seaborn分布数据可视化:直方图|密度图|散点图
系统自带的数据表格(存放在github上https://github.com/mwaskom/seaborn-data),使用时通过sns.load_dataset('表名称')即可,结果为一个DataFrame。
print(sns.get_dataset_names()) #获取所有数据表名称
# ['anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'exercise', 'flights',
# 'fmri', 'gammas', 'iris', 'mpg', 'planets', 'tips', 'titanic']
tips = sns.load_dataset('tips') #导入小费tips数据表,返回一个DataFrame
tips.head()

一、直方图distplot()
distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None,hist_kws=None, kde_kws=None, rug_kws=None,
fit_kws=None,color=None, vertical=False, norm_hist=False, axlabel=None,label=None, ax=None)
- a 数据源
- bins 箱数
- hist、kde、rug 是否显示箱数、密度曲线、数据分布,默认显示箱数和密度曲线不显示数据分析
- {hist,kde,rug}_kws 通过字典形式设置箱数、密度曲线、数据分布的各个特征
- norm_hist 直方图的高度是否显示密度,默认显示计数,如果kde设置为True高度也会显示为密度
- color 颜色
- vertical 是否在y轴上显示图标,默认为False即在x轴显示,即竖直显示
- axlabel 坐标轴标签
- label 直方图标签
fig = plt.figure(figsize=(12,5))
ax1 = plt.subplot(121)
rs = np.random.RandomState(10) # 设定随机数种子
s = pd.Series(rs.randn(100) * 100)
sns.distplot(s,bins = 10,hist = True,kde = True,rug = True,norm_hist=False,color = 'y',label = 'distplot',axlabel = 'x')
plt.legend() ax1 = plt.subplot(122)
sns.distplot(s,rug = True,
hist_kws={"histtype": "step", "linewidth": 1,"alpha": 1, "color": "g"}, # 设置箱子的风格、线宽、透明度、颜色,风格包括:'bar', 'barstacked', 'step', 'stepfilled'
kde_kws={"color": "r", "linewidth": 1, "label": "KDE",'linestyle':'--'}, # 设置密度曲线颜色,线宽,标注、线形
rug_kws = {'color':'r'} ) # 设置数据频率分布颜色

二、密度图
密度曲线kdeplot(data, data2=None, shade=False, vertical=False, kernel="gau",bw="scott", gridsize=100, cut=3, clip=None,
legend=True,cumulative=False,shade_lowest=True,cbar=False, cbar_ax=None,cbar_kws=None, ax=None, **kwargs)
- shade 是否填充与坐标轴之间的
- bw 取值'scott' 、'silverman'或一个数值标量,控制拟合的程度,类似直方图的箱数,设置的数量越大越平滑,越小越容易过度拟合
- shade_lowest 主要是对两个变量分析时起作用,是否显示最外侧填充颜色,默认显示
- cbar 是否显示颜色图例
- n_levels 主要对两个变量分析起作用,数据线的个数
数据分布rugplot(a, height=.05, axis="x", ax=None, **kwargs)
- height 分布线高度
- axis {'x','y'},在x轴还是y轴显示数据分布
1.单个样本数据分布密度图
sns.kdeplot(s,shade = False, color = 'r',vertical = False)# 是否填充、设置颜色、是否水平
sns.kdeplot(s,bw=0.2, label="bw: 0.2",linestyle = '-',linewidth = 1.2,alpha = 0.5)
sns.kdeplot(s,bw=2, label="bw: 2",linestyle = '-',linewidth = 1.2,alpha = 0.5,shade=True)
sns.rugplot(s,height = 0.1,color = 'k',alpha = 0.5) #数据分布

2.两个样本数据分布密度图
两个维度数据生成曲线密度图,以颜色作为密度衰减显示。
rs = np.random.RandomState(2) # 设定随机数种子
df = pd.DataFrame(rs.randn(100,2),columns = ['A','B'])
sns.kdeplot(df['A'],df['B'],shade = True,cbar = True,cmap = 'Reds',shade_lowest=True, n_levels = 8)# 曲线个数(如果非常多,则会越平滑)
plt.grid(linestyle = '--')
plt.scatter(df['A'], df['B'], s=5, alpha = 0.5, color = 'k') #散点
sns.rugplot(df['A'], color="g", axis='x',alpha = 0.5) #x轴数据分布
sns.rugplot(df['B'], color="r", axis='y',alpha = 0.5) #y轴数据分布

rs1 = np.random.RandomState(2)
rs2 = np.random.RandomState(5)
df1 = pd.DataFrame(rs1.randn(100,2)+2,columns = ['A','B'])
df2 = pd.DataFrame(rs2.randn(100,2)-2,columns = ['A','B'])
sns.set_style('darkgrid')
sns.set_context('talk')
sns.kdeplot(df1['A'],df1['B'],cmap = 'Greens',shade = True,shade_lowest=False)
sns.kdeplot(df2['A'],df2['B'],cmap = 'Blues', shade = True,shade_lowest=False)

三、散点图
jointplot() / JointGrid() / pairplot() /pairgrid()
1.jointplot()综合散点图
rs = np.random.RandomState(2)
df = pd.DataFrame(rs.randn(200,2),columns = ['A','B']) sns.jointplot(x=df['A'], y=df['B'], # 设置x轴和y轴,显示columns名称
data=df, # 设置数据
color = 'k', # 设置颜色
s = 50, edgecolor="w",linewidth=1, # 设置散点大小、边缘线颜色及宽度(只针对scatter)
kind = 'scatter', # 设置类型:“scatter”、“reg”、“resid”、“kde”、“hex”
space = 0.1, # 设置散点图和上方、右侧直方图图的间距
size = 6, # 图表大小(自动调整为正方形)
ratio = 3, # 散点图与直方图高度比,整型
marginal_kws=dict(bins=15, rug=True,color='green') # 设置直方图箱数以及是否显示rug
)

当kind分别设置为其他4种“reg”、“resid”、“kde”、“hex”时,图表如下。
sns.jointplot(x=df['A'], y=df['B'],data=df,kind='reg',size=5) #
sns.jointplot(x=df['A'], y=df['B'],data=df,kind='resid',size=5) #
sns.jointplot(x=df['A'], y=df['B'],data=df,kind='kde',size=5) #
sns.jointplot(x=df['A'], y=df['B'],data=df,kind='hex',size=5) #蜂窝图

在密度图中添加散点图,先通过sns.jointplot()创建密度图并赋值给变量,再通过变量.plot_joint()在密度图中添加散点图。
rs = np.random.RandomState(15)
df = pd.DataFrame(rs.randn(300,2),columns = ['A','B'])
g = sns.jointplot(x=df['A'], y=df['B'],data = df, kind="kde", color="pink",shade_lowest=False) #密度图,并赋值给一个变量
g.plot_joint(plt.scatter,c="w", s=30, linewidth=1, marker="+") #在密度图中添加散点图
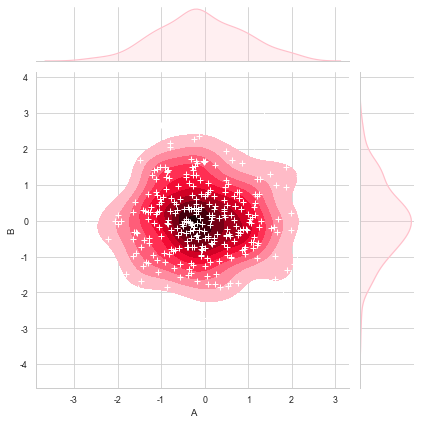
2.拆分综合散点图JointGrid()
上述综合散点图可分为上、右、中间三部分,设置属性时对这三个参数都生效,JointGrid()可将这三部分拆开分别设置属性。
①拆分为中间+上&右 两部分设置
# plot_joint() + plot_marginals()
g = sns.JointGrid(x="total_bill", y="tip", data=tips)# 创建一个绘图区域,并设置好x、y对应数据
g = g.plot_joint(plt.scatter,color="g", s=40, edgecolor="white") # 中间区域通过g.plot_joint绘制散点图
plt.grid('--') g.plot_marginals(sns.distplot, kde=True, color="y") # h = sns.JointGrid(x="total_bill", y="tip", data=tips)# 创建一个绘图区域,并设置好x、y对应数据
h = h.plot_joint(sns.kdeplot,cmap = 'Reds_r') # 中间区域通过g.plot_joint绘制散点图
plt.grid('--')
h.plot_marginals(sns.kdeplot, color="b")

②拆分为中间+上+右三个部分分别设置
# plot_joint() + ax_marg_x.hist() + ax_marg_y.hist()
sns.set_style("white")# 设置风格
tips = sns.load_dataset("tips") # 导入系统的小费数据
print(tips.head())
g = sns.JointGrid(x="total_bill", y="tip", data=tips)# 创建绘图区域,设置好x、y对应数据
g.plot_joint(plt.scatter, color ='y', edgecolor = 'white') # 设置内部散点图scatter
g.ax_marg_x.hist(tips["total_bill"], color="b", alpha=.6,bins=np.arange(0, 60, 3)) # 设置x轴直方图,注意bins是数组
g.ax_marg_y.hist(tips["tip"], color="r", alpha=.6, orientation="horizontal", bins=np.arange(0, 12, 1)) # 设置y轴直方图,需要orientation参数
from scipy import stats
g.annotate(stats.pearsonr) # 设置标注,可以为pearsonr,spearmanr
plt.grid(linestyle = '--')


3.pairplot()矩阵散点图
矩阵散点图类似pandas的pd.plotting.scatter_matrix(...),将数据从多个维度进行两两对比。
对角线默认显示密度图,非对角线默认显示散点图。
sns.set_style("white")
iris = sns.load_dataset("iris")
print(iris.head())
sns.pairplot(iris,
kind = 'scatter', # 散点图/回归分布图 {‘scatter’, ‘reg’}
diag_kind="hist", # 对角线处直方图/密度图 {‘hist’, ‘kde’}
hue="species", # 按照某一字段进行分类
palette="husl", # 设置调色板
markers=["o", "s", "D"], # 设置不同系列的点样式(个数与hue分类的个数一致)
height = 1.5, # 图表大小
)
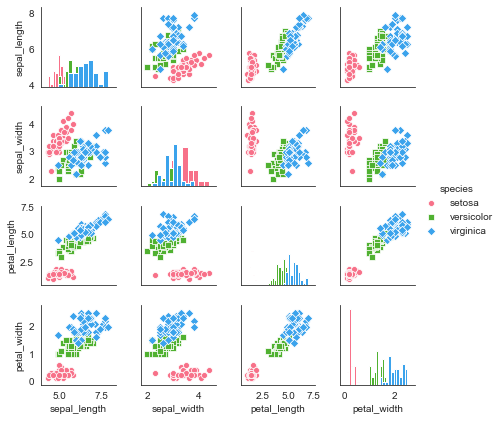
对原数据的局部变量进行分析,可添加参数vars
sns.pairplot(iris,vars=["sepal_width", "sepal_length"], kind = 'reg', diag_kind="kde", hue="species", palette="husl")

plot_kws()和diag_kws()可分别设置对角线和非对角线的显示
sns.pairplot(iris, vars=["sepal_length", "petal_length"],diag_kind="kde", markers="+",
plot_kws=dict(s=50, edgecolor="b", linewidth=1),# 设置非对角线点样式
diag_kws=dict(shade=True,color='r',linewidth=1)# 设置对角线密度图样式
)

4.拆分综合散点图JointGrid()
类似JointGrid()的功能,将矩阵散点图拆分为对角线和非对角线图表分别设置显示属性。
①拆分为对角线和非对角线
# map_diag() + map_offdiag() g = sns.PairGrid(iris,hue="species",palette = 'hls',vars=["sepal_width", "sepal_length"])
g.map_diag(plt.hist, # 对角线图表,plt.hist/sns.kdeplot
histtype = 'barstacked', # 可选:'bar', 'barstacked', 'step', 'stepfilled'
linewidth = 1, edgecolor = 'gray')
g.map_offdiag(plt.scatter, # f非对角线其他图表,plt.scatter/plt.bar...
edgecolor="yellow", s=20, linewidth = 1, # 设置点颜色、大小、描边宽度)

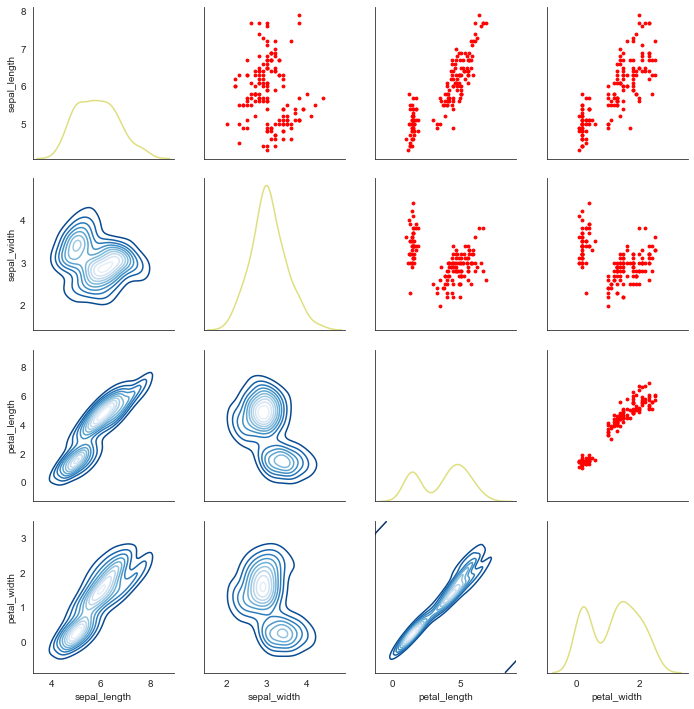
②拆分为对角线+对角线上+对角线下 3部分设置
# map_diag() + map_lower() + map_upper()
g = sns.PairGrid(iris)
g.map_diag(sns.kdeplot, lw=1.5,color='y',alpha=0.5) # 设置对角线图表
g.map_upper(plt.scatter, color = 'r',s=8) # 设置对角线上端图表显示为散点图
g.map_lower(sns.kdeplot,cmap='Blues_r') # 设置对角线下端图表显示为多密度分布图
seaborn分布数据可视化:直方图|密度图|散点图的更多相关文章
- Python图表数据可视化Seaborn:1. 风格| 分布数据可视化-直方图| 密度图| 散点图
conda install seaborn 是安装到jupyter那个环境的 1. 整体风格设置 对图表整体颜色.比例等进行风格设置,包括颜色色板等调用系统风格进行数据可视化 set() / se ...
- Echarts数据可视化series-radar雷达图,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
- Echarts数据可视化series-line线图,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
- Echarts数据可视化series-graph关系图,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
- Python数据可视化——使用Matplotlib创建散点图
Python数据可视化——使用Matplotlib创建散点图 2017-12-27 作者:淡水化合物 Matplotlib简述: Matplotlib是一个用于创建出高质量图表的桌面绘图包(主要是2D ...
- seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化
一.线性关系数据可视化lmplot( ) 表示对所统计的数据做散点图,并拟合一个一元线性回归关系. lmplot(x, y, data, hue=None, col=None, row=None, p ...
- R绘图(1): 在散点图边缘加上直方图/密度图/箱型图
当我们在绘制散点图的时候,可能会遇到点特别多的情况,这时点与点之间过度重合,影响我们对图的认知.为了更好地反映特征,我们可以加上点的密度信息,比如在原来散点所在的位置将密度用热图的形式呈现出来,再比如 ...
- Matplotlib学习---用matplotlib画直方图/密度图(histogram, density plot)
直方图用于展示数据的分布情况,x轴是一个连续变量,y轴是该变量的频次. 下面利用Nathan Yau所著的<鲜活的数据:数据可视化指南>一书中的数据,学习画图. 数据地址:http://d ...
- 用Python的Plotly画出炫酷的数据可视化(含各类图介绍,附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 我被狗咬了 在谈及数据可视化的时候,我们通常都会使用到matplo ...
随机推荐
- node+ajax实战案例(4)
4.用户登录实现 4.1.用户登录实现思路 1 用户输入登录信息,点击登录的时候把用户登录的这些信息收集起来,然后组装数据通过ajax方式发送到后台 2 后台接到用户输入的登录信息,把这些信息拿去和数 ...
- JavaScript基础对象创建模式之命名空间(Namespace)模式(022)
JavaScript中的创建对象的基本方法有字面声明(Object Literal)和构造函数两种,但JavaScript并没有特别的语法来表示如命名空间.模块.包.私有属性.静态属性等等面向对象程序 ...
- how to switch a different buffer from a terminal buffer
In term-mode, any regular C-x whatever keybinding becomes C-c whatever instead.
- 关于soapui的使用
打开SoapUI软件,点击File -->NewSoapProject 创建测试项目 输入测试项目名称,点击OK保存 在测试项目上右击选择AddWSDL 输入所需要测试的接口地址,点击ok确 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- 深入了解JVM-方法区
本文首发于微信公众号[猿灯塔],转载引用请说明出处 今天呢!灯塔君跟大家讲: 深入了解JVM-方法区 当JVM使用类装载器装载某个类时,它首先要定位对应的class文件,然后读入这个class文件,最 ...
- 包含min函数的栈(剑指offer-20)
题目描述 定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数(时间复杂度应为O(1)). 注意:保证测试中不会当栈为空的时候,对栈调用pop()或者min()或者top()方法 ...
- 报错信息ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.9' not found (required by............)
报错信息ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.9' not found (required by............) L ...
- Django---进阶14
目录 登陆功能 首页搭建 admin后台管理 用户头像展示 图片防盗链 个人站点 侧边栏筛选功能 登陆功能 def login(request): if request.method == 'POST ...
- Pop!_OS配置JAVA环境
Pop!_OS配置JAVA环境 #0x0 安装vscode #0x1 安装JDK #0x2 配置vscode #0x3 安装Eclipse #0x0 安装vscode 见Pop!_OS下安装C++编程 ...