C++ folly库解读(二) small_vector —— 小数据集下的std::vector替代方案
介绍
行为与std::vector类似,但是使用了small buffer optimization(类似于fbstring中的SSO),将指定个数的数据内联在对象中,而不是像std::vector直接将对象分配在堆上,避免了malloc/free的开销。
small_vector基本兼容std::vector的接口。
small_vector<int,2> vec;
vec.push_back(0); // Stored in-place on stack
vec.push_back(1); // Still on the stack
vec.push_back(2); // Switches to heap buffer.
small_vector<int,2> vec指定可以内联在对象中2个数据:
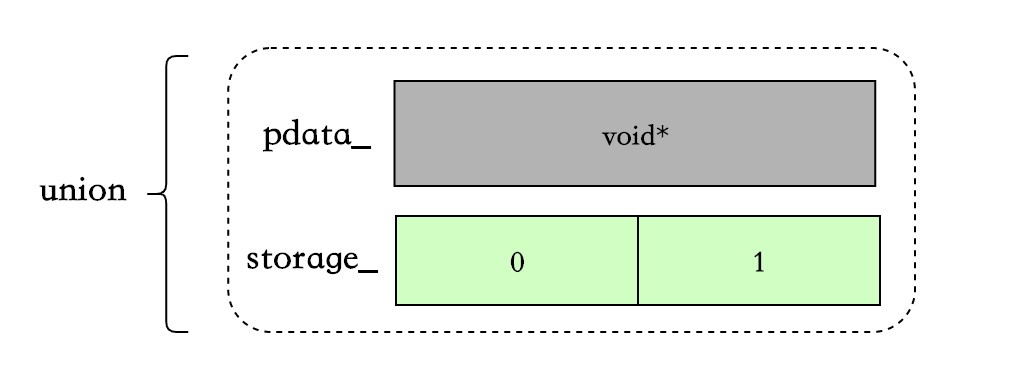
当超过2个后,后续添加的数据会被分配到堆上,之前的2个数据也会被一起move到堆上:
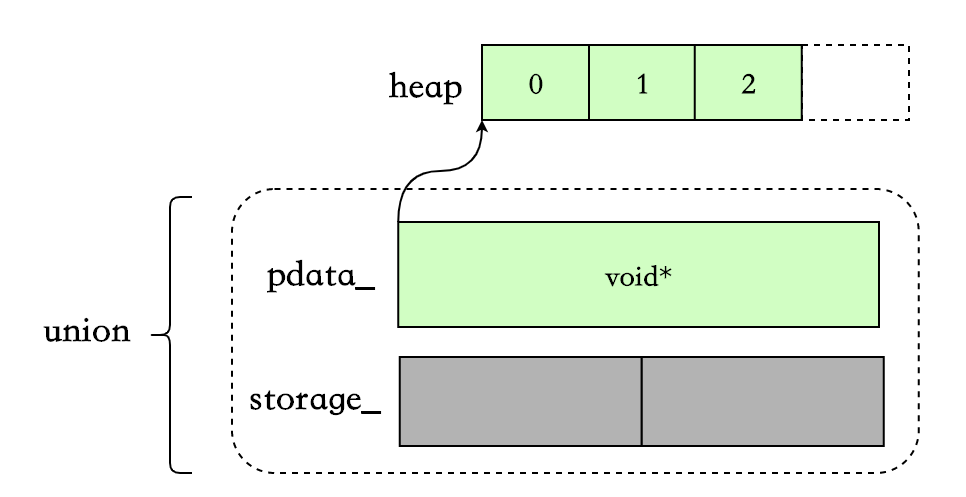
使用场景
根据官方文档的介绍,small_vector在下面3种场景中很有用:
- 需要使用的vector的生命周期很短(比如在函数中使用),并且存放的数据占用空间较小,那么此时节省一次malloc是值得的。
- 如果vector大小固定且需要频繁查询,那么在绝大多数情况下会减少一次cpu cache miss,因为数据是内联在对象中的。
- 如果需要创建上亿个vector,而且不想在记录capacity上浪费对象空间(一般的vector对象内会有三个字段:pointer _Myfirst、pointer _Mylast、pointer _Myend)。small_vector允许让malloc来追踪
allocation capacity(这会显著的降低insertion/reallocation效率,如果对这两个操作的效率比较在意,你应该使用FBVector,FBVector在官方描述中可以完全代替std::vector)
比如在io/async/AsyncSocket.h中,根据条件的不同使用small_vector或者std::vector:
// Lifecycle observers.
//
// Use small_vector to avoid heap allocation for up to two observers, unless
// mobile, in which case we fallback to std::vector to prioritize code size.
using LifecycleObserverVecImpl = conditional_t<
!kIsMobile,
folly::small_vector<AsyncTransport::LifecycleObserver*, 2>,
std::vector<AsyncTransport::LifecycleObserver*>>;
LifecycleObserverVecImpl lifecycleObservers_;
// push_back
void AsyncSocket::addLifecycleObserver(
AsyncTransport::LifecycleObserver* observer) {
lifecycleObservers_.push_back(observer);
}
// for loop
for (const auto& cb : lifecycleObservers_) {
cb->connect(this);
}
// iterator / erase
const auto eraseIt = std::remove(
lifecycleObservers_.begin(), lifecycleObservers_.end(), observer);
if (eraseIt == lifecycleObservers_.end()) {
return false;
}
为什么不是std::array
下面两种情况,small_vector比std::array更合适:
- 需要空间后续动态增长,不仅仅是编译期的固定size。
- 像上面的例子,根据不同条件使用std::vector/small_vector,且使用的API接口是统一的。
其他用法
NoHeap: 当vector中数据个数超过指定个数时,不会再使用堆。如果个数超过指定个数,会抛出std::length_error异常。<Any integral type>: 指定small_vector中size和capacity的数据类型。
// With space for 32 in situ unique pointers, and only using a 4-byte size_type.
small_vector<std::unique_ptr<int>, 32, uint32_t> v;
// A inline vector of up to 256 ints which will not use the heap.
small_vector<int, 256, NoHeap> v;
// Same as the above, but making the size_type smaller too.
small_vector<int, 256, NoHeap, uint16_t> v;
其中,依赖boost::mpl元编程库,可以让后两个模板变量任意排序。
其他类似库
Benchmark
没有找到官方的benchmark,自己简单的写了一个,不测试数据溢出到堆上的情况。
插入4个int,std::vector使用reserve(4)预留空间。
BENCHMARK(stdVector, n) {
FOR_EACH_RANGE(i, 0, n) {
std::vector<int> vec;
vec.reserve(4);
for (int i = 0; i < 4; i++) {
vec.push_back(1);
}
doNotOptimizeAway(vec);
}
}
BENCHMARK_DRAW_LINE();
BENCHMARK_RELATIVE(smallVector, n) {
FOR_EACH_RANGE(i, 0, n) {
small_vector<int, 4> vec;
for (int i = 0; i < 4; i++) {
vec.push_back(1);
}
doNotOptimizeAway(vec);
}
}
结果是:small_vector比std::vector快了40%:
============================================================================
delve_folly/benchmark.cc relative time/iter iters/s
============================================================================
stdVector 440.79ns 2.27M
----------------------------------------------------------------------------
smallVector 140.48% 313.77ns 3.19M
============================================================================
如果把stdVector中的vec.reserve(4);去掉,那么small_vector速度比std::vector快了3倍。在我的环境上,std::vector的扩容因子为2,如果不加reserve,那么std::vector会有2次扩容的过程(貌似很多人不习惯加reserve,是有什么特别的原因吗 : )):
============================================================================
delve_folly/benchmark.cc relative time/iter iters/s
============================================================================
stdVector 1.26us 795.06K
----------------------------------------------------------------------------
smallVector 417.25% 301.44ns 3.32M
============================================================================
代码关注点
small_vector代码比较少,大概1300多行。主要关注以下几个方面:
- 主要类。
- 数据存储结构,capacity的存储会复杂一些。
- 扩容过程,包括数据从对象中迁移到堆上。
- 常用的函数,例如push_back、reserve、resize。
- 使用makeGuard代替了原版的try-catch。
- 通过boost::mpl支持模板参数任意排序。
- 通过boost-operators简化operator以及C++20的<=>。
主要类
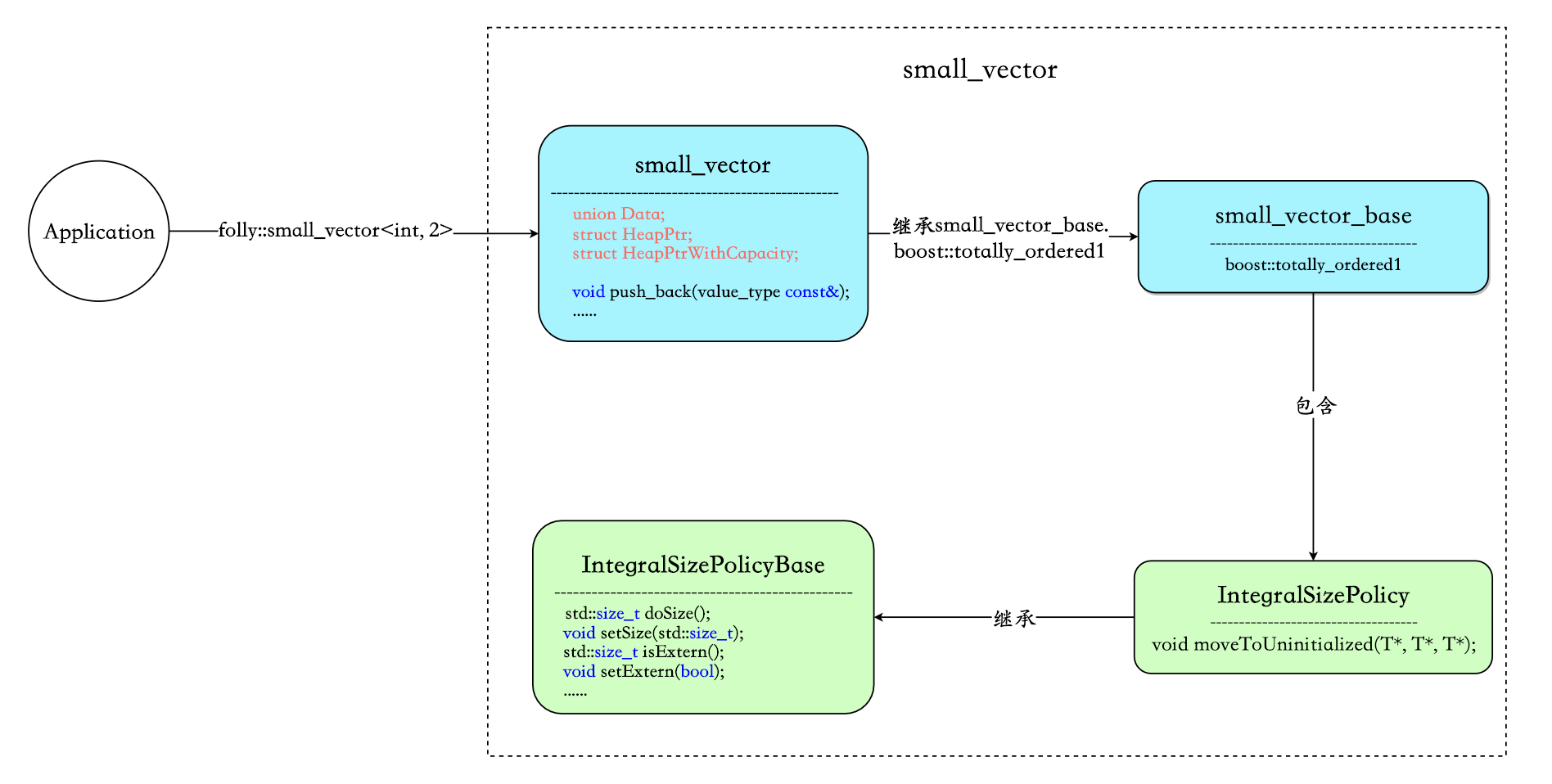
- small_vector : 包含的核心字段为
union Data、struct HeapPtr、struct HeapPtrWithCapacity,这三个字段负责数据的存储。此外small_vector对外暴露API接口,例如push_back、reserve、resize等。 - small_vector_base : 没有对外提供任何函数接口,类内做的就是配合boost::mpl元编程库在编译期解析模板参数,同时生成boost::totally_ordered1供small_vector继承,精简operator代码。
- IntegralSizePolicyBase:负责size/extern/heapifiedCapacity相关的操作。
- IntegralSizePolicy : 负责内联数据溢出到堆的过程。
small_vector
声明:
template <
class Value,
std::size_t RequestedMaxInline = 1,
class PolicyA = void,
class PolicyB = void,
class PolicyC = void>
class small_vector : public detail::small_vector_base<
Value,
RequestedMaxInline,
PolicyA,
PolicyB,
PolicyC>::type
声明中有三个策略模板参数是因为在一次提交中删除了一个无用的策略,OneBitMutex:Delete small_vector's OneBitMutex policy。
small_vector_base
template <
class Value,
std::size_t RequestedMaxInline,
class InPolicyA,
class InPolicyB,
class InPolicyC>
struct small_vector_base;
boost::mpl放到最后说吧 :)
数据结构
small_vector花了一些心思在capacity的设计上,尽可能减小对象内存,降低内联数据带来的影响。
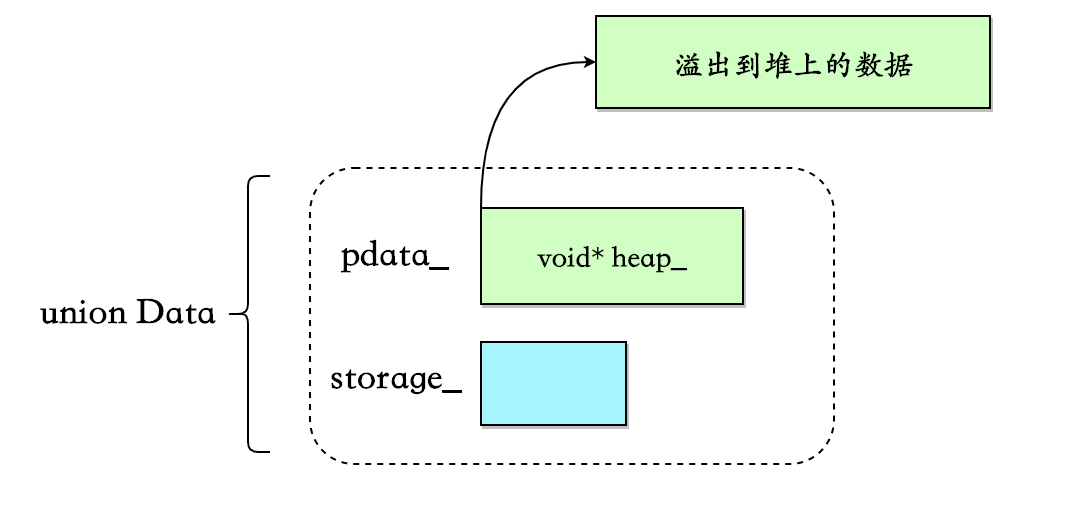
union Data负责存储数据:
union Data{
PointerType pdata_; // 溢出到堆后的数据
InlineStorageType storage_; // 内联数据
}u;
InlineStorageType
使用std::aligned_storage进行初始化,占用空间是sizeof(value_type) * MaxInline,对齐要求为alignof(value_type):
typedef typename std::aligned_storage<sizeof(value_type) * MaxInline, alignof(value_type)>::type InlineStorageType;
capacity
与std::vector用结构体字段表示capacity不同,small_vector的capacity存放分为三种情况。
capacity内联在对象中
这是最简单的一种情况:
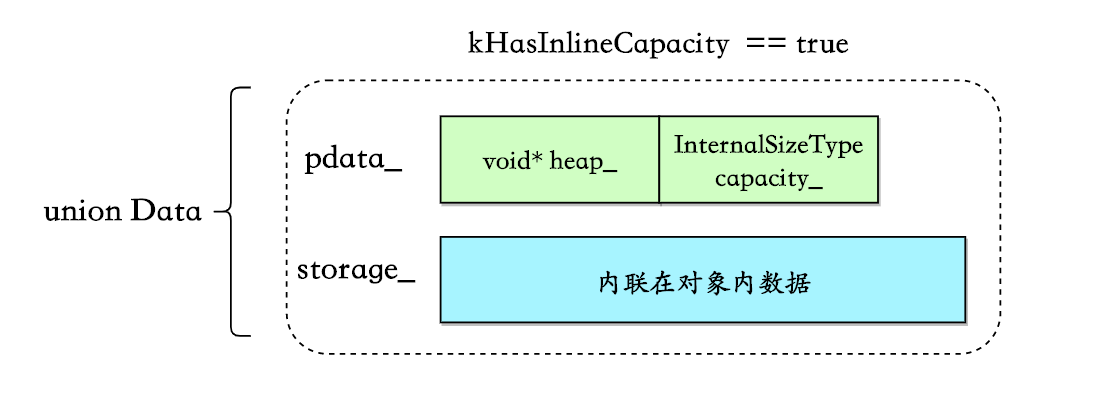
条件为sizeof(HeapPtrWithCapacity) < sizeof(InlineStorageType) (这里我不明白为什么等于的情况不算在内):
static bool constexpr kHasInlineCapacity = sizeof(HeapPtrWithCapacity) < sizeof(InlineStorageType);
typedef typename std::conditional<kHasInlineCapacity, HeapPtrWithCapacity, HeapPtr>::type PointerType;
struct HeapPtrWithCapacity {
value_type* heap_;
InternalSizeType capacity_;
} ;
union Data{
PointerType pdata_; // 溢出到堆后的数据
InlineStorageType storage_; // 内联数据
}u;
通过malloc_usable_size获取capacity
假如上述kHasInlineCapacity == false,即sizeof(InlineStorageType) <= sizeof(HeapPtrWithCapacity)时,考虑到节省对象空间,capacity不会内联在对象中,此时PointerType的类型为HeapPtr,内部只保留一个指针:
struct HeapPtr {
value_type* heap_;
} ;
union Data{
PointerType pdata_; // 溢出到堆后的数据
InlineStorageType storage_; // 内联数据
}u;
那么此时capacity存放在哪里了呢?这里又分了两种情况,第一种就是这里要说明的:直接通过malloc_usable_size获取从堆上分配的内存区域的可用数据大小,这个结果就被当做small_vector当前的capacity:
malloc_usable_size(heap_) / sizeof(value_type); // heap_指向堆上的数据
但是有一个问题,由于内存分配存在alignment和minimum size constraints的情况,malloc_usable_size返回的大小可能会大于申请时指定的大小,但是folly会利用这部分多余的空间来存放数据(如果能放的下)。
比如在不使用jemalloc的情况下,在扩容的函数内,将向系统申请的字节数、malloc_usable_size返回的可用空间、small_vector的capacity打印出来:
folly::small_vector<uint32_t, 2> vec; // uint32_t => four bytes
for (int i = 0; i < 200; i++) {
vec.push_back(1);
std::cout << vec.capacity() << std::endl;
}
// 代码进行了简化
template <typename EmplaceFunc>
void makeSizeInternal(size_type newSize, bool insert, EmplaceFunc&& emplaceFunc, size_type pos) {
const auto needBytes = newSize * sizeof(value_type);
const size_t goodAllocationSizeBytes = goodMallocSize(needBytes);
const size_t newCapacity = goodAllocationSizeBytes / sizeof(value_type);
const size_t sizeBytes = newCapacity * sizeof(value_type);
void* newh = checkedMalloc(sizeBytes);
std::cout << "sizeBytes:" << sizeBytes << " malloc_usable_size:" << malloc_usable_size(newh) << " "
<< kMustTrackHeapifiedCapacity << std::endl;
// move元素等操作,略过....
}
// output :
2
2
sizeBytes:16 malloc_usable_size:24 0
6
6
6
6
sizeBytes:40 malloc_usable_size:40 0
10
10
10
10
sizeBytes:64 malloc_usable_size:72 0
18
18
18
18
18
18
18
18
......
......
可以看出,扩容时即使向系统申请16字节的空间,malloc_usable_size返回的是24字节,而small_vector此时的capacity也是24,即会利用多余的8个字节额外写入2个数据。
**如果使用了jemalloc **,那么会根据size classes分配空间。
这种方式也是有使用条件的,即needbytes >= kHeapifyCapacityThreshold,kHeapifyCapacityThreshold的定义为:
// This value should we multiple of word size.
static size_t constexpr kHeapifyCapacitySize = sizeof(typename std::aligned_storage<sizeof(InternalSizeType), alignof(value_type)>::type);
// Threshold to control capacity heapifying.
static size_t constexpr kHeapifyCapacityThreshold = 100 * kHeapifyCapacitySize;
我没想明白这个100是怎么定下来的
C++ folly库解读(二) small_vector —— 小数据集下的std::vector替代方案的更多相关文章
- C++ folly库解读(三)Synchronized —— 比std::lock_guard/std::unique_lock更易用、功能更强大的同步机制
目录 传统同步方案的缺点 folly/Synchronized.h 简单使用 Synchronized的模板参数 withLock()/withRLock()/withWLock() -- 更易用的加 ...
- Android图表库MPAndroidChart(二)——线形图的方方面面,看完你会回来感谢我的
Android图表库MPAndroidChart(二)--线形图的方方面面,看完你会回来感谢我的 在学习本课程之前我建议先把我之前的博客看完,这样对整体的流程有一个大致的了解 Android图表库MP ...
- 从函数式编程到Ramda函数库(二)
Ramda 基本的数据结构都是原生 JavaScript 对象,我们常用的集合是 JavaScript 的数组.Ramda 还保留了许多其他原生 JavaScript 特性,例如,函数是具有属性的对象 ...
- php--------php库生成二维码和有logo的二维码
php生成二维码和带有logo的二维码,上一篇博客讲的是js实现二维码:php--------使用js生成二维码. 今天写的这个小案例是使用php库生成二维码: 效果图: 使用了 php ...
- Recorder︱深度学习小数据集表现、优化(Active Learning)、标注集网络获取
一.深度学习在小数据集的表现 深度学习在小数据集情况下获得好效果,可以从两个角度去解决: 1.降低偏差,图像平移等操作 2.降低方差,dropout.随机梯度下降 先来看看深度学习在小数据集上表现的具 ...
- 面向小数据集构建图像分类模型Keras
文章信息 本文地址:http://blog.keras.io/building-powerful-image-classification-models-using-very-little-data. ...
- Seaborn(二)之数据集分布可视化
Seaborn(二)之数据集分布可视化 当处理一个数据集的时候,我们经常会想要先看看特征变量是如何分布的.这会让我们对数据特征有个很好的初始认识,同时也会影响后续数据分析以及特征工程的方法.本篇将会介 ...
- 9.3.1 map端连接- DistributedCache分布式缓存小数据集
1.1.1 map端连接- DistributedCache分布式缓存小数据集 当一个数据集非常小时,可以将小数据集发送到每个节点,节点缓存到内存中,这个数据集称为边数据.用map函数 ...
- 我的Keras使用总结(2)——构建图像分类模型(针对小数据集)
Keras基本的使用都已经清楚了,那么这篇主要学习如何使用Keras进行训练模型,训练训练,主要就是“练”,所以多做几个案例就知道怎么做了. 在本文中,我们将提供一些面向小数据集(几百张到几千张图片) ...
随机推荐
- idea使用maven的打包工具package不会打上主类解决方法
- CF-1451 E Bitwise Queries 异或 交互题
E - Bitwise Queries 传送门 题意 有一组序列,长度为 \(n(4\le n \le 2^{16})\),且 \(n\) 为 2 的整数次幂,序列中数值范围为 [0,n-1], 每次 ...
- Educational Codeforces Round 86 (Div. 2)
比赛链接:https://codeforces.com/contest/1342 A - Road To Zero 题意 有两个非负整数 x, y 以及两种操作: 支付 a 点代价使其中一个数加一或减 ...
- Codeforces Round #570 (Div. 3) G. Candy Box (hard version) (贪心,优先队列)
题意:你有\(n\)个礼物,礼物有自己的种类,你想将它们按种类打包送人,但是打包的礼物数量必须不同(数量,与种类无关),同时,有些礼物你想自己留着,\(0\)表示你不想送人,问你在送出的礼物数量最大的 ...
- - Visible Trees HDU - 2841 容斥原理
题意: 给你一个n*m的矩形,在1到m行,和1到n列上都有一棵树,问你站在(0,0)位置能看到多少棵树 题解: 用(x,y)表示某棵树的位置,那么只要x与y互质,那么这棵树就能被看到.不互质的话说明前 ...
- A - 你能数的清吗 51Nod - 1770
题目: 演演是个厉害的数学家,他最近又迷上了数字谜.... 他很好奇 xxx...xxx(n个x)*y 的答案中 有多少个z,x,y,z均为位数只有一位的整数. 大概解释一下: 22222*3 = ...
- Bone Collector II HDU - 2639 01背包第k最大值
题意: 01背包,找出第k最优解 题解: 对于01背包最优解我们肯定都很熟悉 第k最优解的话也就是在dp方程上加一个维度来存它的第k最优解(dp[i][j]代表,体积为i能获得的第j最大价值) 对于每 ...
- 三、Python基本数据类型
一.基本算术运算(获取的结果是值) 1 a1=10 2 a2=20#初始赋值 3 a3=a1+a2 #结果30 4 a4=a2-a1 #结果10 5 a5=a1*a2 #结果200 6 a6=a2/a ...
- 详解Go语言I/O多路复用netpoller模型
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 本文使用的go的源码15.7 可以从 Go 源码目录结构和对应代码文件了解 Go 在不同 ...
- meterpreter php payload && windows payload 学习
一 情景 本地kali linux 192.168.1.2 目标 windows NT 服务器192.168.1.4 目的是获取shell 二 过程 首先在linux建立终端 ,msfconsole ...