Apache Pulsar 在 BIGO 的性能调优实战(上)
背景
在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频)。Bigo Live 在 150 多个国家/地区兴起,Likee 有 1 亿多用户,并在 Z 世代中很受欢迎。
随着业务的迅速增长,BIGO 消息队列平台承载的数据规模出现了成倍增长,下游的在线模型训练、在线推荐、实时数据分析、实时数仓等业务对消息的实时性和稳定性提出了更高的要求。
BIGO 消息队列平台使用的是开源 Kafka,然而随着业务数据量的成倍增长、消息实时性和系统稳定性要求不断提高,多个 Kafka 集群的维护成本越来越高,主要体现在:
- 数据存储和消息队列服务绑定,集群扩缩容/分区均衡需要大量拷贝数据,造成集群性能下降
- 当分区副本不处于 ISR(同步)状态时,一旦有 broker 发生故障,可能会造成丢数或该分区无法提供读写服务
- 当 Kafka broker 磁盘故障/使用率过高时,需要进行人工干预
- 集群跨区域同步使用 KMM(Kafka Mirror Maker),性能和稳定性难以达到预期
- 在 catch-up 读场景下,容易出现 PageCache 污染,造成读写性能下降
- 虽然 Kafka 的 topic partition 是顺序写入,但是当 broker上有成百上千个topic partition 时,从磁盘角度看就变成了随机写入,此时磁盘读写性能会随着 topic partition 数量的增加而降低,因此 Kafka broker 上存储的 topic partition 数量是有限制的
- 随着 Kafka 集群规模的增长,Kakfa 集群的运维成本急剧增长,需要投入大量的人力进行日常运维。在 BIGO,扩容一台机器到 Kafka 集群并进行分区均衡,需要 0.5人/天;缩容一台机器需要 1 人/天
为了提高消息队列实时性、稳定性和可靠性,降低运维成本,我们重新考虑了 Kafka 架构设计上的不足,调研能否从架构设计上解决这些问题,满足当前的业务要求。
下一代消息流平台:Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体。Pulsar 于 2016 年由 Yahoo 开源并捐赠给 Apache 软件基金会进行孵化,2018 年成为Apache 软件基金会顶级项目。
Pulsar 采用计算与存储分离的分层架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐以及低延时的高可扩展流数据存储特性。
Pulsar 吸引我们的主要特性如下:
- 线性扩展:能够无缝扩容到成百上千个节点
- 高吞吐:已经在 Yahoo 的生产环境中经受了考验,支持每秒数百万消息的 发布-订阅(Pub-Sub)
- 低延迟:在大规模的消息量下依然能够保持低延迟(小于 5 ms)
- 持久化机制:Plusar 的持久化机制构建在 Apache BookKeeper 上,提供了读写分离
- 读写分离:BookKeeper 的读写分离 IO 模型极大发挥了磁盘顺序写性能,对机械硬盘相对比较友好,单台 bookie 节点支撑的 topic 数不受限制
Apache Pulsar 的架构设计解决了我们使用 Kafka 过程中遇到的各种问题,并且提供了很多非常棒的特性,如多租户、消息队列和批流融合的消费模型、强一致性等。
为了进一步加深对 Apache Pulsar 的理解,衡量 Pulsar 能否真正满足我们生产环境大规模消息 Pub-Sub 的需求,我们从 2019 年 12 月份开始进行了一系列压测工作。由于我们使用的是机械硬盘,没有 SSD,在压测过程中遇到了一些列性能问题,非常感谢 StreamNative 同学的帮助,感谢斯杰、翟佳、鹏辉的耐心指导和探讨,经过一系列的性能调优,不断提高 Pulsar 的吞吐和稳定性。
经过 3~4 个月的压测和调优,2020 年 4 月份我们正式在生产环境中使用 Pulsar 集群。我们采用 bookie 和 broker 在同一个节点的混部模式,逐步替换生产环境的 Kafka 集群。截止到目前为止,生产环境中 Pulsar 集群规模为十几台,日处理消息量为百亿级别,并且正在逐步扩容和迁移 Kafka 流量到 Pulsar 集群。
压测/使用 Pulsar 遇到的问题
大家在使用/压测 Pulsar 时,可能会遇到如下问题:
- Pulsar broker 节点负载不均衡。
- Pulsar broker 端 Cache 命中率低,导致大量读请求进入 bookie,且读性能比较差。
- 压测时经常出现 broker 内存溢出现象(OOM)。
- Bookie 出现 direct memory OOM 导致进程挂掉。
- Bookie 节点负载不均衡,且经常抖动。
- 当 Journal 盘为 HDD 时,虽然关闭了 fsync,但是 bookie add entry 99th latency 依旧很高,写入性能较差。
- 当 bookie 中有大量读请求时,出现写被反压,add entry latency 上升。
- Pulsar client 经常出现“Lookup Timeout Exception”。
- ZooKeeper 读写延迟过高导致整个 Pulsar 集群不稳定。
- 使用 reader API(eg. pulsar flink connector) 消费 Pulsar topic 时,消费速度较慢(Pulsar 2.5.2 之前版本)。
当 Journal/Ledger 盘为机械硬盘(HDD)时,问题 4、5、6、7 表现得尤为严重。这些问题直观来看,是磁盘不够快造成的,如果 Journal/Ledger 盘读写速度足够快,就不会出现消息在 direct memory 中堆积,也就不会有一系列 OOM 的发生。
由于在我们消息队列生产系统中,需要存储的数据量比较大(TB ~ PB 级别),Journal 盘和 Ledger 盘都是 SSD 需要较高的成本,那么有没有可能在 Pulsar / BookKeeper 上做一些参数/策略的优化,让 HDD 也能发挥出较好的性能呢?
在压测和使用 Pulsar 过程中,我们遇到了一系列性能问题,主要分为 Pulsar Broker 层面和 BookKeeper 层面。为此,本系列性能调优文章分为两篇,分别介绍 BIGO 在使用 Pulsar 过程中对 Pulsar Broker 和 Bookkeeper 进行性能调优的解决方案,以使得 Pulsar 无论在磁盘为 SSD 还是 HDD 场景下,都能获得比较好的性能。
由于篇幅原因,本次性能调优系列分为两部分,上半部分主要介绍 Pulsar broker 的性能调优,下半部分主要介绍 BookKeeper 与 Pulsar 结合过程中的性能调优。
本文接下来主要介绍 Pulsar / BookKeeper 中和性能相关的部分,并提出一些性能调优的建议(这些性能调优方案已经在 BIGO 生产系统中稳定运行,并获得了不错的收益)。
环境部署与监控
环境部署与监控
由于 BookKeeper 和 Pulsar Broker 重度依赖 ZooKeeper,为了保证 Pulsar 的稳定,需要保证 ZooKeeper Read/Write 低延迟。此外,BookKeeper 是 IO 密集型任务,为了避免 IO 之间互相干扰,Journal/Ledger 放在独立磁盘上。总结如下:
- Bookie Journal/Ledger 目录放在独立磁盘上
- 当 Journal/Ledger 目录的磁盘为 HDD 时,ZooKeeper dataDir/dataLogDir 不要和 Journal/Ledger 目录放在同一块磁盘上
BookKeeper 和 Pulsar Broker 均依赖 direct memory,而且 BookKeeper 还依赖 PageCache 进行数据读写加速,所以合理的内存分配策略也是至关重要的。Pulsar 社区的 sijie 推荐的内存分配策略如下:
- OS: 1 ~ 2 GB
- JVM: 1/2
- heap: 1/3
- direct memory: 2/3
- PageCache: 1/2
假设机器物理内存为 128G,bookie 和 broker 混部,内存分配如下:
- OS: 2GB
- Broker: 31GB
- heap: 10GB
- direct memory: 21GB
- Bookie: 32GB
- heap: 10GB
- direct memory: 22GB
- PageCache: 63GB
Monitor:性能调优,监控先行
为了更加直观地发现系统性能瓶颈,我们需要为 Pulsar/BookKeeper 搭建一套完善的监控体系,确保每一个环节都有相关指标上报,当出现异常(包括但不限于性能问题)时,能够通过相关监控指标快速定位性能瓶颈,并制定相应解决方案。
Pulsar/BookKeeper 都提供了 Prometheus 接口,相关统计指标可以直接使用 Http 方式获取并直接对接 Prometheus/Grafana。感兴趣的同学可以直接按照 Pulsar Manager 的指导进行安装: https://github.com/streamnative/pulsar-manager。
需要重点关注的指标如下:
Pulsar Broker
- jvm heap/gc
- bytes in per broker
- message in per broker
- loadbalance
- broker 端 Cache 命中率
- bookie client quarantine ratio
- bookie client request queue
BookKeeper
- bookie request queue size
- bookie request queue wait time
- add entry 99th latency
- read entry 99th latency
- journal create log latency
- ledger write cache flush latency
- entry read throttle
ZooKeeper
- local/global ZooKeeper read/write request latency
有一些指标在上面 repo 中没有提供相应 Grafana 模板,大家可以自己添加 PromQL 进行配置。
Pulsar broker 端性能调优
对 Pulsar broker 的性能调优,主要分为如下几个方面:
- 负载均衡
- Broker 之间负载均衡
- Bookie 节点之间的负载均衡
- 限流
- Broker 接收消息需要做流控,防止突发洪峰流量导致 broker direct memory OOM。
- Broker 发送消息给 consumer/reader 时需要做流控,防止一次发送太多消息造成 consumer/reader 频繁 GC。
- 提高 Cache 命中率
- 保证 ZooKeeper 读写低延迟
- 关闭 auto bundle split,保证系统稳定
负载均衡
Broker 之间负载均衡
Broker 之间负载均衡,能够提高 broker 节点的利用率,提高 Broker Cache 命中率,降低 broker OOM 概率。这一部分内容主要涉及到 Pulsar bundle rebalance 相关知识。
Namespace Bundle 结构如下,每个 namespace(命名空间)由一定数量的 bundle 组成,该 namespace 下的所有 topic 均通过 hash 方式映射到唯一 bundle 上,然后 bundle 通过 load/unload 方式加载/卸载到提供服务的 broker 上。
如果某个 broker 上没有 bundle 或者 bundle 数量比其他 broker 少,那么这台 broker 的流量就会比其他 broker 低。

现有的/默认的 bundle rebalance 策略(OverloadShedder)为:每隔一分钟统计集群中所有 broker 的 CPU、Memory、Direct Memory、BindWith In、BindWith Out 占用率的最大值是否超过阈值(默认为85%);如果超过阈值,则将一定数量大入流量的 bundle 从该 broker 中卸载掉,然后由 leader 决定将被卸载掉的 bundle 重新加载到负载最低的 broker 上。
这个策略存在的问题是:
- 默认阈值比较难达到,很容易导致集群中大部分流量都集中在几个 broker 上;
- 阈值调整标准难以确定,受其他因素影响较大,特别是这个节点上部署有其他服务的情况下;
- broker 重启后,长时间没有流量均衡到该 broker 上,因为其他 broker 节点均没有达到 bundle unload 阈值。
为此,我们开发了一个基于均值的负载均衡策略,并支持 CPU、Memory、Direct Memory、BindWith In、BindWith Out 权重配置,相关策略请参见 PR-6772。
该策略在 Pulsar 2.6.0 版本开始支持,默认关闭,可以在 broker.conf 中修改如下参数开启:
loadBalancerLoadSheddingStrategy=org.apache.pulsar.broker.loadbalance.impl.ThresholdShedder
我们可以通过如下参数来精确控制不同采集指标的权重:
# The broker resource usage threshold.
# When the broker resource usage is greater than the pulsar cluster average resource usage,
# the threshold shredder will be triggered to offload bundles from the broker.
# It only takes effect in ThresholdSheddler strategy.
loadBalancerBrokerThresholdShedderPercentage=10
# When calculating new resource usage, the history usage accounts for.
# It only takes effect in ThresholdSheddler strategy.
loadBalancerHistoryResourcePercentage=0.9
# The BandWithIn usage weight when calculating new resource usage.
# It only takes effect in ThresholdShedder strategy.
loadBalancerBandwithInResourceWeight=1.0
# The BandWithOut usage weight when calculating new resource usage.
# It only takes effect in ThresholdShedder strategy.
loadBalancerBandwithOutResourceWeight=1.0
# The CPU usage weight when calculating new resource usage.
# It only takes effect in ThresholdShedder strategy.
loadBalancerCPUResourceWeight=1.0
# The heap memory usage weight when calculating new resource usage.
# It only takes effect in ThresholdShedder strategy.
loadBalancerMemoryResourceWeight=1.0
# The direct memory usage weight when calculating new resource usage.
# It only takes effect in ThresholdShedder strategy.
loadBalancerDirectMemoryResourceWeight=1.0
# Bundle unload minimum throughput threshold (MB), avoiding bundle unload frequently.
# It only takes effect in ThresholdShedder strategy.
loadBalancerBundleUnloadMinThroughputThreshold=10
均衡 bookie 节点之间的负载
Bookie 节点负载监控如下图所示,我们会发现:
- Bookie 节点之间负载并不是均匀的,最高流量节点和最低流量节点可能相差几百 MB/s
- 在高负载情况下,某些节点的负载可能会出现周期性上涨和下降,周期为 30 分钟

这些问题的影响是:bookie 负载不均衡,导致 BookKeeper 集群利用率下降,且容易出现抖动。
出现这个问题的原因在于:bookie client 对 bookie 写请求的熔断策略粒度太大。
先来回顾一下 Pulsar broker 写入 bookie 的策略:
当 broker 接收到 producer 发送的 message 时,首先会将消息存放在 broker 的 direct memory 中,然后调用 bookie client 根据配置的(EnsembleSize,WriteQuorum,AckQuorum)策略将 message 以 pipeline 方式发送给 bookies。
Bookie client 每分钟会统计各 bookie 写入的失败率(包括写超时等各类异常)。默认情况下,当失败率超过 5 次/分钟时,这台 bookie 将会被关入小黑屋 30 分钟,避免持续向出现异常的 bookie 写入数据,从而保证 message 写入成功率。

这个熔断策略存在的问题是:某台 bookie 负载(流量)很高时,所有写入到该 bookie 的消息有可能同时会变慢,所有 bookie client 可能同时收到写入异常,如写入超时等,那么所有 bookie client 会同时把这台 bookie 关入小黑屋 30 分钟,等到 30 分钟之后又同时加入可写入列表中。这就导致了这台 bookie 的负载周期性上涨和下降。
为了解决该问题,我们引入了基于概率的 quarantine 机制,当 bookie client 写入消息出现异常时,并不是直接将这台 bookie 关入小黑屋,而是基于概率决定是否 quarantine。
这一 quarantine 策略可以避免所有 bookie client 同时将同一台 bookie 关入小黑屋,避免 bookie 入流量抖动。相关 PR 请参见:BookKeeper PR-2327 ,由于代码没有合并和发布到 bookie 主版本,大家如果想使用该功能,需要自己独立编译代码:https://github.com/apache/bookkeeper/pull/2327。

从 BIGO 实践测试来看,该功能将 bookie 节点之间入流量标准差从 75 MB/s 降低到 40 MB/s。

限流
>>Broker direct memory OOM(内存溢出)
在生产环境中,在高吞吐场景下,我们经常遇到 broker direct memory OOM,导致 broker 进程挂掉。这里的原因可能是底层 bookie 写入变慢,导致大量数据积压在 broker direct memory 中。Producer 发送的消息在 broker 中的处理过程如下图所示:

在生产环境中,我们不能保证底层 bookie 始终保持非常低的写延迟,所以需要在 broker 层做限流。Pulsar 社区的鹏辉开发了限流功能,限流逻辑如下图所示:
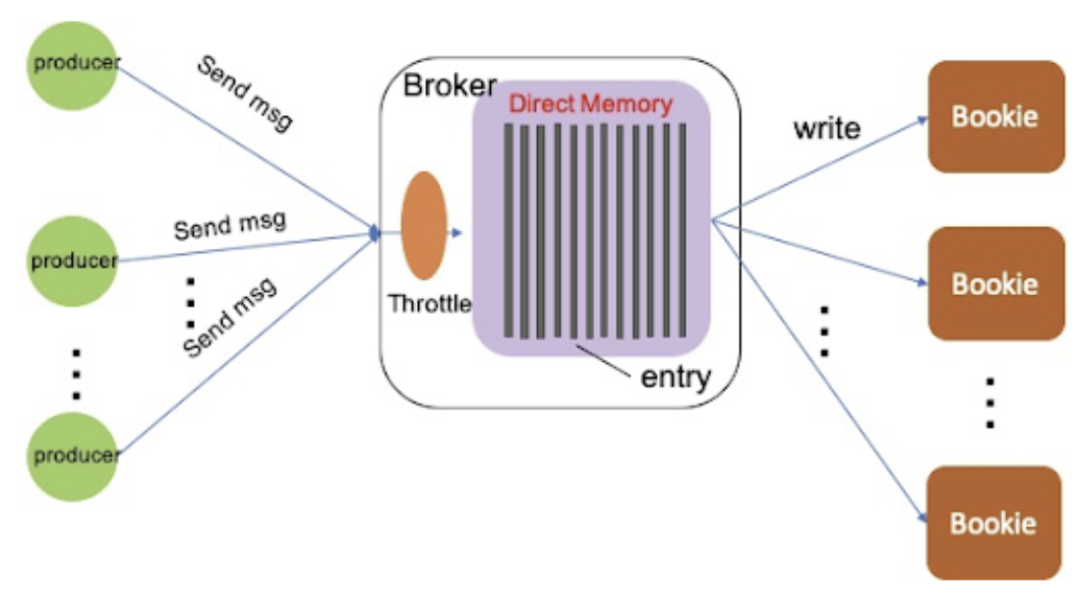
在 Pulsar 2.5.1 版本中已发布,请参见 PR-6178。
Consumer 消耗大量内存
当 producer 端以 batch 模式发送消息时,consumer 端往往会占用过多内存导致频繁 GC,监控上的表现是:这个 topic 的负载在 consumer 启动时飙升,然后逐渐回归到正常水平。
这个问题的原因需要结合 consumer 端的消费模式来看。
当 consumer 调用 receive 接口消费一条消息时,它会直接从本地的 receiverQueue 中请求一条消息,如果 receiverQueue 中还有消息可以获取,则直接将消息返回给 consumer 端,并更新 availablePermit,当 availablePermit < receiverQueueSize/2 时,Pulsar client 会将 availablePermit 发送给 broker,告诉 broker 需要 push 多少条消息过来;如果 receiverQueue 中没有消息可以获取,则等待/返回失败,直到 receiverQueue 收到 broker 推送的消息才将 consumer 唤醒。
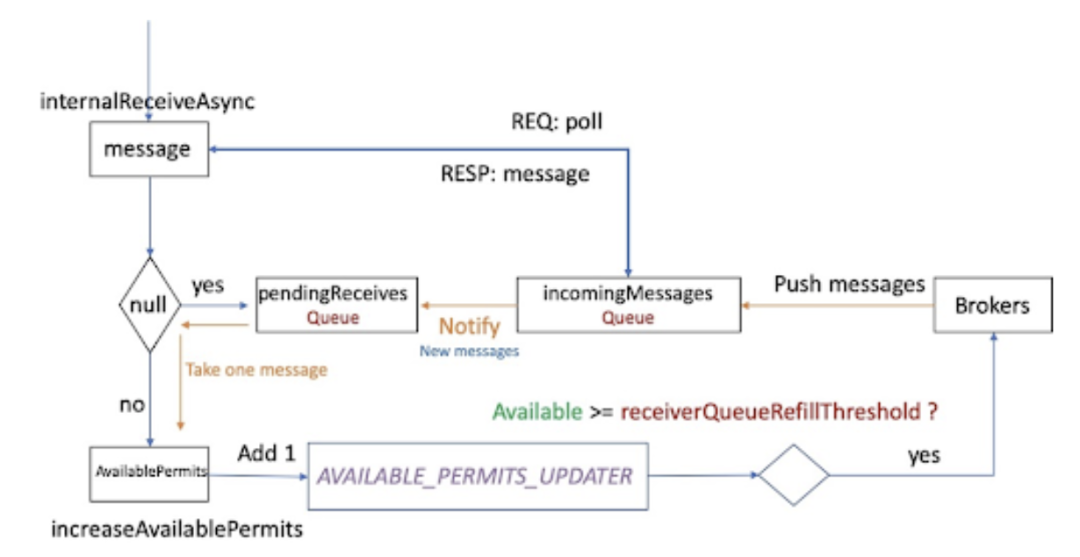
Broker 收到 availablePermit 之后,会从 broker Cache/bookie 中读取 max(availablePermit, batchSize) 条 entry,并发送给 consumer 端。处理逻辑如下图所示:

这里的问题是:当 producer 开启 batch 模式发送,一个 entry 包含多条消息,但是 broker 处理 availablePermit 请求仍然把一条消息作为一个 entry 来处理,从而导致 broker 一次性将大量信息发送给 consumer,这些消息数量远远超过 availiablePermit(availiablePermit vs. availiablePermit * batchSize)的接受能力,引起 consumer 占用内存暴涨,引发频繁 GC,降低消费性能。
为了解决 consumer 端内存暴涨问题,我们在 broker 端统计每个 topic 平均 entry 包含的消息数(avgMessageSizePerEntry), 当接收到 consumer 请求的 availablePermit 时,将其换算成需要发送的 entry 大小,然后从 broker Cache/bookie 中拉取相应数量的 entry,然后发送给 consumer。处理逻辑如下图所示:
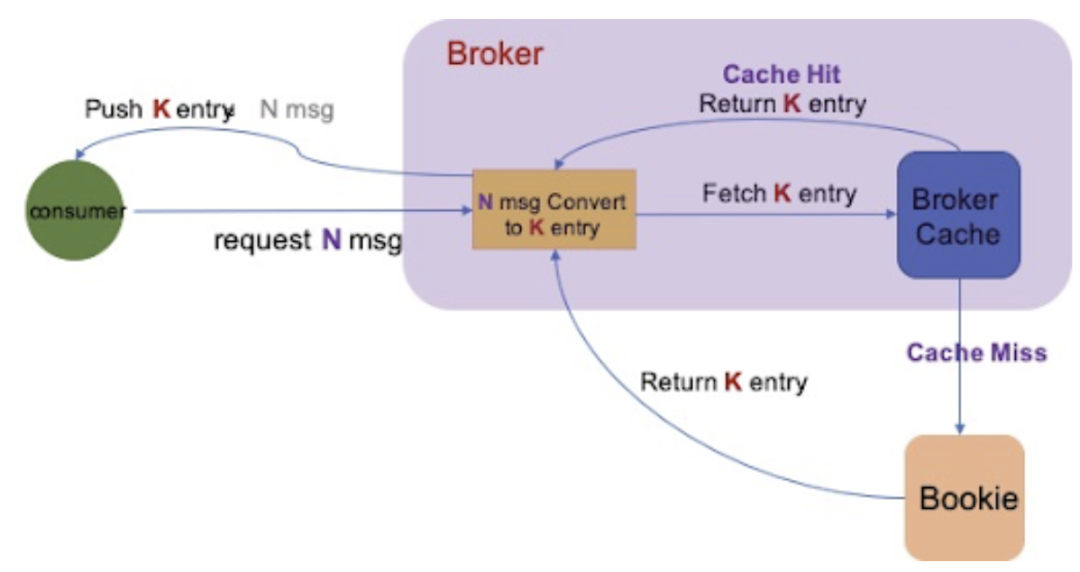
这个功能在 Pulsar 2.6.0 中已发布,默认是关闭的,大家可以通过如下开关启用该功能:
# Precise dispatcher flow control according to history message number of each entry
preciseDispatcherFlowControl=true
提高 Cache 命中率
Pulsar 中有多层 Cache 提升 message 的读性能,主要包括:
- Broker Cache
- Bookie write Cache(Memtable)
- Bookie read Cache
- OS PageCache
本章主要介绍 broker Cache 的运行机制和调优方案,bookie 侧的 Cache 调优放在下篇介绍。
当 broker 收到 producer 发送给某个 topic 的消息时,首先会判断该 topic 是否有 Active Cursor,如果有,则将收到的消息写入该 topic 对应的 Cache 中;否则,不写入 Cache。处理流程如下图所示:
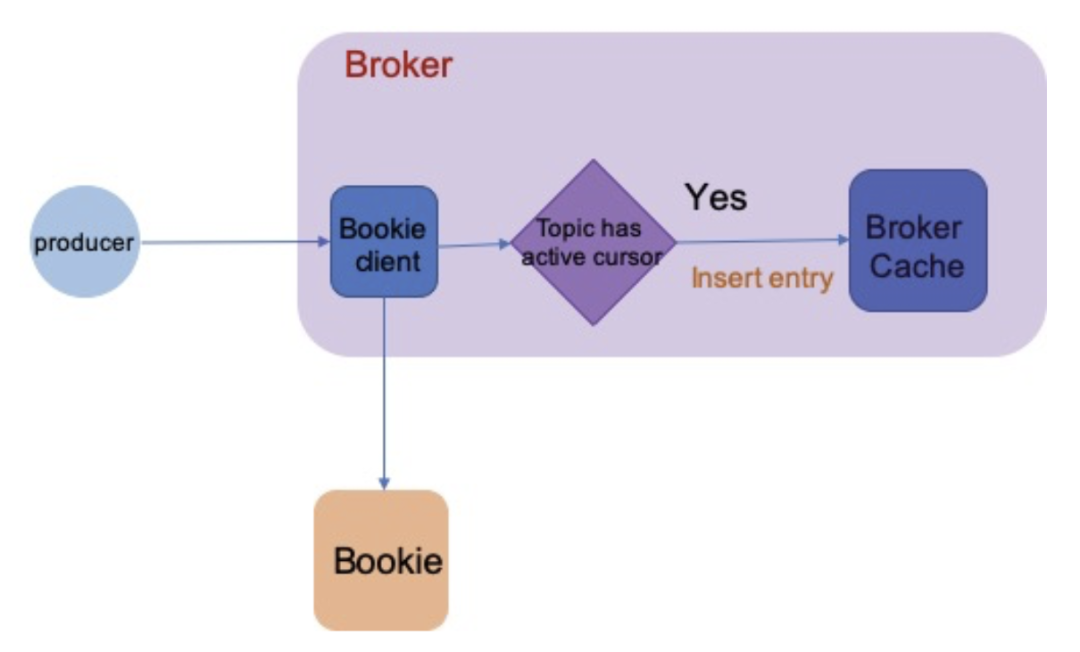
判断是否有 Active Cursor 需要同时满足以下两个条件:
- 有 durable cursor
- Cursor 的 lag 在 managedLedgerCursorBackloggedThreshold 范围内
由于 reader 使用 non-durable cursor 进行消费,所以 producer 写入的消息不会进入 broker Cache,从而导致大量请求落到 bookie 上,性能有所损耗。
streamnative/pulsar-flink-connector 使用的是 reader API 进行消费,所以同样存在消费性能低的问题。
我们 BIGO 消息队列团队的赵荣生同学修复了这个问题,将 durable cursor 从 Active Cursor 判断条件中删除,详情请见 PR-6769 ,这个 feature 在 Pulsar 2.5.2 发布,有遇到相关性能问题的同学请升级 Pulsar 版本到 2.5.2 以上。
此外,我们针对 topic 的每个 subscription 添加了 Cache 命中率监控,方便进行消费性能问题定位,后续会贡献到社区。
Tailing Read
对于已经在 broker Cache 中的数据,在 tailing read 场景下,我们怎样提高 Cache 命中率,降低从 bookie 读取数据的概率呢?我们的思路是尽可能让数据从 broker Cache 中读取,为了保证这一点,我们从两个地方着手优化:
- 控制判定为 Active Cursor 的最大 lag 范围,默认是 1000 个 entry ,由如下参数控:
# Configure the threshold (in number of entries) from where a cursor should be considered 'backlogged'
# and thus should be set as inactive.
managedLedgerCursorBackloggedThreshold=1000
Active Cursor 的判定如下图所示。

- 控制 broker Cache 的 eviction 策略,目前 Pulsar 中只支持默认 eviction 策略,有需求的同学可以自行扩展。默认 eviction 策略由如下参数控制:
# Amount of memory to use for caching data payload in managed ledger. This memory
# is allocated from JVM direct memory and it's shared across all the topics
# running in the same broker. By default, uses 1/5th of available direct memory
managedLedgerCacheSizeMB=
# Whether we should make a copy of the entry payloads when inserting in cache
managedLedgerCacheCopyEntries=false
# Threshold to which bring down the cache level when eviction is triggered
managedLedgerCacheEvictionWatermark=0.9
# Configure the cache eviction frequency for the managed ledger cache (evictions/sec)
managedLedgerCacheEvictionFrequency=100.0
# All entries that have stayed in cache for more than the configured time, will be evicted
managedLedgerCacheEvictionTimeThresholdMillis=1000
Catchup Read
对于 Catchup Read 场景,broker Cache 大概率会丢失,所有的 read 请求都会落到 bookie 上,那么有没有办法提高读 bookie 的性能呢?
Broker 向 bookie 批量发送读取请求,最大 batch 由 dispatcherMaxReadBatchSize 控制,默认是 100 个 entry。
# Max number of entries to read from bookkeeper. By default it is 100 entries.
dispatcherMaxReadBatchSize=100
一次读取的 batchSize 越大,底层 bookie 从磁盘读取的效率越高,均摊到单个 entry 的 read latency 就越低。但是如果过大也会造成 batch 读取延迟增加,因为底层 bookie 读取操作时每次读一条 entry,而且是同步读取。
这一部分的读取调优放在《Apache Pulsar 在 BIGO 的性能调优实战(下)》中介绍。
保证 ZooKeeper 读写低延迟
由于 Pulsar 和 BookKeeper 都是严重依赖 ZooKeeper 的,如果 ZooKeeper 读写延迟增加,就会导致 Pulsar 服务不稳定。所以需要优先保证 ZooKeeper 读写低延迟。建议如下:
- 在磁盘为 HDD 情况下,ZooKeeper dataDir/dataLogDir 不要和其他消耗 IO 的服务(如 bookie Journal/Ledger 目录)放在同一块盘上(SSD 除外);
- ZooKeeper dataDir 和 dataLogDir 最好能够放在两块独立磁盘上(SSD 除外);
- 监控 broker/bookie 网卡利用率,避免由于网卡打满而造成和 ZooKeeper 失联。
关闭 auto bundle split,保证系统稳定
Pulsar bundle split 是一个比较耗费资源的操作,会造成连接到这个 bundle 上的所有 producer/consumer/reader 连接断开并重连。一般情况下,触发 auto bundle split 的原因是这个 bundle 的压力比较大,需要切分成两个 bundle,将流量分摊到其他 broker,来降低这个 bundle 的压力。控制 auto bundle split 的参数如下:
# enable/disable namespace bundle auto split
loadBalancerAutoBundleSplitEnabled=true
# enable/disable automatic unloading of split bundles
loadBalancerAutoUnloadSplitBundlesEnabled=true
# maximum topics in a bundle, otherwise bundle split will be triggered
loadBalancerNamespaceBundleMaxTopics=1000
# maximum sessions (producers + consumers) in a bundle, otherwise bundle split will be triggered
loadBalancerNamespaceBundleMaxSessions=1000
# maximum msgRate (in + out) in a bundle, otherwise bundle split will be triggered
loadBalancerNamespaceBundleMaxMsgRate=30000
# maximum bandwidth (in + out) in a bundle, otherwise bundle split will be triggered
loadBalancerNamespaceBundleMaxBandwidthMbytes=100
当触发 auto bundle split 时 broker 负载比较高,关闭这个 bundle 上的 producer/consumer/reader,连接就会变慢,并且 bundle split 的耗时也会变长,就很容易造成 client 端(producer/consumer/reader)连接超时而失败,触发 client 端自动重连,造成 Pulsar/Pulsar client 不稳定。
对于生产环境,我们的建议是:预先为每个 namespace 分配好 bundle 数,并关闭 auto bundle split 功能。如果在运行过程中发现某个 bundle 压力过大,可以在流量低峰期进行手动 bundle split,降低对 client 端的影响。
关于预先分配的 bundle 数量不宜太大,bundle 数太多会给 ZooKeeper 造成比较大的压力,因为每一个 bundle 都要定期向 ZooKeeper 汇报自身的统计数据。
总结
本篇从性能调优角度介绍了 Pulsar 在 BIGO 实践中的优化方案,主要分为环境部署、流量均衡、限流措施、提高 Cache 命中率、保证 Pulsar 稳定性等 5 个方面,并深入介绍了 BIGO 消息队列团队在进行 Pulsar 生产落地过程中的一些经验。
本篇主要解决了开篇提到的这几个问题(1、2、5、7、8、9 )。对于问题 3,我们提出了一个缓解方案,但并没有指出 Pulsar broker OOM 的根本原因,这个问题需要从 BookKeeper 角度来解决,剩下的问题都和 BookKeeper 相关。
由于 Pulsar 使用分层存储架构,底层的 BookKeeper 仍需要进行一系列调优来配合上层 Pulsar,充分发挥高吞吐、低延迟性能;下篇将从 BookKeeper 性能调优角度介绍 BIGO 的实践经验。
非常感谢 StreamNative 同学的悉心指导和无私帮助,让 Pulsar 在 BIGO 落地迈出了坚实的一步。Apache Pulsar 提供的高吞吐、低延迟、高可靠性等特性极大提高了 BIGO 消息处理能力,降低了消息队列运维成本,节约了近一半的硬件成本。
同时,我们也积极融入 Pulsar 社区,并将相关成果贡献回社区。我们在 Pulsar Broker 负载均衡、Broker Cache 命中率优化、Broker 相关监控、Bookkeeper 读写性能优、Bookkeeper 磁盘 IO 性能优化、Pulsar 与 Flink & Flink SQL 结合等方面做了大量工作,帮助社区进一步优化、完善 Pulsar 功能。
关于作者
陈航,BIGO 大数据消息平台团队负责人,负责承载大规模服务与应用的集中发布-订阅消息平台的创建与开发。他将 Apache Pulsar 引入到 BIGO 消息平台,并打通上下游系统,如 Flink、ClickHouse 和其他实时推荐与分析系统。他目前聚焦 Pulsar 性能调优、新功能开发及 Pulsar 生态集成方向。
Apache Pulsar 在 BIGO 的性能调优实战(上)的更多相关文章
- JVM 性能调优实战之:使用阿里开源工具 TProfiler 在海量业务代码中精确定位性能代码
本文是<JVM 性能调优实战之:一次系统性能瓶颈的寻找过程> 的后续篇,该篇介绍了如何使用 JDK 自身提供的工具进行 JVM 调优将 TPS 由 2.5 提升到 20 (提升了 7 倍) ...
- JVM 性能调优实战之:一次系统性能瓶颈的寻找过程
玩过性能优化的朋友都清楚,性能优化的关键并不在于怎么进行优化,而在于怎么找到当前系统的性能瓶颈.性能优化分为好几个层次,比如系统层次.算法层次.代码层次…JVM 的性能优化被认为是底层优化,门槛较高, ...
- spring-petclinic性能调优实战(转)
1.spring-petclinic介绍 spring-petclinic是spring官方做的一个宠物商店,结合了spring和其他一些框架的最佳实践. 架构如下: 1)前端 Thymeleaf做H ...
- Java性能调优实战,覆盖80%以上调优场景
Java 性能调优对于每一个奋战在开发一线的技术人来说,随着系统访问量的增加.代码的臃肿,各种性能问题便会层出不穷. 日渐复杂的系统,错综复杂的性能调优,都对Java工程师的技术广度和技术深度提出了更 ...
- 高性能 Java 计算服务的性能调优实战
作者:vivo 互联网服务器团队- Chen Dongxing.Li Haoxuan.Chen Jinxia 随着业务的日渐复杂,性能优化俨然成为了每一位技术人的必修课.性能优化从何着手?如何从问题表 ...
- PHP 性能分析第三篇: 性能调优实战
注意:本文是我们的 PHP 性能分析系列的第三篇,点此阅读 PHP 性能分析第一篇: XHProf & XHGui 介绍 ,或 PHP 性能分析第二篇: 深入研究 XHGui. 在本系列的 ...
- Tomcat性能调优实战
今日帮朋友做了tomcat性能调优的实际操作,心得记录一下. 服务器:Windows2017 配置:CPU 4 内存 8G Tomcat8.0+版本. 压力测试工具:apache-jmeter-4.0 ...
- 【转】UIKit性能调优实战讲解
文/bestswifter(简书作者)原文链接:http://www.jianshu.com/p/619cf14640f3著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”. 在使用UIKi ...
- Spark&Spark性能调优实战
Spark特别适用于多次操作特定的数据,分mem-only和mem & disk.当中mem-only:效率高,但占用大量的内存,成本非常高;mem & disk:内存用完后,会自己主 ...
随机推荐
- react-ts模板2.0
最新整理的react模板2.0 - react 16.12.0 - react-router - redux,redux-thunk - hooks,typescript - antd v4,sass ...
- 包管理Go module的使用
我用 Golang 的 Web 框架 Iris 写项目时,发现下载依赖老是失败原因是被墙了(可以参考上一篇 https://www.cnblogs.com/ser0632/p/11374790.htm ...
- 没用过消息队列?一文带你体验RabbitMQ收发消息
人生终将是场单人旅途,孤独之前是迷茫,孤独过后是成长. 楔子 先给大家说声抱歉,最近一周都没有发文,有一些比较要紧重要的事需要处理. 今天正好得空,本来说准备写SpringIOC相关的东西,但是发现想 ...
- SpringMVC入门和常用注解
SpringMVC的基本概念 关于 三层架构和 和 MVC 三层架构 我们的开发架构一般都是基于两种形式,一种是 C/S 架构,也就是客户端/服务器,另一种是 B/S 架构,也就 是浏览器服务器.在 ...
- ios textView跟随键盘的移动
实现效果: textview 能够跟随键盘的移动而移动 效果图如下: 下边贴上主要的代码: 1.创建textview @interface ViewController ()<UITextVie ...
- Linux-sed命令使用笔记
Linux的sed命令和python脚本一起,可以对文本进行快速的修改.比如在删除日志的时候,python写出固定日期删除脚本,再用sed循环将python脚本的日期修改调用,就可以批删除指定日期的日 ...
- HashMap:从源码分析到面试题
1 HashMap简介 HashMap是实现map接口的一个重要实现类,在我们无论是日常还是面试,以及工作中都是一个经常用到角色.它的结构如下: 它的底层是用我们的哈希表和红黑树组成的.所以我们在学习 ...
- 3、Template Method 模板方法 行为型设计模式
1.了解模板方法 1.1 模式定义 定义一个操作算法中的框架,而将这些步骤延迟加载到子类中. 它的本质就是固定算法框架. 1.2 解决何种问题 让父类控制子类方法的调用顺序 模板方法模式使得子类可以不 ...
- LeetCode343 整数拆分详解
题目详情 给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化. 返回你可以获得的最大乘积. 示例 1: 输入: 2 输出: 1 解释: 2 = 1 + 1, 1 × 1 = 1 ...
- MacOS抓包工具Charles
抓包工具有wireshark, tcpdump, 还有就是Charles. 今天分享的是最后一个Charles.抓包分2个, 一个是移动端的,一个是macOS自带的应用. 安装Charles http ...