支持较高并发。
- 支持实时导入,导入即可被查询,支持高并发导入。
- 采用分布式 shared-nothing 的架构,可以扩展到PB级。
- 支持聚合函数,count 和 sum,以及使用 javascript 实现自定义 UDF。
- 支持复杂的 Aggregator,近似查询的 Aggregator 例如 HyperLoglog 以及 Yahoo 开源的 DataSketches。
- 支持Groupby,Select,Search查询。
- 不支持大表之间的Join,但其 lookup 功能满足和维度表的 Join。
不支持
- 不支持精确去重
- 不支持 Join(只能进行 semi-join)
- 不支持根据主键的单条记录更新
Druid下载
- maven中央仓库: http://central.maven.org/maven2/com/alibaba/druid/
- 源代码仓库地址: https://github.com/alibaba/druid
Druid可以做什么
可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
二、Druid在SpringBoot中的整合
配置Druid数据源
这里基于SpringBoot 2.3.2、IntelliJ IDEA开发工具、Maven 3.6.3、Mysql 8.0.20
1.在 Spring Boot 项目中的Pom.xml文件中加入druid-spring-boot-starter依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.17</version>
</dependency>
<!-- log4j日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2.添加application的配置项,这里使用yaml文件格式
spring:
datasource:
url: jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 970628
# 切换Druid数据源
type: com.alibaba.druid.pool.DruidDataSource
#Spring Boot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
注意:
- url中在mysql的8版本以上的可能需要设置时区:
serverTimezone=UTC- driver-class-name数据库驱动,如果是mysql8版本以上的使用
com.mysql.cj.jdbc.Driver,低版本的使用com.mysql.jdbc.Driver- type属性是切换数据源为Druid,SpringBoot 2.0以上默认的数据源为
com.zaxxer.hikari.HikariDataSource
这只是部分属性配置,下面是常用的其他配置项,可以根据情况选择。
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候 可以通过名字来区分开来。如果没有配置,将会生成一个名字, 格式是:”DataSource-” + System.identityHashCode(this) |
|
| jdbcUrl | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto |
|
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中, 可以使用ConfigFilter。详细看这里: https://github.com/alibaba/druid/wiki/使用ConfigFilter |
|
| driverClassName | driverClassName | 这一项可配可不配,如果不配置druid会根据url自动识别dbType, 然后选择相应的driverClassName |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法, 或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后, 缺省启用公平锁,并发效率会有所下降, 如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 |
|
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。 PSCache对支持游标的数据库性能提升巨大,比如说oracle。 在mysql5.5以下的版本中没有PSCache功能,建议关闭掉。 5.5及以上版本有PSCache,建议开启。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时, poolPreparedStatements自动触发修改为true。 在Druid中,不会存在Oracle下PSCache占用内存过多的问题, 可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。 如果validationQuery为null,testOnBorrow、testOnReturn、 testWhileIdle都不会其作用。 |
|
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效, 做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效, 做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。 申请连接的时候检测,如果空闲时间大于 timeBetweenEvictionRunsMillis, 执行validationQuery检测连接是否有效 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1) Destroy线程会检测连接的间隔时间 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
|
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件 | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>, 如果同时配置了filters和proxyFilters, 是组合关系,并非替换关系 |
|
3.添加 DruidDataSource 组件到容器中,并绑定属性
在SpringBoot中需要自定义一个配置类进行属性赋值
package com.kuang.config;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
@Configuration
public class DruidConfig {
/*
将自定义的 Druid数据源添加到容器中,不再让 Spring Boot 自动创建
绑定全局配置文件中的 druid 数据源属性到 com.alibaba.druid.pool.DruidDataSource从而让它们生效
@ConfigurationProperties(prefix = "spring.datasource"):作用就是将 全局配置文件中
前缀为 spring.datasource的属性值注入到 com.alibaba.druid.pool.DruidDataSource 的同名参数中
*/
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druidDataSource() {
return new DruidDataSource();
}
}
4.编写测试类验证是否生效
测试之前保证数据库的用户名及密码正确及数据库连接字符串拼写正确
package com.tioxy;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
@SpringBootTest
class SpringBootDataApplicationTests {
@Autowired
DataSource dataSource;
@Test
void contextLoads() throws SQLException {
// 查看一下默认的数据源
System.out.println(dataSource.getClass());
// 获得数据库链接
Connection connection = dataSource.getConnection();
System.out.println(connection);
connection.close();
}
}
测试结果
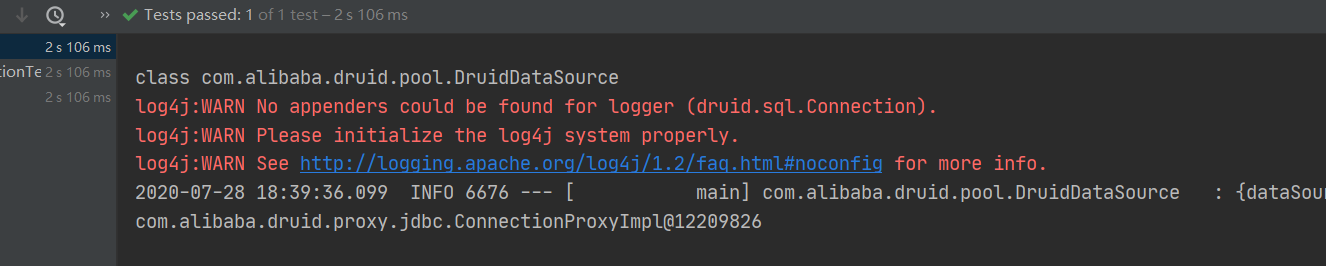
配置Druid数据源监控
Druid 的监控主要有两点,业务查询情况和平台运行情况。前者主要包括 datasource 的查询量、查询耗时、网络流量等;后者主要包括各个服务的 gc 情况、cpu 和内存使用情况、空闲 Jetty 线程数等。
配置步骤如下:
1.添加application的配置项
在原来的配置基础上添加数据源监控配置项
spring:
datasource:
url: jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 970628
# 切换Druid数据源
type: com.alibaba.druid.pool.DruidDataSource
#Spring Boot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority
#则导入 log4j 依赖即可,Maven 地址:https://mvnrepository.com/artifact/log4j/log4j
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
2.配置Druid数据监控登录的账号密码
因为Druid内置了数据监控的可视化界面,我们可以设置其登录的账号及密码,这样就可以直观的进行各项业务查询和平台运行监控情况。
我们原来在SSM中配置页面需要用到servlet,springBoot 内置了servlet容器,所以没有web.xml,使用这种的配置类,用bean的方式注册到容器中,所以在配置类添加自定义servlet方法。
//配置 Druid 监控管理后台的Servlet;
//内置 Servlet 容器时没有web.xml文件,所以使用 Spring Boot 的注册 Servlet 方式
@Bean
public ServletRegistrationBean statViewServlet() {
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
// 这些参数可以在 com.alibaba.druid.support.http.StatViewServlet
// 的父类 com.alibaba.druid.support.http.ResourceServlet 中找到
Map<String, String> initParams = new HashMap<>();
initParams.put("loginUsername", "admin"); //后台管理界面的登录账号
initParams.put("loginPassword", "123456"); //后台管理界面的登录密码
//后台允许谁可以访问
//initParams.put("allow", "localhost"):表示只有本机可以访问
//initParams.put("allow", ""):为空或者为null时,表示允许所有访问
initParams.put("allow", "");
//deny:Druid 后台拒绝谁访问
//initParams.put("kuangshen", "192.168.1.20");表示禁止此ip访问
//设置初始化参数
bean.setInitParameters(initParams);
return bean;
}
启动测试运行,检查配置是否成功
运行后输入地址:http://localhost:8080/druid/login.html
进入到Druid的后台登录页面
输入配置好的账号密码,点击登录,即可进入控制台页面

3.(可选)配置Druid过滤器
在实际的开发中,此项根据实际的业务和要求进行配置
同样的在Druid配置类中添加一下方法:
//配置 Druid 监控 之 web 监控的 filter
//WebStatFilter:用于配置Web和Druid数据源之间的管理关联监控统计
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
//exclusions:设置哪些请求进行过滤排除掉,从而不进行统计
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions", "*.js,*.css,/druid/*,/jdbc/*");
bean.setInitParameters(initParams);
//"/*" 表示过滤所有请求
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
以上便是SpringBoot整合Druid的简单使用,这只是入门配置,如后续根据实际的业务进行业务增加及调整。
文章引用:
狂神说JAVA之SpringBoot整合Druid课程学习笔记
SpringBoot学习之整合Druid的简单应用的更多相关文章
- SpringBoot学习之整合Mybatis
本博客使用IDEA开发工具,通过Maven构建SpringBoot项目,初始化项目添加的依赖有:spring-boot-starter-jdbc.spring-boot-starter-web.mys ...
- springboot 学习之路 1(简单入门)
目录:[持续更新.....] spring 部分常用注解 spring boot 学习之路1(简单入门) spring boot 学习之路2(注解介绍) spring boot 学习之路3( 集成my ...
- SpringBoot学习:整合MyBatis,使用Druid连接池
项目下载地址:http://download.csdn.NET/detail/aqsunkai/9805821 (一)添加pom依赖: <!-- https://mvnrepository.co ...
- SpringBoot学习之整合Swagger
Swagger介绍 1.什么是Swagger 作为后端程序开发,我们多多少少写过几个后台接口项目,不管是编写手机端接口,还是目前比较火热的前后端分离项目,前端与后端都是由不同的工程师进行开发,那么这之 ...
- SpringBoot学习:整合Mybatis,使用HikariCP超高性能数据源
一.添加pom依赖jar包: <!--整合mybatis--> <dependency> <groupId>org.mybatis.spring.boot</ ...
- springboot学习2 整合mybatis
springboot整合mybatis 一.添加mybatis和数据库连接的依赖 <!--整合mybatis--> <dependency> <groupId>or ...
- 尚硅谷springboot学习32-整合druid
使用druid数据源 配置druid数据源 这里配置的数据源参数并不会生效,因为在DataSourceProperties中并没有这些字段,如果想要生效,必须自己配置druid数据源 @Configu ...
- SpringBoot学习:整合shiro(身份认证和权限认证),使用EhCache缓存
项目下载地址:http://download.csdn.NET/detail/aqsunkai/9805821 (一)在pom.xml中添加依赖: <properties> <shi ...
- SpringBoot学习:整合shiro(rememberMe记住我后自动登录session失效解决办法)
项目下载地址:http://download.csdn.NET/detail/aqsunkai/9805821 定义一个拦截器,判断用户是通过记住我登录时,查询数据库后台自动登录,同时把用户放入ses ...
随机推荐
- 第二部分用户交互程序开发,通过paramiko记录ssh会话记录
需求及任务:实现一个给用户登录的界面(通过ssh登到堡垒机上,然后给它展现一个命令行的页面,然后他选择登哪台机器,一选择就连上去且把日志也记录下来). 先在admin创建几条组数据并与用户关联如下图: ...
- Logstash7.6.2同步Mysql数据到ElasticSearch
1.准备工作:存在的mysql的数据库表.创建好的elasticsearch索引 2.下载mysql-connector 下载地址:https://dev.mysql.com/downloads/co ...
- Html5中input新增的表单元素和属性介绍。
input标签主要用于Web表单的创建交互,以便接受来自用户的数据. 我们通过更改type属性的值,来实现不同的输入类型.在以前的写法中表单元素必须放在form元素所包含的里面,而在html5中,我们 ...
- Github和Azure DevOps的代码同步
[前言]Github和Azure DevOps都提供了Git代码库功能,那么有没有办法将两边的代码库进行同步呢,答案是肯定的.这里的操作我都是用Azure DevOps的Pipelines功能来完成的 ...
- 初识C#扩展方法
1)扩展方法是什么? 扩展方法可以在不修改原有类的代码前提下,给类“增加”一个方法.扩展方法虽然属于静态方法,但调用的语法却和对象调用类似.直接用一个例子来演示扩展方法. 1.准备实体类 public ...
- 宁波市第三届网络安全大赛-WriteUp(Misc)
友情链接 Web师傅:skyxmao师傅 内心OS 第一次参加这种大型比赛,实力较菜,请师傅们多多指点 Misc | 完成 | 第一 下载文件,看一下doc没有任何问题, 没有发现任何隐写,然后修改文 ...
- Django---进阶2
目录 数据的查,改,删 django orm中如何创建表关系 django请求生命周期流程图(必会) 路由层 路由匹配 无名分组 有名分组 无名有名是否可以混合使用 反向解析 作业 数据的查,改,删 ...
- 002.Nginx安装及启动
一 Nginx yum安装 1.1 前置准备 1 [root@nginx01 ~]# systemctl status firewalld.service #检查防火墙 2 [root@nginx01 ...
- CSS基础面试题,快来查漏补缺
本文大部分问题来源:50道CSS基础面试题(附答案),外加一些面经. 我对问题进行了分类整理,并给了自己的回答.大部分知识点都有专题链接(来源于本博客相关文章),用于自己前端CSS部分的查漏补缺.虽作 ...
- 【网鼎杯2018】fakebook
解题过程: 首先进行目录扫描,发现以下目录: user.php.bak login.php flag.php user.php robots.txt user.php.bak猜测存在源码泄露. 查看源 ...