整理requests和正则表达式爬取猫眼Top100中遇到的问题及解决方案
最近看崔庆才老师的爬虫课程,第一个实战课程是requests和正则表达式爬取猫眼电影Top100榜单。虽然理解崔老师每一步代码的实现过程,但自己敲代码的时候还是遇到了不少问题:
问题1:获取response.text时出现中文乱码的问题
问题2:通过requests.get()方法获取的网页代码与网页源代码不一致的问题
问题3:正则表达式匹配内容为空(多次修改pattern,甚至直接copy崔老师视频中的pattern也输出为空)
问题1:获取response.text时出现中文乱码的问题
1 import requests
2 from requests.exceptions import RequestException
3 import re
4
5 def get_one_page(url):
6 try:
7 response = requests.get(url)
8 if response.status_code == 200:
9 return response.text
10 else:
11 return None
12 except RequestException:
13 return None
14
15 shili = get_one_page('http://maoyan.com/board/4?')
16 print(shili)
上述代码运行后出现中文乱码的问题,经过网上收集资料显示:requests是从服务器返回的Response Headers 中Content-Type中获取编码,若指定了Charset就根据指定识别编码,否则就使用默认的ISO-8859-1,当服务器不符合此规范时就会出现乱码。解决方案是根据requests中的utils模块的get_encodings_from_content()方法进行解码:
# 将上述代码中第9行进行修改
content = response.text.encode('ISO-8859-1').decode(requests.utils.get_encodings_from_content(response.text)[0])
return content
这样就顺利解决了中文乱码的问题,但是后面发现有更简单的方法(通过添加headers参数):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecho) Chrome/85.0.4183.121 Safari/537.36'
}
response = requests.get(url, headers=headers)
问题2:通过requests.get()方法获取的网页代码与网页源代码不一致的问题
从network - Requests Headers下直接复制user-agent来添加请求头,发现得到的网页代码html属性是“android”:
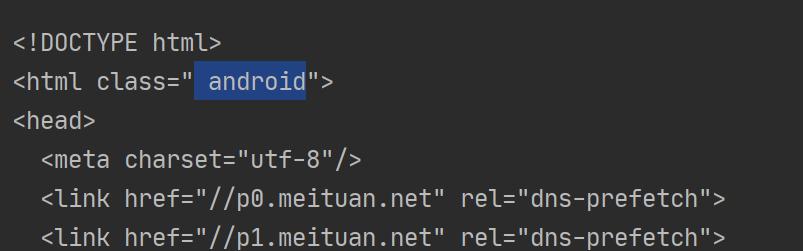
正确的源代码应该是这样的:

经过与崔老师的代码比较并进行调试,发现是浏览器复制的请求头出现了问题:
浏览器直接复制的user-agent 是这样的:

于是我上网搜索请求头user-agent的构成,以Chrome为例:

将其分为四个部分:
(1)默认部分:Mozilla/5.0
(2)表示操作系统版本部分:(Windows NT 10.0; Win64; x64)
(3)表示搜索引擎部分:AppleWebKit/537.36 (KHTML, like Gecho)
(4)表示浏览器版本部分:Chrome/85.0.4183.121 Safari/537.36
发现通过浏览器直接复制的user-agent中操作系统版本不对,这是因为在F12代码页面下点击了左上角的手机模式,将其关闭即可。
问题3:正则表达式匹配内容为空(多次修改pattern,甚至直接copy视频中的pattern也输出为空)
敲代码时自己尝试写正则表达式,运行后没有报错但是返回空列表:
def parser_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a.*?>'
+ '(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">'
+ '(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
print(items) def main():
url = 'https://maoyan.com/board/4?'
html = get_one_page(url)
parser_one_page(html) if __name__ == '__main__':
main()
后面发现直接复制URL时是https协议,改为http后能够正确返回pattern匹配内容。
非计算机专业爬虫小白,理论知识不足,欢迎计算机大神批评指正。
整理requests和正则表达式爬取猫眼Top100中遇到的问题及解决方案的更多相关文章
- 使用Requests+正则表达式爬取猫眼TOP100电影并保存到文件或MongoDB,并下载图片
需要着重学习的地方:(1)爬取分页数据时,url链接的构建(2)保存json格式数据到文件,中文显示问题(3)线程池的使用(4)正则表达式的写法(5)根据图片url链接下载图片并保存(6)MongoD ...
- requests和正则表达式爬取猫眼电影Top100练习
1 import requests 2 import re 3 from multiprocessing import Pool 4 from requests.exceptions import R ...
- Requests+BeautifulSoup+正则表达式爬取猫眼电影Top100(名称,演员,评分,封面,上映时间,简介)
# encoding:utf-8 from requests.exceptions import RequestException import requests import re import j ...
- python3.6 利用requests和正则表达式爬取猫眼电影TOP100
import requests from requests.exceptions import RequestException from multiprocessing import Pool im ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- 14-Requests+正则表达式爬取猫眼电影
'''Requests+正则表达式爬取猫眼电影TOP100''''''流程框架:抓去单页内容:利用requests请求目标站点,得到单个网页HTML代码,返回结果.正则表达式分析:根据HTML代码分析 ...
- Python 爬取 猫眼 top100 电影例子
一个Python 爬取猫眼top100的小栗子 import json import requests import re from multiprocessing import Pool #//进程 ...
- python爬虫:爬取猫眼TOP100榜的100部高分经典电影
1.问题描述: 爬取猫眼TOP100榜的100部高分经典电影,并将数据存储到CSV文件中 2.思路分析: (1)目标网址:http://maoyan.com/board/4 (2)代码结构: (3) ...
- 使用Beautiful Soup爬取猫眼TOP100的电影信息
使用Beautiful Soup爬取猫眼TOP100的电影信息,将排名.图片.电影名称.演员.时间.评分等信息,提取的结果以文件形式保存下来. import time import json impo ...
随机推荐
- Selenium执行js脚本
如何使用Selenium来执行Javascript脚本呢 Selenium中提供了一个方法:execute_script 来执行js脚本 return 可以返回js的返回结果 execute_scri ...
- vue 组件内的守卫
1.beforeRouteEnter () // 进入该组件之前要去进行的逻辑操作, 2.beforeRouteLeave() // 离开该组件之前要去进行的逻辑操作(可清除定时器等耗用内存的变量, ...
- Unity3d流光效果
Material中纹理的属性都有Tiling和Offset,可以利用Offset做uv动画,从而完成各种有趣的动画,比如流光效果! 流过效果即通常一条高光光在物体上划过,模拟高光移动照射物体的效果,之 ...
- Ignatius and the Princess IV (水题)
"OK, you are not too bad, em... But you can never pass the next test." feng5166 says. &qu ...
- linux安装dubbo与zookeeper(一)
所需工具: jdk1_7.tar.gz dubbo-admin-2.5.4.war(此文件不需解压) zookeeper.tar.gz tomcat7.0.tar.gz 以上文件下载需根据自己的电脑系 ...
- 使用代码生成工具快速生成基于ABP框架的Vue+Element的前端界面
世界上唯一不变的东西就是变化,我们通过总结变化的规律,以规律来应付变化,一切事情处理起来事半功倍.我们在开发后端服务代码,前端界面代码的时候,界面都是依照一定的规律进行变化的,我们通过抽取数据库信息, ...
- Tomcat9w.exe无法启动为started
问题: startup.bat可以正常启动,http://localhost:8080/ 可以正常访问.但是Tomcat9w.exe无法启动为started,一直为Stopped. 解决方案: 如下图 ...
- python基础 格式化输出
格式化输出 '%s %d %.2f' % ('Novak', 33, 1.88) 需要逗号
- Typecho 使用
安装 下载Typecho 链接:typecho 下载后得到一个压缩文件,解压后获得目录如下: 将该文件夹改名为blog并且上传到/var/www/blog目录下:如下: 修改apache配置 参考:链 ...
- Docker 学习笔记一
Docker 学习笔记一 1.Docker是什么? Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源.让开发者打包他们的应用以及依赖包到一 ...