论文学习笔记 - Classifification of Hyperspectral and LiDAR Data Using Coupled CNNs
Classifification of Hyperspectral and LiDAR Data Using Coupled CNNs
来源:IEEE TGRS 2020
Abstract
本篇论文的主要工作就是基于信息融合的分类任务。
在这篇论文中,作者通过使用两个耦合的CNN,提出一种融合高光谱和LiDAR数据的框架。设计一个CNN从高光谱数据中了解光谱空间特征,另一个则用于捕获来自LiDAR数据。它们都由三个卷积层组成,最后两个卷积层通过参数共享策略。在融合阶段,特征级融合和决策级融合方法同时用于集成这些充足的异质特征。对于特征级融合,评估了三种不同的融合策略,包括串联策略,最大化策略和求和策略。对于决策级融合,加权采用求和策略,确定权重通过每个输出的分类精度。
提出的模型根据在美国休斯顿获得的城市数据集进行评估,还有在意大利Trento农村地区捕获的数据。在休斯顿数据中,作者的模型可以达到新记录,整体精度为96.03%。在Trento数据上,其总体精度为99.12%。这些结果充分证明了作者提出的模型的有效性。
INTRODUCTION
文中模型的数据源是两幅异质图像——高光谱图像(HSI)和激光雷达(LiDAR)图像。
HSI图像相比MSI具有更丰富的光谱信息,但是对于同一材质的物体区分性较弱,他们具有相似的光谱回应。不同于HSI,LiDAR可以记录物体的海拔信息,能够为HSI提供补充,二者优势互补。
例如:区域中的楼房和道路由同样的混凝土结构组成,HSI图像很难区分二者之间的差别,但是LiDAR图像则可以准确区分出楼房和道路,因为他们有不同的高度。相反,LiDAR无法区分两条用不同材料(沥青和混凝土)组成的道路,而可以用HSI。因此,融合高光谱和LiDAR数据是一种很有前途的方案,其性能已经得到了验证。
METHODOLOGY
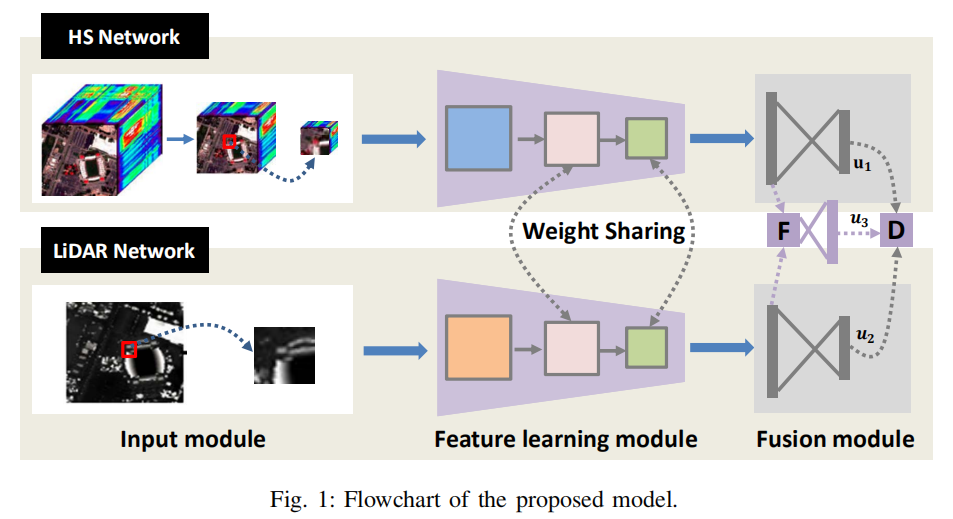
作者提出的模型主要包括两个网络:用于光谱空间特征学习的HSI网络
和用于海拔特征学习的LiDAR网络。它们每个都包含一个输入模块,一个特征学习模块和融合模块,如上图所示。在特征学习模块中,输入的HSI图像和LiDAR图像分别通过一个三层的网络结构进行特征提取,三层网络结构中的后两个卷积层权值共享。权值共享能够减少网络参数,而且有利于两个分支统一优化。特征提取后则进入信息的融合模块,在融合模块中,构造了三个分类器,每个CNN都有一个输出层,它们的融合特征也具有输出层。
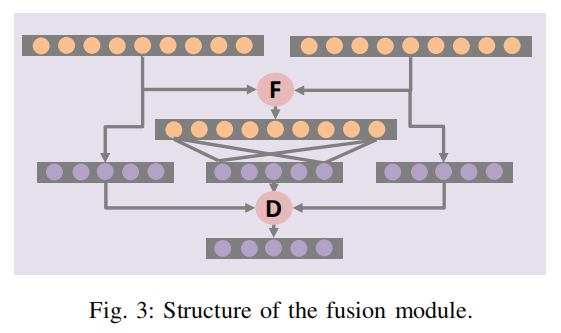
如图2所示,两组图像特征首先通过特征级融合 \(F\) 获得特征级融合特征\(F3=F1+F2\) 或者 \(F3=max(F1,F2)\),特征级融合可以采用逐元素相加或者Max函数。然后对上述 \(F1,F2,F3\) 分别以下操作:
\]
然后文中使用决策级融合 \(D\) 获得最终的融合特征:\(O=F1\odot y1+F2\odot y2+F3\odot y3\),\(\odot\) 为加权操作。
然后 \(L1\) 表示HSI图像(\(y1\))的交叉熵损失,\(L2\)表示LiDAR图像(\(y2\))的交叉熵损失。\(L3\)表示融合信息(\(O\))的交叉熵损失。所以最终的损失函数为:
\]
EXPERIMENTS
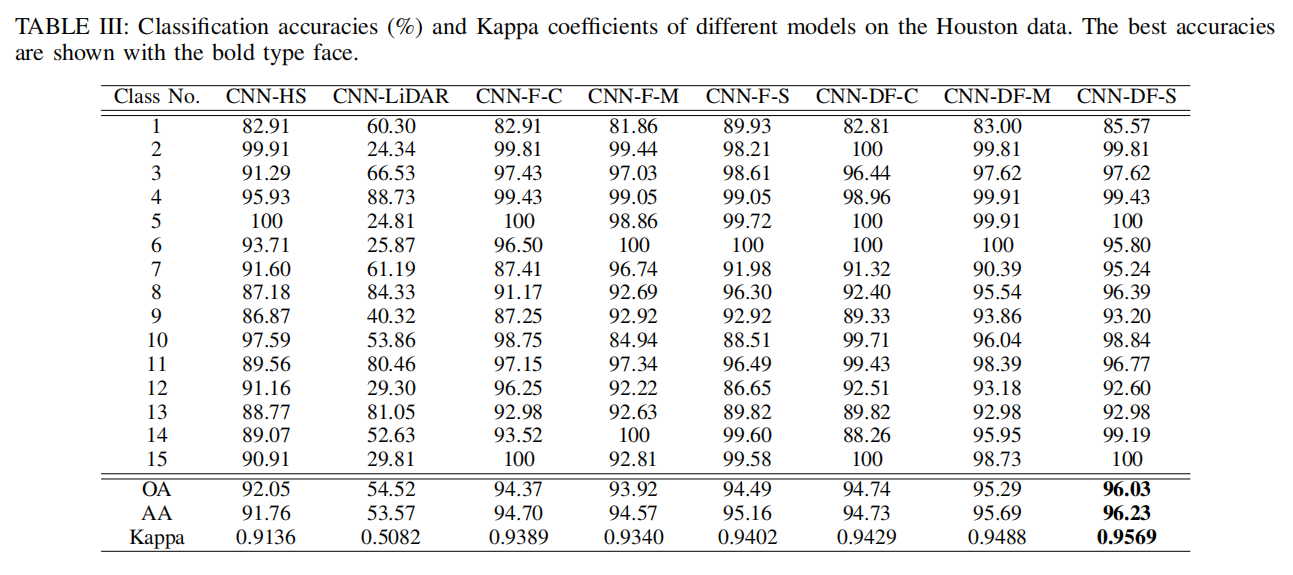

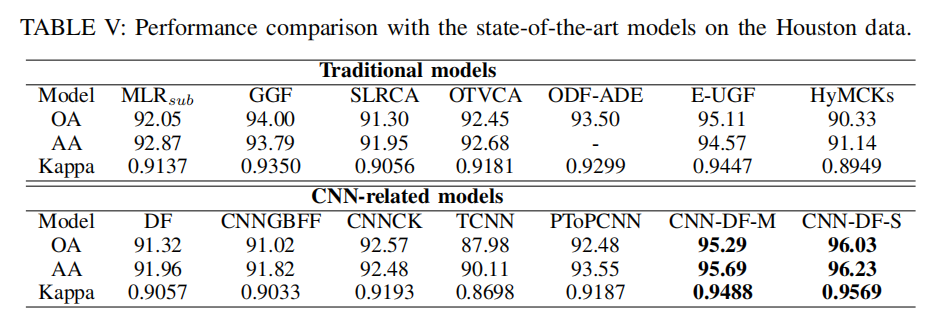
CONCLUSIONS
在将来需要探索更强大的邻近提取方法,因为当前的分类图仍然存在过度平滑的问题。
论文学习笔记 - Classifification of Hyperspectral and LiDAR Data Using Coupled CNNs的更多相关文章
- 论文学习笔记 - 高光谱 和 LiDAR 融合分类合集
A³CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Se ...
- Apache Calcite 论文学习笔记
特别声明:本文来源于掘金,"预留"发表的[Apache Calcite 论文学习笔记](https://juejin.im/post/5d2ed6a96fb9a07eea32a6f ...
- Lasso估计论文学习笔记(一)
最近课程作业让阅读了这篇经典的论文,写篇学习笔记. 主要是对论文前半部分Lasso思想的理解,后面实验以及参数估计部分没有怎么写,中间有错误希望能提醒一下,新手原谅一下. 1.整体思路 作者提出了一种 ...
- Raft论文学习笔记
先附上论文链接 https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf 最近在自学MIT的6.824分布式课程,找到两个比较好的githu ...
- 论文学习笔记--无缺陷样本产品表面缺陷检测 A Surface Defect Detection Method Based on Positive Samples
文章下载地址:A Surface Defect Detection Method Based on Positive Samples 第一部分 论文中文翻译 摘要:基于机器视觉的表面缺陷检测和分类可 ...
- QA问答系统,QA匹配论文学习笔记
论文题目: WIKIQA: A Challenge Dataset for Open-Domain Question Answering 论文代码运行: 首先按照readme中的提示安装需要的部分 遇 ...
- 【Python学习笔记】Coursera课程《Python Data Structures》 密歇根大学 Charles Severance——Week6 Tuple课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week6 Tuple 10 Tuples 10.1 Tuples A ...
- JMeter学习笔记(九) 参数化2--CSV Data Set Config
2.CSV Data Set Config 1)添加 CSV Data Set Confi 2)配置CSV Data Set Config 3)添加HTTP请求,引用参数,格式 ${} 4)执行HTT ...
- JMeter学习笔记(十一) 关于 CSV Data Set Config 的 Sharing mode 对取值的影响
关于 CSV Data Set Config 的一些介绍之前已经梳理过了,可以参考: https://www.cnblogs.com/xiaoyu2018/p/10184127.html . 今天主要 ...
随机推荐
- 使用Java Stream,提取集合中的某一列/按条件过滤集合/求和/最大值/最小值/平均值
不得不说,使用Java Stream操作集合实在是太好用了,不过最近在观察生产环境错误日志时,发现偶尔会出现以下2个异常: java.lang.NullPointerException java.ut ...
- Linux实战(13):Centos8 同步时间
前言 以下操作是通过ntpdate命令实现同步 timedatectl set-timezone Asia/Shanghai # 设置时区 rpm -ivh http://mirrors.wlnmp. ...
- 交互平台 - Processing - 开发模板(仿Openframeworks)
之前在CSDN上发表过: https://blog.csdn.net/fddxsyf123/article/details/62425251
- 一台电脑配置多个GigHub账号
换了新的公司,原来的公司用SVN(比较老了),自己平时用码云(Gitee),新公司使用GitHub.前天通知我注册GitHub账号,但是并未通知用户名的事情(要求用自己的名字),原来的GitHub账号 ...
- Helm部署和体验jenkins
如何快速且简单的部署 通过helm可以快速且简单的部署多种应用,关于helm的安装和使用请参考 环境信息 本次实战的环境信息如下: kubernetes集群:三台CentOS7.7服务器 kubern ...
- 基于NPOI的Excel导入导出类库
概述 支持多sheet导入导出.导出字段过滤.特性配置导入验证,非空验证,唯一验证,错误标注等 用于基础配置和普通报表的导入导出,对于复杂需求,比如合并列,公式,导出图片等暂不支持 GitHub地址: ...
- 你用对锁了吗?浅谈 Java “锁” 事
每个时代,都不会亏待会学习的人 大家好,我是yes. 本来打算继续写消息队列的东西的,但是最近在带新同事,发现新同事对于锁这方面有一些误解,所以今天就来谈谈"锁"事和 Java 中 ...
- JDBC Java 连接 MySQL 数据库
MySQL 版本:Server version: 5.7.17-log MySQL Community Server (GPL) 用于测试的 MySQL 数据库:game 查看数据库中的表 mysql ...
- apline无法向gitlab上传git lfs问题
1 背景 在k8s中基于alpine做底层系统的容器进行git lfs push操作时,发现报错无法上传成功 Fatal error: Server error: http://git.ops.xxx ...
- maven下载依赖包下载失败
在家办公,遇到项目的maven包下载不了,刚开始以为是vpn的问题,折腾半天反复确认之后没有发现什么问题. 同时试过阿里巴巴的maven仓库,删除过以来,重新导过包发现都不行. 后来在idea的设置里 ...